はじめに
こんにちは!
NRI xPalette Advent Calendar 2025の14日目は、
【初心者でもできる!】KiroとAWS MCP Serversで始める、AWS CDKのSpec駆動開発体験記👻
という記事の内容でお届けします!
社会人1年目であり、AWS CDK初心者の筆者が、最近GAされ話題のKiroとMCPサーバーを用い、AIの力をフルに借りながら、CDKを実装する便利さを実感しましたので、是非この便利さを多くの方に知って欲しいと考え、記事にまとめさせていただきました!
この記事を読み、KiroとAWS MCP Serversを用いれば初心者でもCDKによるインフラ管理ができそう!と少しでも思ってもらえたら幸いです!
想定している読者
この記事は以下のような人を読者として想定しています。
- CDK初心者であるが、CDKでインフラ管理してみたい
- Kiroについての理解を深めたい
- AWSをIaC管理する時に有用なMCPサーバーとその使い方を知りたい
この記事で書くこと・書かないこと
書くこと
- CDKの基礎知識
- Kiroの基礎知識
- 実際に使用したMCPサーバー
- Kiroの使用方法
- Kiroを用いてCDKを実装する作業過程
- Kiroを用いてCDKを実装する利点
書かないこと
- 詳細な環境構築方法
- CDKの設計、応用的な知識
- MCPサーバーの仕組み
- KiroのAPIリファレンスの網羅
CDKについて
CDKとは
AWS Cloud Development Kit (AWS CDK) は、TypeScriptやPythonなどのプログラミング言語を用いてインフラ構成を定義できるフレームワークです。TypeScriptなどで書いたコードを、AWS CDKがCloudFormationテンプレートに変換し、AWSへデプロイしてくれます。
CDKの利点
CDKには、開発者が書き慣れた言語でインフラを実装できること以外にも、以下のような大きなメリットが存在します。
プログラミング言語の恩恵を受けられる
CDKは前述の通り、一般的なプログラミング言語を用いて開発するため、変数、条件分岐、ループ処理など普段使用している言語の機能を用いて開発ができます。
型安全性と補完機能
TypeScriptなど、型定義がしっかりしている言語を使う場合、IDE(Kiroを含む)による強力な型補完が効きます。また、この型補完はAIにとっても正しいコードを生成するための評価指標となるため、AI時代における開発スタイルにも非常にマッチしています。
抽象化
筆者がCDKを用いて最も感動したポイントです。
CDKには異なる抽象化レベルで、複数のConstruct(構成要素)が用意されています。
- CloudFormationと1対1対応してリソースを定義できる、L1 Construct
- AWSの基本的なベストプラクティスに沿って少ない記述量でリソースを定義(抽象化)できるL2 Construct
- 一般的なアーキテクチャパターンに従って、リソースが組み合わされたタスク群を提供するL3 Construct
公式ドキュメントには Fargate で ECSを起動する例として、以下のようなコードが提示されています。
export class MyEcsConstructStack extends Stack {
constructor(scope: App, id: string, props?: StackProps) {
super(scope, id, props);
const vpc = new ec2.Vpc(this, "MyVpc", {
maxAzs: 3 // Default is all AZs in region
});
const cluster = new ecs.Cluster(this, "MyCluster", {
vpc: vpc
});
// Create a load-balanced Fargate service and make it public
new ecs_patterns.ApplicationLoadBalancedFargateService(this, "MyFargateService", {
cluster: cluster, // Required
cpu: 512, // Default is 256
desiredCount: 6, // Default is 1
taskImageOptions: { image: ecs.ContainerImage.fromRegistry("amazon/amazon-ecs-sample") },
memoryLimitMiB: 2048, // Default is 512
publicLoadBalancer: true // Default is false
});
}
}
この実装だけでなんと 500 行を超える AWS CloudFormation テンプレートが生成され、VPC周りの設定からECSまで基本的な設定を全て裏でベストプラクティスに沿ってデプロイしてくれます。
さらに、抽象化の利点は実装量の削減だけではありません。
Lambda関数に特定のS3バケットへの読み取り権限を与えたい、そんなケースは開発していて頻繁に生じます。CDKでは最小権限に従って、上記の要件を以下の1行で宣言できます。(lambdaFunctionは定義済みと想定)
