※この記事は「本番環境などでやらかしちゃった人 Advent Calendar 2025」向けの体験談です。
ADサーバーが消えると、たくさん楽しいことが起きます。
1. 登場人物
まずは登場人物から。
- Aさん:作業者。入社1年目。数回のメンテナンス作業経験あり。
- 私:作業の確認者。入社5年目くらい。システム構築やメンテナンス作業の経験あり。
- B課長:Aさんと私の上司。
- C部長:B課長の上司
- D事業部長:C部長の上司
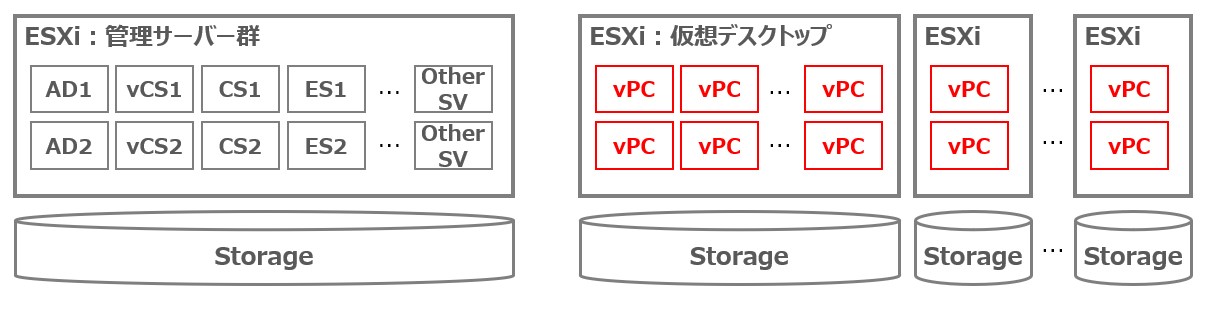
2. システム構成
VMware製品を使用した DaaS(仮想デスクトップサービス)環境 です。
細かい構成要素はいろいろありますが、典型的なDaaSアーキテクチャでも同じような話は起きうるので、ざっくり以下のような構成だと思ってください。

-
すべての管理サーバーは仮想サーバーで、Active-Active構成で冗長化されています。
- AD:Active Directory / DHCP / DNS Server
- vCS:VMware vCenter Server
- CS:Horizon Connection Server
- ES:VMware Enrollment Server
-
ユーザーが利用する仮想デスクトップは、管理サーバー群とは別の ESXi 上で稼働しています。
- vPC:仮想デスクトップ(VDI)
3. 月次の管理サーバーメンテナンス
管理サーバーは Windows Server なので、毎月の Windows Update が必要です。
再起動も発生するため、日中にやるのはリスクが高い。なので、 メンテナンス時間中(深夜) に作業をします。
今回のメンテ対象は AD1 と AD2。片系ずつ順番に作業する手順は以下の通りでした。
- 監視システムを抑止モードに設定:(監視システムは別環境。再起動するとアラートが飛ぶので一時停止)
- AD2 をシャットダウン
- AD2 のスナップショット取得
- AD2 を起動 → Windows Update 実行 → 再起動を繰り返しつつ更新プログラム適用
- AD2 の正常性確認。問題なければ再度シャットダウン
- AD2 の一番古いスナップショットを削除
- AD2 を起動し、正常性を確認
- AD1 をシャットダウン
- AD1 のスナップショット取得
- AD1 を起動 → Windows Update 実行 → 再起動を繰り返しつつ更新プログラム適用
- AD1 の正常性確認。問題なければ再度シャットダウン
- AD1 の一番古いスナップショットを削除
- AD1 を起動し、正常性を確認
- 監視システムの抑止モードを解除
4. 作業ミス発生:ADが「インベントリから」消える
手順 6 でミスってしまいました。
vmware エンジニアブログさんの画像をお借りして状況を説明すると、こんな画面構成でした(※イメージ)。

本来やるべきだったのは:
- 青枠:スナップショットのウィンドウで、一番古いスナップショットを削除
しかし実際にやってしまったのは:
- 赤枠:仮想マシン自体を操作するメニューで、「インベントリから削除(Delete from Inventory)」を実行
昔の vCenter は、仮想マシンがオフになっていると「インベントリから削除」というメニューが出てくるのですが、眠すぎて「Delete」という文字しか目に入っていませんでした。
時刻は AM3時。 前日、私は 18時間ぶっ通しでモンハンをしていました。
Aさん「Deleteをクリックします」
私「はい」(← 超絶眠くて目が9割くらい閉じている。ほぼ寝てる)
Aさん「なんか違う気がするんですが、合っていますかね?」
私「項目が1個減ったので合っていると思いますよ」(← 寝不足)
ここでも、本来は 青枠のスナップショット一覧を確認すべきなのに、
赤枠の仮想マシン一覧を見て「減ってるからOK」と判断してしまいました。
その後、手順 8 以降を進め、手順 12 のAD1のスナップショット削除に入ったところで、再度違和感が出てきました。
