本記事の内容
「Pythonではじめる機械学習」のオライリー本を読んだので備忘録。
副題の通り、scikit-learn の使い方や特徴量エンジニアリング、モデルの評価、パイプラインまでが一通り分かる本。
一般的な内容は6章まででよいかも。
前提知識
いきなり番外編
scikit-learn を使った機械学習の基本的な流れ。
scikit-learn 推定器API
- データの準備
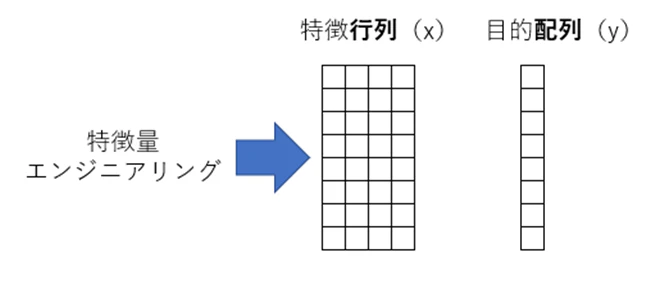
- モデルの選択(import)
- ハイパーパラメータの選択(インスタンス化)
- 訓練データによる学習(fit)
- 新しいデータに適用(predict)
- モデルの評価(metrics)
教師あり学習
各モデルの特徴・長所・短所・パラメーター
k-NN
モデルの構築は訓練データセットを格納するだけなので、シンプルで高速。
予測は最近傍の点を用いる。そのため、訓練データセットが大きくなる(サンプル数、特徴量)と遅くなる。
重要なパラメータ
- n_neighbors:近傍点の数
- データポイント間の距離測度:ユークリッド距離(default)でよい
特徴・注意点
- 前処理(スケーリング、エンコーディング)が必要
- 上手く機能しないケース:
多数の特徴量を持つデータセット
疎なデータセット - モデルを理解しやすい反面、多数の特徴量を扱えないので、ほぼ使われない
(特徴量が少ない時に、ベースラインとして程度)
線形モデル
多数の特徴量をもつデータセットに対して、非常に強力。
特に、特徴量の数 > サンプル数 の時に性能を発揮する(完全に分離できる)。
正則化
-
L1正則化:Lasso
重要な特徴量以外は係数を0にする -
L2正則化:Ridge
デフォルト
重要なパラメータ
正則化パラメータ(対数スケールで探索)
- 回帰モデル:alpha
- 分類モデル:C
特徴・注意点
- 訓練・予測が高速
- 非常に大きいデータセットにも適用可能(それ用のsolverやクラスがある)
- 疎なデータセットにも機能する
ナイーブベイズ クラス分類器
クラスに対する統計値を個々の特徴量ごとに集めて学習する(分類のみ・回帰なし)
3種類の実装
-
GaussianNB
任意の連続値データ・高次元データに対して -
BernoulliNB
2値データ・疎なカウントデータ -
MultinomialNB
カウントデータ(例:単語の出現数)・疎なカウントデータ、大きなドキュメントなどに有効
特徴・注意点
長所・短所は線形モデルと共通する。
非常に(線形モデルよりも)高速。そのため、非常に大規模なデータセットに対するベースラインとなるモデル。
決定木
分類・回帰、どちらにも用いられる。
Yes/No で答えられる質問で構成された階層的な木構造。
重要なパラメータ
複雑さの制御をするため、2種類の枝刈りパラメータが存在する。
-
事前枝刈り:木の生成を早めに止める(どれか1つで十分)
max_depth : 木の深さの最大値
max_leaf_nodes : 葉の数の最大値
min_samples_leaf : 葉のサンプルの最小値 -
事後枝刈り:一度木を構築してから、情報の少ないノードを削除する
(sklearnには実装されていない)
特徴・注意点
- 前処理(スケーリング、エンコーディング)不要
- 特徴量の重要性を可視化できる(feature_importance_)
- 過剰適合しやすく、汎化性能が低い => その場合は、アンサンブル法が有用
- 決定木による回帰モデルは外挿できない:訓練データの外のレンジに対しては予測ができない
決定木のアンサンブル法(1/2): バギング(RandomForest)
多数の決定木の確率予測を平均し、最も確率の高いラベルが予測値となる。
木の生成の際に、少しずつ条件を振る。
多数の弱学習器の組み合わせ。(多数決)
- ブートストラップサンプリング:元のデータポイントから、復元抽出でn_samples回選び出す(同じサイズで一部が欠けたデータセットになる)
