はじめに
以前、「Pylearn2で三目並べのAIをつくってみる」という記事を書きました。
このときは問題を簡単にして三目並べにしましたが、今回はオセロのAIをニューラルネットワークで作成するという当初の目標にチャレンジします。
トライ&エラーが多い記事になるかもしれませんがご容赦ください。
今回はDeep Learning用ライブラリとしてChainerを使ってみます。
記事は2部構成です。
- 前編(この記事)
- 教師データの変換
- MLPの設計
- モデルのトレーニングと保存
-
後編
- オセロゲームへの実装
- プレイアブルかどうかの確認(ルールを逸脱せずにゲームできるか)
- ここでプレイアブルでないと分かったら、MLPモデルの作成に戻る
後編でAIの実装を行いますが、上手くいかなければ、ニューラルネットワークの構成から考え直すことになります...
→動作確認と結論が出ました
教師データの準備
こちらから棋譜データを拝借させていただきました。
ggf形式で保存されている大量の対戦データです。
テキスト形式で可読性があります。
MLPの設計
まずは、入力と出力を決めます。
オセロのAIを作成するので、入力を盤面の状態とし、その次の一手を出力とします。
図で書くと以下のイメージです。
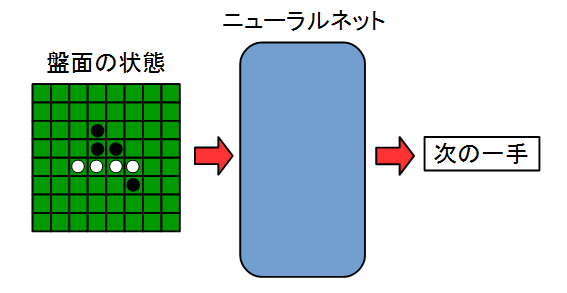
具体的にニューラルネットに落とし込みます。
入力は盤面の状態、つまり 8 x 8 のベクトルとします。
ベクトルの要素は、'0' : なし、'1' : 黒、'2' : 白とします。
出力は盤面のどこに次の一手を打つか、でクラス分けするので64通りなのですが、取りうる場合としてはPassをする場合もありますので、全部で65通りにクラス分けすることになります。
0~63で盤面位置を表し、Passを64とします。
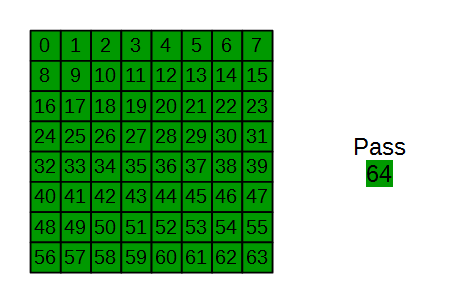
あとは隠れ層の設計です。
とりあえず、2層、ともにニューロン数100としています。
ここの設計を理論的にやるにはどうすればいいのか...
図に表すと以下のようになります。
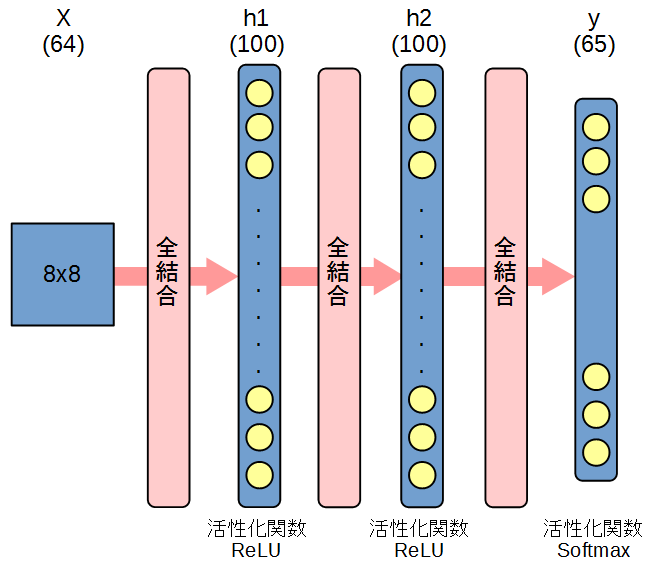
実装
以下を行うpythonのプログラムを示します。
- 教師データの読み込みと変換
- ChainerによるMLPモデル作成と保存、トレーニング
- 簡単なテスト
#!/usr/bin/env python
# coding=utf-8
#
# 0 : none
# 1 : black
# 2 : white
#
import sys
import numpy as np
import chainer
from chainer import cuda, Function, gradient_check, report, training, utils, Variable
from chainer import datasets, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
gVec = [(-1,-1),(-1,0),(-1,1),(0,-1),(0,1),(1,-1),(1,0),(1,1)]
gCol = ('A','B','C','D','E','F','G','H')
gRow = ('1','2','3','4','5','6','7','8')
# (1)
class MLP(Chain):
def __init__(self):
super(MLP, self).__init__(
l1=L.Linear(64, 100),
l2=L.Linear(100, 100),
l3=L.Linear(100, 65),
)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
return y
class Classifier(Chain):
def __init__(self, predictor):
super(Classifier, self).__init__(predictor=predictor)
def __call__(self, x, t):
y = self.predictor(x)
loss = F.softmax_cross_entropy(y, t)
accuracy = F.accuracy(y, t)
report({'loss': loss, 'accuracy': accuracy}, self)
return loss
def print_board(board):
for i in range(8):
print board[i]
print ""
def update_board(board, pos_str, clr):
assert clr!=0, "stone color is not black or white."