bucket.grantRead(lambdaFunction);
これにより、権限をより宣言的に、かつリソースの定義に近い場所で記述できるようになり、リソースと権限の関係を直感的に理解しやすくなります。
他にも、CDKの魅力や実装にあたって知っておいた方が良いことはたくさんあるのですが、筆者もお世話になったCDK初学者が読むべき資料をまとめてくれている有り難すぎる記事がございますので、気になった方は是非こちらをご参照していただけますと幸いです。
Kiroについて
2025年11月18日にAWSのAI コーディングツールKiroがGAされました。![]()
このタイミングで、従来プレビュー版としてローンチされていたKiro IDEだけでなく、Q Developer CLIがKiro CLIに変更されたりしていますので、改めて基本的な特徴について以下にまとめていきます。
以下の情報は2025年11月末時点での情報です。
最新の情報につきましては別途公式サイトをご確認ください。
Amazon Q Developerとは
Kiroについてまとめる前に、Amazon Q Developerで何ができたのか、また何がKiroに置き換わったのかについて整理します。
Amazon Q Developerは、AWSでの開発ライフサイクル全体を支援するために設計された、生成AIアシスタントサービスであり、以下の機能を有しています。
-
IDEでの支援
VS Codeなどのエディタに拡張機能としてインストールし、コードの自動生成、チャットでの質問、セキュリティスキャンなどを行う -
CLIでの支援
ターミナルで q コマンドを使用し、自然言語でシェルコマンドを生成したり、CLIツールの補完を行う -
AWSマネジメントコンソールでの支援
AWSのWebコンソール上で、エラー原因の診断など、ユーザーの運用をサポートする
今回のKiroのGAに合わせて、1及び2で提供されていたコーディング支援がKiro IDE、Kiro CLIにリブランディングされました。
Kiroの料金・登録方法
では、Kiroによる開発を始めるにはどのように登録するべきなのでしょうか。
Kiroを一旦試しに利用してみたい、と言うことでしたらフリープランでも新規でサインインしたアカウントに対し、30日間限定の 500 クレジットが提供されます。皆さん、まずはこの 500 クレジットを使って存分に遊んでみましょう。
料金プランは以下のようになっています。
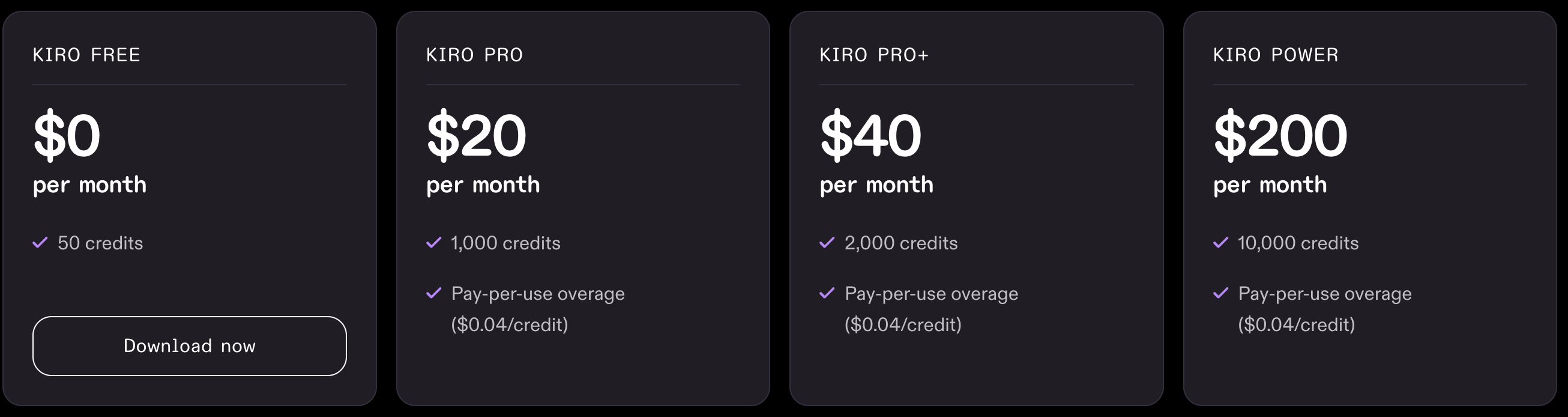
Kiroのサブスクリプションプランは、Q Developerと独立しているものの、Q Developer Proプランと提供機能が重複しており、違いが分かりにくくなっています。
Kiroのプランごとの詳細、またQ Developer Proとの違いについては以下の素晴らしい記事にわかりやすくまとまっています。
上記の記事を読みお気づきの方も多いと思いますが、現状はQ Developer ProプランがKiroのProプランを内包しており、かつマネジメントコンソールでの支援を含む機能が備わっていますのでAWSアカウントを持っている方であれば、Q Developer Proプランで登録するのも選択肢の一つです。
なお、クレジット量についてはKiro 導入ガイドより、Q Developer Proプランは「KiroのProプラン相当」であるとされています。
重複しますが、2025年11月末時点の情報であり、今後はKiroプランでのサブスクリプションが強く推奨されていくと思われます。
参考に、筆者がQ Developer Proプランに登録した手順を以下に示します。
まず、一番の注意ポイントですが、現状Builder IDでのQ Developer Proプランへの導線は閉じられており、Kiro Proプランへのサブスクリプションにリダイレクトされます。
そのため、Q Developer Proプランは個人アカウントであっても、IAM Identity Centerから行う必要があります。
Q Developer Pro プランへの登録は IAM Identity Center から行う必要がある一方、Kiro の各種プランは Builder ID に加えて、Google アカウントや GitHub アカウントからも登録できます。
まず、マネジメントコンソールでKiroを検索し、Kiroのページを開きます。
そこで、下記画像の「Enable Q Developer」をクリックし、新規のユーザーを作成します。
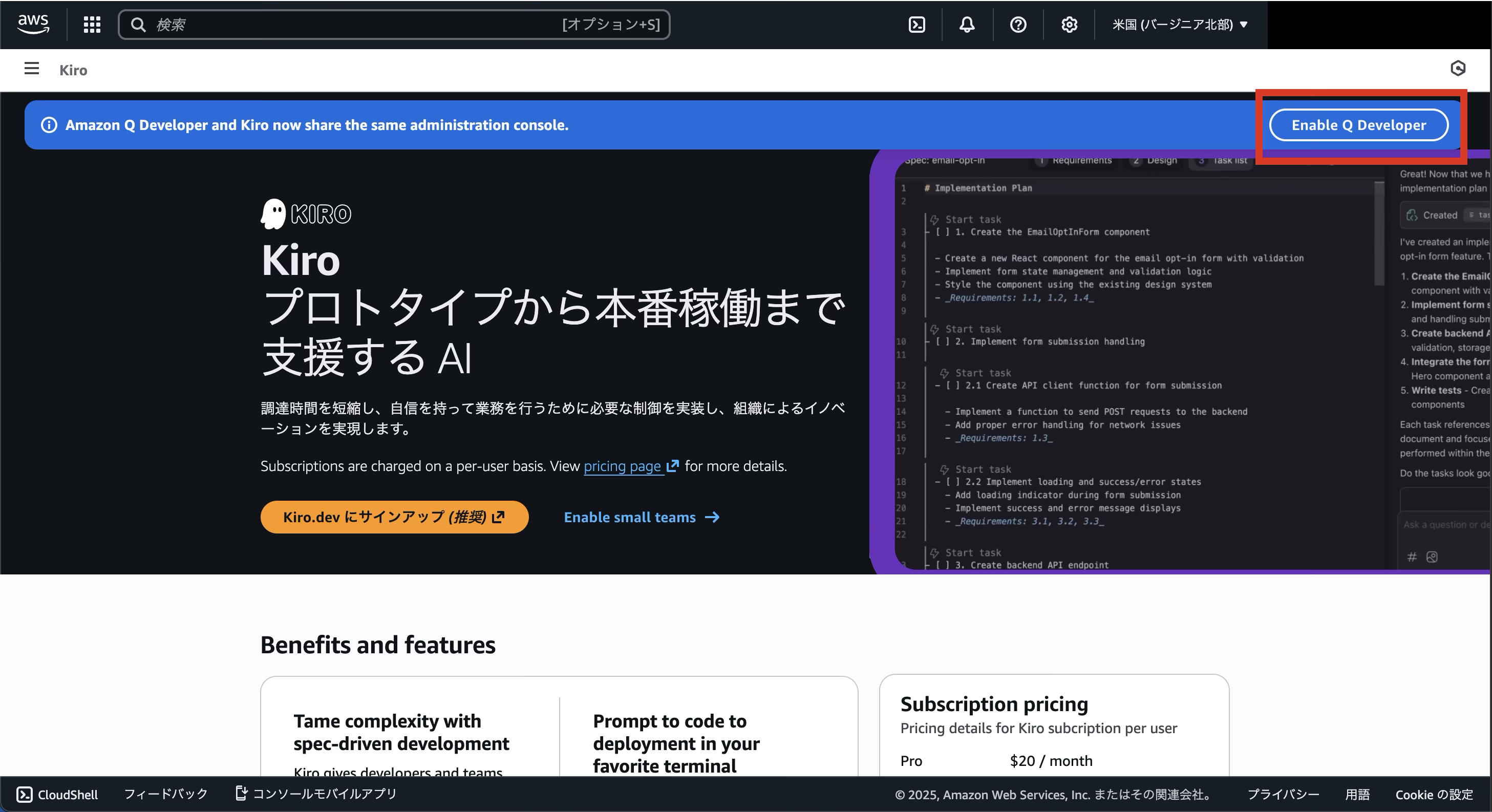
すると、自動でIAM Identity Centerが有効化され、先ほど登録したユーザーが作成されています。
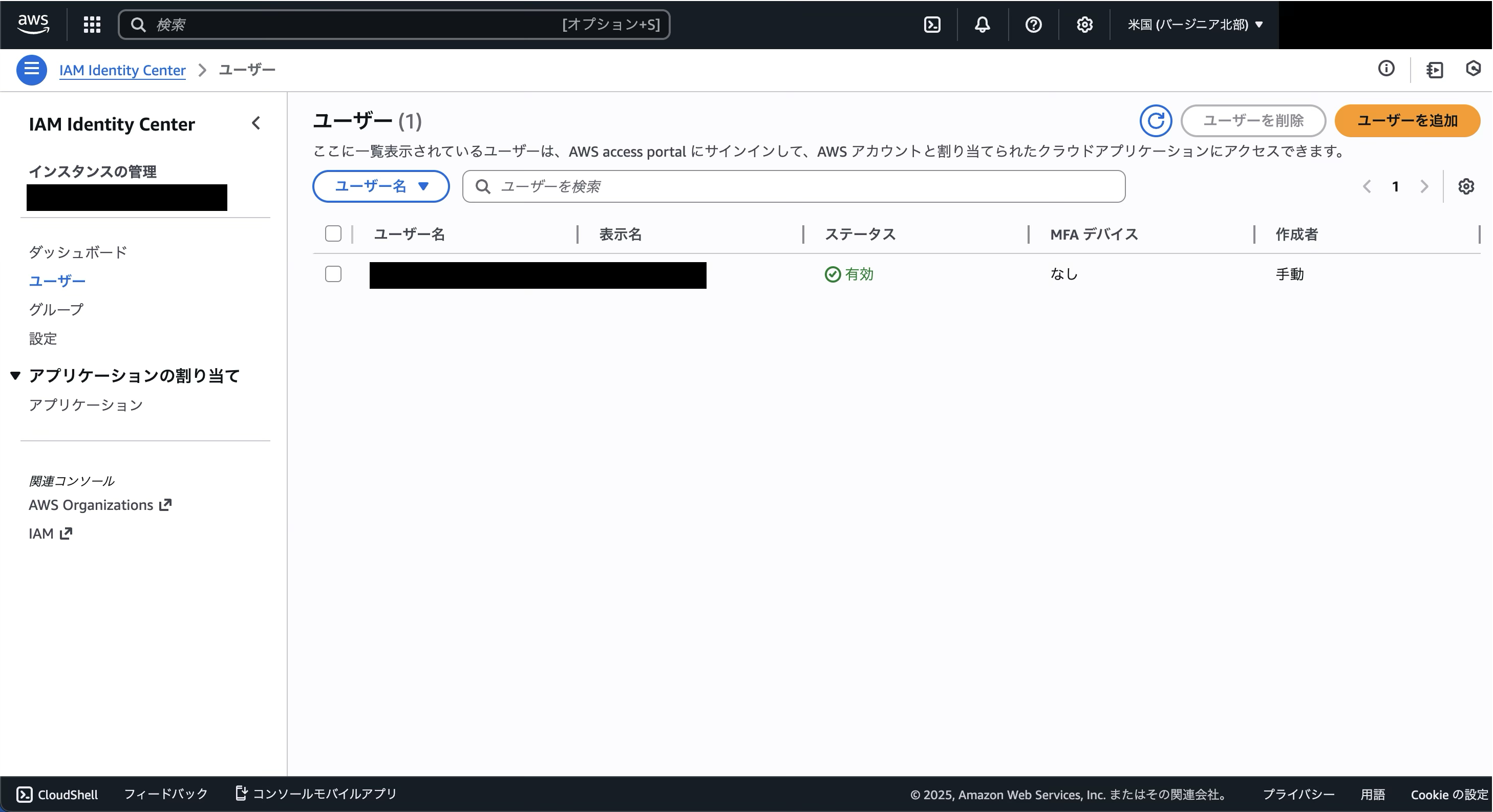
もう一度Kiroに戻り、先ほどの「Enable Q Developer」をクリックし、「有効にする」ボタンを押します。すると、「Q Developer Proをユーザー1人あたり19ドルで有効にする」ボタンが出るので、それをクリックします。
その後、サブスクリプションにユーザーを登録すれば完了です。
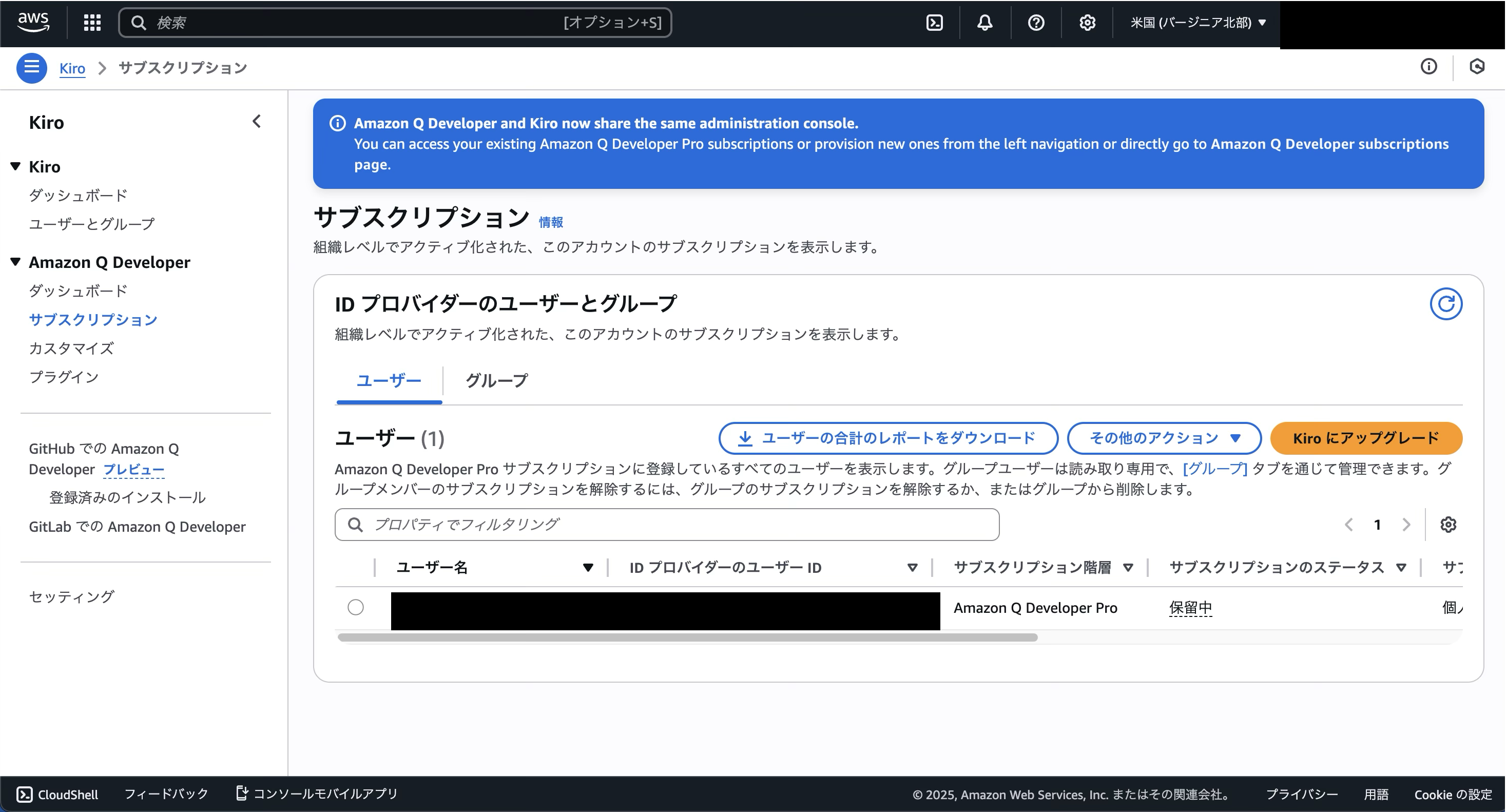
KiroにはIdentity Center経由でログインするようにしましょう!
