はじめに
Transformerを使用したチャットボットを作ってみました。
単純なEncoder-Decoderモデルだとつまらないので、前の会話の記憶を引き継ぎ、文脈を意識するようなモデルを作ってみました。あまり上手く機能しませんでしたが・・・![]()
モチベーション
通常のEncoder-Decoderモデルでチャットボットを作ろうとすると、直前の発言に対する応答を生成するようなモデルとなります。
一方で、人間の会話は直前の発言だけでなく過去の会話から得られる文脈にしたがって行われます。
そこで、LSTMのように、記憶を引き継ぐようなモデルを作れれば、より自然な会話を行うチャットボットを開発できるのではと考えました。
ソースコード
ソースコードは以下にアップロードしました。
データセット
データセットはTwitterから収集しました。
データ収集に用いるTwitter APIを利用するためには、事前にTwitterの開発者アカウントを取得する必要があります。
英語で少し大変ですが、何度かやりとりをすれば、2, 3日で取得することができます。
検索すると、解説サイトがいろいろ出てくるので、是非それらを参照してください。
Twitterから、ツイートが7回続いた会話を取得し、合計で約9万会話を収集しました。
ツイート数に直すと、約63万ツイートになります。
モデル
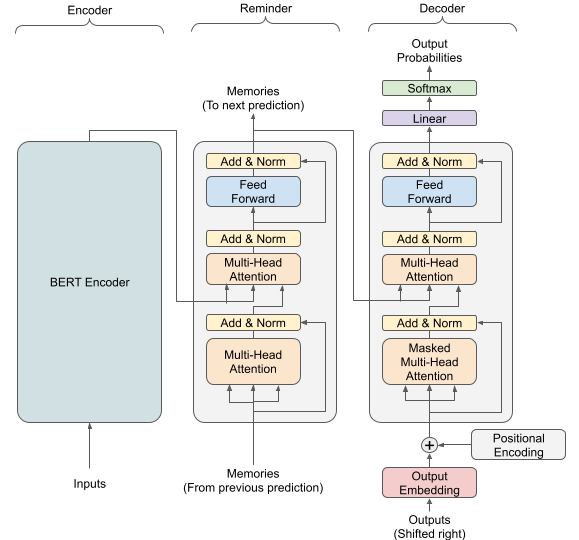
モデルは、以下の図のようにEncoder, Reminder, Decoderの3層構造となっています。
Reminderとは今回提案する手法で、前の会話の記憶を入力し、次の会話のために出力する層になります。
通常の入出力以外に、このように記憶を入出力する層を追加することで、記憶の引継ぎを可能としています。
EncoderにはBERT, ReminderとDecoderにはTransformerをそれぞれ使用しました。
学習
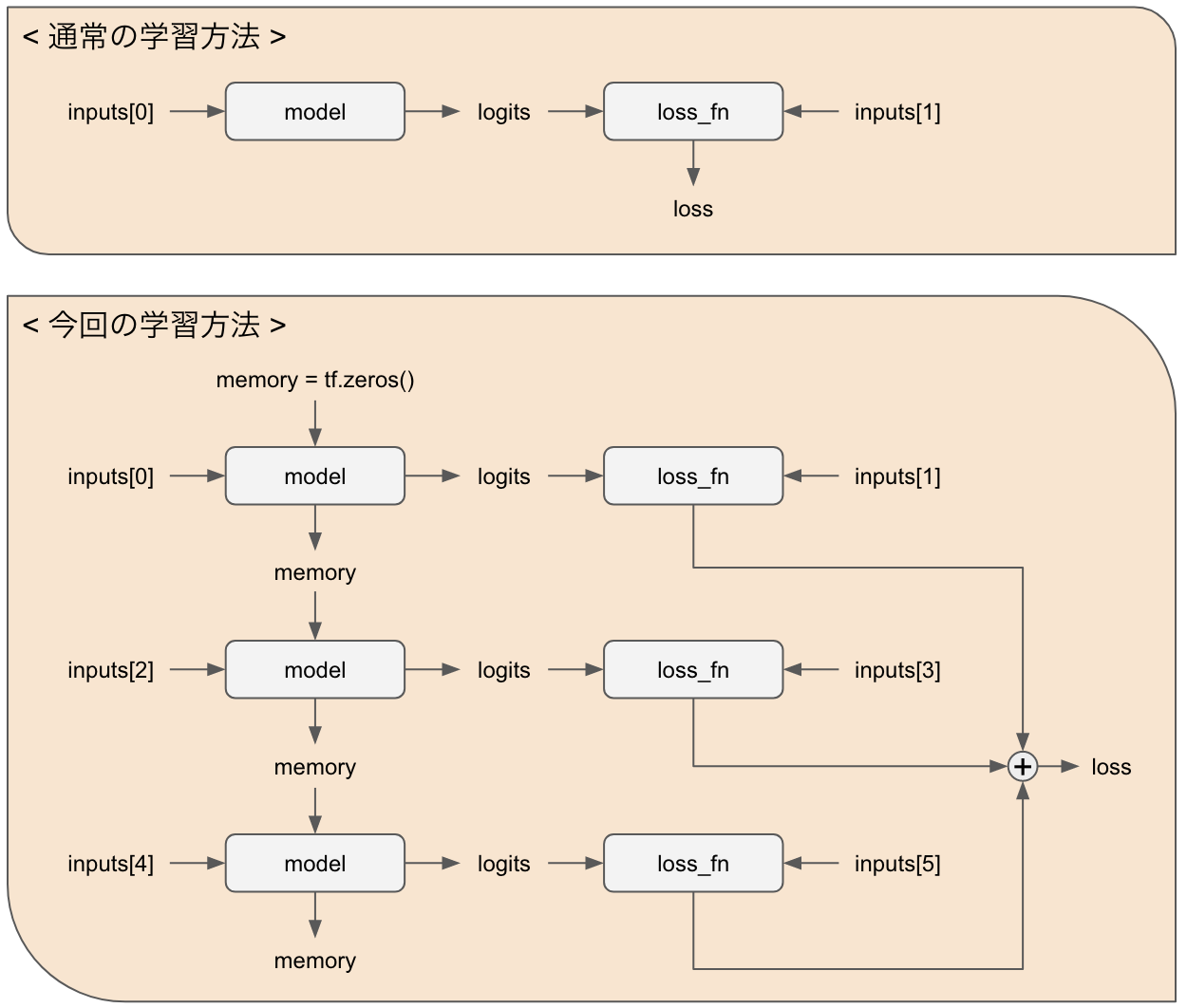
学習では、次の会話に有用な記憶を出力させるために、複数の会話を一気に学習させています。
@tf.function(input_signature=train_step_signature)
def train_step(inputs):
batch_size = tf.shape(inputs[0])[0]
mem = tf.zeros(
(batch_size, dataloader.max_token_length, hidden_size),
dtype=tf.float32)
with tf.GradientTape() as tape:
loss = 0
for i in range(0, len(inputs), 2):
