はじめに
私の担当するプロジェクトでは実験管理ツールとしてMLflowを定番で利用しています。一方、最近Model ServingのOSSとしてBentoMLにも注目しています。これを連携させることで、モデルの開発・学習フェーズ(Devフェーズ)と運用フェーズ(Opsフェーズ)の橋渡しを上手くできないかと考えました。
MLflowについて
MLflowはTracking、Projects、Models、Model Registryという4つの主要コンポーネントで構成されています。今回はこのうちのTrackingとModel Registryを利用します。
MLflow Tracking
実験結果(学習時に指定したパラメータ、精度等のメトリクス、アーティファクト、など)を記録する機能です。学習プログラムの中で各種実験結果をMLflowに記録するAPIを呼び出すことで、MLflow Trackingに情報が蓄積されます。蓄積された情報はMLflow UIで確認できます。
MLflow Model Registry
学習済モデルのバージョン管理・ステージ管理をする機能です。pkl形式で出力された学習済モデルのファイル自体はTrackingの機能で記録・保管されていますが、再学習によるモデルのバージョンを管理したり、どのバージョンのモデルが検証・本番の環境で有効なのかを管理するのがModel Registryの役割になります。
BentoMLについて
機械学習モデルを管理・提供するためのフレームワークです。この基本機能については以前投稿したこちらで整理しました。
システム構成とML業務プロセス
環境
今回は全てのプロセスをローカルPCで試行しています。
- OS: Ubuntu 20.04(Windows WSL2)
- Docker 20.10.21, Python 3.8.10
- mlflow 2.1.1
- Bentoml 1.0.13
システム関連図
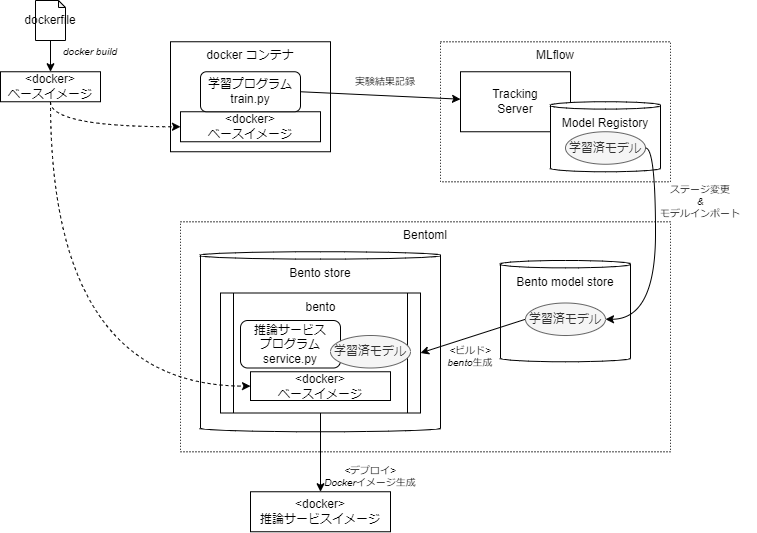
少々分かりづらいかもですが😅 ポイントを整理すると、
- モデル学習はDocker上で実行します。そこでの学習の結果(実験結果)はMLflowに記録されるようにします。また学習済モデルはModel Registryに登録されるようにします。
- Model Registryから最も精度のよいモデルをBento model storeにインポートします。
- 推論サービスプログラムと学習済モデルを纏めてbentoを生成します。基盤はモデル学習でも使ったDockerイメージを指定します。