- 個々のノードで、特徴量のサブセットをランダムに(max_features 個)選び、その中から最適なテストを選ぶ
重要なパラメータ
- n_estimators : 大きければ大きいほどよいが、時間とメモリの制約がある
- max_features : 特徴量選択の乱数性を決定。小さくなると過剰適合が低減するが、分岐に使う特徴量の選択肢が少なくなり、決定木をかなり深く作らないと適合しない:1 ~ n_features
- max_depth : 事前枝刈りパラメータ
特徴・注意点
- 前処理(スケーリング、エンコーディング)不要
- パラメータもほぼデフォルトでOK
- n_jobs パラメータでコア数を指定:n_jobs = -1 で全てのコアを使う
- テキストデータなど、非常に高次元で疎なデータには上手く機能しない傾向 => その場合は、線形モデル
決定木のアンサンブル法(2/2): ブースティング(GradientBoosting)
直前の決定木の誤りを、次の木が修正するように学習する。
デフォルトでは乱数性は無いが、代わりに、強力な事前枝刈り(深さ:1 ~ 5)が用いられる。
多数の弱学習器(浅い木)の組み合わせ。
重要なパラメータ
パラメータ次第で性能が非常によい。
- learning_rate:学習率(それまでの木の誤りをどれくらい強く補正するか) => 大きくすると複雑に
- n_estimators:木の数 => 増やすと複雑に(時間とメモリ量で決めて、最適な学習率を探索)
- max_depth:非常に小さく、5以上になることはあまり無い
デフォルトでは、深さ3の木が100本、学習率は0.1
特徴・注意点
- 前処理(スケーリング、エンコーディング)不要
- テキストデータなど、非常に高次元で疎なデータには上手く機能しない傾向 => その場合は、線形モデル
- 訓練に時間がかかる
- パラメータの調整が重要
カーネル法を用いた Support Vector Machine
カーネル法:非線形特徴量(i.e. feature x ** 2)をデータ表現に加えることで、線形モデルで扱えるようにする手法。
- 多項式カーネル (polynomial kernel) : 特定の次数までの全ての多項式
- 放射基底関数 (radial basis function : RBF) : 無限次元の特徴空間(ガウシアンカーネル)へマップ
重要なパラメータ
パラメータチューニングが重要(モデルの複雑度を調整)
- C:正則化パラメータ
- gamma:ガウシアンカーネルの幅の逆数(kernel = RBF の場合)
特徴・注意点
- 特徴量の多寡に関わらず機能する
- サンプル数が大きくなると(> 100 K ~)、うまく機能しない(メモリ使用量)
- 前処理(スケーリング)が必要
教師なし学習
アルゴリズムの制約から、新しいデータセットに対して適用できないものが散見される(t-SNE, Agglomerative Clustering, DBSCAN)
次元削減、特徴量抽出、多様体学習
教師あり学習の前処理的な使い方も可能。
- fit_transform # 本記事の内容
「Pythonではじめる機械学習」のオライリー本を読んだので備忘録。
副題の通り、scikit-learn の使い方や特徴量エンジニアリング、モデルの評価、パイプラインまでが一通り分かる本。
6章までで十分。
前提知識
教師あり学習
各モデルの特徴・長所・短所・パラメーター
k-NN
モデルの構築は訓練データセットを格納するだけなので、シンプルで高速。
予測は最近傍の点を用いる。そのため、訓練データセットが大きくなる(サンプル数、特徴量)と遅くなる。
重要なパラメータ
- n_neighbors:近傍点の数
- データポイント間の距離測度:ユークリッド距離(default)でよい
特徴・注意点
- 前処理(スケーリング、エンコーディング)が必要
- 上手く機能しないケース:
多数の特徴量を持つデータセット