updated_board = [[0 for col in range(8)] for row in range(8)]
rev_list = []
pos = pos_str2pos_index(pos_str)
for v in gVec:
temp_list = []
for i in range(1, 8):
# out of board
if pos[0]+v[0]*(i+1) > 7 or pos[1]+v[1]*(i+1) > 7 or\
pos[0]+v[0]*(i+1) < 0 or pos[1]+v[1]*(i+1) < 0:
continue
if board[pos[0]+v[0]*i][pos[1]+v[1]*i] == (clr % 2 + 1):
temp_list.append([pos[0]+v[0]*i, pos[1]+v[1]*i])
if board[pos[0]+v[0]*(i+1)][pos[1]+v[1]*(i+1)] == clr:
for j in temp_list:
rev_list.append(j)
break
else:
break
rev_list.append(pos) # put stone at pos
assert board[pos[0]][pos[1]] == 0, "put position is not empty."
print "rev_list = " + str(rev_list)
for i in range(0, 8):
for j in range(0, 8):
if [i, j] in rev_list:
updated_board[i][j] = clr
else:
updated_board[i][j] = board[i][j]
return updated_board
def who_is_winner(board):
# ret : 0 draw
# 1 black win
# 2 white win
ret = 0
score_b = 0
score_w = 0
for i in range(0, 8):
for j in range(0, 8):
if board[i][j] == 1:
score_b += 1
elif board[i][j] == 2:
score_w += 1
if score_b > score_w:
ret = 1
elif score_b < score_w:
ret = 2
print "Black vs White : " + str(score_b) + " vs " + str(score_w)
return ret
def pos_str2pos_index(pos_str):
pos_index = []
for i, c in enumerate(gRow):
if pos_str[1] == c:
pos_index.append(i)
for i, c in enumerate(gCol):
if pos_str[0] == c:
pos_index.append(i)
return pos_index
def pos_str2pos_index_flat(pos_str):
pos_index = pos_str2pos_index(pos_str)
index = pos_index[0] * 8 + pos_index[1]
return index
#==== Main ====#
record_X = [] # MLP input (board list)
record_y = [] # MLP output(class(0-64) list)
temp_X = []
temp_y = []
temp2_X = []
temp2_y = []
board = []
row = []
argv = sys.argv
argc = len(argv)
if argc != 3:
print 'Usage'
print ' python ' + str(argv[0]) + ' <record_filename> <type>'
print ' type : black'
print ' black_win'
print ' white'
print ' white_win'
quit()
# check type
build_type = ''
for t in ['black', 'black_win', 'white', 'white_win']:
if argv[2] == t:
build_type = t
if build_type == '':
print 'record type is illegal.'
quit()
#(2)-- load record --#
f = open(argv[1], "r")
line_cnt = 1
for line in f:
print 'Line Count = ' + str(line_cnt)
idx = line.find("BO[8")
if idx == -1:
continue
idx += 5
# make board initial state
for i in range(idx, idx+9*8):
if line[i] == '-':
row.append(0)
elif line[i] == 'O':
row.append(2)
elif line[i] == '*':
row.append(1)
if (i-idx)%9 == 8:
board.append(row)
row = []
if len(board) == 8:
break
row = []
print_board(board)
# record progress of game
i = idx+9*8+2
while line[i] != ';':
if (line[i] == 'B' or line[i] == 'W') and line[i+1] == '[':
temp_X.append(board)
pos_str = line[i+2] + line[i+3]
if pos_str == "pa": # pass
temp_y.append(64)
# board state is not change
print_board(board)
else:
if line[i] == 'B':
clr = 1
elif line[i] == 'W':
clr = 2
else:
clr = 0
assert False, "Stone Color is illegal."