tar_inp, tar_real = inputs[i + 1][:, :-1], inputs[i + 1][:, 1:]
logits, mem = model([inputs[i], mem, tar_inp], True)
loss += loss_fn(logits, tar_real)
gradients = tape.gradient(loss, model.trainable_variables)
opt.apply_gradients(zip(gradients, model.trainable_variables))
train_loss_metric(loss)
# Calc accuracy with last conversation
train_accuracy_metric(tar_real, logits)
# train loop
for step in range(start_steps, total_steps):
inputs = next(train_ds_iter)
# train reply for 0->1, 2->3, 4->5
train_step(inputs[:-1])
# train reply for 1->2, 3->4, 5->6
train_step(inputs[1:])
少し分かりづらいのですが、図にすると以下のようになります。
通常、入力データは前の発言と正解データの2つをとりますが、今回は前の発言と正解データを3組、合計6つの使います。
これにより、3つの会話を同時に学習し、文脈の理解の獲得を目指します。
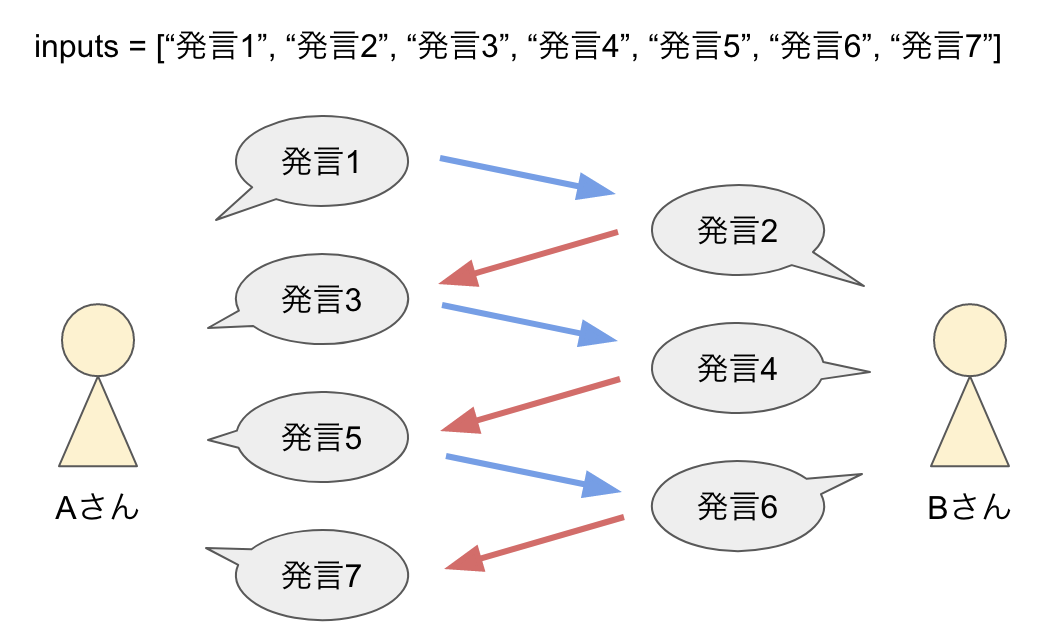
さらに、今回のデータセットは7つの発言(ツイート)からなる会話データの為、3つの会話の組を2組作れます。そこで、1ステップを2回に分けて学習します。
すなわち以下の図で、Bさんから見た会話とAさんから見た会話をそれぞれ学習させることになります。
結果
学習したモデルを用いて会話を行ったところ、以下のようになりました。
残念ながら文脈以前に、直前の会話にもちゃんと返せていないです。
要因の一つとして、今回用いたTwitterの会話データは、会話の分布に偏りがありそうなことが考えられます。また、会話という難易度の高いタスクに対してTransformerレベルのニューラルネットワーク一つでは十分に対応できないのではないかと思われます。

まとめ
今回は、前の文脈を意識した応答を返すようなチャットボットを作る為、新たにReminderという層を組み込んだTransformerを提案しました。
残念ながら、上手く行ったとは言い難いですが、データセットやモデル構造に改善の余地がありそうなことが分かりました。
参考文献
本プログラムの作成にあたって、以下の記事を参考にさせていただきました。