疎なデータセット - モデルを理解しやすい反面、多数の特徴量を扱えないので、ほぼ使われない
(特徴量が少ない時に、ベースラインとして程度)
線形モデル
多数の特徴量をもつデータセットに対して、非常に強力。
特に、特徴量の数 > サンプル数 の時に性能を発揮する(完全に分離できる)。
正則化
-
L1正則化:Lasso
重要な特徴量以外は係数を0にする -
L2正則化:Ridge
デフォルト
重要なパラメータ
正則化パラメータ(対数スケールで探索)
- 回帰モデル:alpha
- 分類モデル:C
特徴・注意点
- 訓練・予測が高速
- 非常に大きいデータセットにも適用可能(それ用のsolverやクラスがある)
- 疎なデータセットにも機能する
ナイーブベイズ クラス分類器
クラスに対する統計値を個々の特徴量ごとに集めて学習する(分類のみ・回帰なし)
3種類の実装
-
GaussianNB
任意の連続値データ・高次元データに対して -
BernoulliNB
2値データ・疎なカウントデータ -
MultinomialNB
カウントデータ(例:単語の出現数)・疎なカウントデータ、大きなドキュメントなどに有効
特徴・注意点
長所・短所は線形モデルと共通する。
非常に(線形モデルよりも)高速。そのため、非常に大規模なデータセットに対するベースラインとなるモデル。
決定木
分類・回帰、どちらにも用いられる。
Yes/No で答えられる質問で構成された階層的な木構造。
重要なパラメータ
複雑さの制御をするため、2種類の枝刈りパラメータが存在する。
-
事前枝刈り:木の生成を早めに止める(どれか1つで十分)
max_depth : 木の深さの最大値
max_leaf_nodes : 葉の数の最大値
min_samples_leaf : 葉のサンプルの最小値 -
事後枝刈り:一度木を構築してから、情報の少ないノードを削除する
(sklearnには実装されていない)
特徴・注意点
- 前処理(スケーリング、エンコーディング)不要
- 特徴量の重要性を可視化できる(feature_importance_)
- 過剰適合しやすく、汎化性能が低い => その場合は、アンサンブル法が有用
- 決定木による回帰モデルは外挿できない:訓練データの外のレンジに対しては予測ができない
決定木のアンサンブル法(1/2): バギング(RandomForest)
多数の決定木の確率予測を平均し、最も確率の高いラベルが予測値となる。
木の生成の際に、少しずつ条件を振る。
多数の弱学習器の組み合わせ。(多数決)
- ブートストラップサンプリング:元のデータポイントから、復元抽出でn_samples回選び出す(同じサイズで一部が欠けたデータセットになる)
- 個々のノードで、特徴量のサブセットをランダムに(max_features 個)選び、その中から最適なテストを選ぶ
重要なパラメータ
- n_estimators : 大きければ大きいほどよいが、時間とメモリの制約がある
- max_features : 特徴量選択の乱数性を決定。小さくなると過剰適合が低減するが、分岐に使う特徴量の選択肢が少なくなり、決定木をかなり深く作らないと適合しない:1 ~ n_features
- max_depth : 事前枝刈りパラメータ
特徴・注意点
- 前処理(スケーリング、エンコーディング)不要
- パラメータもほぼデフォルトでOK
- n_jobs パラメータでコア数を指定:n_jobs = -1 で全てのコアを使う
- テキストデータなど、非常に高次元で疎なデータには上手く機能しない傾向 => その場合は、線形モデル
決定木のアンサンブル法(2/2): ブースティング(GradientBoosting)
直前の決定木の誤りを、次の木が修正するように学習する。
デフォルトでは乱数性は無いが、代わりに、強力な事前枝刈り(深さ:1 ~ 5)が用いられる。
多数の弱学習器(浅い木)の組み合わせ。
重要なパラメータ
パラメータ次第で性能が非常によい。
- learning_rate:学習率(それまでの木の誤りをどれくらい強く補正するか) => 大きくすると複雑に