Aさん「スナップショット削除しましたが、赤枠の項目が減らないですね」 ← 手順としては合ってる
私「そうですね」
Aさん「あ、すみません、間違って青枠の方で作業していました。すみません、削除します」 ← 間違っている
私「はい」
そして、AD1 も無事インベントリから削除されました。
次の手順 13 で AD1 を起動しようとしたときでした。
Aさん「手順通りに起動しようとしたんですが、AD1 がいないです」
私「は?」(← ここでやっと目が覚める)
目の前にあるのは、
- AD1 も AD2 も存在しない vCenter の画面
全身から変な汗が噴き出しました。 「あ、これ完全に作業ミスだ」 と脳が理解するまで数秒かかりました。
「ん?ちょっと待て、なんで AD1 のときに初めて気づいたんだ?」と冷静になって考えると、AD2 のときに正常性確認(手順7)をしていれば、その時点で気付けたはずです。
そうです。Aさんは 手順 7 をスキップしていました。
作業者あるあるの「読み飛ばし」です。
そして私は、そのスキップに気づけていませんでした。
さて、リカバリーしようにもADサーバーが片系だけいないなら、単純にリストアすればよい話ですが、今回は 両系いない。
両方いなくなったとき、リストアでうまくいくのか?というか、そもそもこれリストアできるか?と思ったが、
「あ、インベントリから削除しただけだから、ストレージにはデータが残っている!」
「そこからリストアすればいけるじゃないか!!」
メンテナンス終了時刻まで 残り1時間。
「まだリカバリーいけるな」と、自分に言い聞かせ、黙ってリカバリを始めます。
本来ならここで上司にエスカレーションすべきなのですが、
- メンテ時間内に直したい
- 怒られたくない(重要)
という感情が勝ち、私は自分が作業者となって、ESXi のデータストアからリストア作業を始めました。
結果として:
- AD1 / AD2 の仮想マシンは無事復活
- ESXi の vSphere Client 上でも存在を確認
- AD / DHCP / DNS も一見正常に見える
メンテ終了 10分前にリカバリー完了。
「ギリギリ間に合った!やればできるじゃん!」と、妙な達成感がありました。
Aさんもニッコリです。私もニッコリ。
……
最後の手順 14:監視システムの抑止モードを解除をしました。
5分後、約8000件のアラートメール が飛んできました。
- 監視室のパトランプが鳴り止まない
- Aさんはフリーズ
- 私の心拍数は爆上がり
このアラートメールは、もちろん 上司にも届きます。
5. AD 両系リストアの影響:管理サーバ群がドメインに参加できない
ここでようやく、「さっきのリストアって、本当に正しいやり方だったのか?」という話になります。
この環境では、ADサーバー両系をスナップショット時点へロールバックしてしまったため、
他のサーバー(vCS, CS, ES など)との コンピュータアカウントが不整合になりました。

つまり、
- vCS / CS / ES などの管理サーバーは、いずれもドメインに参加できない。
- その影響でADサーバ以外の管理サーバーは名前解決が成立しない状態に。
そして致命的なのは、これら管理サーバーは「ドメイン参加した状態」を前提に構築されているという点です。
名前解決ができない = 何もできない
となり、結果的に:
- 全管理サーバーをドメイン再参加させる必要あり
- = 機能は全部入れ直し
- = ほぼ再構築

管理サーバー群を再構築するということは、そのサーバー群が制御している vPC も全セットアップし直しになります。
- マスターPC からすべての vPC を再展開
- 数も多いので、それなりに時間がかかるが、作業自体はそんなに大変ではない(管理サーバーの方がやばい)
運用面を十分考慮したアーキテクチャだったか?と言われると、正直微妙…
ただ、アーキテクチャの反省は一旦置いておいて、「なぜこんなことになったのか」にフォーカスします。
6. なぜ作業ミスは起きたのか?