- bentoから推論サービスのDockerイメージ生成します。
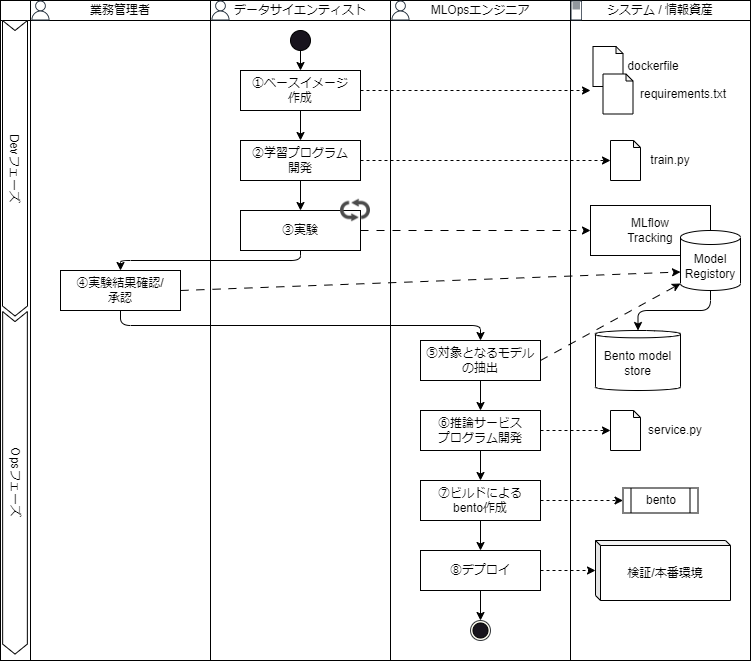
ML業務プロセス
ML業務プロセスで整理すると下図のような流れになります。(ロールや担当の切り分けは会社やプロジェクトによって様々なので、1つのモデルケースとして捉えてもらえればよいです。)
操作
事前準備
事前準備として、python仮想環境の作成、MLflowとBentomlのインストールを行います。MLflowでModel Registryの機能も使うので、実験結果がSQLiteに記録されるように設定します。
# python仮想環境の作成と有効化
python -m venv venv
source venv/bin/activate
# MLflow準備
mkdir mlruns
touch mlruns/mlruns.db
pip install mlflow
# ソースディレクトリ作成
mkdir src
# BentoML準備
pip install bentoml
以下のコマンドを実行するとMLflowのTrackingサーバーが起動します。
# MLflow Trackingサーバーの起動
mlflow server --host 0.0.0.0 --port 5000 \
--backend-store-uri sqlite:///mlruns/mlruns.db \
--default-artifact-root mlruns
ブラウザで http://localhost:5000/ にアクセスしてMLflow UIが表示されれば準備OKです。
①ベースイメージ作成
機械学習のためのベースとなるDockerイメージを作成します。今回はscikit-learnを使ったモデルを作ります。また、実験結果をMLflowに記録するためにmlflowパッケージ、後ほど推論サービスを動かすためにbentomlのパッケージを利用します。scikit-learnはmlflowインストール時に一緒インストールされるので、それをそのまま利用します。ですので今回はごくシンプルなDockerfileになります。
FROM python:3.8.10-buster
RUN pip install mlflow bentoml
WORKDIR /work
docker buildでイメージをビルドします。
docker build -t sample-training .
