SPSS Modelerで、watsonx.aiで生成系AIのwatsonx.aiをつかってセンチメント分析(感情分析)をします。
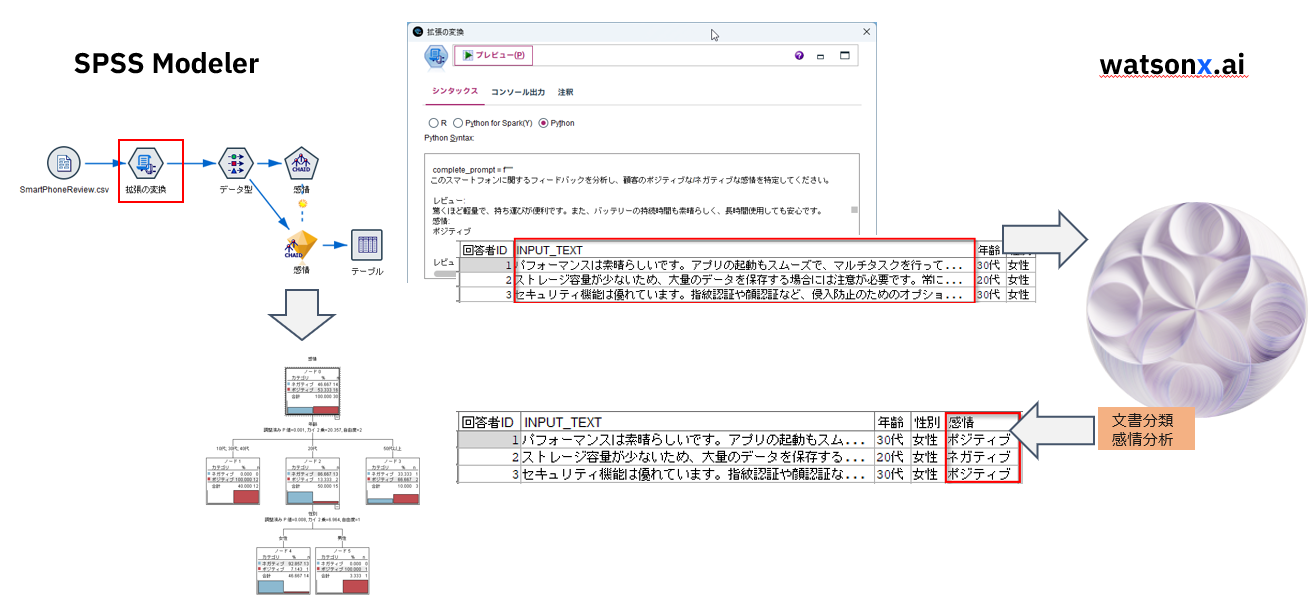
SPSS Modelerで日本語文をwatsonx.aiに与えて、センチメント分析をした結果を受け取ります。「拡張の変換ノード」のNative Pythonを使います。Pythonプログラムのロジックは以下の解説とほぼ同じです。
watsonx.aiで日本語文からの固有表現抽出(Python編)
具体的にはスマートフォンのレビュー文を「ポジティブ」か「ネガティブ」に分類してModelerで表示し、その後構造化データとして分析します。
実行動画(2分53秒)
- サンプルストリーム
- テスト環境
- Modeler 18.5
- Windows 11 64bit
- watsonx.ai (クラウド)
- python:3.10.9
- ibm_watson_machine_learning:1.0.353
1. ibm_watson_machine_learningの導入
Modeler内のPythonにibm_watson_machine_learningを導入します。
管理者としてコマンドプロンプトを起動します。
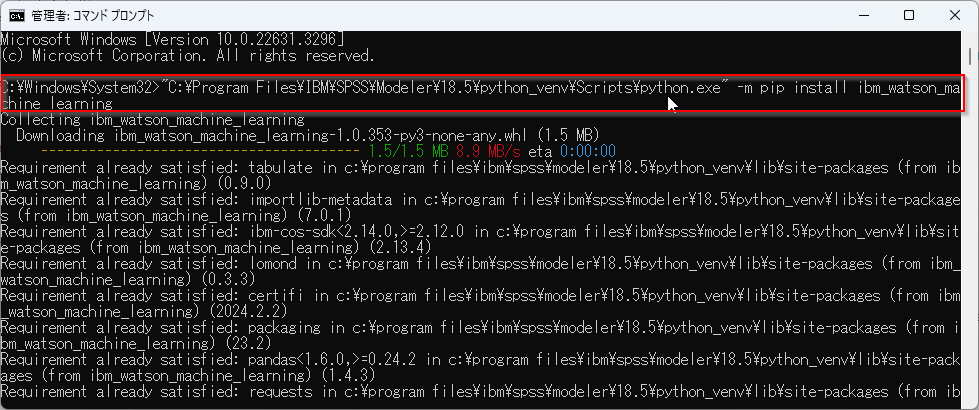
以下のコマンドで導入します。
