watsonx.aiで、日本語文からの項目抽出(Entity Extraction)を行います。LLMにはIBMのgranite-8b-japaneseを使ってみます。プロンプト・ラボでやったことのPython版になります。プロジェクトの準備までは同じ手順になりますので、プロジェクトを作成しておいてください。
具体的には以下のような保険請求文書から、車両タイプと車種、日付、時間帯と場所の情報をJSONで抽出して、PadasのDataFrameにしてみます。
保険請求文書:
ハイブリッドセダン型車両、トヨタプリウス、2024年2月15日午後3時頃、
神奈川県横浜市の都市部の交差点で信号待ち中に後方から追突され、
後部バンパーが損傷しました。
追突事故により、車両の後部パネルにもひびが入り、修理が必要です。
保険金の支払いを申請します。
JSON:
{"車両タイプ": "ハイブリッドセダン型車両",
"車種": "トヨタプリウス",
"日付": "2024年2月15日",
"時間帯": "午後3時頃",
"場所": "神奈川県横浜市"}
- テスト環境
- watsonx.ai (クラウド)
- python:3.10.9
- ibm_watson_machine_learning:1.0.353
APIキーとプロジェクトIDの取得
APIキーの作成
watsonxのハンバーガーメニューから「アクセス(IAM)」にアクセスします。

「APIキー」を選び「作成」クリックします。

適当な名前をつけて「作成」します。

「コピー」や「ダウンロード」をして保存しておいてください。

プロジェクトID取得
プロジェクトに入り、「管理」タブの「一般」を選び、「プロジェクト ID」をコピーします。

Jupyter Notebookからの実行
Jupyter Notebookで実行してみます。
watsonxの上のJupyterでも実行できますし、VS Codeなどから手元のPC環境でも実行できます。
まずpipでibm-watson-machine-learningのパッケージを導入しておいてください。
pip install ibm-watson-machine-learning
ibm-watson-machine-learningから必要なモジュールをインポートします。
from ibm_watson_machine_learning.foundation_models import Model
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes, DecodingMethods
プロジェクトID、APIキーは先ほど取得したものを入力します。
#プロジェクトID
watsonx_project_id = "xxxxxxxxxxxxxxxx"
#APIキー
api_key = "xxxxxxxxxxx"
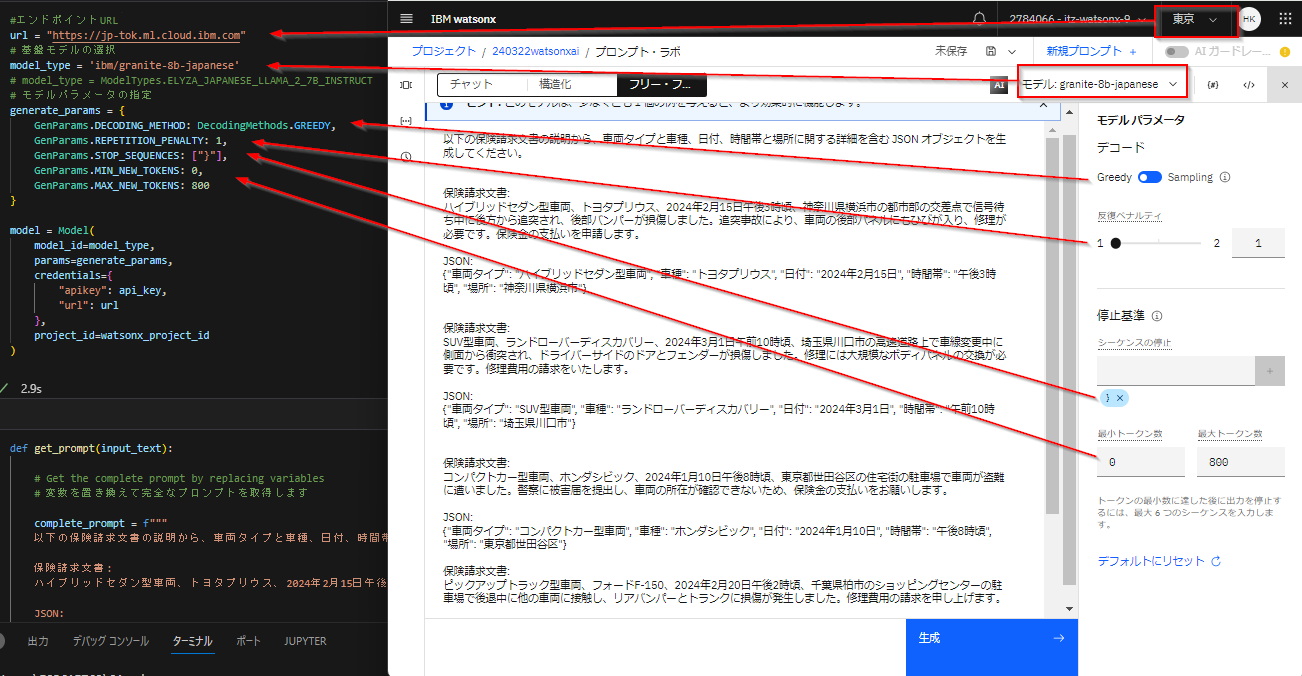
エンドポイントURLはリージョンに合わせて以下から選びます。ここではgranite-8b-japaneseモデルを使いたいので、東京リージョンのエンドポイントURLを選んでいます。
url = "https://jp-tok.ml.cloud.ibm.com"
基盤モデルを選択しています。
ModelTypesは以下で定義されています。
ただ、ibm-watson-machine-learning-1.0.353では、まだgranite-8b-japaneseが定義されていなかったので、model_type = 'ibm/granite-8b-japanese'で文字列で定義しています。
サポートされているモデルは以下に掲載されています。
model_type = 'ibm/granite-8b-japanese'