②学習プログラム開発
必要な環境が揃ったので、学習プログラムを開発します。今回はワインの品質予測のモデルを開発します。
-
train.pyという名前で下記プログラムを記述し、srcディレクトリに保存します。 - MLflowのAutolog機能を使って各種パラメータやメトリクス情報を
experiment_winequality-redというExperiment名で自動的に記録するようにしています。また、生成されたモデルはwinequality-red-modelという名前でMLflow Model Registryに登録されるようにしています。
import sys
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
if __name__ == "__main__":
# データのダウンロード
csv_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
data = pd.read_csv(csv_url, sep=";")
# MLflow設定: Experimentの指定とAutologの設定
experiment = mlflow.set_experiment("experiment_winequality-red")
mlflow.sklearn.autolog(registered_model_name="winequality-red-model")
# データをトレーニングセットとテストセットに分割
train, test = train_test_split(data)
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
# alphaとl1_ratioの値を定義(値はコマンドライン引数で受け取る:デフォルト値は共に0.5)
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
# 学習を実行
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
プログラムが完成したら、Dockerコンテナの中で実行してみましょう。
Dockerコンテナを起動する際にMLFLOW_TRACKING_URIという環境変数を指定します。これはMLflowのTrackingサーバのURLになります。ローカルPCからMLflowはhttp://localhost:5000/でアクセスできますが、Dockerコンテナから呼び出すときは"localhost"ではなくホスト側のIPアドレスを指定する必要があります。LinuxのIPアドレスはip -4 aといったコマンドで確認できますので、これを応用して以下のように実行します。
# docker run 実行
# -vオプションでカレントディレクトリをボリューム共有。
# -eオプションで環境変数MLFLOW_TRACKING_URIを指定。ポート名(ここでは"eth0")が異なる場合は修正してください。
docker run --rm -it \
-v $(pwd):/work \