- n_estimators:木の数 => 増やすと複雑に(時間とメモリ量で決めて、最適な学習率を探索)
- max_depth:非常に小さく、5以上になることはあまり無い
デフォルトでは、深さ3の木が100本、学習率は0.1
特徴・注意点
- 前処理(スケーリング、エンコーディング)不要
- テキストデータなど、非常に高次元で疎なデータには上手く機能しない傾向 => その場合は、線形モデル
- 訓練に時間がかかる
- パラメータの調整が重要
カーネル法を用いた Support Vector Machine
カーネル法:非線形特徴量(i.e. feature x ** 2)をデータ表現に加えることで、線形モデルで扱えるようにする手法。
- 多項式カーネル (polynomial kernel) : 特定の次数までの全ての多項式
- 放射基底関数 (radial basis function : RBF) : 無限次元の特徴空間(ガウシアンカーネル)へマップ
重要なパラメータ
パラメータチューニングが重要(モデルの複雑度を調整)
- C:正則化パラメータ
- gamma:ガウシアンカーネルの幅の逆数(kernel = RBF の場合)
特徴・注意点
- 特徴量の多寡に関わらず機能する
- サンプル数が大きくなると(> 100 K ~)、うまく機能しない(メモリ使用量)
- 前処理(スケーリング)が必要
教師なし学習
アルゴリズムの制約から、新しいデータセットに対して適用できないものが散見される(t-SNE, Agglomerative Clustering, DBSCAN)
次元削減、特徴量抽出、多様体学習
- 次元削減:高次元データの可視化 for EDA, 教師あり学習の前処理として
- 特徴量抽出:元のデータ表現よりも解析に適した表現(ピクセル輝度ではなく顔認識)。教師あり学習の前処理として
- 多様体学習:主に非線形データの可視化(2次元の散布図)に用いられる for EDA
fit_transform のみ
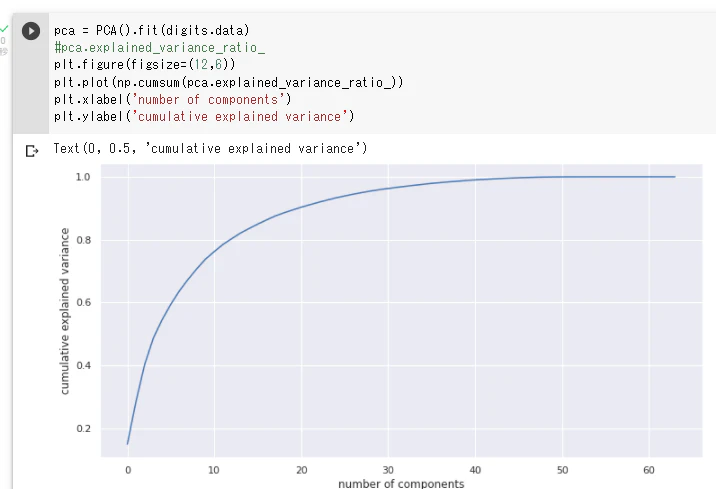
PCA の最適な成分数の見極めには、エルボー法もあるが、分散がどの程度保存されたかを見る方法もある。
クラスタリング
クラスタ中心の数を特徴量以上にすることによって、情報を膨らませ、かつ、上手く分離することが可能。
例:two_moons => 10 のクラスタセンター
- fit_predict => 属するクラスタを予測
- fit_transform => 各 Cluster center からの距離を計算
特徴量エンジニアリング
カテゴリ変数のエンコーディング
- pandas.get_dummies
- sklearn.preprocessing.OneHotEncoder
連続値データの特徴量エンジニアリング
- ビニング:階級を定義して離散化。 np.digitize
- 交互作用特徴量:interaction feature 平たく言うと、複数の特徴量のかけ算
- 多項式特徴量:polynomial feature 平たく言うと、各特徴量の累乗
これらは、特徴量(カラム)を増やすため、線形モデルには効果絶大だが、決定木のように元々モデル自身が複雑なものには効果がない。
単変量非線形変換
入力データに分布の偏りが見られる場合、一様分布に変換することで、性能が良くなる。
例えば、データ(特徴量)の分布に非対称性、特にポアソン分布のような偏りが見られる場合、対数をとることで、ヒストグラムが一様になり、非常に大きい外れ値は無くなる。
これにより線形モデルの性能が改善される。
ただし、線形モデルなどには効果絶大だが、決定木のようにスケールに依存しないものには効果がない。
自動特徴量選択
特徴量を追加し、複雑なモデルを構築すると、計算量に時間がかかるし、モデルの理解も難しい。
そこで、予測に最も有用な特徴量のみを残したい。
制約としては、教師ありデータセットにしか適用できない。
基本的な戦略は、以下3つ。
