はじめに
この記事は「ChainerでオセロのAIをつくってみる ~前編~」の続編です。
この記事を読む前に前編をお読みいただけると幸いです。
-
教師データの変換
-
MLPの設計
-
モデルのトレーニングと保存
-
後編(この記事)
-
オセロゲームへの実装
-
プレイアブルかどうかの確認(ルールを逸脱せずにゲームできるか)
- ここでプレイアブルでないと分かったら、MLPモデルの作成に戻る
というわけで、前編で作成したトレーニング済みのモデルを使用して、MLPモデルを使用したAIをオセロゲームに実装しました。
オセロゲームアプリは「wxPythonでオセロをつくろう」で作成したものを流用します。
オセロゲームアプリのソースコードやトレーニング済みのモデルはGitHubに上げてありますので、そちらから取得してください。
オセロゲームアプリ説明
wxPythonで作成したアプリです。動作にはwxPythonのインストールが必要です。インストール方法はこちらなどをご覧ください。
起動方法は以下です。
$ python reversi.py
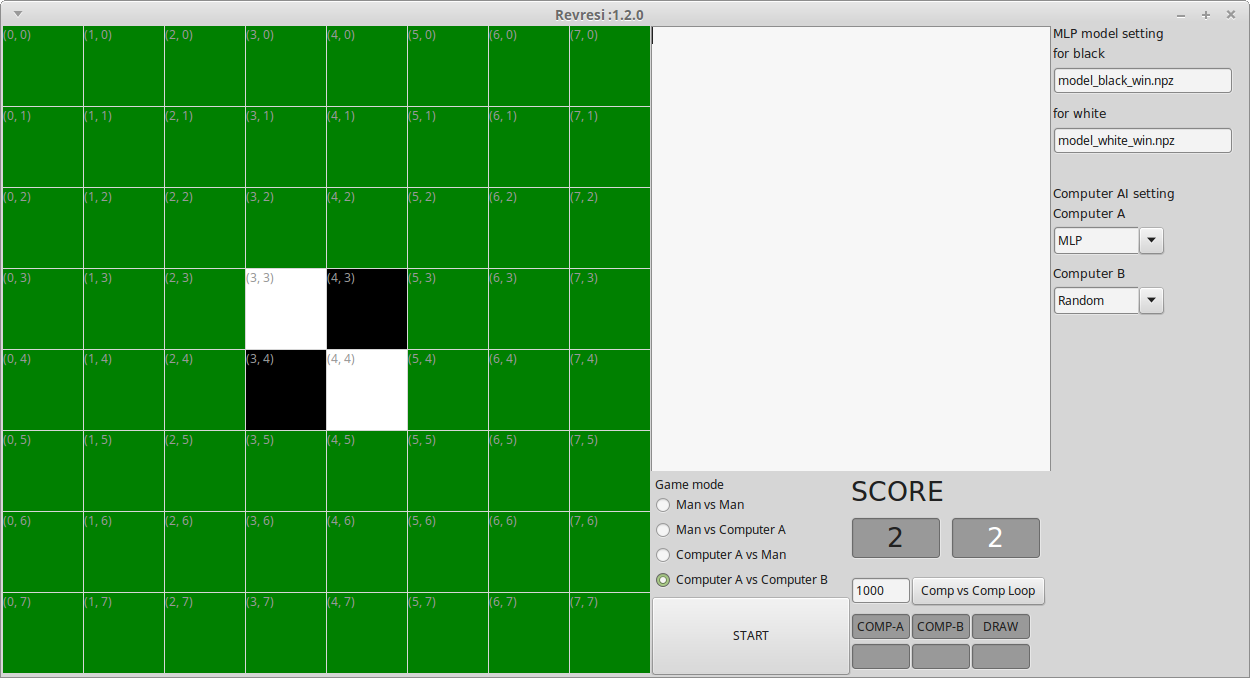
簡単に画面の説明をします。
右端の"MLP model setting"でMLPによるAIのためのモデルを指定します。"for black"に先手(黒)用のモデルを、"for white"に後手(白)用のモデルを指定します。
同じく右端の"Computer AI setting"でComputerのAIを指定します。AIの詳細は後述します。
中央の空白エリアにはゲームが進むごとに棋譜を表示します。
中央下部の"Game mode"でGameの種類を設定し、"START"ボタンでゲームを開始します。
- Man vs Man
- 人間同士の対戦。左クリックで石を置きます。先手が黒です。
- Man vs Computer A
- 人間 vs Computer A。人間が先手(黒)です。ComputerのAIは"Computer AI setting"でComputer Aとして設定したものになります。
- Computer A vs Man
- Computer A vs 人間。Computer Aが先手(黒)です。
- Computer A vs Computer B
- Computer同士の対戦を行います。
中央下部の"SCORE"は現在の先手(黒)、後手(白)の石の数です。
中央下部のテキストボックスにLoop回数を入れ、"Comp vs Comp Loop"ボタンを押すと、Computer AとComputer Bの対戦を指定回数連続で行います。
(このときは"START"ボタンは使いません)
Loopが終了すると、Computer AとComputer Bのそれぞれの勝利数が表示されます。DRAWは引き分けた数です。
このオセロアプリは通常の対戦ができるだけでなく以下の機能があります。
-
Computer AIの選択ができる。(MLP以外のAIについての詳細はこちら)
- MLP
- トレーニング済みMLPモデルを使用したAI。今回の検証対象です。
- 1st Gain Max
- 盤面に評価値を設定し、自手で取れる石の場所の評価値の合計が高くなる場所に置くAI。
- Min Max 3