Kiroの特徴
続いて、Kiroの特徴についてです。
前述している通り、KiroにはKiro IDEとKiro CLIがありますが、基本的なコンセプトはどちらも一致しています。
Kiro IDEは、VS CodeをベースとしたAIエージェント型IDEです。
コード補完やチャット、インラインでの編集指示、MCPサーバーとの統合といった、CursorやGitHub Copilotなどを通じて標準的になった機能は一通り備わっています。
Kiro CLIはターミナル上で動作するAIエージェントです。IDEと同様に、従来のClaude Codeなどが有する基本的なAIエージェントとしての機能が備わっています。
既存のAIツールと比較した時のKiroの特徴的な機能は以下の二点です。
Spec
KiroはSpecモードを有しており、ユーザーが与えた指示に基づきSpecと言われる仕様書を、「要件定義 → 設計 → 実装計画」という3段階のプロセスを経て作成します。
KiroでSpecを作成すると、主に以下の3つのMarkdownファイルが生成され、Kiroはこれらのファイルを開発中に参照します
-
requirements.md(要件定義書) -
design.md(設計書) -
tasks.md(実装タスク計画書)
またKiroは「AIによって書かれたコードが本当に仕様通りか?」を確認するために、プロパティベーステストが導入されています。
requirements.md から自動的にテスト可能なプロパティを抽出し、テストを自動生成して実行し、実装が意図と一致しているかを検証します。
文字上ではそれぞれの役割がいまいちわかりにくいですが、後半の体験記パートでそれぞれの成果物について確認してきます。
Hook
Hookは、ファイルの保存や作成などのイベントをトリガーにして、AIエージェントがバックグラウンドで自律的にタスクを実行する機能です。
Hookは、どのようなタイミングでエージェントを起動するかイベントタイプを定義できます。
- File Created (ファイル作成時)
- File Saved / Modified (ファイル保存/変更時)
- File Deleted (ファイル削除時)
- Manual Trigger (手動トリガー)
公式サイトには以下のような利用例が挙げられています。
-
テストの自動化
src/*.tsを保存した際、対応するtest/*.test.tsを探し、新しいロジックに対するテストケースを追加・更新し、テストを実行してパスするか確認する -
ドキュメントの最新化
関数やAPIを変更した際、JSDocや README.md の記述を自動的に書き換える -
セキュリティスキャン
コミット前や保存時に、コード内にAPIキーやパスワードがハードコードされていないか、脆弱性がないかをチェックする -
クリーンアップ
コンポーネントファイルを削除した際、プロジェクト全体をスキャンして、そのコンポーネントを参照しているインポート文を削除またはコメントアウトする
Hookについても、詳細な利用例は後半のパートで触れていきます。
MCPサーバーについて
CDKと相性が良いAWS MCP Serversの紹介
今回のCDK実装では、AWSによって提供されている専用のMCPサーバー群である、AWS MCP Serversを用いていきます。
今回は以下の4つを利用していきますが、同時に登録するMCPサーバーは3つまでとし、フェーズごとにMCPサーバーを入れ替えていきます。
- AWS Knowledge MCP Server
- AWS Diagram MCP Server
- AWS Well-Architected Security Assessment Tool MCP Server
- AWS CDK MCP Server
KiroにMCPサーバーを組み込む
では、上記のMCPサーバーを実際にKiroに登録していきます。
AWS MCP serversの公式ドキュメントではKiroにMCPサーバーを組み込む例を紹介してくれています。とてもありがたいですね。
Kiroの公式ドキュメントに従って、 kiro ~/.kiro/settings/mcp.jsonでユーザーのKiroの設定ファイルを開きます。
今回は、フェーズにより有効化するMCPサーバーを選択するため、一旦aws-knowledge-mcp-server以外のMCPサーバーを"disabled": true,としています。
aws-knowledge-mcp-serverはどのフェーズにおいても必要と考え、常に"disabled": true,のまま実装を進めていきます。
{
"mcpServers": {
"aws-knowledge-mcp-server": {
"url": "https://knowledge-mcp.global.api.aws",
"type": "http",
"disabled": false
},
"awslabs.cdk-mcp-server": {
"command": "uvx",
"args": ["awslabs.cdk-mcp-server@latest"],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR",
"AWS_PROFILE": "default",
"AWS_REGION": "us-east-1"
},
"disabled": true,
"autoApprove": []
},
"awslabs.aws-diagram-mcp-server": {
"command": "uvx",
"args": ["awslabs.aws-diagram-mcp-server@latest"],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR",
"AWS_PROFILE": "default",
"AWS_REGION": "us-east-1"
},
"disabled": true,
"autoApprove": []
},
"well-architected-security-mcp-server": {
"command": "uvx",
"args": [
"--from",
"awslabs.well-architected-security-mcp-server",
"well-architected-security-mcp-server"
],
"env": {
"AWS_PROFILE": "default",
"AWS_REGION": "ap-northeast-1",
"FASTMCP_LOG_LEVEL": "ERROR"
},
"disabled": true
}
}
}
AWSに関する質問をしてみて、MCPサーバーが実際に呼び出されることを確認したら準備完了です。
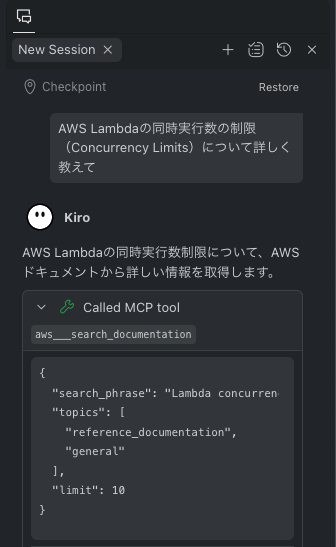
デプロイするアプリの紹介
今回、SPAのフロントエンドとサーバレスで実装するAPIを用いて、「架空の日記」を生成するアプリを検証用にAWS上にデプロイしていきます。
このアプリは、AIが生成した日記を見られる簡易的なアプリです。ユーザーはログインして日付を選択するとAIが生成したその日の日記を閲覧することができます。
この記事ではCDKの実装がメインのため、フロントエンドの詳細は控えさせていただきますが、簡単にFigma Makeを使用してアプリの見た目を作成しました。
イメージ図は以下の通りです。
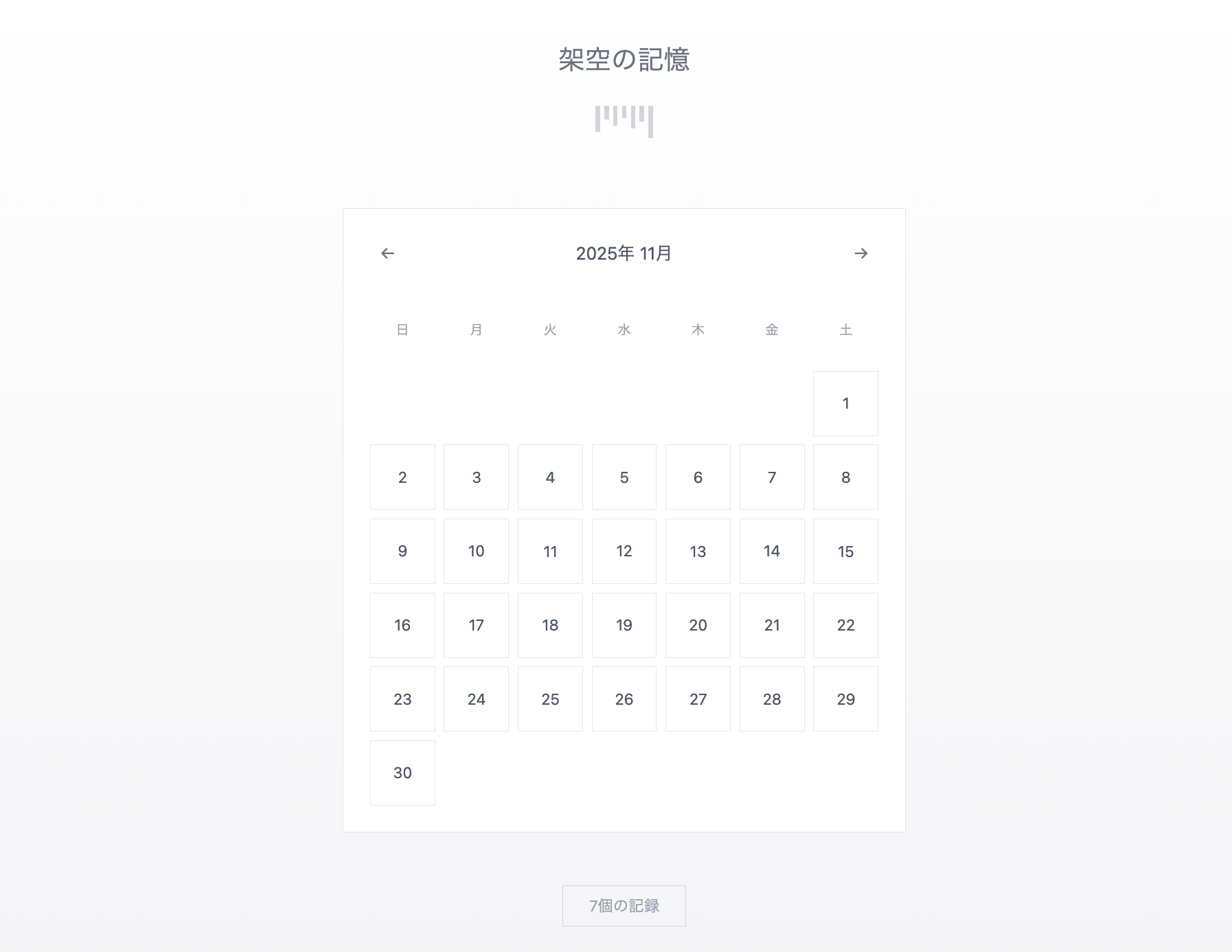

こちらを実際にCDKで実装する静的ホスティング環境にデプロイし、サーバレスで実装するAPIと組み合わせ動作確認をしていきます。