# model_type = ModelTypes.ELYZA_JAPANESE_LLAMA_2_7B_INSTRUCT
次にモデルパラメーターを設定していきます。
次のパラメーターを指定しています。以下に定義があります。
各パラメーターの意味は以下です。
generate_params = {
GenParams.DECODING_METHOD: DecodingMethods.GREEDY,
GenParams.REPETITION_PENALTY: 1,
GenParams.STOP_SEQUENCES: ["}"],
GenParams.MIN_NEW_TOKENS: 0,
GenParams.MAX_NEW_TOKENS: 800
}
model = Model(
model_id=model_type,
params=generate_params,
credentials={
"apikey": api_key,
"url": url
},
project_id=watsonx_project_id
)
プロンプト・ラボとの対応は以下のようになります。
プロンプトを作成します。
ここではFew shotでプロンプトを作っています。つまり「保険請求文書」と「JSON」の例をいくつか用意しています。そして最終的に結果を得たい「保険請求文書」を{input_text}で与えるようにしています。このように関数化することで、複数の「保険請求文書」に対して繰り返して処理を行うことも可能にしています。なおf-stringで記述しているのでJSONにある「{」は「{{」でエスケープしています。
def get_prompt(input_text):
# Get the complete prompt by replacing variables
# 変数を置き換えて完全なプロンプトを取得します
complete_prompt = f"""
以下の保険請求文書の説明から、車両タイプと車種、日付、時間帯と場所に関する詳細を含む JSON オブジェクトを生成してください。
保険請求文書:
ハイブリッドセダン型車両、トヨタプリウス、2024年2月15日午後3時頃、神奈川県横浜市の都市部の交差点で信号待ち中に後方から追突され、後部バンパーが損傷しました。追突事故により、車両の後部パネルにもひびが入り、修理が必要です。保険金の支払いを申請します。
JSON:
{{"車両タイプ": "ハイブリッドセダン型車両", "車種": "トヨタプリウス", "日付": "2024年2月15日", "時間帯": "午後3時頃", "場所": "神奈川県横浜市"}}
保険請求文書:
SUV型車両、ランドローバーディスカバリー、2024年3月1日午前10時頃、埼玉県川口市の高速道路上で車線変更中に側面から衝突され、ドライバーサイドのドアとフェンダーが損傷しました。修理には大規模なボディパネルの交換が必要です。修理費用の請求をいたします。
JSON:
{{"車両タイプ": "SUV型車両", "車種": "ランドローバーディスカバリー", "日付": "2024年3月1日", "時間帯": "午前10時頃", "場所": "埼玉県川口市"}}
保険請求文書:
コンパクトカー型車両、ホンダシビック、2024年1月10日午後8時頃、東京都世田谷区の住宅街の駐車場で車両が盗難に遭いました。警察に被害届を提出し、車両の所在が確認できないため、保険金の支払いをお願いします。
JSON:
{{"車両タイプ": "コンパクトカー型車両", "車種": "ホンダシビック", "日付": "2024年1月10日", "時間帯": "午後8時頃", "場所": "東京都世田谷区"}}
保険請求文書:
ピックアップトラック型車両、フォードF-150、2024年2月20日午後2時頃、千葉県柏市のショッピングセンターの駐車場で後退中に他の車両に接触し、リアバンパーとトランクに損傷が発生しました。修理費用の請求を申し上げます。
JSON:
{{"車両タイプ": "ピックアップトラック型車両", "車種": "フォードF-150", "日付": "2024年2月20日", "時間帯": "午後2時頃", "場所": "千葉県柏市"}}
保険請求文書:
{input_text}
JSON:
"""
return complete_prompt
以下で生成を実行しています。「ステーションワゴン型車両、スバルアウトバック・・・」の文書からJSONで固有表現を抽出します。
model.generateにプロンプトを入れているだけです。
# プロンプトに入力テキストを入力
complete_prompt = get_prompt('ステーションワゴン型車両、スバルアウトバック、2024年1月5日午後4時頃、神奈川県横須賀市で自宅近くの道路で大雨による洪水が発生し、浸水によりエンジンと電子システムに損傷が発生しました。保険金のお支払いをお願いします。')
# LLMから結果を取得
generated_response = model.generate(prompt=complete_prompt)
response_text = generated_response['results'][0]['generated_text']
import pprint
pprint.pprint(generated_response)
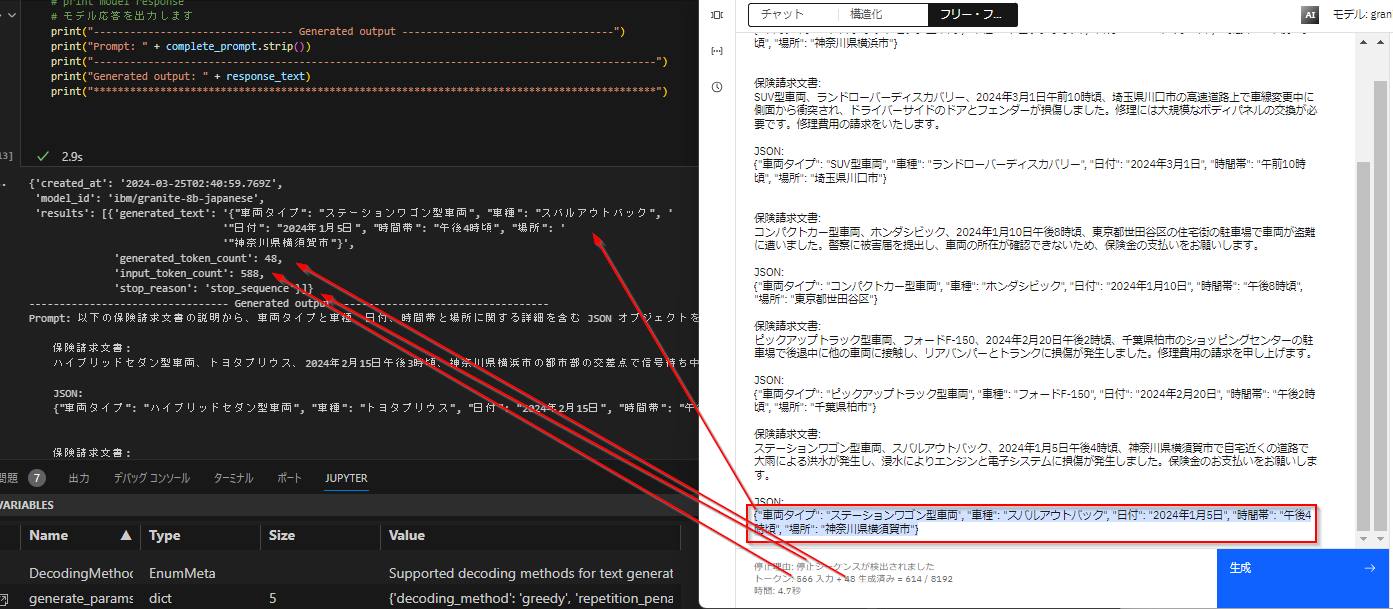
generated_responseはdict型になっていて、この'results'の中に結果が含まれています。うまくJSONに抽出できていることがわかります。
{'created_at': '2024-03-25T02:40:59.769Z',
'model_id': 'ibm/granite-8b-japanese',
'results': [{'generated_text': '{"車両タイプ": "ステーションワゴン型車両", "車種": "スバルアウトバック", '
'"日付": "2024年1月5日", "時間帯": "午後4時頃", "場所": '
'"神奈川県横須賀市"}',
'generated_token_count': 48,
'input_token_count': 588,
'stop_reason': 'stop_sequence'}]}
実行したプロンプトと生成結果を出力してみます。
print("--------------------------------- Generated output -----------------------------------")
print("Prompt: " + complete_prompt.strip())
print("---------------------------------------------------------------------------------------------")
print("Generated output: " + response_text)
print("*********************************************************************************************")
--------------------------------- Generated output -----------------------------------