- Min-Max法で3手先読みするAI。だが非常に弱い。たぶん何かが間違ってる。
- Random
- 置ける場所にランダムに置いていくAI。
- MLP
-
MLPモデルを使用したAIを選択しており、AIがルールを逸脱した手を選択した場合に標準エラー出力に"Illegal move! ..."を出力する。種類は以下の通り。なお、Illegal move!が発生した場合のComputerの手は、石が置けるならば、その中で最初に見つかった場所に置き、パスをしなければならないときは、パスしてゲームを続行させます(Fail Safe)。
- Cannot put stone but AI cannot select 'PASS'.
- 石を置ける場所がないのに、PASSを選択できなかった。
- Cannot 'PASS' this turn but AI selected it.
- パスできない(置ける場所がある)のに、PASSを選択した。
- Cannot put stone at AI selected postion.
- 石を置けない場所を選択した。
- Cannot put stone but AI cannot select 'PASS'.
-
Computer AI同士の対戦を複数回連続で行い、勝敗をカウントできる。
- 各AIの先攻、後攻はランダムに決定されます。
- AI同士の対戦の棋譜を"record.log"として保存します。
- この棋譜は"build_mlp.py"で読み込める形式です。
MLPモデルを使用したAIを検証する
では、プレイアブルかどうか検証に移ります。
できるなら強いAIを作りたいですね。そこで先手(黒)の勝った試合の棋譜のみを使用してトレーニングしたモデル(model_black_win.npz)と後手(白)の勝った試合の棋譜のみを使用してトレーニングしたモデル(model_white_win.npz)を使用して人間(私)と対戦させてみます。
ふむふむ。。。むむっ。
Illegal move! 出ちゃいました...
三目並べのときのように簡単にはいかなかったですね。ですが、まだまだ想定内です。まずは出現するIllegal moveの種類とその頻度を調べてみます。
自分と対戦させると日が暮れるので、Computer同士で対戦させましょう。MLPとRandomで対戦させることにします。
1000回対戦して、Illegal move!は7027回発生しました。
発生したIllegal moveの種類の内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 93 |
| Cannot 'PASS' this turn but AI selected it. | 51 |
| Cannot put stone at AI selected postion. | 6883 |
| 合計 | 7027 |
| ざっくりと計算します。一試合にパスが発生せず、盤面が埋まるまで決着がつかないと仮定すると、盤面が埋まり、決着がつくまでに60手。片方プレイヤーが打つのが30手。1000戦で30000手。 | |
| というわけで、7027/30000 なので、23.4%の割合で不正な手を打っていると概算できます。 |
8割方はルールに則ってゲームできているのでMLPの構成を変更するか悩みますね...
