はじめに
pylearn2でDeep Learningしてみたい。でもチュートリアルの画像判別やってるだけだとよく分からない。ということで、三目並べ(いわゆる○×ゲーム)のAIを作ってみようと思います。
本当はオセロのAIを作ってみたかったのですが、pylearn2を使用するのが初めてなので、より簡単なゲームを選びました。
ちなみに機械学習、pylearn2初心者です。間違いなどあればご指摘ください。
pylearn2、およびnumpyなどの必要なパッケージのインストール手順は省きます。
ニューラルネットの設計
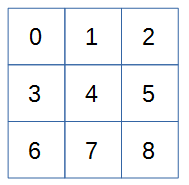
三目並べのAIなので、まずは盤面上の状態を表すために、3x3のボードのマスに番号を振ります。
3x3の盤面のとある状態を入力とし、次の手の位置が出力となるようにします。そこで以下のようなネットワークを考えます。
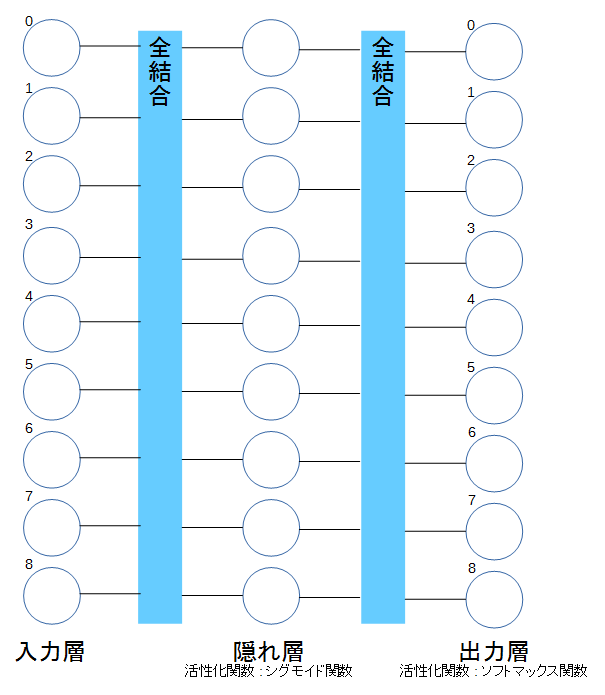
入力と出力の丸の肩にある番号は盤面上のマスの番号です。
9つの入力、つまり9マスの状態を入力とします。隠れ層を一層とし、活性化関数をシグモイド関数とします。出力は9つのクラスに分けるので、ソフトマックス関数を使用します。
ここで、「9つのクラスに分ける」とは、ある入力(盤面の状態)に対して、次の一手をどのマスに打つかでクラス分けする、という意味になります。つまり、0にクラス分けされた場合は、0のマスに次の一手を打つ、となります。
教示データの作成
今回作成するAIは強さを追求しません。教示データからルールを逸脱せずにゲームを進めてくれれば御の字、と割りきっています。そのため、最善手を打っている対戦データだけを集めるのではなく、単にルールに則って対戦しているデータを大量に用意します。
大量の対戦データの生成をするために、先手、後手ともにランダムに置ける場所に置いていくだけのRubyスクリプトを作成しました。なぜpythonで書かないんだと言われそうですが、最近pythonばっかり書いていて飽きた、というだけで深い意味はありません。
先手が〇、後手が×です。
引数にLoop回数を指定して実行すると、棋譜が作成できます。これを教示データとします。
数字は置いたマスの番号、末尾のwin,loseは先攻の勝敗を示しています。
# !/usr/bin/env ruby
#
# tic tac toe
#
# 0 : O (first)
# 1 : X (second)
# 2 : none
#
def show_board(array)
p array[0][0].to_s + "," + array[0][1].to_s + "," + array[0][2].to_s
p array[1][0].to_s + "," + array[1][1].to_s + "," + array[1][2].to_s
p array[2][0].to_s + "," + array[2][1].to_s + "," + array[2][2].to_s
p ""
end
def judge(array)
ret = 2
for stone in [0, 1] do
for i in [0 ,1, 2] do
if (array[i][0]==stone && array[i][1]==stone && array[i][2]==stone) ||
(array[0][i]==stone && array[1][i]==stone && array[2][i]==stone) then
ret = stone
end
end
if (array[0][0]==stone && array[1][1]==stone && array[2][2]==stone) ||