どれも、以下のパッケージに含まれる。
from sklearn.feature_selection import
- 単変量統計:モデルと完全に独立。ターゲットに関係が深そうな特徴量をp値で探す。 (SelectPercentile)
- モデルベース特徴量:モデルが分析した結果を用いる。モデルの feature_importance_ 属性を用いる。 (SelectFromModel)
- 反復特徴量選択:再帰的特徴量削減(RFE)により、重要度が低い特徴量を1つずつ削除。モデルが分析。モデルの feature_importance_ 属性を用いる。(RFE)
専門家知識
線形モデルでも、特徴量の工夫次第で、複雑なモデルと同程度のスコアが出せる。
特にドメインの専門知識でなくとも、曜日や祝日の情報だけでも、大幅に改善することがある。
モデルの評価・改良
いきなり番外編
本書には記載がないが、「Pythonデータサイエンスハンドブック」の方で記載のあった内容を備忘録。
スコアの改善に向けて
ザックリ言うと、以下2つのアプローチ
1. モデルの改善
モデルの最適な柔軟性(複雑度)を考慮する。(最適なモデル選択がされている前提。)
より複雑度の(高い/低い)モデルが良いか判断するのに検証曲線が役立ち、その想定に応じて、ハイパーパラメータチューニングを行っていく。
検証曲線(validation curve):モデルの複雑度とスコアの関係

2. インプットの改善(水増し作戦)
2-1. 学習サンプルを増やす(特徴行列の行を増加)
スコア改善のヒントを得るために、学習曲線を理解する。
学習曲線(learning curve):学習セットのサイズとスコアの関係
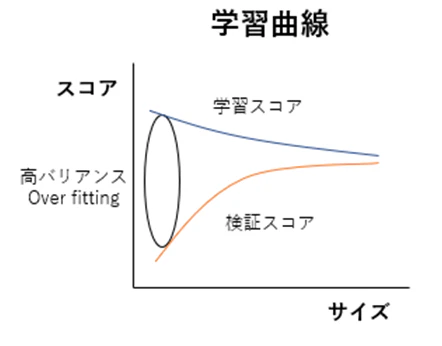
モデルが収束するのに十分なサンプルデータ量があるかどうか。
ある => モデルの複雑度を調整する。特徴量を追加する。
ない => さらなるサンプルデータを準備する。
2-2. 特徴量を追加(特徴行列の列を増加)
特徴量エンジニアリング。離散化(ビニング)・交互作用(掛け算)・多項式(累乗)など。
より複雑度の高いモデルを使えるようになるため、スコアの改善が見込める場合が多い。
k分割交差検証
モデルの評価手法
from sklearn.model_selection import cross_val_score
デフォルト: k=5, cv= KFold (for regression) / StratifiedKFold (for classification)
Stratified : クラス分類タスクのテストデータを分割する際、正解クラスの分布(割合)を保つように分割
cross_val_score(model, data, target, cv=必要に応じて) :モデルは返さない、return は score のみ
cv の例:
- 小さいデータセット: LeaveOneOut()
- Kfold(n_splits=) : 回帰
- StratifiedKFold(n_splits=) : 分類
- GroupKFold(n_splits=) : 時系列、写真からの感情認識の際に同一人物をグルーピング
- 大きいデータセット(回帰): ShuffleSplit(test_size=.3, train_size=.5, n_splits=1)
- 大きいデータセット(分類): StratifiedShuffleSplit(test_size=.3, train_size=.5, n_splits=1)
グリッドサーチ
主にハイパーパラメータチューニングのため
GridSearchCV
メタEstimator = 他の Estimator を用いて作られる Estimator
GridSearchCV(model, param_grid, cv):cv のデフォルトは5
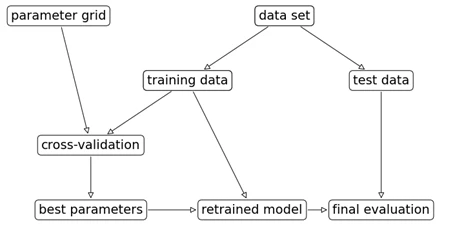
データセットの分割
リークに注意!