まずはMLPの構成は変更しないで思いつくことをやっていこうと思います。
トライ&エラー祭り、開始です。
リトライ1 : 勝った試合の棋譜だけを使用しないで、全試合の棋譜を使用してみる
強いAIをつくるのは一旦、横に置いておいて、ルールを遵守することを優先させてみようと思います。そこで勝った試合だけでなく、負けた試合も含めて学習させることで、パターンの多様性を増してみます。
MLPのAIとして、先手(黒)用に"model_black.npz"、後手(白)用に"model_white.npz"を設定します。これらのモデルは以下のコマンドで作ったモデルです。
$ python build_mlp.py Othello.01e4.ggf black
$ mv reversi_model.npz model_black.npz
$ python build_mlp.py Othello.01e4.ggf white
$ mv reversi_model.npz model_white.npz
では、先ほどと同様にComputer同士を対戦させます。MLP vs Random 再戦です。
1000回対戦して、Illegal move!は5720回発生しました。内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 65 |
| Cannot 'PASS' this turn but AI selected it. | 123 |
| Cannot put stone at AI selected postion. | 5532 |
| 合計 | 5720 |
5720/30000 なので 19.1%の割合で不正な手を打っています。まだ先は長そうですが、先ほどより減ってますね。いい傾向です。
リトライ2 : トレーニングするEpochカウントを1000から3000に増やしてみる
かなりやっつけなですが、トレーニングを回数を多くしてみれば上手くいくのでは、という方法です。
"build_mlp.py"を改造して、引数にbatch_sizeとmax epoch countを指定できるようにして、batch_size=100, max_epoch_count=3000でモデルを作り直しました。
$ python build_mlp.py Othello.01e4.ggf black 100 3000
$ mv reversi_model.npz model_epoch-3000_black.npz
$ python build_mlp.py Othello.01e4.ggf white 100 3000
$ mv reversi_model.npz model_epoch-3000_white.npz
ちなみに私の環境では、この学習に5時間+5時間=10時間かかりました...
VirtualBox上のLinux環境しか持っていないのが恨めしい...
これらのモデルでComputer同士対戦させます。MLP vs Random 1000戦です。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 35 |
| Cannot 'PASS' this turn but AI selected it. | 257 |
| Cannot put stone at AI selected postion. | 5677 |
| 合計 | 5966 |
5966/30000 なので 19.9%の割合で不正な手を打っています。
あまり変わりませんね。Epochを1000以上に増やしても、これ以上学習が進むわけではないようです。
実はEpochを3000にして試さなくても、教師データと同様のテストデータを1000個ほど別に用意して、"build_mlp.py"を実行するときに、Epoch - Accuracy相関(学習曲線)をとってみればどれくらいのEpochで学習がこれ以上進みそうにないことが分かります。
リトライ3 : MLP vs Randomを10000回実施し、その棋譜でトレーニングしたモデルを使用する
教師データの工夫してもなかなか上手くいかないので、違うアプローチをしてみます。
"model_black.npz", "model_white.npz" を使用してMLP AIを設定し、Computer同士の対戦をMLP vs Randomで行います(今回は10000戦行いました)。その棋譜で再度トレーニングしてみます。
意図としては、MLP AIの苦手なパターンに対して、Fail Safe機能で正解を付与した形の棋譜を用いることで、MLP AIの苦手なパターンについても学習させることができるのではないか、と思ったからです。
まず10000回 MLP vs Random対戦をさせます。
"record.log"という棋譜ファイルが保存されますので、"mlp_vs_random_10000_01.log"とリネームしておきます。このlogファイルを読み込んでモデルを作り直します。
$ python build_mlp.py mlp_vs_random_10000_01.log black 100 1000
$ mv reversi_model.npz model_mlp_vs_random_black_01.npz
$ python build_mlp.py mlp_vs_random_10000_01.log white 100 1000
$ mv reversi_model.npz model_mlp_vs_random_white_01.npz
新たにできたモデル(model_mlp_vs_random_black_01.npz, model_mlp_vs_random_white_01.npz)を使用して MLP vs Randomで再戦です。
1000回対戦して、Illegal move!は2794回発生しました。
内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 84 |
| Cannot 'PASS' this turn but AI selected it. | 57 |
| Cannot put stone at AI selected postion. | 2653 |
| 合計 | 2794 |
2794/30000 なので 9.3%の割合で不正な手を打っています。
いいですね! 約半分になりました!