D事業部長からC部長とB課長が3時間くらい会議室で詰められていました。
その後、私はB課長から物凄く怒られました。Aさんは泣いちゃいました。
ここから、なぜなぜ分析のスタートです。
「真因を探るには、最低5回は『なぜ』を繰り返せ」とよく言われますが、今回はインパクトが大きすぎたため、D事業部長から
「更に深い真なる真因を出して対策せよ」
というオーダーが入り、7回なぜをやることになりました。
Aさんの場合
Aさん向けのなぜなぜ。
-
なぜ手順6で削除する場所を誤ってしまったのか?
→ Aさん「私の能力不足が原因です。大変申し訳ございません」 -
なぜ能力不足なのか?
→ Aさん「私の能力が不足しているからです。大変申し訳ございません」
入社1年目でメンタルも消耗していたこともあり、すべて自分の能力の問題に帰属してしまう状態になっていました。
ここで一旦、Aさんへの追及はストップして私自身のなぜなぜ分析に移ります。
私の場合(7回なぜ)
-
なぜ手順6の削除場所の誤りに気付けなかったのか?
→ 私「注意が不足していたため」 -
なぜ注意が不足していたのか?
→ 私「寝不足だったため」 -
なぜ寝不足だったのか?
→ 私「プライベートが充実しすぎて、睡眠時間を確保しなかったため」(= 18時間モンハン) -
なぜ睡眠時間を確保しなくても大丈夫だと思ったのか?
→ 私「Aさんなら問題なく、手順通りにやれると思ったから」 -
なぜ Aさんなら問題なく手順通りにやれると思ったのか?
→ 私「すでに何度もメンテナンスを完遂した実績があったから」 -
なぜ完遂実績が複数回あるだけで『大丈夫』だと判断したのか?
→ 私「日頃から一緒に作業していて、Aさんの作業レベルに一定の信用をしていたから」 -
なぜ Aさんをそこまで信用してしまったのか?
→ 私「」
「深淵の真因」が見えてきましたね。
直接原因への対策ももちろんやっています
ヒューマンエラーそのものを減らす対策も実施しました。
-
手順の改善
- スナップショットの取得と削除を、1つの手順の中で完結させる
-
作業の自動化
- RPA(UiPath / WinActor など)や PowerShell / Python などで自動化
- 特に削除系の作業はリスクが高いため、必ず CLI で実施する仕組みに変更
これらを B課長に報告した上で、C部長 / D事業部長ともレビューが行われました。
( 最終的には、UiPath + PowerShell で今回の定期メンテ作業を 管理サーバー群すべてに対して自動化 しました。)
D事業部長もB課長やC部長相手になぜなぜ分析をした結果、
- B課長:私と Aさんを信用していた
- C部長:B課長を信用していた
つまり、組織全体が「あの人たちなら大丈夫でしょ」という現場猫状態になっていました。(ある意味、とても良い職場でした)
7. 根本原因の対策、効果
事業部内で 「誰も信用しないことを原則とする行動指針」 を立てました。
サイバーセキュリティの世界には、
「決して信用せず、常に検証せよ」
という考え方に基づいた Zero Trust セキュリティモデル があります。
これの人間版です。この後、何度も登場するので、HZT(Human Zero Trust model)と表記します。
HZT の基本方針
HZT の根本思想はシンプルです。
「すべての作業を、すべて記録に残す」
そのために、以下のような体制を構築しました。
-
作業者と確認者は オンサイトでのコミュニケーション禁止
- オフラインの会話は記録が残らず、かつ、対面だとなんとなく信頼が生まれやすいため
-
すべての作業は オンライン会議上で実施
-
オンライン会議の URL は事業部内に展開し、役職者は いつでも乱入可能