"C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts\python.exe" -m pip install ibm_watson_machine_learning
2. 入力
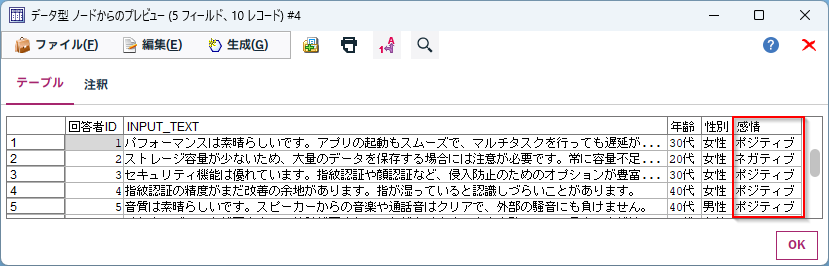
「SmartPhoneReview.csv」というファイルを読み込みます。スマホのレビューが「INPUT_TEXT」列に入っています。
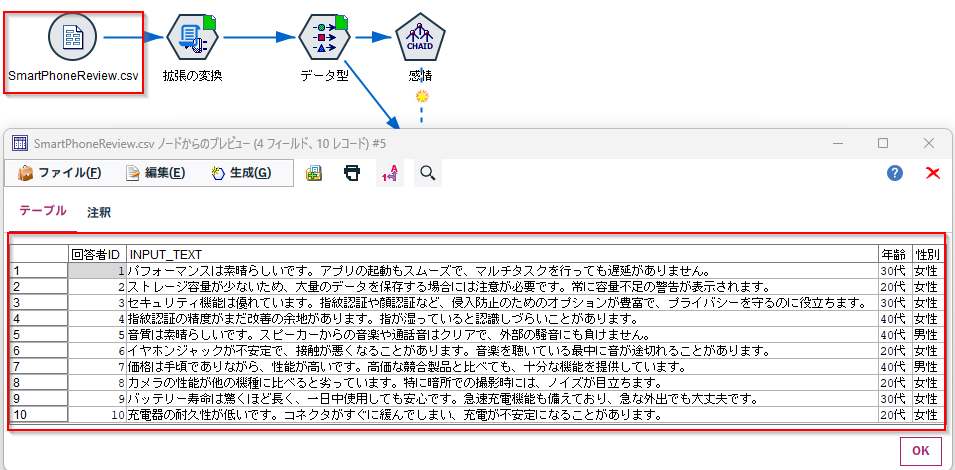
3. 拡張のエクスポートノード
APIキーとプロジェクトIDは以下を参考に取得してください。
「拡張のエクスポートノード」に以下を入力して実行します。
APIキーとプロジェクトIDは上で取得したものに置き換えてください。
api_key = "XXXXXXXXXXXXXXXXXXXXXXXX"
watsonx_project_id = "XXXXXXXXXXXXXXXXXXXXXXXXX"
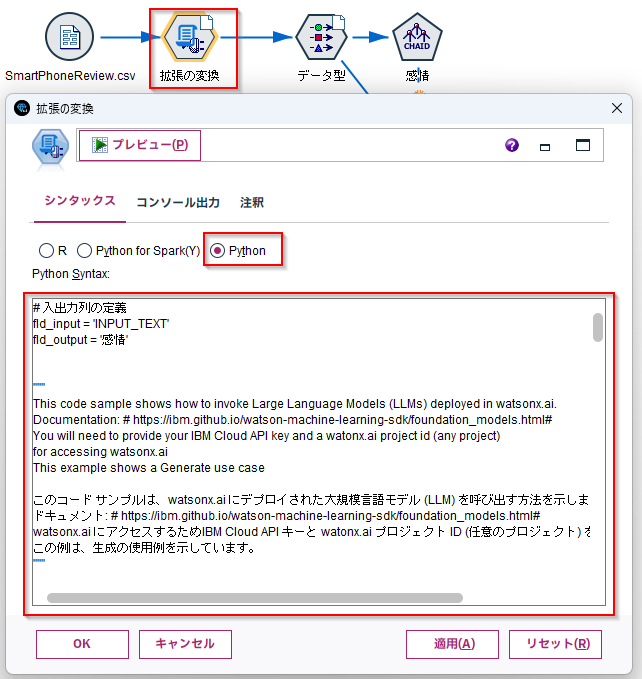
# 入出力列の定義
fld_input = 'INPUT_TEXT'
fld_output = '感情'
"""
This code sample shows how to invoke Large Language Models (LLMs) deployed in watsonx.ai.