-e MLFLOW_TRACKING_URI=http://$(ip -4 a show eth0 | grep -oP '(?<=inet\s)\d+(\.\d+){3}'):5000 \
sample-training:latest bash
上記コマンドでコンテナ内に入れます。ここでtrain.pyを実行します。
python src/train.py
実行すると下記のようなメッセージが表示されるかと思います。最後にCreated version '1' of model 'winequality-red-model'.と表示されれば成功です。
root@f681f77eef1a:/work# python src/train.py
2023/02/03 00:27:57 INFO mlflow.tracking.fluent: Experiment with name 'experiment_winequality-red' does not exist. Creating a new experiment.
2023/02/03 00:27:57 WARNING mlflow.utils.autologging_utils: You are using an unsupported version of sklearn. If you encounter errors during autologging, try upgrading / downgrading sklearn to a supported version, or try upgrading MLflow.
2023/02/03 00:27:57 INFO mlflow.utils.autologging_utils: Created MLflow autologging run with ID '201f8132f348454a850f1e5f50dc89c6', which will track hyperparameters, performance metrics, model artifacts, and lineage information for the current sklearn workflow
Successfully registered model 'winequality-red-model'.
2023/02/03 00:28:00 INFO mlflow.tracking._model_registry.client: Waiting up to 300 seconds for model version to finish creation. Model name: winequality-red-model, version 1
Created version '1' of model 'winequality-red-model'.
MLflow UIを見ると実験結果の記録と登録されたモデルが確認できます。
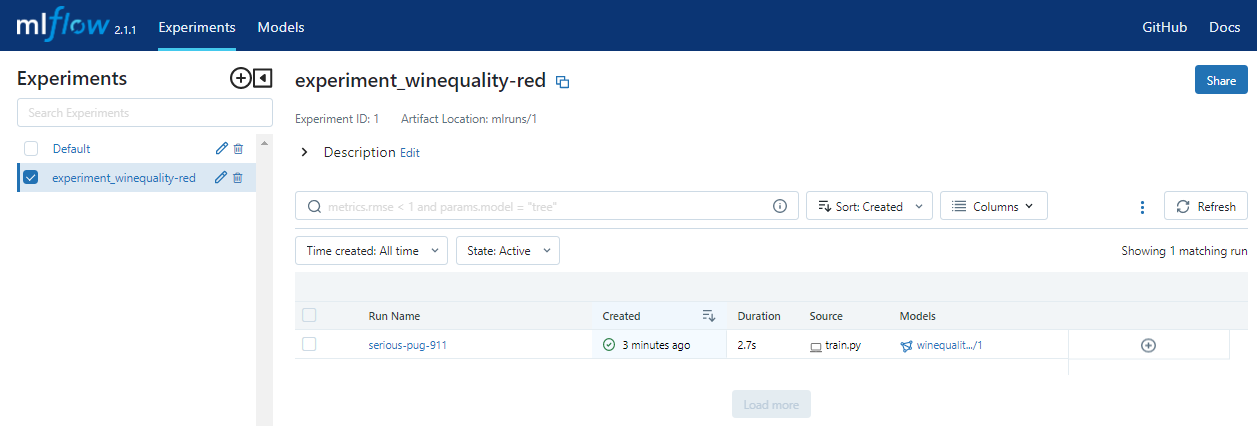
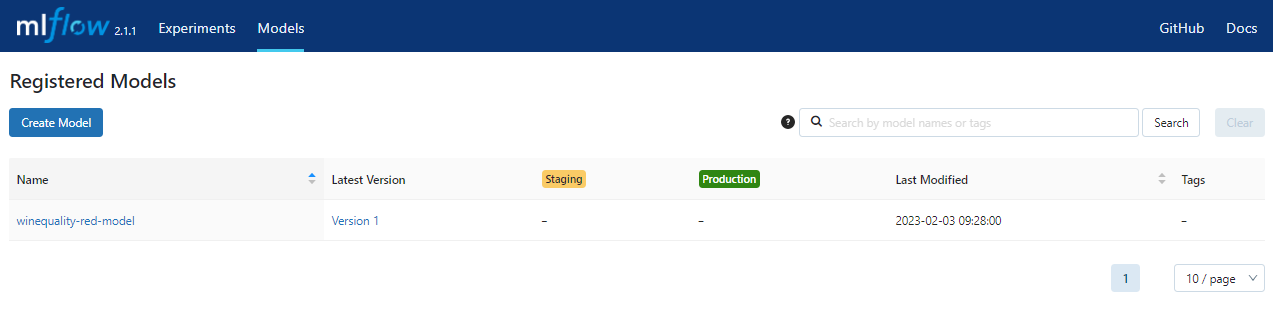
③実験