前処理も fit は training set のみに対して。
- training set : Model fitting
- validation set : Param selection
- test set : Evaluation
パラメータ選択とモデル評価の流れ
param_grid はリストにできる
組み合わせによっては不要なパラメータもあるので、その際は必要なものだけ指定。
param_grid = [{
'kernel': ['rbf'],
'C': np.logspace(-3, 2, 6),
'gamma': np.logspace(-3, 2, 6)
}, {
'kernel': ['linear'],
'C': np.logspace(-3, 2, 6)
}]
heatmapでの可視化
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
scores = grid_search.cv_results_['mean_test_score'].reshape(6, 6)
sns.heatmap(scores, annot=True, xticklabels=param_grid['gamma'], yticklabels=param_grid['C'], ax=ax, square=True)
ax.set_xlabel('gamma'), ax.set_ylabel('C')

ネストした交差検証
scores = cross_val_score(GridSearchCV(SVC(), param_grid), iris.data, iris.target)
得られるのはスコアのみで、モデルが得られることはないため、未知のデータに適用するための予測モデルを探すために用いられることは、ほとんどない。
(最適なパラメータが何だったかも、得られない・・・)
選択されたモデルの、所与のデータセットに対する性能の評価には有用。
交差検証の評価基準
デフォルトの評価基準は accuracy だが、GridSearchCV、cross_val_score に scoring という引数があり、変更可能。
grid_search = GridSearchCV(SVC(), param_grid, scoring="roc_auc")
# または
cross_val_score(SVC(), digits.data, digits.target == 9, scoring='roc_auc')
評価基準とスコア
評価基準はビジネスアプリケーションを考慮する必要がある。
2クラス分類
偏ったデータセット(現実のデータ)では基準が重要。
混同行列(confusion matrix)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)

この順番が大事。
-
正解率(accuracy):全体に対する正答の割合
accuracy = (TP + TN) / (TP + FP + FN + TN) -
適合性(precision):1と予測した中で、実際に1であった割合
precision = TP / (TP + FP) -
再現性(recall):実際に1であった中で、1と予測した割合
recall = TP / (TP + FN) -
F1スコア(f1 score):適合性と再現性の調和平均
調和平均:逆数の算術平均の逆数
F1 score = \frac{2}{\frac{1}{precision} + \frac{1}{recall}}
classification_report

**キャリブレーション(較正)**は説明割愛
適合率-再現率カーブ (precision_recall_curve):
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(y_test, svc.decision_function(X_test))
plt.plot(precision, recall, label='precision recall curve')
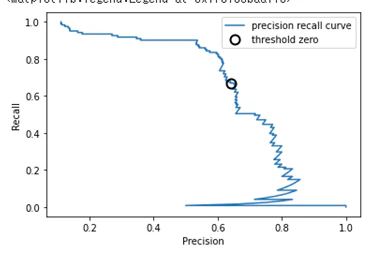
右上を目指す(トレードオフを良く表す)。
decision_function, predict_proba の閾値を調整して、適切な operating point を設定する。
曲線下の面積 : average_precision_score
ROCカーブ (roc_curve):
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, svc.decision_function(X_test))
plt.plot(fpr, tpr, label='ROC curve')

左上を目指す。
曲線下の面積 : AUC (roc_auc_score)
多クラス分類
「特定のクラス」vs「それ以外」としてとらえ、2クラス分類を適用するだけ。