Documentation: # https://ibm.github.io/watson-machine-learning-sdk/foundation_models.html#
You will need to provide your IBM Cloud API key and a watonx.ai project id (any project)
for accessing watsonx.ai
This example shows a Generate use case
このコード サンプルは、watsonx.ai にデプロイされた大規模言語モデル (LLM) を呼び出す方法を示します。
ドキュメント: # https://ibm.github.io/watson-machine-learning-sdk/foundation_models.html#
watsonx.ai にアクセスするためIBM Cloud API キーと watonx.ai プロジェクト ID (任意のプロジェクト) を提供する必要があります。
この例は、生成の使用例を示しています。
"""
# Install the wml api your Python env prior to running this example:
# この例を実行する前に、Python 環境に wml API をインストールしてください
# pip install ibm-watson-machine-learning
# テストした環境
# ibm_watson_machine_learning:1.0.353
# python:3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)]
# ibm_watson_machine_learningのモジュールをインポート
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes, DecodingMethods
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models import Model
# 環境依存情報
# APIキー
api_key = "XXXXXXXXXXXXXXXXXXXXXXXX"
# プロジェクトID
watsonx_project_id = "XXXXXXXXXXXXXXXXXXXXXXXXX"
# エンドポイントURL
url = "https://jp-tok.ml.cloud.ibm.com"
# モデルの定義
def get_model():
# 基盤モデルの選択
model_type = 'ibm/granite-8b-japanese'
# model_type = ModelTypes.ELYZA_JAPANESE_LLAMA_2_7B_INSTRUCT
# モデルパラメータの指定
generate_params = {
GenParams.DECODING_METHOD: DecodingMethods.GREEDY,
GenParams.REPETITION_PENALTY: 1.1,
GenParams.MIN_NEW_TOKENS: 0,
GenParams.MAX_NEW_TOKENS: 200
}
model = Model(
model_id=model_type,
params=generate_params,
credentials={
"apikey": api_key,
"url": url
},
project_id=watsonx_project_id
)
return model
# プロンプトの作成
def get_prompt(input_text):
# Get the complete prompt by replacing variables
# 変数を置き換えて完全なプロンプトを取得します
complete_prompt = f"""