さあ、ここからが頑張りどころです。
この方法は有効なようなので、もう一度同じ手順を踏んでみます。
model_mlp_vs_random_black_01.npz, model_mlp_vs_random_white_01.npzを使用して MLP vs Randomで10000回対戦させ、そのときの"record.log"を、"mlp_vs_random_10000_02.log"とし、このログで再度モデルを作り直します。
$ python build_mlp.py mlp_vs_random_10000_02.log black 100 1000
$ mv reversi_model.npz model_mlp_vs_random_black_02.npz
$ python build_mlp.py mlp_vs_random_10000_02.log white 100 1000
$ mv reversi_model.npz model_mlp_vs_random_white_02.npz
新たにできたモデル(model_mlp_vs_random_black_02.npz, model_mlp_vs_random_white_02.npz)を使用して MLP vs Randomで再戦です。
1000回対戦して、Illegal move!は2561回発生しました。
内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 121 |
| Cannot 'PASS' this turn but AI selected it. | 41 |
| Cannot put stone at AI selected postion. | 2399 |
| 合計 | 2561 |
2399/30000 なので 8.0%の割合で不正な手を打っています。
むむむ...わずかに低下したとみるべきか。
一旦、この方法はここでストップしておきます。
リトライ4 : MLP vs Randomを10000回実施し、その棋譜をOthell0.01e4.ggfと合わせて、トレーニングしたモデルを使用する。
$cat Othello.01e4 mlp_random_10000_01.log > 01e4_mlp_randomA_10000_01.ggf
$ python build_mlp.py 01e4_mlp_randomA_10000_01.ggf
black 100 1000
$ mv reversi_model.npz model_01e4_mlp_vs_random_black_02.npz
$ python build_mlp.py 01e4_mlp_randomA_10000_01.ggf
white 100 1000
$ mv reversi_model.npz model_01e4_mlp_vs_random_white_02.npz
上記のように既存の棋譜"Othello.01e4.ggf"と前段で作成した"mlp_random_10000_01.log"を連結させた棋譜でトレーニングしてみます。
より多様性があり、Illegal moveになる手を含んだ棋譜が出来上がるので、性能があがるのではないか、と考えました。
新たにできたモデル(model_01e4_mlp_vs_random_black.npz, model_01e4_mlp_vs_random_white.npz)を使用して MLP vs Randomで再戦です。
1000回対戦して、Illegal move!は3325回発生しました。
内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 48 |
| Cannot 'PASS' this turn but AI selected it. | 90 |
| Cannot put stone at AI selected postion. | 3187 |
| 合計 | 3325 |
3325/30000 なので 11.1%の割合で不正な手を打っています。
うーん、リトライ3と大差ない結果ですね。残念。
中間まとめ
今週はこの辺で一旦まとめます。
- 初期のモデルで単純に棋譜を読み込んだだけでは、プレイアブルなAIにはならない
- 黒、白のそれぞれ勝った棋譜だけを読み込んだAIは、誤った手を打つ可能性が高くなる
- MLPのAIには、誤った手を選択した場合のFail Safeとして、少なくともゲームを続行できる手に修正ができる機能を設けるべき
- MLPでのAIにFail Safeを設けて、MLP vs Randomで大量の棋譜を取得し、その棋譜で再度トレーニングすると、誤った手を打つ可能性を低減できる
こんなところでしょうか。
現状、不正な手を選択する確率が概算で8.0%まで低減できたので、これにFail SafeをつけたAIを中間時点での成果とします。
まぁ、これを最終成果としてもよいのですが、ちょっと悔しいので、来週以降は、MLPモデルの設定もいじっていきます。
今後のトライについても、この記事に順次追記していこうと思っています。
展開が気になる方はウォッチしていただければ幸いです。
この検討では、私の環境では、毎度棋譜からモデルのトレーニングに数時間単位で時間がかかるのが非常にネックになっています...
GPUが使用できる方は、もう少し手軽にできると思いますので、"build_mlp.py"をGPU対応に書き換えていただいて、いろいろ試してみると面白いのではないでしょうか。
↓↓↓↓↓ 2016/08/14更新 ↓↓↓↓↓
学習曲線の確認
"bulid_mlp.py"を更新して学習曲線が出せるようにしました。データの終端1000サンプルをテスト(Validation)データとして確保し(この1000サンプルはトレーニングには使用しない)、各Epochでのトレーニングデータでの正答率(main/accuracy)とモデルにとって未知であるテストデータに対する正答率(validation/main/accuracy)を表示するようにしました。
これで学習曲線が描けるようになりました。
まぁ、最初からやっとけ、という話なんですが...