Step 1 - Kiroと一緒にインフラ要件を整理する
実装にあたり、最大限Kiroを有効に使用する方法を調査しておりますが、当記事で紹介している開発手法や実装の流れが絶対のベストプラクティスでないことはご留意いただけますと幸いです。
上記の要件から実際にCDKの開発を開始していきます。
CDKのMCPサーバーに問い合わせてほしいため、awslabs.cdk-mcp-serverを"disabled": false,にします。
まず、開発において準拠させたいルールをSteeringファイルに保存します。
SteeringファイルはKiroが開発する際の規約となるファイルです。
今回は最低限の要件だけKiroに伝え、Kiro自身にSteeringファイルを作成させました。
Steeringファイル全体を載せることは省略いたしますが、
-
cdk destroy一発ですべてのリソースがきれいに削除されるようRemovalPolicy.DESTROYを設定すること - 開発環境では最小限のリソースを使用すること
- 全リソースへの一貫したタグをつけること
- Spec の記述は日本語で行うこと(レビューの可読性を優先するため)
などを指定しました。
次に、上記のアプリの要件と事前に計画していたインフラ構成をGeminiに投げ、KiroのSpecを生成するプロンプトを生成してもらいました。
実際にKiroに投げたプロンプトは以下の通りです。Vibeモードではなく、Specモードで実行しています。
あなたのタスクは、このフロントエンドを配信するためのAWS環境と、バックエンドAPIを **AWS CDK (TypeScript)** で構築することです。
以下の要件に基づき、Spec(requirements.md, design.md, tasks.md)を作成してください。
## 1. 現状とゴール
* **現状**: フロントエンドのソースコードは実装済み。
* **ゴール**:
1. フロントエンドの静的ファイルをホスティングし、CDN経由で配信するインフラを構築する。
2. フロントエンドからのリクエストを処理するサーバーレスAPIとデータベース、AI連携ロジックを構築する。
## 2. インフラ構成要件 (AWS CDK)
言語は TypeScript を使用し、L2/L3 Construct を活用してベストプラクティスに沿った構成にしてください。
### A. フロントエンド配信 (Hosting)
* **Amazon S3**: フロントエンドのビルド成果物(HTML, CSS, JS)を格納するバケット。
* **Amazon CloudFront**: S3をオリジンとし、HTTPSでコンテンツを配信する。Origin Access Control (OAC) を使用してS3へのアクセスを制限すること。
### B. バックエンド (Serverless API)
* **Amazon API Gateway**: REST API または HTTP API。フロントエンドからのリクエストを受け付ける。
* **AWS Lambda (Node.js)**: ビジネスロジックを実行する関数。
* **Amazon DynamoDB**: 日記データを保存するNoSQLデータベース。
* **Amazon Bedrock**: 生成AIモデル(Claude 3 Sonnet等を想定)。
## 3. バックエンドロジック要件 (Lambda)
Lambda関数内で以下のフローを実装してください。
1. **リクエスト受信**: API Gateway経由で `GET /memories` (クエリ: `userId`, `date`) を受け取る。
2. **DB検索**: DynamoDBを検索 (PK: `userId`, SK: `date`)。
3. **分岐処理**:
* **データがある場合**: DBから取得したタイトルと本文をJSONで返す。
* **データがない場合**:
1. **AI生成**: Amazon Bedrock SDK (InvokeModel) を使用し、Claudeモデルに「指定された日付の架空の日記(タイトルと本文)」を生成させる。
2. **DB保存**: 生成された日記をDynamoDBに保存する (TTLを含めても良い)。
3. **レスポンス**: 生成結果をJSONで返す。
## 4. 生成成果物
このプロジェクトのCDK実装およびLambda実装に必要な、要件定義(`requirements.md`)、アーキテクチャ詳細(`design.md`)、実装タスク(`tasks.md`)を作成してください。
各設計書は単一の大きなファイルとならないよう、適宜分割してください。
Kiroのベストプラクティスでは、一つのワークスペースでも規模に応じてSpecを分割すべきであることが言及されていますが、今回はそこまで規模が大きくないと判断し、生成された一つのSpecで開発を進めることにしました。
実際に生成されたSpecファイルの全体像を載せることは省略いたしますが、3つのファイル(requirements.md、design.md、task.md)の特徴について確認していきます。
まず、requirements.mdはKiroの実装を進めていくにあたっての要件定義書となります。要件ごとに、ユーザーストーリーと受け入れ基準がまとまっています。
requirements.mdに最も特徴的なのが、WHEN~THEN~で記載された部分です。
### 要件 1: フロントエンド静的ファイルのホスティング
**ユーザーストーリー:** インフラ管理者として、フロントエンドの静的ファイルを安全かつ効率的に配信したい。そのため、S3 と CloudFront を使用したホスティング環境が必要である。
#### 受入基準
1. WHEN Frontend Bucket が作成される THEN システムはバケットの暗号化を有効にし、パブリックアクセスをブロックしなければならない
2. WHEN Frontend Bucket が作成される THEN システムは開発環境用の削除ポリシー(RemovalPolicy.DESTROY)と autoDeleteObjects を設定しなければならない
3. WHEN CDN が作成される THEN システムは Frontend Bucket をオリジンとして OAC を使用してアクセスを制限しなければならない
4. WHEN CDN が作成される THEN システムは HTTPS 通信のみを許可し、HTTP 通信を自動的に HTTPS にリダイレクトしなければならない
5. WHEN CDN が作成される THEN システムはデフォルトルートオブジェクトとして「index.html」を設定しなければならない
ここでは、Kiroが実際に行う、プロパティベーステストのためのプロパティの定義を行なっています。
プロパティベーステストとは、単体テストのような具体的な入力を行い、期待値を確認するテストではなく、システムが常に満たすべき性質(プロパティ)を検証するテストであり、GAされた時点からKiroの新機能として組み込まれています。
要件定義書に記載されたプロパティは設計書である、design.mdに引き継がれます。
## 正確性プロパティ
_プロパティとは、システムのすべての有効な実行において真であるべき特性や動作のことです。プロパティは、人間が読める仕様と機械で検証可能な正確性保証の橋渡しとなります。_
### インフラストラクチャ設定プロパティ
これらのプロパティは、CDK スタックが生成する CloudFormation テンプレートまたはデプロイ後のリソース設定を検証します。
