SPSS Modelerで重複レコードをまとめるのが重複ノードです。この重複ノードを解説するとともに、Pythonのpandasで書き換えてみます。
重複ノードは、文字通り完全に重複したレコードを削除することにも使えますが、Modelerで使う場合には、グループ化したなかでの1番目のレコードを取得するために使うことが多いと思います。
そのためここではID付POSデータをつかって、以下の2つのユースケースで解説します。
①最初に購入したアイテムの特定
②商品カテゴリ内の売上1位アイテムの特定
0.元データ
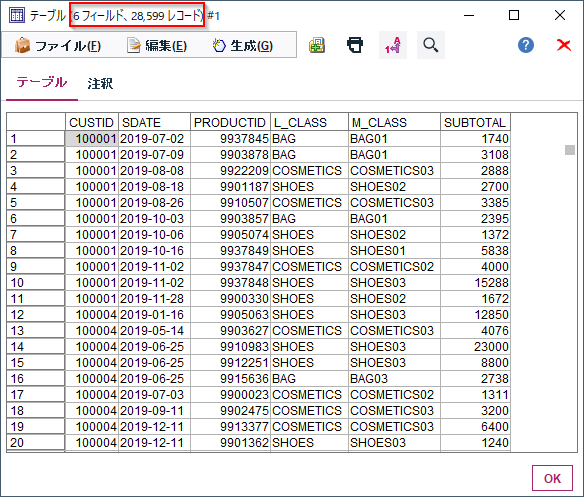
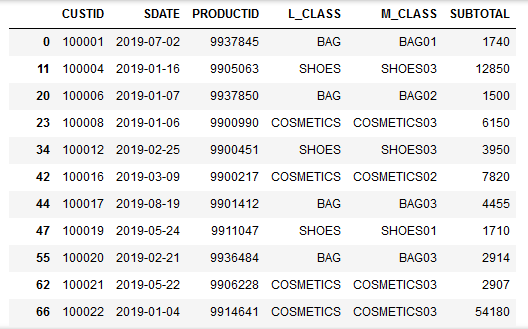
以下のID付POSデータを対象に行います。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
6フィールド、28,599件あります。
1m.①最初に購入したアイテムの特定 Modeler版
最初に購入したものでその後の購買行動がわかってくることがあったりします。最初にある商品を買った人は優良顧客になりやすい、ある商品を買った人は2度目の購入がなく離反しやすいというような商品の特性がみえてくれば、優良顧客になりやすい商品が目立つような棚割りやバナー配置をするなどの方策を考えることができます。
ID付POSのデータからCUSTID毎に最初の購入トランザクションを抽出してみます。
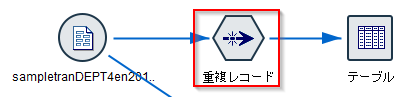
重複レコードノードのモードを「各グループの最初のレコードだけを含める」にします。
グループ化のキーフィールドはCUSTIDのみにします。これによって一つのCUSTIDに対して1レコードだけを抽出します。
「グループ内でレコードをソート」でSDATEを昇順で指定します。これでCUSTID毎にもっとも古いトランザクションが選ばれます。
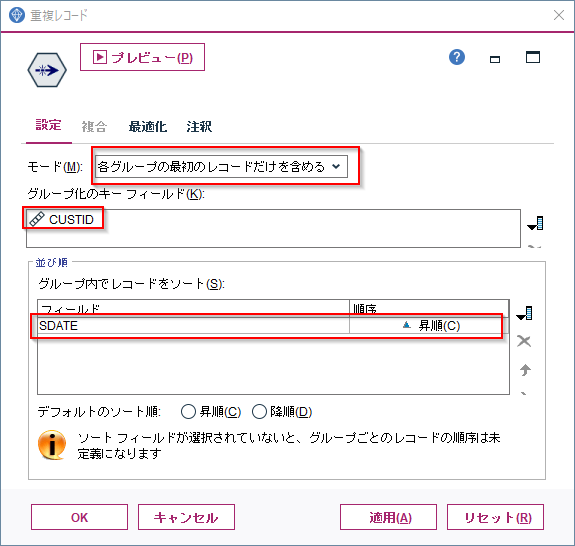
結果は以下のようになります。
100001番のCUSTIDの人が一番最初に購入したのはBAG01の9937845という商品でした。
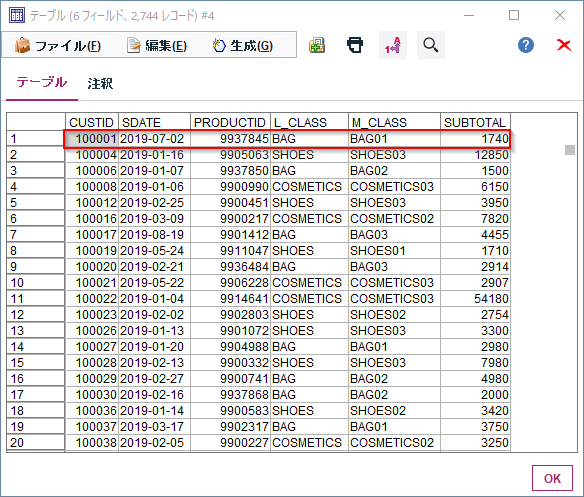