(array[0][2]==stone && array[1][1]==stone && array[2][0]==stone) then
ret = stone
end
end
return ret
end
loop_max = ARGV[0].to_i
# p "loop max=" + loop_max.to_s
cell_array = []
stone_array = []
loop_cnt = 0
until loop_cnt >= loop_max do
cell_array = Array.new(9)
stone_array = Array.new(3).map { Array.new(3, 2) }
9.times do |num|
cell_array[num] = num
end
i = 10
history = []
9.times do |num|
#p i
rnd = rand(i) - 1
if num % 2 == 0
stone_array[cell_array[rnd].divmod(3)[0]][cell_array[rnd].divmod(3)[1]] = 0
else
stone_array[cell_array[rnd].divmod(3)[0]][cell_array[rnd].divmod(3)[1]] = 1
end
history.push(cell_array[rnd])
#show_board(stone_array)
ret = judge(stone_array)
if ret == 0 then
history.push("win") # "O" is winner.
break
elsif ret == 1 then
history.push("lose") # "O" is loser.
break
end
cell_array.delete_at(rnd)
i -= 1
end
p history.join(",")
loop_cnt += 1
end
$ ruby tic_tac_toe.rb 500 | tee tic-tac-toe_records.log
"6,8,3,4,2,0,lose"
"7,1,4,5,0,2,8,win"
"6,2,3,0,5,8,1,7,4,win"
"3,8,4,2,6,5,lose"
"1,8,2,7,3,0,6,4,lose"
"8,0,3,6,7,4,1,2,lose"
"6,8,3,5,2,7,4,win"
"2,1,7,4,3,5,8,6,0"
"4,8,6,7,1,3,2,win"
"6,1,3,0,8,7,5,4,lose"
"8,2,7,1,4,3,0,win"
"8,6,1,2,7,0,3,4,lose"
"4,3,8,1,2,6,7,0,lose"
"8,6,3,4,1,5,7,2,lose"
"1,2,0,4,7,8,5,6,lose"
"0,5,2,3,6,7,8,4,lose"
"7,1,2,6,4,5,0,3,8,win"
"2,1,0,8,3,5,7,4,6,win"
"2,0,8,5,6,7,4,win"
...
この棋譜データを入力として使用しやすいようにcsvに加工しておきます。今回は後攻の手を決めるAIを作るため後攻が勝利したものだけ抜き出しています。
$ awk '{gsub("\"","");print $0;}' tic-tac-toe_records.log | grep lose | tee tic-tac-toe_records_lose.csv
加工後はこうなります。
6,8,3,4,2,0,lose
3,8,4,2,6,5,lose
1,8,2,7,3,0,6,4,lose
8,0,3,6,7,4,1,2,lose
...
