SPSS Modelerでフォルダ内のCSVを一括で読みたいことがあります。
これをModelerスクリプトをつかって実現しました。
■テスト環境
Modeler 18.2.1 および18.4
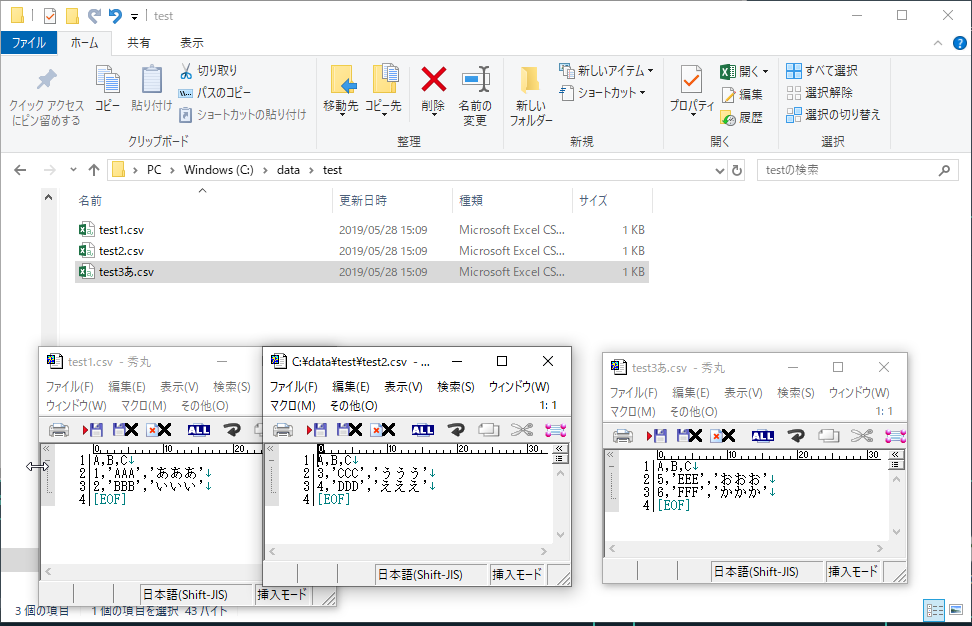
1.フォルダ内にcsvを配置する
以下のように一つのフォルダに同じ列を持つcsvを配置します。
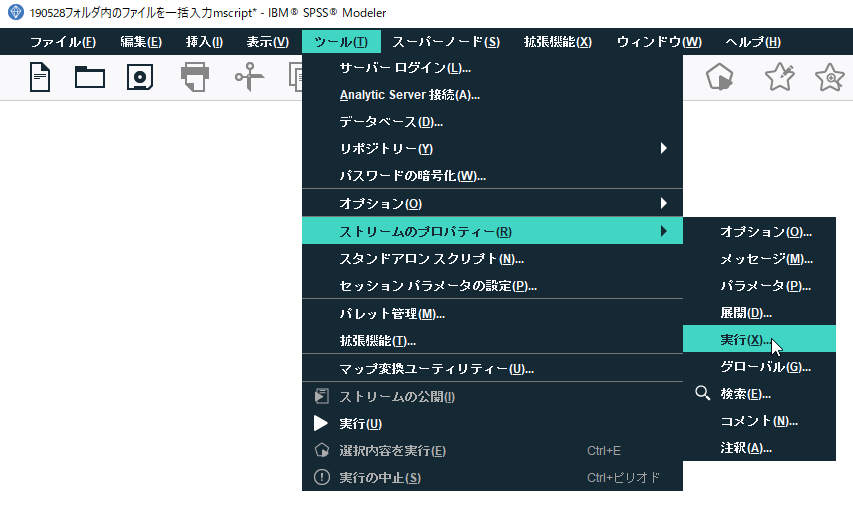
2.空のキャンパスを開き、スクリプトを入力する
「ツール」_「ストリームのプロパティ」_「実行」でスクリプトの入力画面を開きます。
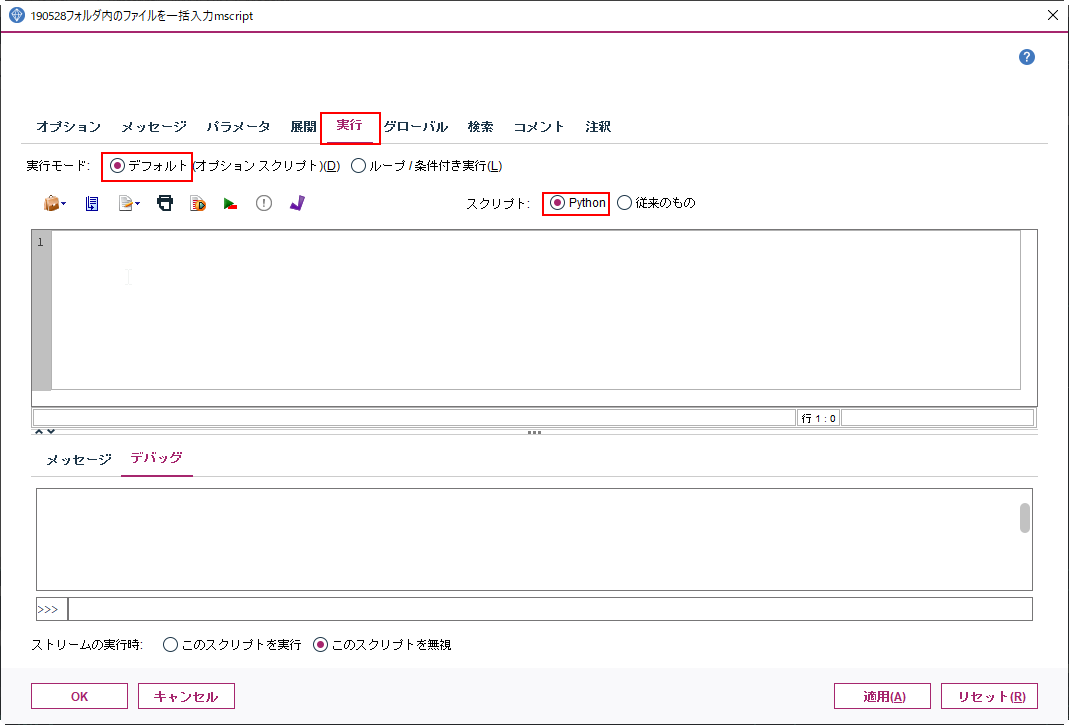
実行モードが「デフォルト」で、スクリプトが「Python」であることを確認します。
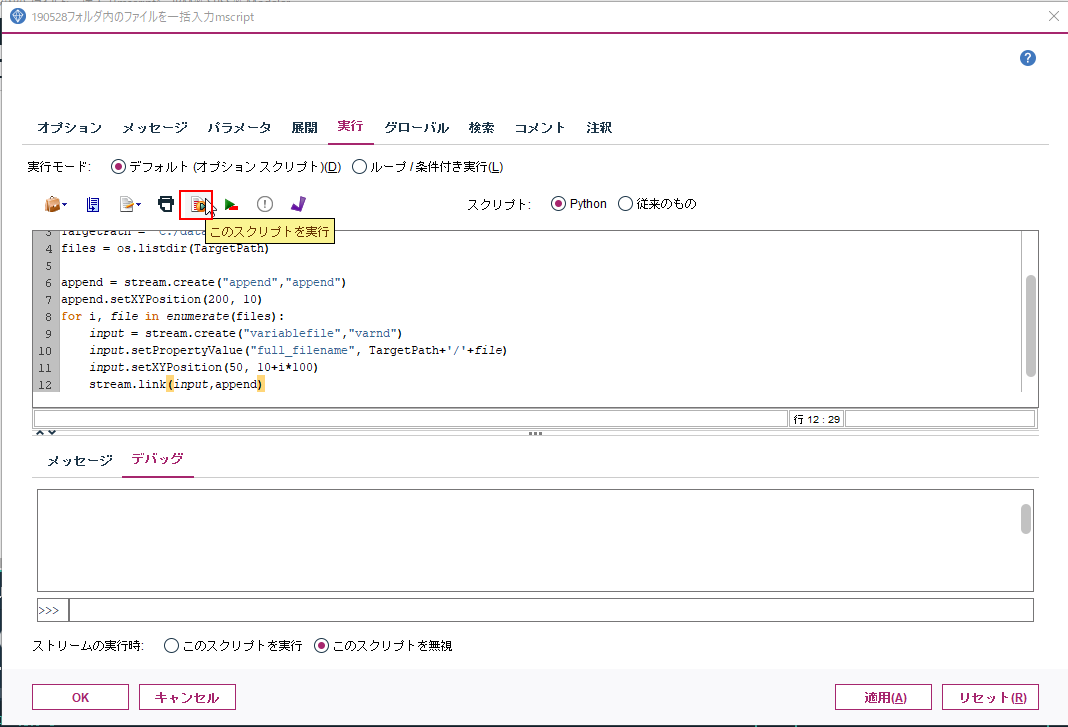
3. 以下のスクリプトを入力し、実行します。
stream = modeler.script.stream()
import os
TargetPath = 'C:/data/test'
files = os.listdir(TargetPath)
append = stream.create("append","append")