1p.①最初に購入したアイテムの特定 pandas版
pandasで重複行を1行にまとめる場合はsort_valuesとdrop_duplicates関数を使います。
まずsort_valuesで’CUSTID'毎にSDATE順に並べ替えをします。
そしてdrop_duplicatesで各CUSTID毎に先頭行のみを抽出します。subsetで’CUSTID'のみで重複を検出することがポイントです。
# CUSTIDとSDATEでソート
df_sorted=df.sort_values(['CUSTID','SDATE'])
# CUSTID毎に先頭行を抽出
df_sorted.drop_duplicates(subset='CUSTID')
- 参考
- pandas.DataFrame, Seriesの重複した行を抽出・削除 | note.nkmk.me
- https://note.nkmk.me/python-pandas-duplicated-drop-duplicates/
2m.②商品カテゴリ内の売上1位アイテムの特定 Modeler版
重複レコードノードはレコード集計ノードと合わせて、集計結果の中のナンバーワンやワーストワンのレコードを抽出することにもよく使います。
ここではBAG、COSMETICS、SHOESの商品大分類内で最も売り上げの大きい商品を抽出してみます。
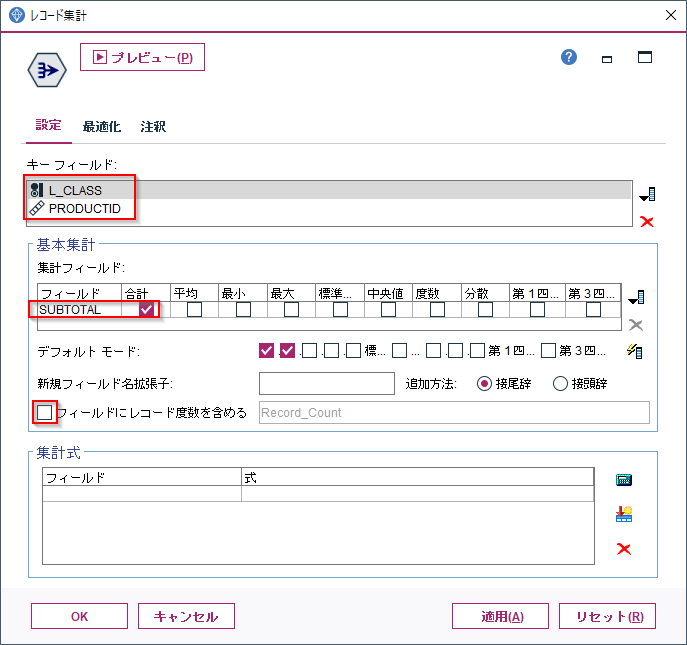
まず、レコード集計でL_CLASSとPRODUCTIDでグループ化して、SUBTOTALの合計を計算します。
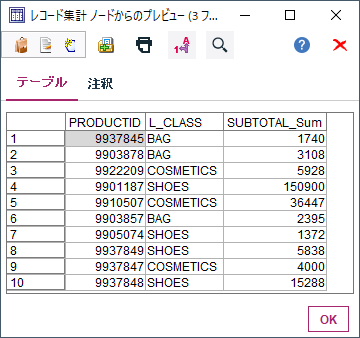
これで商品ごとの総売り上げ額が計算されました。
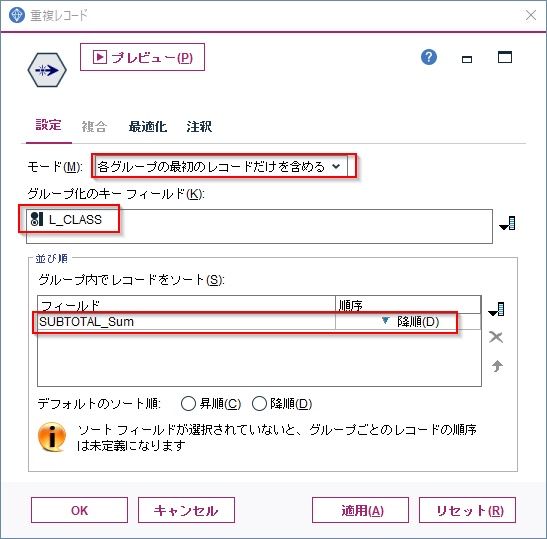
次に重複ノードで以下のように設定します。
モードを「各グループの最初のレコードだけを含める」にします。
グループ化のキーフィールドはL_CLASSのみにします。これによって一つのL_CLASSに対して1レコードだけを抽出します。
「グループ内でレコードをソート」でSUBTOTAL_Sumを昇順で指定します。これでL_CLASS毎にもっとも売り上げの大きい商品が選ばれます。
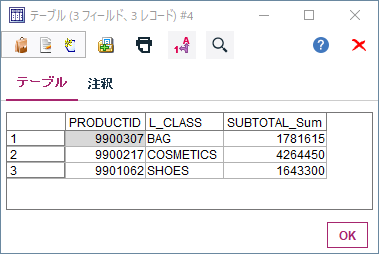