このスマートフォンに関するフィードバックを分析し、顧客のポジティブな/ネガティブな感情を特定してください。
レビュー:
驚くほど軽量で、持ち運びが便利です。また、バッテリーの持続時間も素晴らしく、長時間使用しても安心です。
感情:
ポジティブ
レビュー:
カメラの性能が他の機種に比べるとやや劣っています。特に暗所での撮影時には、ノイズが目立ちます。
感情:
ネガティブ
レビュー:
デザインは非常に洗練されており、手にしっくりと馴染みます。操作性も高く、使いやすさに定評があります。
感情:
ポジティブ
レビュー:
画面の解像度がやや低いです。テキストや画像を拡大すると、粗さが目立ちます。
感情:
ネガティブ
レビュー:
{input_text}
感情:
"""
return complete_prompt
# 生成の実行
def get_output(input_text):
# Instantiate the model
# モデルをインスタンス化する
model = get_model()
# プロンプトに入力テキストを入力
complete_prompt = get_prompt(input_text)
# LLMから結果を取得
generated_response = model.generate(prompt=complete_prompt)
response_text = generated_response['results'][0]['generated_text']
# print model response
# モデル応答を出力します
# print("--------------------------------- Generated output -----------------------------------")
# print("Prompt: " + complete_prompt.strip())
# print("---------------------------------------------------------------------------------------------")
# print("Generated output: " + response_text)
# print("*********************************************************************************************")
return response_text
# ネイティブ Python APIのパッケージ
import modelerpy
import pandas as pd
import json
# データモデルの参照時
if modelerpy.isComputeDataModelOnly():
modelerDataModel = modelerpy.getDataModel()
outputDataModel = None
# Compute output data model here
# 出力データモデルの設定。取得列を追加
outputDataModel = modelerDataModel
outputDataModel.addField(modelerpy.Field(fld_output, "string", measure="nominal"))
modelerpy.setOutputDataModel(outputDataModel)
# データ出力時
else:
modelerData = modelerpy.readPandasDataframe()
outputData = modelerData
# スコアリング
# LLM生成。戻り値はpd.Series
#outputData[fld_output]='DUMMY'
#print(modelerData[fld_input].apply(get_output))
outputData[fld_output]=modelerData[fld_input].apply(get_output)