学習プログラムが開発できたら、実験ということで様々条件を変えて学習を実行します。
Dockerコンテナに入った状態で、以下のようにプログラムを手動で複数回実行します。
# train.pyを4回実行
# 第1引数はalpha、第2引数l1_ratio
python src/train.py 0.4 0.4
python src/train.py 0.3 0.3
python src/train.py 0.2 0.2
python src/train.py 0.1 0.1
MLflow UIを見ると、学習プログラム開発時で行った時の実行と合わせて5つの結果が記録されているのが確認できます。
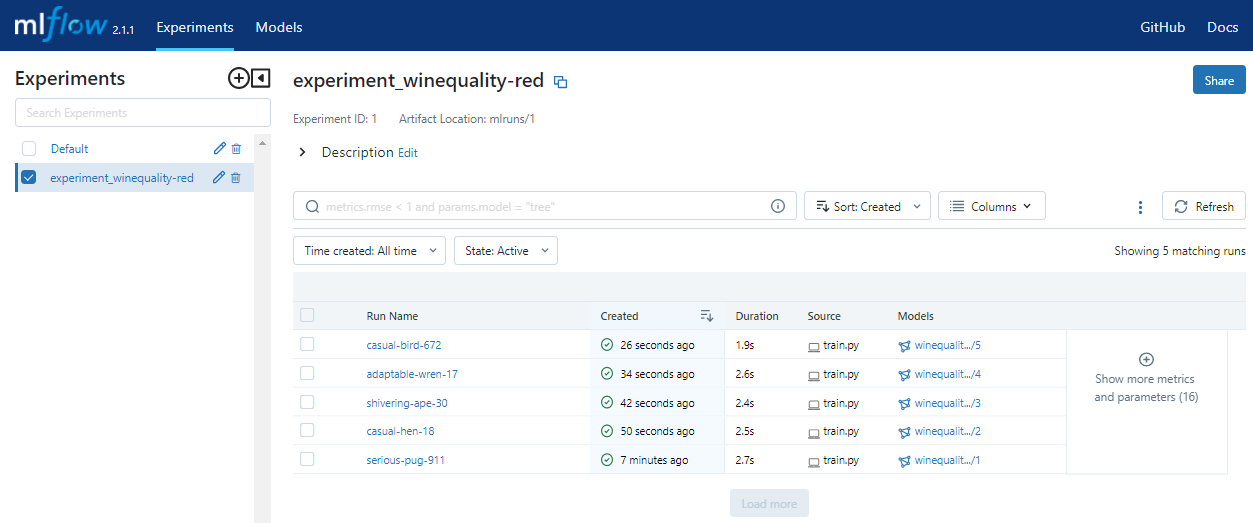
④実験結果確認/承認
一通りの実験が終わりましたので、実験結果を確認して最も精度のよいモデルを判断します。MLflow UIには実験結果の比較機能もありますのでそれらを活用します。今回はalpha=0.1、l1_ratio=0.1で学習したものが、平均二乗偏差(root_mean_squared_error)などのメトリックで良い結果が出たと判断できるので、これを採用することにします。
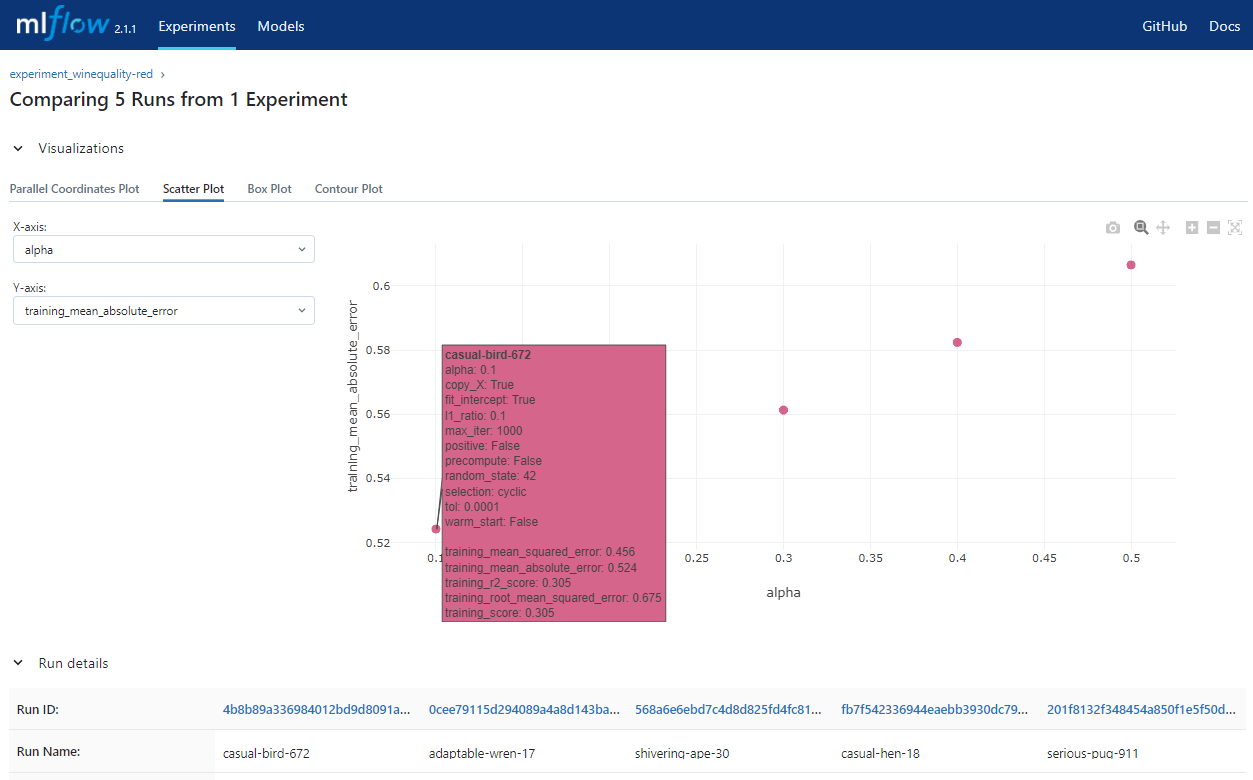
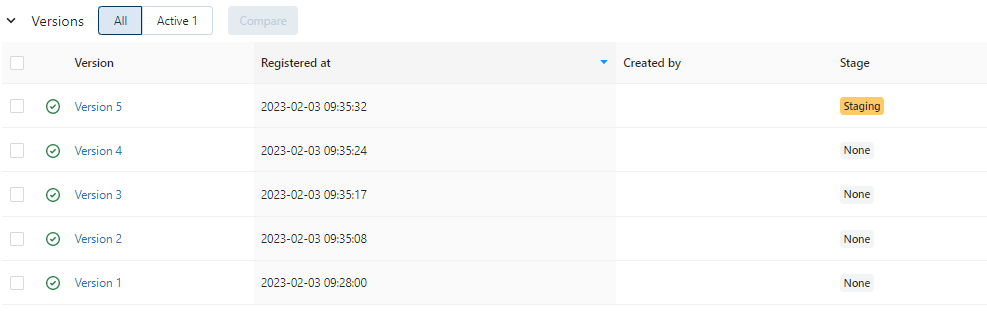
alpha=0.1、l1_ratio=0.1で学習したモデルはMLflow Model Registryにて"winequality-red-model"という名前で、"Version5"として登録されています。このVersion5の画面を開いて、StageをNoneからStageに変更します。
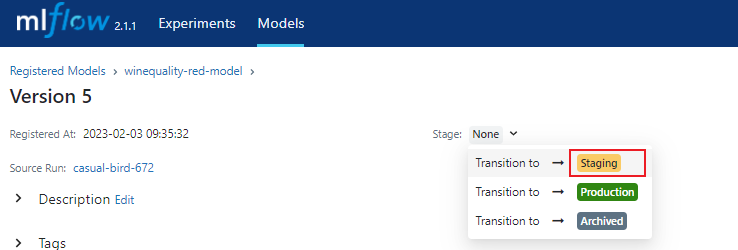
変更されると以下のような表示となります。
⑤対象となるモデルの抽出
ここからBentoMLを利用したModel Servingのプロセスに入っていきます。まずは、先ほどMLflow Model RegistryでStageに変更されたモデルを取り出して、BentoML model storeに保存します。以下のスクリプトimport_model.shを記述してください。
#!/bin/bash
export MLFLOW_TRACKING_URI=http://localhost:5000
# MLflow Model Registryの指定
MLFLOW_MODEL_NAME="winequality-red-model"
STAGE="Staging"
MODEL_URI="models:/$MLFLOW_MODEL_NAME/$STAGE"
# BentoML model storeへの保存
BENTOML_MODEL_NAME="winequality-red"
python -c "import bentoml; bentoml.mlflow.import_model('$BENTOML_MODEL_NAME', '$MODEL_URI')"