まず、初期のモデルでの学習曲線を示します。
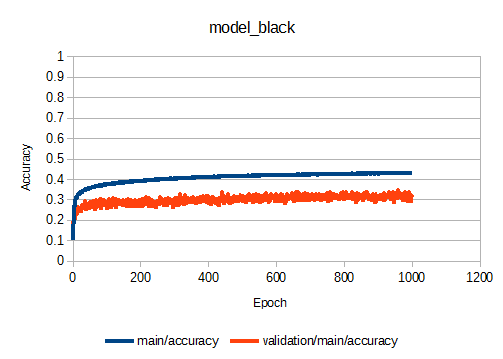
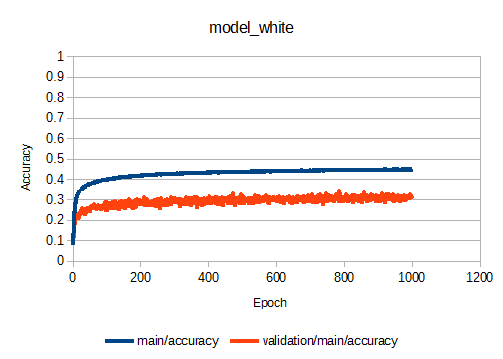
1000 Epochにおいて、main/accuracyが0.45くらいで飽和していますね。
リトライ2で行ったEpochを1000→3000にしてみる、というのが効果がなさそうだと判断できます。
ちなみに、0.45=45%の正答率って低くない?と思うかもしれませんが、実際の棋譜を使用しているため、ある盤面の状態に対して複数の打つ手が答えとして存在するので、正答率はそれほど高くならないのだと思われます。
次に隠れ層(h1, h2)のニューロンの数を100→200に増やした場合の学習曲線を示します。
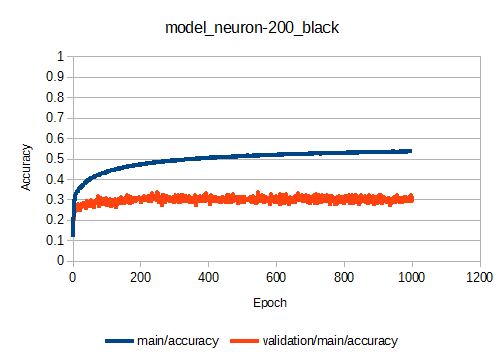
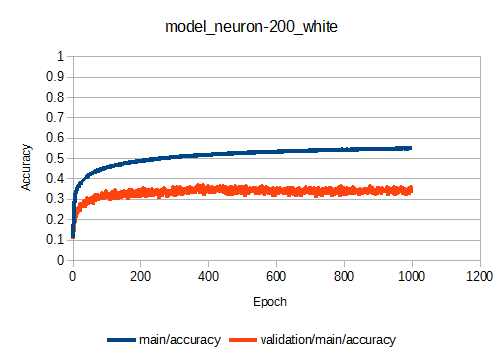
1000 Epoch程度でほぼ収束するのは同じ。ニューロンを増やすとトレーニングデータの正答率(main/accuracy)は上がりますが、未知の入力に対する正答率であるvalidation/main/accuracyの値がニューロンが100の場合とほぼ同じです。
と、いうことは...ニューロン100→200に変更してもルールの遵守はできそうにないですね...
でも一応、リトライ5として確認してみます。
リトライ5 : h1, h2のニューロンを100→200に増やす
ニューロンの数を増やすことで、より棋譜に対するトレーニング効果が高まり、ルールを遵守できるようになるのではないか、と考えて行いました。
"build_mlp.py"のMLP Classの定義を変更します。
...
class MLP(Chain):
def __init__(self):
super(MLP, self).__init__(
l1=L.Linear(64,200)
l2=L.Linear(200,200)
l3=L.Linear(200,65)
)
...