これで準備は完了です。
pylearn2を使用したMLPモデル
まずソースコードを示します。
# !/usr/bin/env python
# -*- cording: utf-8 -*-
import theano
from pylearn2.models import mlp
from pylearn2.training_algorithms import sgd
from pylearn2.termination_criteria import EpochCounter
from pylearn2.datasets.dense_design_matrix import DenseDesignMatrix
import numpy as np
import csv
class TicTacToe(DenseDesignMatrix):
def __init__(self):
X = []
y = []
X_temp = [0,0,0,0,0,0,0,0,0] # 3x3 board
y_temp = [0,0,0,0,0,0,0,0,0] # 3x3 board
# (1)
self.class_names = ['0', '3']
f = open("tic-tac-toe_records_lose.csv", "r")
reader = csv.reader(f)
# (2)
for row in reader:
for i, cell_index in enumerate(row):
if cell_index == "win" or cell_index == "lose":
X_temp = [0,0,0,0,0,0,0,0,0]
elif i % 2 == 0:
temp = []
X_temp[int(cell_index)] = 1
for x in X_temp:
temp.append(x)
#print " temp = " + str(temp)
X.append(temp)
else:
X_temp[int(cell_index)] = 2
y_temp[int(cell_index)] = 3
#print "y_temp = " + str(y_temp)
y.append(y_temp)
y_temp = [0,0,0,0,0,0,0,0,0]
X = np.array(X)
y = np.array(y)
super(TicTacToe, self).__init__(X=X, y=y)
# (3)
data_set = TicTacToe()
h0 = mlp.Sigmoid(layer_name='h0', dim=9, irange=.1, init_bias=1.)
out = mlp.Softmax(layer_name='out', n_classes=9, irange=0.)
trainer = sgd.SGD(learning_rate=.05, batch_size=200, termination_criterion=EpochCounter(5000))
layers = [h0, out]
ann = mlp.MLP(layers, nvis=9)
trainer.setup(ann, data_set)
# (4)
while True:
trainer.train(dataset=data_set)
ann.monitor.report_epoch()
ann.monitor()
if trainer.continue_learning(ann) == False:
break
# (5)-1
next_move = [0,0,0,0,0,0,0,0,0]
inputs = np.array([[0,0,1,0,0,0,0,0,0]])
output = ann.fprop(theano.shared(inputs, name='inputs')).eval()
print output[0]
for i in range(0,9):
if max(output[0]) == output[0][i]:
next_move[i] = 3
print next_move
# (5)-2
next_move = [0,0,0,0,0,0,0,0,0]
inputs = np.array([[1,0,2,1,0,0,0,1,2]])
output = ann.fprop(theano.shared(inputs, name='inputs')).eval()
print output[0]
for i in range(0,9):
if max(output[0]) == output[0][i]:
next_move[i] = 3
print next_move
少し解説していきます。コード上の(1), (2)...と対応させて読んでください。
前提として、〇を"1", ×を"2", 何も置いていないマスを"0"としています。
(教示データの作成に使用したrubyのコードとは異なります。分かりにくくてすいません。)
(1) 出力の値の設定
出力の値としてとる値。入力に0,1,2を使用しているので、出力には3を使用することにしました。
(2) 棋譜の変換
読み込んだ棋譜をニューラルネットの入力と出力に対応させます。
例えば、棋譜の入力が"6,8,3,4,2,0,lose"の場合、以下のような展開になります。
棋譜 : 6,8,3,4,2,0,lose
X[n] = [0,0,0,0,0,0,1,0,0] : "6"の位置に"〇"、つまり"1"を入力
y[n] = [0,0,0,0,0,0,0,0,3] : 次の手は"8"の位置に"×"なので、"8"の位置に"3"が出力
X[n+1] = [0,0,0,1,0,0,1,0,2] : "8"の位置に"×"、つまり"2", 次は"3"の位置に"〇"、つまり"1"を入力
y[n+1] = [0,0,0,0,3,0,0,0,0] : 次の手は"4"の位置に"×"なので、"4"の位置に"3"が出力
X[n+2] = [0,0,1,1,2,0,1,0,2] : "4"の位置に"×"、つまり"2", 次は"2"の位置に"〇"、つまり"1"を入力
y[n+2] = [3,0,0,0,0,0,0,0,0] : 次の手は"0"の位置に"×"なので、"0"の位置に"3"が出力
(3) MLP構造記述
隠れ層h0をシグモイド関数を活性化関数として、dim(次元)=9(マスの数)で生成します。
irange, init_biasは適当です。
出力層outをソフトマックス関数を活性化関数として、n_classes(クラス分け数)=9(マスの数)で生成します。
irangeは適当です。
確率的勾配降下法でトレーニングします。
learning_rate, batch_sizeは適当です。termination_criterionはいつトレーニングを終了するかを指定します。
ann = mlp.MLP(layers, nvis=9)
上記ではMLPの構造を指定しています。nvisは入力の次元=9(マスの数)です。
(4) トレーニング
トレーニングのループです。途中経過のモニターも出しています。
(5) テスト
ある入力(inputs)に対する出力がどうなるかテストします。
9つのクラスの確率(output[0])の最も大きい個所を次の手(next_move)とします。
プログラムを実行したときの出力は以下のようになります。
$ python tic_tac_toe.py
Parameter and initial learning rate summary:
h0_W: 0.05
h0_b: 0.05
softmax_b: 0.05
softmax_W: 0.05
Compiling sgd_update...