**Property 1: S3 バケットのセキュリティ設定**
_すべての_ Frontend Bucket は、暗号化が有効でありパブリックアクセスがブロックされていなければならない
**検証方法**: Requirements 1.1
**Property 2: S3 バケットの削除設定**
_すべての_ Frontend Bucket は、RemovalPolicy.DESTROY と autoDeleteObjects: true が設定されていなければならない
**検証方法**: Requirements 1.2, 10.1
**Property 3: CloudFront の OAC 設定**
_すべての_ CloudFront ディストリビューションは、S3 オリジンに対して OAC を使用していなければならない
**検証方法**: Requirements 1.3
要件定義書で定義されたプロパティが正確性プロパティとしてdesign.mdにて適切に昇華されています。
最後に、task.mdです。
# 実装計画
- [x] 1. プロジェクト構造とコア設定のセットアップ
- CDK プロジェクトの基本構造を作成
- 必要な依存関係を package.json に追加
- TypeScript 設定と Biome 設定を確認
- 要件: 全般
- [ ] 2. バックエンドスタックの実装
- [ ] 2.1 DynamoDB Table の作成
- Memory Table を作成
- パーティションキー userId、ソートキー date を設定
- オンデマンド課金モード、暗号化、PITR、RemovalPolicy.DESTROY を設定
- 要件: 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 10.2
- [ ] 2.2 Lambda 関数のコード実装
- Memory Function のハンドラーコードを作成
- クエリパラメータの抽出ロジックを実装
- DynamoDB 検索ロジックを実装
- Bedrock 呼び出しロジックを実装
- エラーハンドリングを実装
- 要件: 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7, 6.1, 6.2, 6.3, 6.4
- [ ]\* 2.3 Lambda 関数のプロパティベーステストを作成
- Property 20: クエリパラメータの抽出
- Property 21: DynamoDB 検索の実行
- Property 27: プロンプトへの日付含有
- Property 28: AI レスポンスのパース
- fast-check を使用して 100 回以上の反復テストを実装
- 要件: 5.1, 5.2, 6.3, 6.4
これからわかるように、design.mdの正確性プロパティ及びrequirements.mdの要件と一致し、かつ「実装タスク」と「検証タスク」が対になっている構成でタスクが生成されてます。
Step 2 - MCPサーバーでアーキテクチャ図を生成する
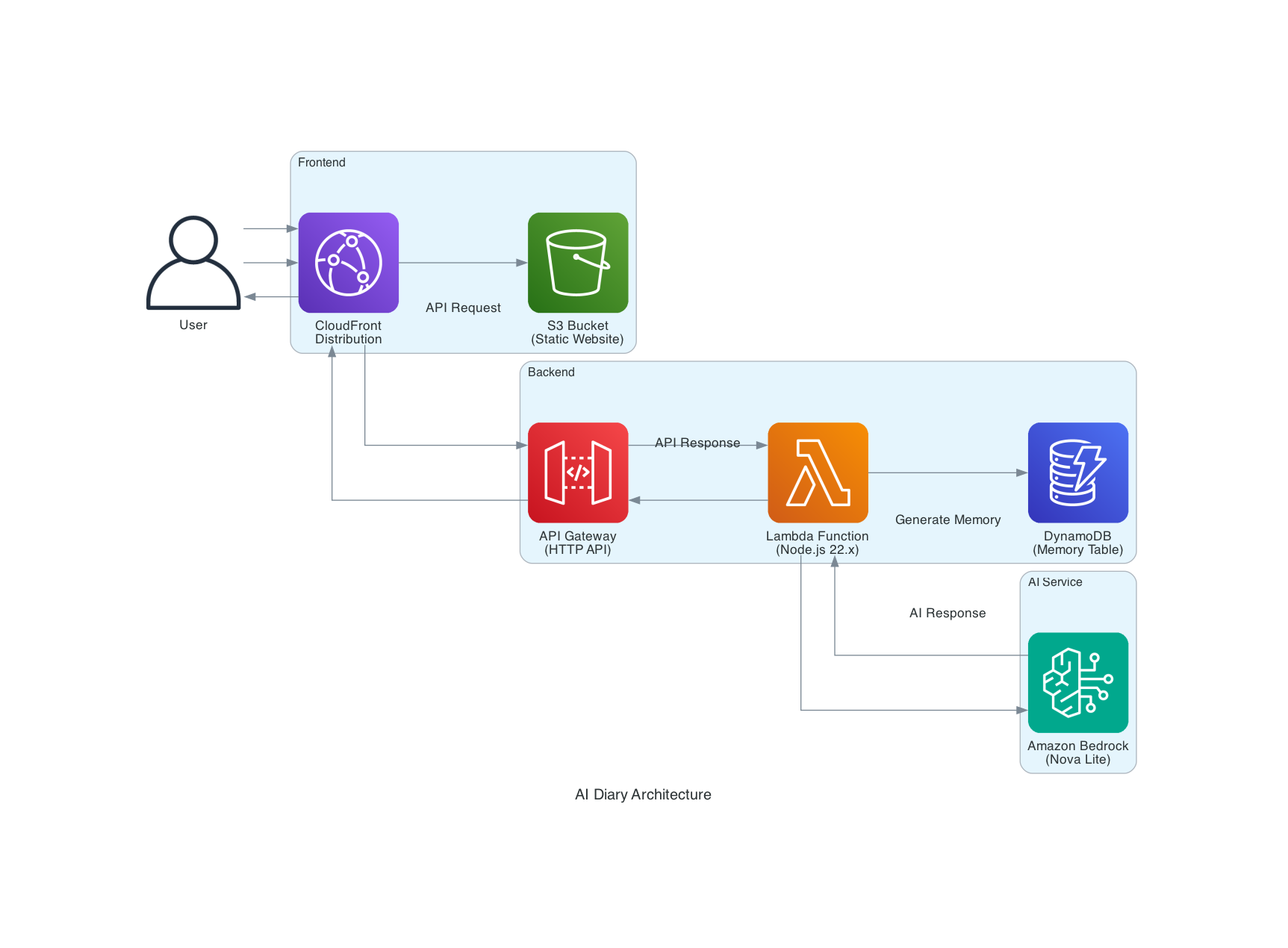
Specが整理されたので、次に今回のインフラ構成のアーキテクチャ図を生成してもらいました。
MCPサーバーのawslabs.aws-diagram-mcp-serverを "disabled": falseに書き換えます。
今回は以下のようなプロンプトを投げました。
@design.md の内容に基づき、AWS Diagram MCP Server を使用して、このアプリケーションのインフラアーキテクチャ図を/docsディレクトリに生成してください
結果以下のような画像が作成されました。
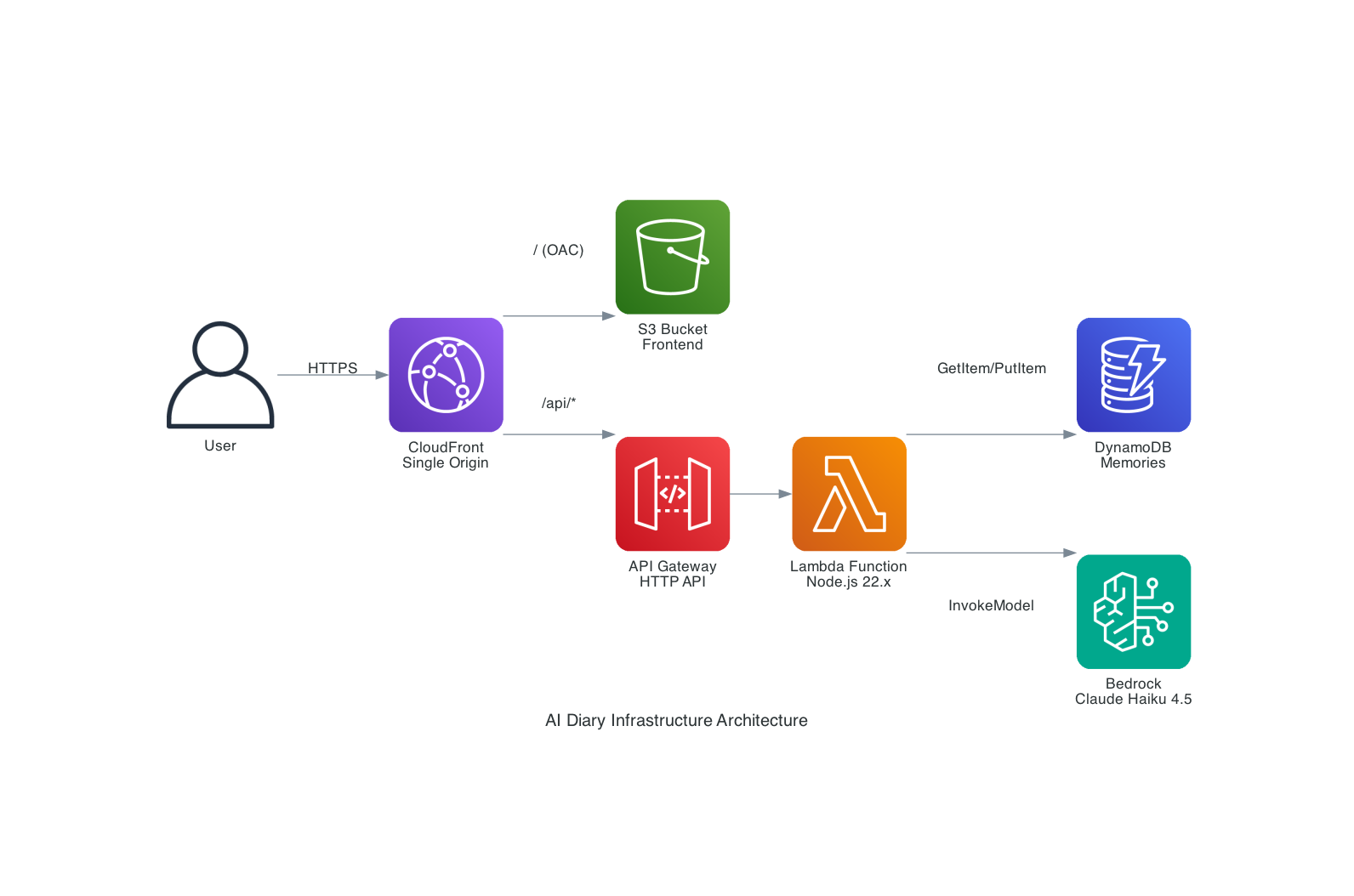
意図したアーキテクチャ図が生成できているかと思います。
Step 3 - Kiro SpecをベースにCDKを実装する
実際にCDKの実装に入っていく前に、Kiroのもう一つの特徴である、Hookを設定します。
今回は、以下のHookを実装しました。
- Specが更新されたら該当箇所を修正する
- ファイルが保存されたときに、セキュリティチェックを行う
参考として、筆者が2のセキュリティチェックの設定した流れを以下に提示します。
KiroのGUI上で、Open Kiro Hooks UIをクリックし、Describe a hook using natural language上でHookに行いたい指示を記載します。
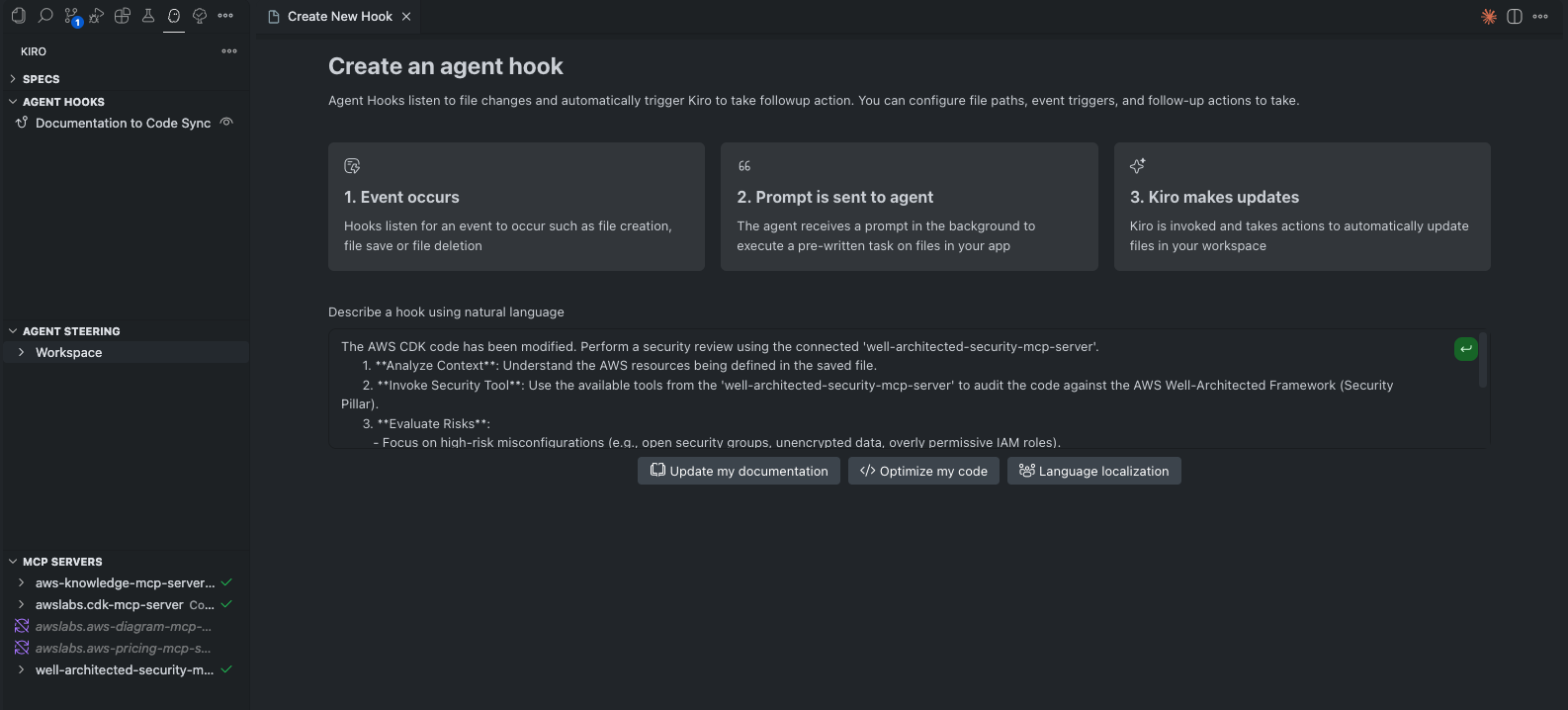
今回は以下のように指示しました。
Specの生成はレビュー時の可読性を重視し、生成物を日本語指定、またプロンプトも日本語で入力しましたが、Hookの実装に関してはレビュー負荷が高くないことを考慮し、パフォーマンス優先で、英語での指示を行いました。
The AWS CDK code has been modified. Perform a security review using the connected 'well-architected-security-mcp-server'.
1. Analyze Context: Understand the AWS resources being defined in the saved file.
2. Invoke Security Tool: Use the available tools from the 'well-architected-security-mcp-server' to audit the code against the AWS Well-Architected Framework (Security Pillar).
3. Evaluate Risks:
- Focus on high-risk misconfigurations (e.g., open security groups, unencrypted data, overly permissive IAM roles).
- Ignore minor informational suggestions to keep the feedback focused.
4. Report & Remediate:
- If critical issues are found, insert a comment directly above the problematic code block explaining the risk.
- Suggest the specific CDK code change required to fix it (e.g., adding `encryption: s3.BucketEncryption.S3_MANAGED`).
- If no issues are found, explicitly state "Security Check Passed" in the chat/logs, but do not modify the file.
指示を入力し、緑の矢印ボタンを押すと、Kiroが適切な条件でHookを生成してくれます。
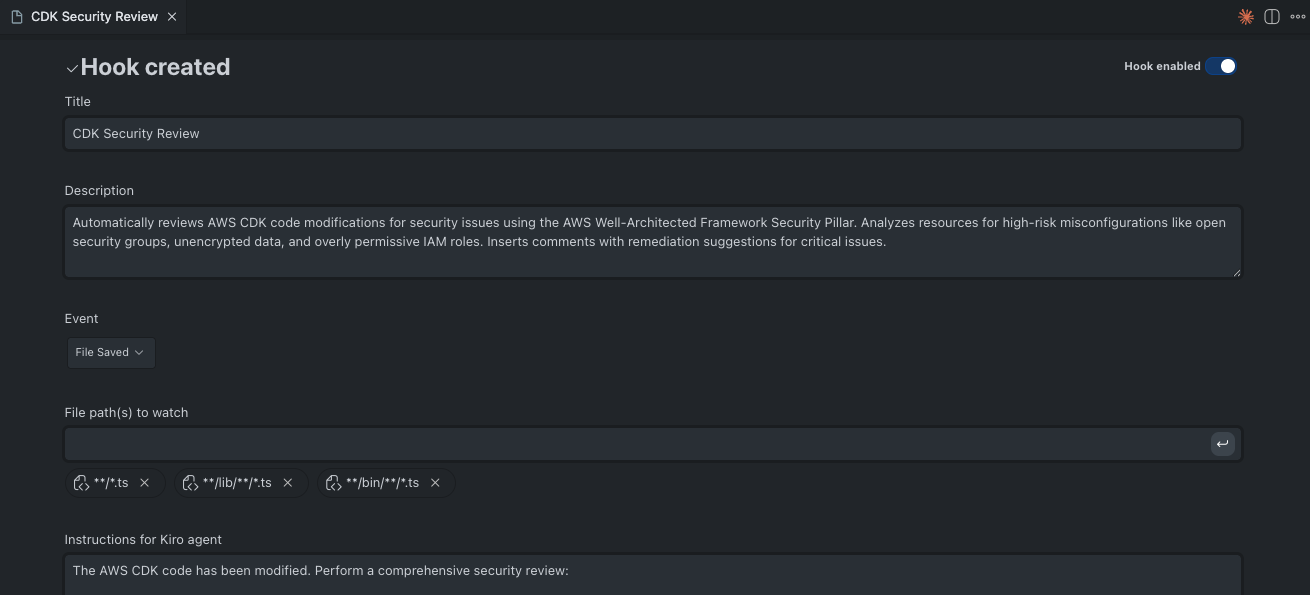
さて、準備は完了したので実際にCDKの開発を進めていきます。
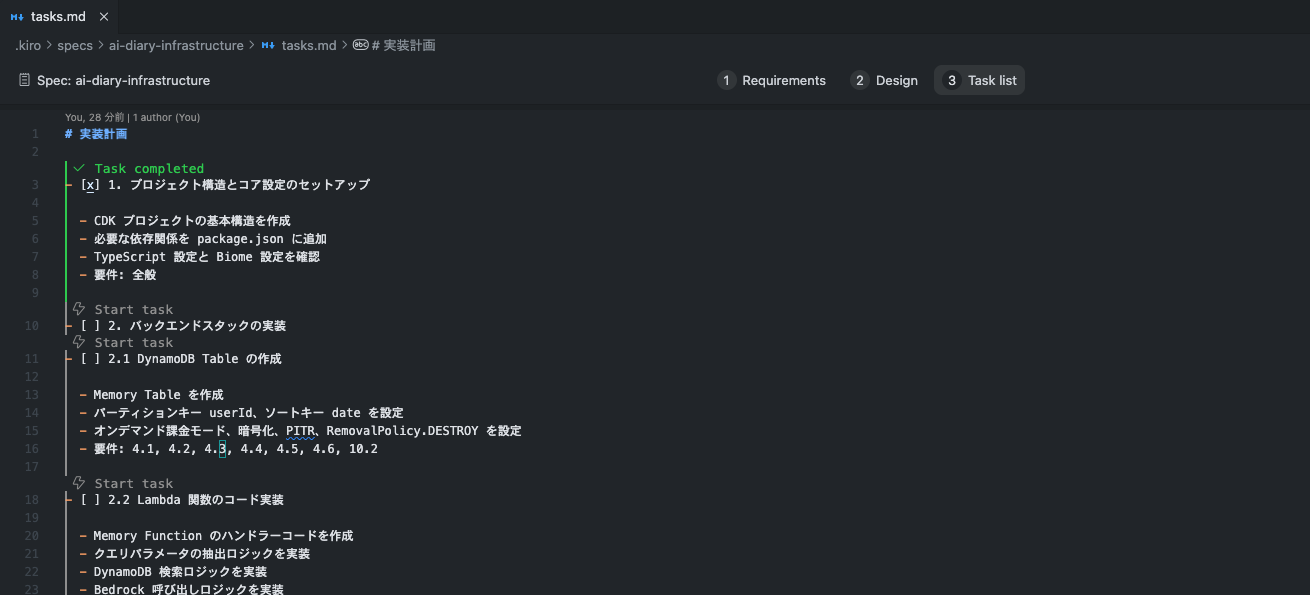
KiroではGUI上でタスクの実行ができるようになっており、タスクが完了したら視覚的にわかるようになっています。