変更後、トレーニング済みモデルを作成します。
$ python build_mlp.py Othelo.01e4.ggf black 100 1000
$ mv reversi_model.npz model_neuron-200_black.npz
$ python build_mlp.py Othelo.01e4.ggf white 100 1000
$ mv reversi_model.npz model_neuron-200_white.npz
新たにできたモデル(model_neuron-200_black.npz, model_neuron-200_white.npz)を使用して MLP vs Randomで再戦です。
("reversi.py"のMLP classの定義も前述のように変更しておく必要があります)
1000回対戦して、Illegal move!は10778回発生しました。
内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 99 |
| Cannot 'PASS' this turn but AI selected it. | 120 |
| Cannot put stone at AI selected postion. | 10778 |
| 合計 | 10997 |
10997/30000 なので 36.7%の割合で不正な手を打っています。
悪化してますね...トレーニングデータにフィットしすぎているのでしょう。
リトライ6 : トレーニングサンプルを約3倍に増やす
読み込ませる棋譜を、Othello.01e4.ggfだけでなく、Othello.02e4.ggf、Othello.03e4.ggfと連結させ、約3倍の量にして、より多様なパターンを学習させてみます。
$ cat Othello.01e4.ggf Othello.02e4.ggf Othello.03e4.ggf > Othello.01-03e4.ggf
$ python build_mlp.py Ohtello.01-03e4.ggf black 100 1000
$ mv reversi_model.npz model_01-03e4_black.npz
$ python build_mlp.py Ohtello.01-03e4.ggf white 100 1000
$ mv reversi_model.npz model_01-03e4_white.npz
学習曲線は以下のようになりました。
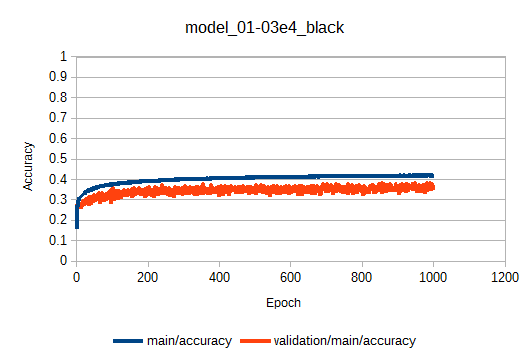
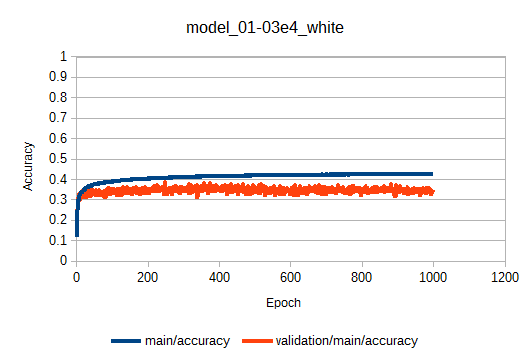
棋譜がOthello.01e4.ggfだけの場合に比べて、validation/main/accuracyが0.3→0.35に改善しています。少しは期待できるか?
新たにできたモデル(model_01-03e4_black.npz, model_01-03e4_white.npz)を使用して MLP vs Randomで再戦です。
1000回対戦して、Illegal move!は5284回発生しました。
内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 40 |
| Cannot 'PASS' this turn but AI selected it. | 228 |
| Cannot put stone at AI selected postion. | 5016 |
| 合計 | 5284 |
5284/30000 なので 17.6%の割合で不正な手を打っています。
棋譜がOthello.01e4.ggfだけを使用した場合(19.1%)と大差ないですね。
かなり手づまりになってきました...
リトライ7 : MLPの入力(盤面の状態)に"置ける場所"の情報を付加する
今度は考え方をガラリと変えて、MLPの入力そのものに手を入れてみます。
具体的には、入力として与える盤面の情報を、'0':なし、'1':黒、'2':白、に加えて、'3':置ける場所 を加えます。
例を示します。
黒の手番の場合の状態X0に対して、置ける場所を付加したものがX1となります。
X0 = [[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,2,1,0,0,0],\
[0,0,1,2,2,2,2,0],\
[0,0,0,1,2,2,0,0],\
[0,0,0,0,1,2,0,0],\
[0,0,0,0,0,0,0,0]]
X1 = [[0,0,0,0,0,0,0,0],\
[0,0,0,0,0,0,0,0],\
[0,0,0,3,3,0,0,0],\
[0,0,3,2,1,3,0,3],\
[0,0,1,2,2,2,2,3],\
[0,0,3,1,2,2,3,0],\
[0,0,0,0,1,2,3,0],\
[0,0,0,0,0,0,0,0]]
これを行うことで、ルールを遵守するAIができるのではないか、と考えました。
「ほぼルール教えてんじゃん!」というツッコミがありそうですが、盤面の状態を入力とし、出力として次の一手を得る、という前提は変わっていません。
(かなり苦しい言い訳...)