Compiling sgd_update done. Time elapsed: 0.203131 seconds
compiling begin_record_entry...
compiling begin_record_entry done. Time elapsed: 0.003911 seconds
Monitored channels:
Compiling accum...
Compiling accum done. Time elapsed: 0.000039 seconds
Monitoring step:
Epochs seen: 1
Batches seen: 3
Examples seen: 542
Monitoring step:
Epochs seen: 2
Batches seen: 6
Examples seen: 1084
...
Monitoring step:
Epochs seen: 5000
Batches seen: 15000
Examples seen: 2710000
Monitoring step:
Epochs seen: 5001
Batches seen: 15003
Examples seen: 2710542
[ 0.07985083 0.10700001 0.00255253 0.15781951 0.08504663 0.16470689
0.11459433 0.12293593 0.16549335]
[0, 0, 0, 0, 0, 0, 0, 0, 3]
[ 2.56981722e-03 1.25923571e-01 2.05250923e-04 6.14268028e-04
1.85819252e-02 2.43921569e-02 8.27328217e-01 3.84348076e-04
4.45556802e-07]
[0, 0, 0, 0, 0, 0, 3, 0, 0]
以上から、
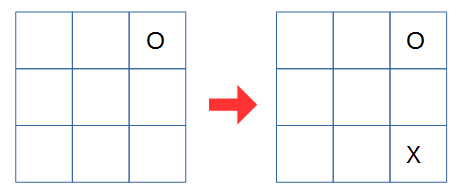
入力が [0,0,1,0,0,0,0,0,0] の場合の次の手は [0,0,0,0,0,0,0,0,3] です。つまり以下の図のようにAIは打ちます。
入力が [1,0,2,1,0,0,0,1,2] の場合の次の手は [0,0,0,0,0,0,3,0,0] です。つまり以下の図のようにAIは打ちます。
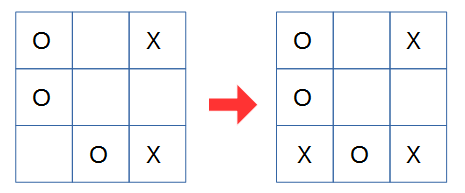
うーん、"5"の位置に"X"を打てば勝利して終了なのですが、"O"のリーチを止めに行ってますね。まぁ、ランダムな棋譜を元にしている割には、まぁまぁでしょうか。
毎度ソースコードをいじらないといけないので、ちょっと面倒ですが、任意の入力に対する次の一手を得られました。
今後は一度のトレーニング結果を元に、任意の入力に対する次の一手を簡単に得られるようにして、三目並べのゲームに実装してみようと思います。まずは三目並べのゲームプログラムを作らねば。
つくりました。以下の記事をご覧ください。
Pylearn2で三目並べのAIをつくってみる - モデルの保存と読み込み -
参考
http://www.arngarden.com/2013/07/29/neural-network-example-using-pylearn2/
[http://sinhrks.hatenablog.com/entry/2014/11/30/085119]
(http://sinhrks.hatenablog.com/entry/2014/11/30/085119)
https://www.safaribooksonline.com/blog/2014/02/10/pylearn2-regression-3rd-party-data/