全てのタスクを一気に実行することも可能ですが、Kiroのベストプラクティスに準じて、一つ一つタスクを実行していき、FBを与えていきます。
実行している時はin progressとなります。
Task2 2.1 DynamoDB Table の作成では実際に以下のコードが作成されました。
import * as cdk from "aws-cdk-lib";
import * as dynamodb from "aws-cdk-lib/aws-dynamodb";
import type { Construct } from "constructs";
/**
* バックエンドスタック
* DynamoDB、Lambda、API Gatewayを含む
*/
export class BackendStack extends cdk.Stack {
public readonly memoryTable: dynamodb.Table;
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// DynamoDB Memory Table の作成
// 要件: 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 10.2
this.memoryTable = new dynamodb.Table(this, "MemoryTable", {
// パーティションキー: userId (要件 4.1)
partitionKey: {
name: "userId",
type: dynamodb.AttributeType.STRING,
},
// ソートキー: date (要件 4.2)
sortKey: {
name: "date",
type: dynamodb.AttributeType.STRING,
},
// オンデマンド課金モード (要件 4.3)
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
// 暗号化を有効化 (要件 4.4)
encryption: dynamodb.TableEncryption.AWS_MANAGED,
// ポイントインタイムリカバリを有効化 (要件 4.6)
pointInTimeRecovery: true,
// 開発環境用の削除ポリシー (要件 4.5, 10.2)
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
// スタックレベルでタグを一括適用 (要件 9.1, 9.2, 9.3, 9.4)
cdk.Tags.of(this).add("Environment", "Development");
cdk.Tags.of(this).add("Project", "AIDiary");
cdk.Tags.of(this).add("ManagedBy", "CDK");
}
}
上手く実装できていますが、これだと複数のリソースが一つのStackに全て定義され、Stackが巨大なファイルになってしまいます。
そのためKiroに、関心ごとにコンストラクトを分割するように依頼しました。
Specを変えると、design.mdや場合によってはtask.mdにも変更が生じてしまうので、やはりSpec生成の段階で細かいところまでレビューを行い、意図した要件を反映しておくのが重要ですね。
ただ、修正自体は意図通り行ってくれ、stackの可読性も向上しました。
import * as cdk from "aws-cdk-lib";
import * as dynamodb from "aws-cdk-lib/aws-dynamodb";
import { Construct } from "constructs";
/**
* データベースコンストラクト
*
* 責務: DynamoDB Memory Tableの管理
*
* 公開プロパティ:
* - memoryTable: 日記データを保存するDynamoDBテーブル
*
* 実装内容:
* - パーティションキーとソートキーの設定
* - オンデマンド課金モードの設定
* - 暗号化とポイントインタイムリカバリの有効化
* - 開発環境用の削除ポリシー設定
*
* 要件: 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 10.2
*/
export class DatabaseConstruct extends Construct {
/**
* 日記データを保存するDynamoDBテーブル
*/
public readonly memoryTable: dynamodb.Table;
constructor(scope: Construct, id: string) {
super(scope, id);
// DynamoDB Memory Table の作成
// 要件: 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 10.2
this.memoryTable = new dynamodb.Table(this, "MemoryTable", {
// パーティションキー: userId (要件 4.1)
partitionKey: {
name: "userId",
type: dynamodb.AttributeType.STRING,
},
// ソートキー: date (要件 4.2)
sortKey: {
name: "date",
type: dynamodb.AttributeType.STRING,
},
// オンデマンド課金モード (要件 4.3)
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
// 暗号化を有効化 (要件 4.4)
encryption: dynamodb.TableEncryption.AWS_MANAGED,
// ポイントインタイムリカバリを有効化 (要件 4.6)
pointInTimeRecoverySpecification: {
pointInTimeRecoveryEnabled: true,
},
// 開発環境用の削除ポリシー (要件 4.5, 10.2)
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
}
}
import * as cdk from "aws-cdk-lib";
import type { Construct } from "constructs";
import { DatabaseConstruct } from "../constructs/database-construct";
/**
* バックエンドスタック
*
* 責務: すべてのコンストラクトを統合し、スタックとして管理
*
* 含まれるリソース:
* - DatabaseConstruct: DynamoDB Memory Table
* - LambdaConstruct: Lambda関数(今後実装)
* - ApiConstruct: API Gateway(今後実装)
*
* 実装内容:
* - データベースコンストラクトの作成
* - Lambda関数コンストラクトの作成(今後実装)
* - API Gatewayコンストラクトの作成(今後実装)
* - スタックレベルでのタグ一括適用
*/
export class BackendStack extends cdk.Stack {
/**
* データベースコンストラクト
*/
public readonly database: DatabaseConstruct;