append.setXYPosition(200, 10)
for i, file in enumerate(files):
input = stream.create("variablefile","varnd")
input.setPropertyValue("full_filename", TargetPath+'/'+file.decode('utf-8'))
input.setXYPosition(50, 10+i*100)
stream.link(input,append)
TargetPathが一括処理をするCSVが入ったフォルダになります。
このスクリプトを実行ボタンをクリックします。
以下のようにCSVファイルを読み込んでレコード追加でまとめてくれます。
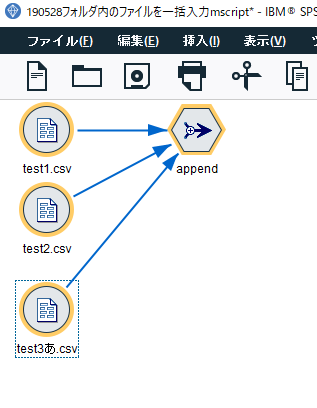
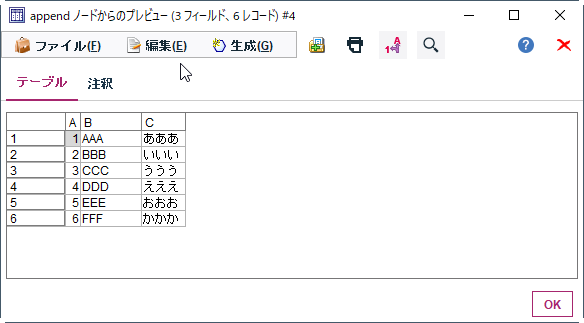
参考
IBM 特定のフォルダにある全てのcsvファイルを可変長ノードから読み込む方法
https://www-01.ibm.com/support/docview.wss?uid=swg22011818
この記事のPythonスクリプトがベースになっています。