print(outputData)
# データの出力
modelerpy.writePandasDataframe(outputData)
4.テスト実行
「テーブル」ノードを接続して実行するとスマホの製品レビューから分類された「感情」が、期待通りにModelerの列に取得できています。
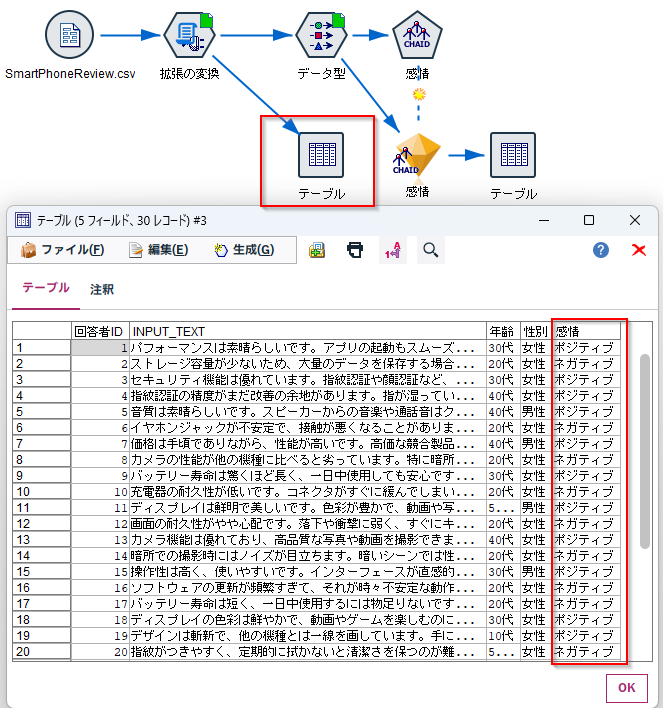
5. モデル作成
「データ型」ノードを接続して、「値の読み込み」を行い、「ロール」を設定します。「年齢」と「性別」から「感情」を予測するという設定です。
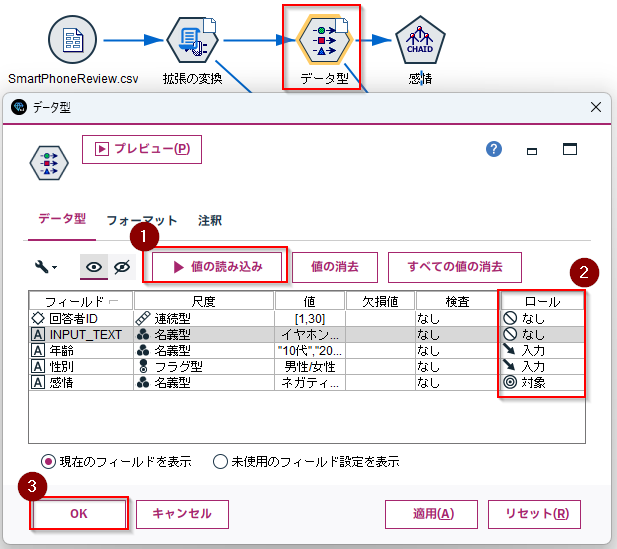
「CHAID」ノードを接続して、右クリックで実行します。
6. モデル内容確認
出来上がったモデルナゲットを右クリック「編集」で開きます。
「ビューアー」タブにうつり、「度数情報を表とグラフで表示」をクリックします。
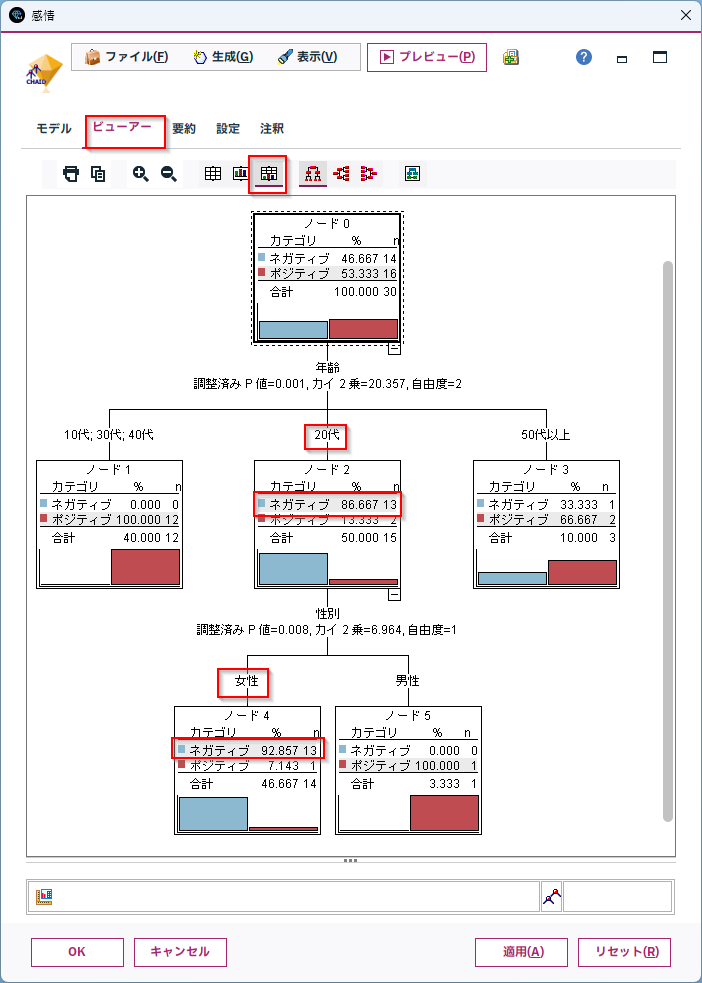
全体としてはポジティブとネガティブが半数ですが、「20代」で「女性」ではネガティブなコメントが多いことがわかります。
このようにして、テキストデータをLLMで分類することで、構造化データとしてModelerでの分析が可能になりました。
7.コードの確認
Pythonからのwatsonx.aiの利用方法についてはこの記事で説明していますので、Modelerと連携部分を説明します。
以下で入力列と出力列を定義しています。
fld_input = 'INPUT_TEXT'
fld_output = '感情'
以下で、データモデルを定義しています。
if modelerpy.isComputeDataModelOnly():
modelerDataModel = modelerpy.getDataModel()
outputDataModel = None
# Compute output data model here
# 出力データモデルの設定。取得列を追加
outputDataModel = modelerDataModel
outputDataModel.addField(modelerpy.Field(fld_output, "string", measure="nominal"))
modelerpy.setOutputDataModel(outputDataModel)
modelerpy.getDataModel()で入力データのデータモデルを取得しています。ここでは「回答者ID」、「INPUT_TEXT」、「年齢」、「性別」列の情報を取得しています。
outputDataModel.addField(modelerpy.Field(fld_output, "string", measure="nominal"))で最初に定義した出力列である「感情」をstring型の名義型で定義しています。
以下で、出力データを作っています。
else:
modelerData = modelerpy.readPandasDataframe()
outputData = modelerData
# スコアリング
# LLM生成
outputData[fld_output]=modelerData[fld_input].apply(get_output)
print(outputData)
# データの出力
modelerpy.writePandasDataframe(outputData)
modelerData[fld_input].apply(get_output)でwatsonx.aiに「INPUT_TEXT」のスマホの製品レビューを渡して、「ポジティブ」や「ネガティブ」の文字列を得ています。
参照
watsonx.aiで日本語文からの固有表現抽出(プロンプト・ラボ編) #watsonx.ai - Qiita
watsonx.aiで日本語文からの固有表現抽出(Python編) #Python - Qiita