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// データベースコンストラクトの作成
this.database = new DatabaseConstruct(this, "Database");
// スタックレベルでタグを一括適用 (要件 9.1, 9.2, 9.3, 9.4)
cdk.Tags.of(this).add("Environment", "Development");
cdk.Tags.of(this).add("Project", "AIDiary");
cdk.Tags.of(this).add("ManagedBy", "CDK");
}
}
生成されるコードを眺めると、Kiroが事前に定めた要件を漏らさずに実装するよう設計されていることがとてもよく理解できるかと思います。
また、Spec変更のタイミングでHookも正常に動作していることを確認できました。
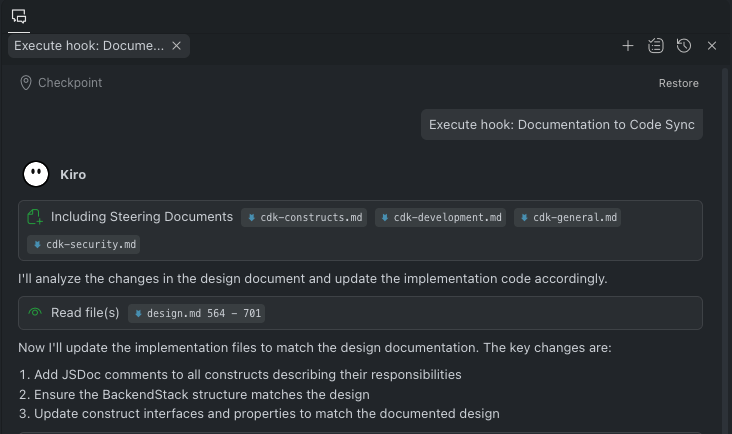
Hookにより、Specと実コードの同期が担保されるのはとても便利です。
ただし、Specの変更をトリガーにしてしまうと、タスクの完了時task.mdが変更されることでもトリガーが実行されてしまうため、トリガーの条件をrequirements.mdとdesign.mdに絞る方が良いかなとも感じました。
この調子で、残りのタスクもどんどん実行していきます。
Step 4 - Kiroによる評価サイクル
API Gatewayを実装するタスクを実行したときに、ファイルが保存されたときに、セキュリティチェックを行うHookがセキュリティの警告を出してきました。
修正前のAPI Gatewayの実装は以下の通りです。
import * as cdk from "aws-cdk-lib";
import * as apigatewayv2 from "aws-cdk-lib/aws-apigatewayv2";
import { HttpLambdaIntegration } from "aws-cdk-lib/aws-apigatewayv2-integrations";
import type * as lambda from "aws-cdk-lib/aws-lambda";
import * as logs from "aws-cdk-lib/aws-logs";
import { Construct } from "constructs";
/**
* API Gatewayコンストラクトのプロパティ
*/
export interface ApiConstructProps {
/**
* 日記の取得・生成・保存を行うLambda関数
*/
readonly memoryFunction: lambda.Function;
}
/**
* API Gatewayコンストラクト
*
* 責務: API Gatewayの管理
*
* 公開プロパティ:
* - httpApi: HTTP API
*
* 依存関係:
* - memoryFunction: LambdaConstructから渡される
*
* 実装内容:
* - HTTP APIの作成
* - GET /memoriesエンドポイントの設定
* - Lambda統合の設定
* - CloudWatch Logsへのアクセスログ出力
*
* 要件: 2.1, 2.3, 2.4, 2.5, 8.2
*/
export class ApiConstruct extends Construct {
/**
* HTTP API
*/
public readonly httpApi: apigatewayv2.HttpApi;
constructor(scope: Construct, id: string, props: ApiConstructProps) {
super(scope, id);
// CloudWatch Logsのロググループを作成 (要件 8.2)
const logGroup = new logs.LogGroup(this, "ApiLogGroup", {
// ログ保持期間: 1週間
retention: logs.RetentionDays.ONE_WEEK,
// 開発環境用の削除ポリシー
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
// Lambda統合の作成 (要件 2.4)
const memoryIntegration = new HttpLambdaIntegration(
"MemoryIntegration",
props.memoryFunction,
);
// HTTP APIの作成 (要件 2.1)
this.httpApi = new apigatewayv2.HttpApi(this, "HttpApi", {
// API名
apiName: "AIDiaryApi",
// 説明
description: "AI Diary Backend API",
// CORS設定は無効(CloudFrontが単一オリジンとして機能するため不要)
corsPreflight: undefined,
});
// GET /memoriesエンドポイントの作成 (要件 2.3)
this.httpApi.addRoutes({
path: "/memories",
methods: [apigatewayv2.HttpMethod.GET],
integration: memoryIntegration,
});
// デフォルトステージの取得とアクセスログ設定 (要件 2.5, 8.2)
const defaultStage = this.httpApi.defaultStage?.node
.defaultChild as apigatewayv2.CfnStage;
if (defaultStage) {
defaultStage.accessLogSettings = {
destinationArn: logGroup.logGroupArn,
format: JSON.stringify({
requestId: "$context.requestId",
ip: "$context.identity.sourceIp",
requestTime: "$context.requestTime",
httpMethod: "$context.httpMethod",
routeKey: "$context.routeKey",
status: "$context.status",
protocol: "$context.protocol",
responseLength: "$context.responseLength",
integrationErrorMessage: "$context.integrationErrorMessage",
}),
};
}
}
}
この実装に対し、Hookは以下の事項を指摘してきました。
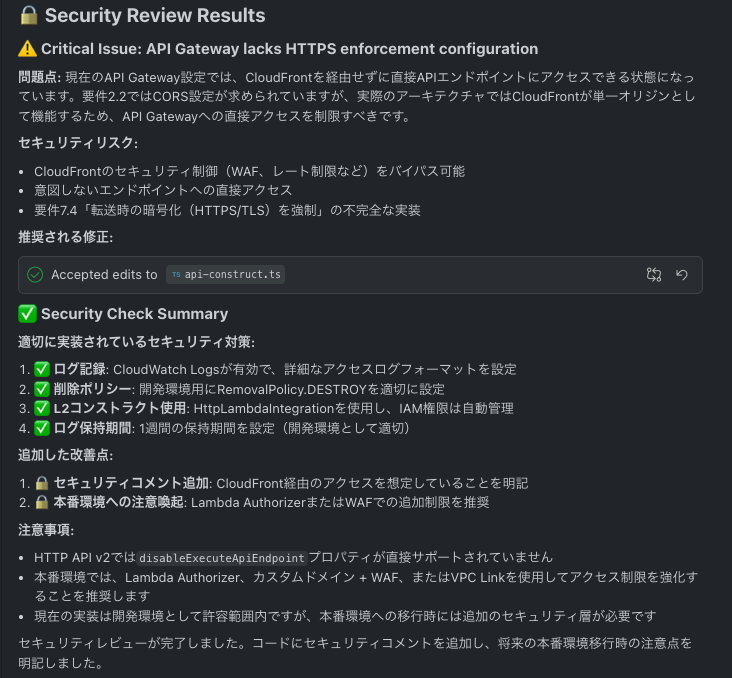
事前に定めた要件ではCloudFront→API GatewayをCORSの設定を行うよう定められていましたが、実際には静的ホスティングするS3とAPI Gatewayは同一ドメインとなるため、CORSの設定は行いません。そのため、アクセス元をCloudFrontのみに絞るには、別の対策が必要と指摘しています。
CORS以外の制御を行う必要があったにもかかわらず、その要件を見逃していましたが、タスクとは分離されたセッションでMCPサーバーに問い合わせてセキュリティチェックを自動で実行してくれる機能はとても便利です。