結果は以下のようになります。
BAGの中で一番売れたのはの9900307という商品で、1,781,615円の売上がありました。
2p.②商品カテゴリ内の売上1位アイテムの特定 pandas版
pandasで集計結果からナンバーワンを抽出する場合はgroupby、sort_values、drop_duplicates関数を使います。Modelerで集計ノード、重複レコードノードを使うのと同じ処理になります。
まずgroupbyでL_CLASSとPRODUCTIDでグループ化して、SUBTOTALの合計を計算します。
次にsort_valuesで’L_CLASS'毎に'SUBTOTAL'の大きい順に並べ替えをします。
そしてdrop_duplicatesで各L_CLASS毎に先頭行のみを抽出します。
# 大分類とPRODUCTIDで売上合計算出
df_sum=df[['L_CLASS','PRODUCTID','SUBTOTAL']].groupby(['L_CLASS','PRODUCTID'],as_index=False).sum()
# 大分類内で売上順にソート
df_sum_sorted=df_sum.sort_values(['L_CLASS','SUBTOTAL'],ascending=[True,False])
# 大分類の先頭行を抽出
df_sum_sorted.drop_duplicates(['L_CLASS'])
以下のように抽出できました。
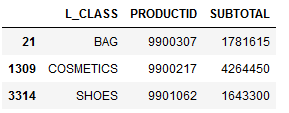
- 参考
- Pandas の groupby の使い方 - Qiita
- https://qiita.com/propella/items/a9a32b878c77222630ae
3. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/distinct/distinct.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/distinct/distinct.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.2.1
Windows 10 64bit
Python 3.6.9
pandas 0.24.1