はじめに
データ分析業務の中でデータに「タイムラグ」があって困ったことはないでしょうか?
今ここで言っているタイムラグとは時系列データにおいて「Aが増加してから、ある程度の時間が経ったあとにBが増加する」ことを指しています。
時間差での相関関係があるということです。
今回はデータのタイムラグについての対処で「相互相関関数」というものが有効なようなのでご紹介したいと思います!
相互相関関数wiki
タイムラグがあるとなぜ困るのか
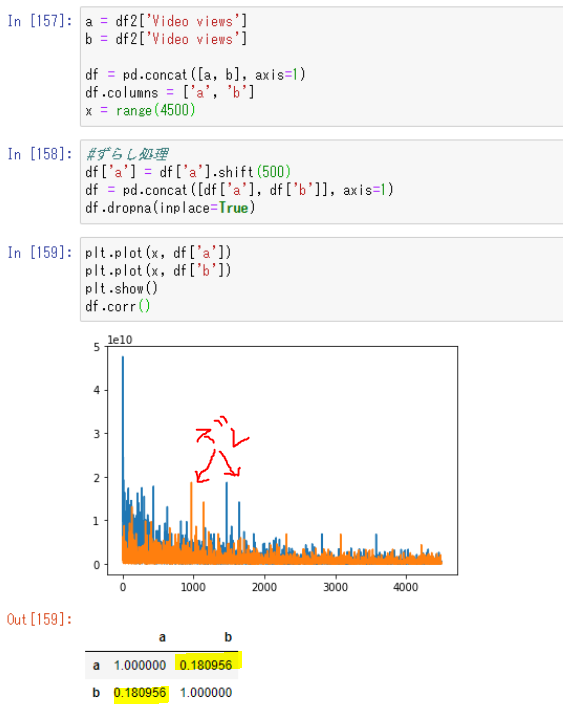
上の画像を見てください。
全く同じ5000行のデータを用意して片方のみ10%(500行)ズラしたデータを用意したものです。
その2つで相関係数を見ると0.18しかありません。
これは相関が無いに等しい値です...データの形は全く同じなのに...
(勿論ずらさなければ相関係数は1.0です)
この問題もデータが大量に用意できれば、多少ずれていても関係を確認することができますが実際の業務ではそうでないことも多々あるのです...アーメン。
じゃあ、相互相関関数は何なのよ
相互相関関数は2つの信号の類似性を見るための関数です。
上の例でも見たように、相関関係があるがずれているということは「データ自体(データの形)に類似性がある」ということです。
実際は音声データ等の波形データのズレを処理する時などによく使われているようです。
実装(Python)
相互相関関数を実装するには、numpyのcorrelateという関数を使います。
これは内部的には畳み込み積分というものが行われていて
その結果がリストとして返ってきます。
重要なのは、畳み込み積分の結果最も積が大きくなる場所がズレを表しているということです。
また、データの平均を0にしないと相互相関関数は適切に使えないため、あらかじめ平均を0に処理しておく必要があります。
def xcorr(df, target, data_names):
total_result = pd.DataFrame()
target_list = []
name_list = []
oldcor_list = []
delay_list = []
newcor_list = []
improvement_list = []
for name in data_names:
result = []
target_list.append(target)
name_list.append(name)
# 処理前の相関係数
tmp = df.loc[:, [target, name]]
cornum = tmp.corr().iloc[1, 0]
oldcor_list.append(cornum)
# 平均0に平準化
tmp[target] = tmp[target] - tmp[target].mean()
tmp[name] = tmp[name] - tmp[name].mean()
# 畳み込み積分処理
corr = np.correlate(tmp[target], tmp[name], 'full')
estimated_delay = corr.argmax() - (len(tmp[name])-1)
delay_list.append(estimated_delay)
# ラグ分をずらして再度相関係数計算
tmp[name] = tmp[name].shift(estimated_delay)
new_cornum = tmp.corr().dropna().iloc[1, 0]
newcor_list.append(new_cornum)
# 相関の改善値
improvement = abs(new_cornum) - abs(cornum)
improvement_list.append(improvement)
target_list = pd.Series(target_list)
name_list = pd.Series(name_list)
oldcor_list = pd.Series(oldcor_list)
delay_list = pd.Series(delay_list)
newcor_list = pd.Series(newcor_list)
improvement_list = pd.Series(improvement_list)
total_result = pd.concat([target_list, name_list, oldcor_list, delay_list
, newcor_list, improvement_list], axis=1)
total_result.columns = ['target', 'partner', 'old_corr', 'estimated_delay', 'new_corr', 'improvement']
return total_result
今回は相互相関関数でデータのラグを検知したあと、そのラグを戻した上で再度相関を確認するところまでを関数にしてみました。
先程のわざとズラしたデータに対して実行すると以下のようになります。

【各項目の意味】
target、partner → データの名前です。
old_corr → 処理前の相関係数
estimated_delay → 相互相関関数によって推定されたデータのラグ(行数)
new_corr → 推定されたラグを戻した上で再度計算した相関係数
improvement → その結果向上した相関係数値
画像を見てもらえれば500行ずれていることがしっかり推定されています。
また、ラグを戻すことで相関が1.0のピッチリ合っているデータであることも確認できました!
終わり
以上のように、データ上のタイムラグを検知しどれくらいズレているかを相互相関関数で確認することができました。
ただし、ズレていないデータにこの関数をかけると変な値が出たりすることがあるので(estimated_delayがバカでかくなったりします)、ある程度「このデータにはタイムラグがある」というアタリをつけながら使う必要はあるかなと思います。