MLflow Model Registryに登録されているモデルを呼び出すときは、実験を行ったときのRun IDで指定する方法や、モデル名とバージョンの組み合わせで指定する方法などもありますが、ここでは、モデル名とステージで指定する方法を取ります。これによって、呼び出す際に毎回Run IDやバージョン番号を確認・変更する必要がなくなります。また実際の呼び出しはPython APIで行いますが、今回はごく簡単な命令だけなので、bashファイルの中にインラインでpythonコードを記載しています。
# BentoML model storeへの保存
bash ./import_model.sh
# 確認
bentoml models list
BentoML model storeへの保存が正しく行えていると、以下のように表示されます。
$ bentoml models list
Tag Module Size Creation Time
winequality-red:kfbvtkvdlsqz6aav bentoml.mlflow 2.60 KiB 2023-02-03 09:47:21
⑥推論サービスプログラム開発
推論サービスのプログラムとしてsrc/service.pyを作成します。以下のようにコードを記述してください。
import bentoml
from bentoml.io import NumpyNdarray
from bentoml.io import PandasDataFrame
runner = bentoml.mlflow.get("winequality-red:latest").to_runner()
svc = bentoml.Service("winequality-red-inference", runners=[runner])
@svc.api(input=PandasDataFrame(orient="split", dtype="float64"), output=NumpyNdarray())
def predict(input_arr):
result = runner.predict.run(input_arr)
return result
ポイントとなるのはデコレーター@svc.apiでのIO descriptorsによるinputの指定です。MLflow UIに戻ってアーティファクトを確認すると、推論する際のinputとしてPandasのDataFrameを使うことが確認できます。なので、IO descriptorsでinputはPandasDataFrame()を指定します。
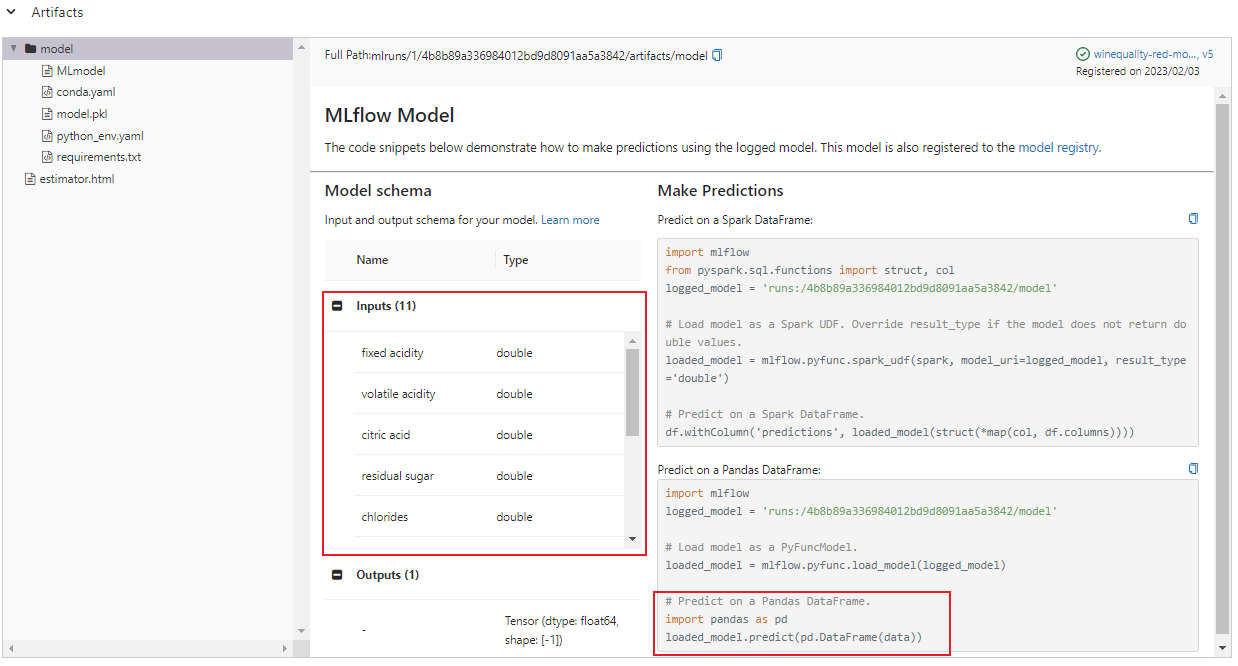
もう1つ考慮するのは、APIコールで渡されたデータをどのようにDataFrameにするかです。例えば下記のような形式でAPIからデータが渡される場合は、PandasDataFrame()の引数でorient="split"と指定します。
{
"columns": [
"alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide",
"pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"