pos_index_flat = pos_str2pos_index_flat(pos_str)
temp_y.append(pos_index_flat)
board = update_board(board, pos_str, clr)
if (line[i] == 'B' and (build_type == 'black' or build_type == 'black_win')) or \
(line[i] == 'W' and (build_type == 'white' or build_type == 'white_win')):
temp2_X.append(temp_X[0])
temp2_y.append(temp_y[0])
print 'X = '
print_board(temp_X[0])
print 'y = ' + str(temp_y[0]) + ' (' + \
str(pos_str2pos_index(pos_str)) + ') ' + \
'(' + pos_str + ')'
print ''
temp_X = []
temp_y = []
i += 1
print "End of game"
print_board(board)
winner = who_is_winner(board)
if (winner == 1 and build_type == 'black_win') or \
(winner == 2 and build_type == 'white_win') or \
build_type == 'black' or build_type == 'white':
record_X.extend(temp2_X)
record_y.extend(temp2_y)
board = []
temp2_X = []
temp2_y = []
line_cnt += 1
#(3)-- MLP model and Training --#
X = np.array(record_X, dtype=np.float32)
y = np.array(record_y, dtype=np.int32)
train = datasets.TupleDataset(X, y)
train_iter = iterators.SerialIterator(train, batch_size=100)
model = Classifier(MLP())
optimizer = optimizers.SGD()
optimizer.setup(model)
updater = training.StandardUpdater(train_iter, optimizer)
trainer = training.Trainer(updater, (1000, 'epoch'), out='result')
trainer.extend(extensions.ProgressBar())
trainer.run()
#(4)-- save model --#
serializers.save_npz('reversi_model.npz', model)
#(5)-- prediction example --#
X1_ = [[[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,2,1,0,0,0],\
[0,0,0,1,2,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0]]]
X1 = np.array(X1_, dtype=np.float32)
y1 = F.softmax(model.predictor(X1))
print "X1 = "
print_board(X1[0])
print "y1 = " + str(y1.data.argmax(1)) + '\n'
X2_ = [[[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,2,2,2,0,0,0],\
[0,0,2,1,1,1,0,0],\
[0,2,2,2,1,1,0,0],\
[0,0,2,1,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0]]]
X2 = np.array(X2_, dtype=np.float32)
y2 = F.softmax(model.predictor(X2))
print "X2 = "
print_board(X2[0])
print "y2 = " + str(y2.data.argmax(1)) + '\n'
簡単に解説していきます。コード内の(1)~(5)と対応させて読んでください。
(1) ChainerのMLP定義
MLPクラスでMLPの構造を定義します。前述のとおり、入力=8x8=64、出力=65、隠れ層2層(ニューロン数100)で定義しています。
活性化関数と層構造は _call_ 内で定義しています。
ClassifierクラスでSoftmaxでのクラス分けを定義しています。
(2) 棋譜の読み込みと変換
長いループですが、棋譜の読み込みと、それを入力(8x8)と出力(0~64)に変換しています。
プログラミングの何が大変ってここが一番大変でした...
(3) MLPモデルのトレーニング
変換した棋譜をモデルに入力してトレーニングします。
入力、出力ともにNumpyのarray形式にして、dataset.TupleDataset で設定できます。
この際、型に注意してください。
あとはソースコードのように
- batch_sizeの設定
- 最適化方法(今回はSGD)の設定
- 実行回数(epoch)の設定
を行います。
trainer.run でトレーニング実行です。
(4) モデルの保存
トレーニング済みのモデルを保存します。NPZ形式です。
後編でオセロゲームにインプリするときに使用します。
(5) 簡単なテスト
トレーニング済みのモデルで正しく次の一手を導出できるかを試します。
実行結果の例は以下のようになります。
教師データとして'Othello.01e4.ggf'を使用し、先手(黒)の勝利したデータだけでAIの作成を行っています。
$ python build_mlp.py Othello.01e4.ggf black_win
...
X1 =
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 2. 1. 0. 0. 0.]
[ 0. 0. 0. 1. 2. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
y1 = [37]
X2 =
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 2. 2. 2. 0. 0. 0.]
[ 0. 0. 2. 1. 1. 1. 0. 0.]
[ 0. 2. 2. 2. 1. 1. 0. 0.]
[ 0. 0. 2. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0.]
y2 = [25]
トレーニングにGPUは使用しないように書いています。
実行すると貧弱なPCだと1時間くらいかかると思います。
Chainerの機能でProgress Barが表示されるようにしていますので、ご自身の環境で行う場合にはまともな時間で完了するのかどうかの参考にしてください。
また、例では Othello.01e4.ggf を使用していますが、想定フォーマットを逸脱しているデータが2件(85行目、2699行目)あったので、削除して実行しました。
結果に表示されているprediction exampleを見ると、AIは次のように打つと分かります。
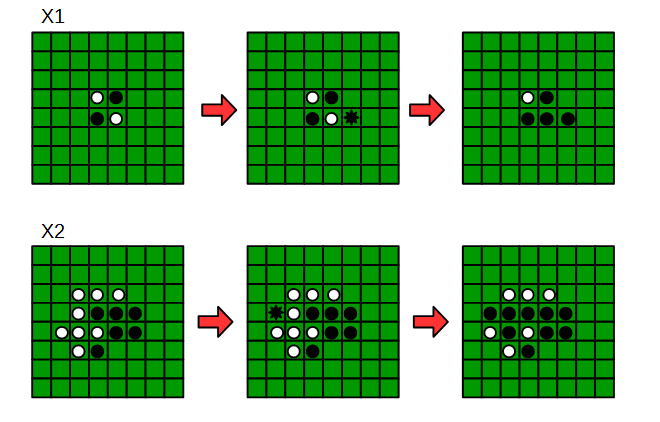
2通りだけですが、簡単なテストでは上手く次の一手を導出できているようです。
後編では、このトレーニング済みのモデルを実際にオセロゲームにAIとしてインプリして、オセロの動作を確認します。
→動作確認と結論が出ました。