個々のクラスのf1値から、全体の値を出すには以下3通り。
- macro : 個々のクラスを同じ様に重視。クラス毎のf値を平均
- weight : クラスの支持度(サンプル数)で重みづけ(クラス分類レポートのデフォルト)
- micro : 個々のサンプルを同じ様に重視。全クラスの総数で計算
回帰
R^2 決定係数
で十分
パイプライン処理
前処理を validation fold を含めて fit してはいけない(リーク)が、交差検証を用いてハイパーパラメータチューニングする際には非常に面倒になる。
これの解決策がパイプライン。
リストで指定した一連のEstimatorを順次処理できる。
パイプラインの構築
一連のステップをリストとして指定。
各ステップは、「名前」と「Estimatorのインスタンス」のタプルからなる。
from sklearn.pipeline import Pipeline
pipe = Pipeline([('scaler', MinMaxScaler()), ('svm', SVC())])
pipe.fit(X_train, y_train).score(X_test, y_test)
簡便なやり方
make_pipeline を用いると「名前」を指定する必要がない。
ステップ名はクラス名を小文字にしただけのものが使われる。同じクラスが複数ある場合は「-1」などの連番が末尾につく。このような場合は明示的に命名した方がよい。
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(StandardScaler(), PCA())
パイプラインを用いたグリッドサーチ
GridSearchCV の引数でモデルを指定する部分にパイプラインを指定する。
パラメータグリッドを指定する際は、「ステップ名__パラメータ名」で指定する。
grid = GridSearchCV(pipe, param_grid)
grid.fit(X_train, y_train)
属性へのアクセス
# パイプライン全体を確認
pipe.steps
# pca の主成分を確認
pipe.named_steps['pca'].components_
# グリッドサーチの場合
grid = GridSearchCV(pipe, param_grid)
grid.fit(X_train, y_train)
# pca の主成分を確認
grid.best_estimator_.named_steps['pca'].components_
前処理とモデルに対するグリッドサーチ
パイプラインを用いることで、前処理のパラメータとモデルのハイパーパラメータの組み合わせに対するグリッドサーチが効率的にできる。
例:前処理2つ、線形回帰
pipe = make_pipeline(StandardScaler(), PolynomialFeatures(), Ridge())
param_grid = {
'polynomialfeatures__degree': [1,2,3],
'ridge_alpha': np.logspace(-3, 2, 6)
}
grid = GridSearchCV(pipe, param_grid)
grid.fit(X_train, y_train)
グリッドサーチによるモデル(および前処理)の選択
パイプラインとグリッドサーチを組み合わせることで、ハイパーパラメータのみでなく、モデル自体も最適なものをサーチすることが可能。
モデルに応じた前処理も何を用いるかを指定(交換)可能。
パラメータグリッドをディクショナリのリストにすればよい。
例:ランダムフォレストに前処理は不要 vs 線形モデル
pipe = Pipeline([('preprocessing', StandardScaler()), ('classifier', SVC())])
param_grid = [
{
'classifier': [SVC()],
'preprocessing': [StandardScaler()],
'classifier__gamma': np.logspace(-3, 2, 6),
'classifier__C': np.logspace(-3, 2, 6)
}, {
'classifier': [RandomForestClassifier(n_estimators=100)],
'preprocessing': [None],
'classifier__max_features': [1, 2, 3]
}
]
grid = GridSearchCV(pipe, param_grid)
grid.fit(X_train, y_train)
まとめ
この本1冊で scikit-learn の使い方が非常に良く分かる。
ライブラリのコントリビューターが著者なので、当然と言えば当然だが。。。
なお、本書の前に「Pythonデータサイエンスハンドブック」も通読したが、そちらも非常にオススメ。