],
"data": [
[ 10.6, 0.091, 0.09, 0.9976, 8.7, 20, 3.34, 2.5, 0.86, 49, 0.52 ]
]
}
これは様々なパターンが考えられるので、詳細は公式ドキュメントのAPI IO Descriptors #Tabular Data with Pandasを参照してください。
では、推論サービスが正しく動作するかを確認します。Dockerコンテナを起動し、そこでサービスを実行します。Dockerコンテナの中からBentoML model storeを参照できるようにボリューム共有している点と3000番ポートを公開している点が先ほどと異なります。
# docker run 実行
# -vオプションでbentoml model storeを共有
# -pオプションで3000番ポートを公開
docker run --rm -it \
-v $(pwd):/work \
-v ~/bentoml:/root/bentoml \
-p 3000:3000 \
sample-training:latest bash
# サービスのテスト実行
cd src
bentoml serve service:svc
サービスが起動したら、別ターミナルで下記のcurlコマンドでAPIコールをします。
curl -X POST -H 'Content-Type:application/json' http://localhost:3000/predict \
--data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"], "data":[[ 10.6, 0.091, 0.09, 0.9976, 8.7, 20, 3.34, 2.5, 0.86, 49, 0.52 ]]}'
実行すると、シンプルですが下記のような感じで結果が返ってきます。
[5.752574055174151]
⑦ビルドによるbento作成
前のステップでサービスの実行まで確認できたので、これでビルドしてbentoを作成します。bentoをビルドするにはbentofile.yamlを作成します。
-
includeでビルド対象とするファイル、excludeでビルド対象外とするファイルを指定します。 -
dockerでこれまで利用してきたカスタムのDockerイメージを指定します。
service: "service:svc"
labels:
owner: mlops-team
stage: stg
include:
- "*.py"
exclude:
- "train.py"
- "__pycache__/"
docker:
base_image: "sample-training:latest"
bentofile.yamlを作成したら、bentoml buildコマンドを実行します。
bentoml build ./src
メッセージでSuccessfully built Bentoと表示されていればビルド成功です。