- (役職者の中でローテーションを組んでランダムな時間に入るようにしていたらしい)
-
作業者は画面共有し、作業画面 / 作業手順書 / チェックリスト が同時に見える状態にする
-
確認者も同様に、作業者の画面と手順書 / チェックリストを常時表示
-
作業中の画面を常時録画
-
作業終了後:
- 作業者と確認者は、録画データを視聴
- その「視聴作業」もまた録画
-
課長は、
- 作業動画(作業者・確認者)2本
- チェック動画(作業者・確認者)2本
計4本を確認し、その様子も録画
-
部のメンバー1名も同様に4本分を確認し、確認風景を録画
-
部長は、
- 課長と部メンバー1名分の「確認動画」2本をチェック
このような状況で、もし作業ミスが発生した場合、部長がすべての責任を負い、お客様対応を行う代わりに、作業者 / 確認者 / 部メンバー1名 / 課長全員に評価面のペナルティが発生。
ただし、
- チェックのタイミングで作業ミスに気付き、部長にエスカレーションした場合はペナルティ回避
というルールにしました。つまり、 「見抜いた人が勝ち組」になる設計 です。
ぱっと見ブラックだが、実態はそこまででもない
ここまで読むと、「いやいや、これ完全にブラックでは?」と思われるかもしれません。
しかし、HZT 推進には 物理的に人と人を分離する必要があるため、副作用としてこんなルールが追加されました。
作業時は 必ずリモートワーク(原則在宅)
この話は コロナ前の出来事です。
当時はリモートワークが主流ではなかったのですが、HZT をきっかけに、メンテ作業に関わるメンバーはリモートワーク中心になりました。
結果として:
- 在宅で作業できる
- 集中しやすい環境で作業できる
- 物理的な移動時間も削減できる
というメリットが大きく、むしろ積極的にメンテ作業に手を挙げる人が増えました。
(エンジニアにとって「リモートで働ける価値」がいかに大きいか、身をもって理解した瞬間です)
HZT の効果
HZT を導入してから半年間の結果です。
- 重大トラブル:0件
- 軽微なミスも大幅に減少
- 後日のアンケートでは、「オフィスで複数人で作業するより、リモート環境の方が集中できる」という声が多数
「過度な信用に頼らず、記録と検証で品質を担保する」という意味で、HZT は汎用的な対策としても悪くないと感じています。
8. 最後に
ここからは少しだけ、2025年の視点で振り返った話です。
まず、今回の出来事を通して、
- Zero Trust はセキュリティだけでなく、人間にも有効
ということがわかりました。一方で、同時にこうも感じました。
- 相手を信じること
- 目を見て「任せた」と言うこと
- 同じ部屋で「おつかれ」と笑い合うこと
そういった、人と人との間にあった温度みたいなものが、少しずつ削られていく感覚がありました。
その後、私は退職しました。
ただ、データがある世界は、AIにはやさしい
ネガティブな側面はわかりやすいので、ここからは少しポジティブに考えてみます。
2025年現在、世の中的には 「AIエージェント元年」 と言われています。
どの企業も「Data & AI」と叫び、
- AI には データが必要
- データがなければ 学習も自動化もできない
という話は、もはや前提です。そう考えると今回の HZT のように、
- すべての作業をオンラインで完結させ
- すべてをログと映像で記録し
- すべてを後から検証できる状態にしている
という業務変革をしたのは、AI から見れば最高の土壌です。なぜなら、「そこにデータがある」 からです。
もしかしたら当時の現場は今、AIで物凄く効率化できているかもしれない。
ということで、最後に少しポエムを入れてみました。
HZTはしんどかったけど良い経験になったかな~と思います。