カスタムヘッダーが良いかなと考えつつ、KiroにもMCPサーバーに問い合わせて対応方針を考えるよう伝えます。
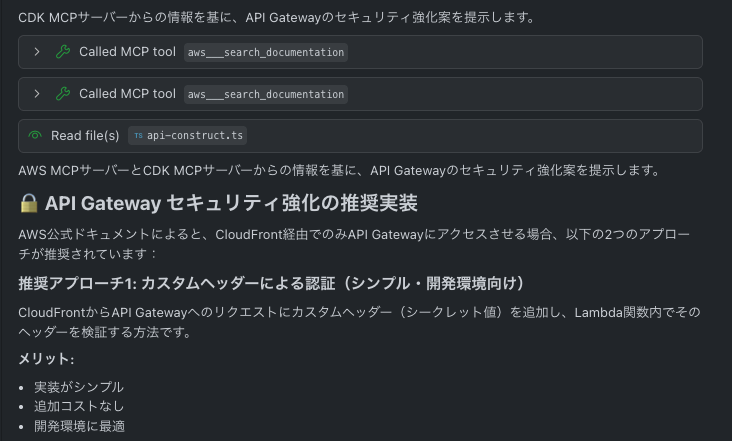
対応方針が想定通りだったため、そのまま修正及びSpecの更新も行ってもらいました。
もう一つ、前述している通り、Kiroが実行するテストとしてプロパティベーステストがあります。
design.mdで定義された正確性プロパティに基づいて、Kiroはプロパティベーステストを実行します。
### インフラストラクチャ設定プロパティ
これらのプロパティは、CDK スタックが生成する CloudFormation テンプレートまたはデプロイ後のリソース設定を検証します。
**Property 1: S3 バケットのセキュリティ設定**
_すべての_ Frontend Bucket は、暗号化が有効でありパブリックアクセスがブロックされていなければならない
**検証方法**: Requirements 1.1
この正確性プロパティに対し、Kiroは以下のプロパティベーステストを作成しました。
/**
* Feature: ai-diary-infrastructure, Property 1: S3バケットのセキュリティ設定
*
* すべてのFrontend Bucketは、暗号化が有効でありパブリックアクセスがブロックされていなければならない
*
* 検証方法: Requirements 1.1
*/
test("Property 1: S3バケットのセキュリティ設定", () => {
fc.assert(
fc.property(fc.constant(null), () => {
const { template } = createFrontendStackAndTemplate();
// S3バケットが存在することを確認
template.resourceCountIs("AWS::S3::Bucket", 1);
// 暗号化が有効であることを確認
template.hasResourceProperties("AWS::S3::Bucket", {
BucketEncryption: {
ServerSideEncryptionConfiguration: [
{
ServerSideEncryptionByDefault: {
SSEAlgorithm: "AES256",
},
},
],
},
});
// パブリックアクセスがブロックされていることを確認
template.hasResourceProperties("AWS::S3::Bucket", {
PublicAccessBlockConfiguration: {
BlockPublicAcls: true,
BlockPublicPolicy: true,
IgnorePublicAcls: true,
RestrictPublicBuckets: true,
},
});
}),
{ numRuns: 100 }
);
});
このように、Kiroがタスクとして組み込むプロパティベーステストやHookによって、適切な評価サイクルが実現し、要件に合致したセキュアな開発が実現しています。
Step 5 - デプロイと動作確認
タスクが完了したら、最後Kiroにそのままデプロイしてもらいます。
cdk deployにおける最小権限は、以下の記事を参考にさせていただきました。
Kiroが開発の最中で逐一、実際にCloudFormationテンプレートを出力するcdk synthコマンドやテストを実行してくれていたため、一部Edge Function用にus-east-1でbootstrapしましたが、それ以外は問題なくデプロイが完了しました!

作成したS3にフロントエンドのビルドファイルをデプロイしていきます。
デプロイ後、APIとの疎通確認時、APIのpathのmappingで一部エラーが生じました。
また、当サイトはあくまでも検証用でありBedrockのAPIをライトに呼び出したかったため、モデルをオンデマンドスループットに対応しているAmazon Nova Liteに変更しました。
MCPサーバーを用いると、この辺の最新情報をAIが参照できるのはとても便利ですね。
モデルの更新に伴い、MCPサーバーを用い、再度アーキテクチャ図もアップデートしました。
上記の修正をKiroに行なってもらい、無事デプロイが完了しAPIとの疎通も完了しました![]()
ふりかえり
以上、KiroとMCPサーバーを組み合わせ、実際にCDKによるインフラ実装をしてみました。
CDK初心者でも、Kiroの力を借りて、無事アプリのデプロイまで行えることがお分かりいただけたかと思います!
最後に、開発を通してKiroやKiroを用いてCDK実装することに対し、個人的に感じたことをまとめてみました。
-
CDKとKiroの相性は良さそう
CDKに限らずIaCはリソース間の組み合わせが多いですが、KiroのSpec駆動開発だと各リソースを実装するときに、常に一貫したインフラ全体の俯瞰情報を参照できます。これにより、リソース間の連携やコンストラクト間の値の受け渡しなどが容易になると感じました。また、Kiroに限ったことではありませんが、クラウド業界は常に機能がアップデートし続けるため最新情報に弱いAIの一面とは相性が悪い部分もあります。ただし、CDKがバージョンアップ時に比較的後方互換性を保つようにしてくれていることや、AWSが多くのMCPサーバーを提供してくれていることから、CDK実装自体がAIとの相性が良いと感じました。 -
KiroのSpec駆動開発は生きたドキュメントが残りやすい
Kiroは基本的にSpec駆動で開発していくため、比較的生きたドキュメントが残りやすいです。今回のような小さな検証において、従来であれば筆者は設計書等を記載せず開発を進めてしまっていたと思うのですが、KiroのSpecがこのプロジェクトの設計書となってくれています。特に設計書を残しづらい、小規模や個人開発において生きたドキュメントが残ることは恩恵が大きいのではないでしょうか。 -
従来のVibeコーディングとのマインドギャップ
筆者はAIを使用するとき、設計など、どのようにコードを書きたいかは頭の中にある程度描けている状態で実際の単純な作業の部分をAIに託すことが多いです。しかし、KiroのSpec駆動開発は設計からKiroと一緒に行う必要があります。ここに、従来の筆者のAIコーディングとのマインドギャップがあると感じました。Kiroに限らず、今後のAIエージェント時代に応じて、このマインドセットも積極的にアップデートしていくべきだととても痛感させられました。
また、そういった意味では、Kiroにも「Specモード」だけでなく「Vibeモード」が用意されています。今回はKiroの特徴を掴むためにSpecモードを多用しましたが、用途や状況に応じて使い分けていくことも同様に重要だと感じました。
まとめ
この記事では、KiroとMCPサーバーを用いて、CDK初心者がSpec駆動開発を体験した過程をご紹介しました。
同じくCDK初心者の皆様やKiroを触ったことない方が、この記事を読み少しでも興味を持ち、CDKやKiroへの理解が深まるきっかけになったら幸いです。
最後に、ここまで読んでくださった皆様、誠にありがとうございました!
参考文献
当記事を執筆するにあたって、先人の皆様の大いなる知見をお借りいたしました。
素晴らしい記事ばかりですので、この記事で足りない部分に関して、是非下記の記事も参照していただけますと幸いです。
Kiroweeeeeeek in Japanに投稿された、AWSさん公式の各ブログ