Prompt: 以下の保険請求文書の説明から、車両タイプと車種、日付、時間帯と場所に関する詳細を含む JSON オブジェクトを生成してください。
保険請求文書:
ハイブリッドセダン型車両、トヨタプリウス、2024年2月15日午後3時頃、神奈川県横浜市の都市部の交差点で信号待ち中に後方から追突され、後部バンパーが損傷しました。追突事故により、車両の後部パネルにもひびが入り、修理が必要です。保険金の支払いを申請します。
JSON:
{"車両タイプ": "ハイブリッドセダン型車両", "車種": "トヨタプリウス", "日付": "2024年2月15日", "時間帯": "午後3時頃", "場所": "神奈川県横浜市"}
保険請求文書:
SUV型車両、ランドローバーディスカバリー、2024年3月1日午前10時頃、埼玉県川口市の高速道路上で車線変更中に側面から衝突され、ドライバーサイドのドアとフェンダーが損傷しました。修理には大規模なボディパネルの交換が必要です。修理費用の請求をいたします。
JSON:
{"車両タイプ": "SUV型車両", "車種": "ランドローバーディスカバリー", "日付": "2024年3月1日", "時間帯": "午前10時頃", "場所": "埼玉県川口市"}
保険請求文書:
コンパクトカー型車両、ホンダシビック、2024年1月10日午後8時頃、東京都世田谷区の住宅街の駐車場で車両が盗難に遭いました。警察に被害届を提出し、車両の所在が確認できないため、保険金の支払いをお願いします。
JSON:
{"車両タイプ": "コンパクトカー型車両", "車種": "ホンダシビック", "日付": "2024年1月10日", "時間帯": "午後8時頃", "場所": "東京都世田谷区"}
保険請求文書:
ピックアップトラック型車両、フォードF-150、2024年2月20日午後2時頃、千葉県柏市のショッピングセンターの駐車場で後退中に他の車両に接触し、リアバンパーとトランクに損傷が発生しました。修理費用の請求を申し上げます。
JSON:
{"車両タイプ": "ピックアップトラック型車両", "車種": "フォードF-150", "日付": "2024年2月20日", "時間帯": "午後2時頃", "場所": "千葉県柏市"}
保険請求文書:
ステーションワゴン型車両、スバルアウトバック、2024年1月5日午後4時頃、神奈川県横須賀市で自宅近くの道路で大雨による洪水が発生し、浸水によりエンジンと電子システムに損傷が発生しました。保険金のお支払いをお願いします。
JSON:
---------------------------------------------------------------------------------------------
Generated output: {"車両タイプ": "ステーションワゴン型車両", "車種": "スバルアウトバック", "日付": "2024年1月5日", "時間帯": "午後4時頃", "場所": "神奈川県横須賀市"}
*********************************************************************************************
プロンプト・ラボとの対応は以下のようになります。
最後にJSONをpandasのDataFrameに変換しています。

import pandas as pd
import json
df = pd.DataFrame(json.loads(response_text), index=[0])
print(df)
参考 JSON文字列をPandas DataFrameにロードする
サンプルプログラム
参考
watsonx.aiで日本語文からの項目抽出(プロンプト・ラボ編)