"build_mlp.py"を変更して置ける場所を付加するかどうか指定できるようにしました。
コマンドの最後にTrueを付加すると置ける場所を'3'として入力の盤面に付加します。
$ pythohn build_mlp.py Othello.01e4.ggf black 100 1000 True
$ mv reversi_model.npz model_black_puttable_mark.npz
$ pythohn build_mlp.py Othello.01e4.ggf white 100 1000 True
$ mv reversi_model.npz model_white_puttable_mark.npz
学習曲線は以下のようになりました。
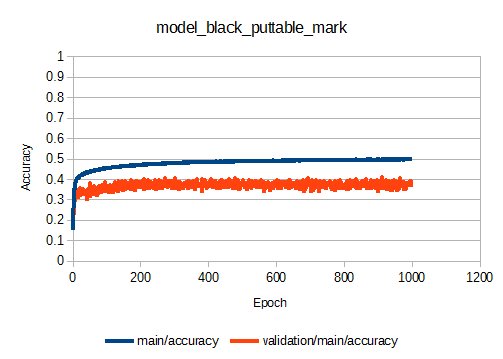
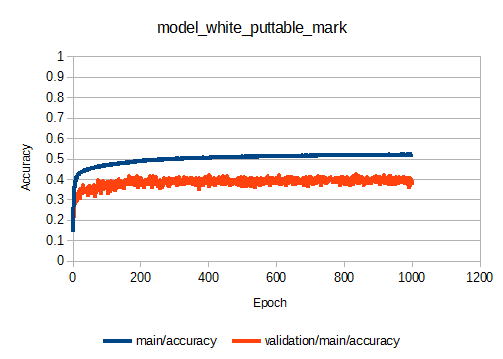
今までで最もvalidation/main/accuracyが高く、0.4程度で収束しています。
新たにできたモデル(model_black_puttable_mark.npz, model_white_puttable_mark.npz)を使用して MLP vs Randomで再戦です。
これらのモデルに対応するために"reversi.py"を修正しました。
指定したMLPモデル名に"puttable_mark"を含む場合、置ける場所を"3"で表した入力に対応します。
1000回対戦して、Illegal move!は207回発生しました。
内訳は以下のようになりました。
| Detail | 発生回数 |
|---|---|
| Cannot put stone but AI cannot select 'PASS'. | 16 |
| Cannot 'PASS' this turn but AI selected it. | 17 |
| Cannot put stone at AI selected postion. | 174 |
| 合計 | 207 |
207/30000 なので 0.7%の割合で不正な手を打っています。
なんと1%以下! 劇的改善です。
最終まとめ
以上をまとめます。
- 初期のモデルで単純に棋譜を読み込んだだけでは、プレイアブルなAIにはならない
- 黒、白のそれぞれ勝った棋譜だけを読み込んだAIは、誤った手を打つ可能性が高くなる
- MLPのAIには、誤った手を選択した場合のFail Safeとして、少なくともゲームを続行できる手に修正ができる機能を設けるべき
- MLPでのAIにFail Safeを設けて、MLP vs Randomで大量の棋譜を取得し、その棋譜で再度トレーニングすると、誤った手を打つ可能性を低減できる
- MLPのニューロンを増やしても誤った手を打つ確率を低減できない(むしろ悪化する)
- MLPのトレーニングサンプルを増やしても誤った手を打つ確率を低減できない
- 入力である盤面の状態に"置ける場所"を情報として付加すると、誤った手を打つ可能性を劇的に改善できる
まともに動作するAIとしては、盤面の状態に"置ける場所"を"3"として付加したものに、Fail Safeを付けたもの、となるでしょうか。
ややズルいかもしれませんが、まともなAIを作ることができました。
AIの強さについては、現状、棋譜に左右されるだけの状態です。
基本的なAIを上記の方法で作成したら、あとは強化学習などを使用して強くしていくということになるでしょう。
強化学習については全く無知なので、勉強してからトライしようと思います。
検討にお付き合いいただきありがとうございました。
お粗末様でした。