Building BentoML service "winequality-red-inference:rpulvbfdl6ub2aav" from build context "/home/ubuntu/bentoml-mlflow/src".
Packing model "winequality-red:kfbvtkvdlsqz6aav"
BentoML will not install Python to custom base images; ensure the base image 'sample-training:latest' has Python installed.
<class 'str'> is not yet supported.
██████╗░███████╗███╗░░██╗████████╗░█████╗░███╗░░░███╗██╗░░░░░
██╔══██╗██╔════╝████╗░██║╚══██╔══╝██╔══██╗████╗░████║██║░░░░░
██████╦╝█████╗░░██╔██╗██║░░░██║░░░██║░░██║██╔████╔██║██║░░░░░
██╔══██╗██╔══╝░░██║╚████║░░░██║░░░██║░░██║██║╚██╔╝██║██║░░░░░
██████╦╝███████╗██║░╚███║░░░██║░░░╚█████╔╝██║░╚═╝░██║███████╗
╚═════╝░╚══════╝╚═╝░░╚══╝░░░╚═╝░░░░╚════╝░╚═╝░░░░░╚═╝╚══════╝
Successfully built Bento(tag="winequality-red-inference:rpulvbfdl6ub2aav").
⑧デプロイ
先ほどビルドしたbentoがBento storeに格納されていることを確認して、bentoからDockerイメージを生成します。
# Bento storeに格納されているBentoの確認
bentoml list
# Dockerイメージの生成
bentoml containerize winequality-red-inference:latest
成功すると最後の方に下記メッセージが表示されます。
Successfully built Bento container for "winequality-red-inference:latest" with tag(s) "winequality-red-inference:rpulvbfdl6ub2aav"
To run your newly built Bento container, run:
docker run -it --rm -p 3000:3000 winequality-red-inference:rpulvbfdl6ub2aav serve --production
メッセージの最終行に記載されているdocker runコマンドで推論サービスを起動することができます。
おわりに
今回はローカルPC上でMLflowとBentoMLを連携させた形で一連のプロセスを実行しました。実際に運用するには他にも考慮が必要な点がありますが、DevからOpsへの一連の流れが見えやすくなったと感じています。