はじめに
2022年11月にMLflow 2.0がリリースされました。v1.27.0以降ではMLflow Pipelinesという名称で先行的にリリースされていた機能ですが、v2になって名称も新たにMLflow Recipesとなりました。以前から気になっていたこの機能を今回は調べてみました。
MLflow Recipesとは
公式ドキュメントでは、高品質なモデルを迅速に開発し、本番環境に導入するためのフレームワークと記載されています。v1時代はMLflow Pipelinesと表現されていましたが、パイプラインそのものを自由に定義できるというものではないようです。パイプラインはMLflow側で事前定義されたものが提供されていて、そのパイプラインの各ステップの処理をこちらが設定するといったものになります。
事前定義されたパイプラインとしては、現在、回帰のテンプレート(MLflow Recipes Regression Template)と、分類のテンプレート(MLflow Recipes Classification Template)の2種類が提供されています。また、現在のテンプレートは、scikit-learnをベースとしたものとなっています。
今回はこのうちの回帰のテンプレートを中心に記載します。
用語定義
公式ドキュメントでは以下の用語が定義されています。
- ステップ(Steps): パイプラインにおける個々の処理/操作を指します。データの取り込み、モデルの評価、などなど。
- レシピ(Recipes): 各ステップをどの順序で実行するかを定義したもの。
- テンプレート(Templates): ステップのコードとレシピ定義のセット。MLflowがGitHubで公開している。
- プロファイル(Profiles): ハイパーパラメータ、モデルレジストリURI、などのユーザや環境固有の定義。
- ステップカード(Step Cards): ステップを実行した実行結果のこと。Jupyterで実行するとセルのOutputとして表示される。また、この情報はMLflowトラッキングにも記録される。
フォルダ構成について
公式ドキュメントでも紹介されているサンプルのNYC taxi fare prediction exampleをみてみます。フォルダ構成は次のようになっています。
..
├── data
│ └── sample.parquet
├── notebooks
│ ├── databricks.py
│ └── jupyter.ipynb
├── profiles
│ ├── databricks.yaml
│ └── local.yaml
├── steps
│ ├── custom_metrics.py
│ ├── ingest.py
│ ├── split.py
│ ├── train.py
│ └── transform.py
├── tests
│
├── README.md
└── recipe.yaml
-
dataサンプルのシナリオで使用するデータが入っています。
-
notebooksレシピ(パイプライン)をステップ毎に呼び出して実行させるコードが書かれたノートブックが含まれています。ローカル実行用とDataBricks実行用の2つが入っています。
-
profilesプロファイルの定義ファイルです。YAML形式で書かれており、ローカル実行用とDataBricks実行用の2つが用意されています。
-
steps各ステップにおける処理が書かれたプログラムです。
-
tests各ステップに対するテストコードが書かれたプログラムです。(pytestを利用)
-
recipe.yamlレシピファイルです。
レシピについて
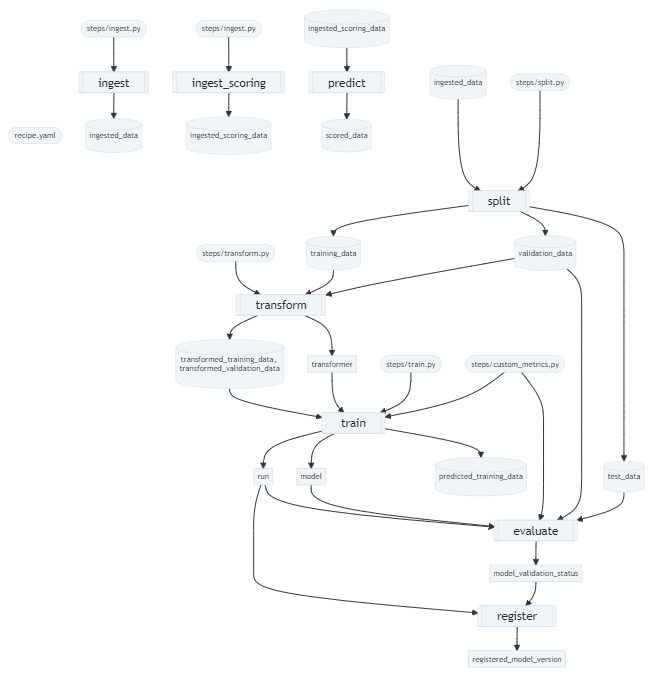
現在提供されているレシピは基本的な流れが決められています。現在のモデル開発レシピにおいては、モデル開発時とバッチスコアリング時の2つの流れが定義されています。
モデル開発時

図の各枠がステップになります。モデル開発時としては6つのステップが固定的に定義されており、左から右へ順次直列に処理が行われます。
各ステップの設定情報はrecipe.yamlで定義します。また、そのステップの中で行う具体的な処理はstepsフォルダ配下にあるステップ名と同名のpyファイルにpythonメソッドとして記述します。
-
ingest
データセットのロードを行います。ロードするデータセットの種別と格納場所(ファイルパス、URI)を指定します。具体的にrecipe.yamlでは以下のように定義します。
recipe.yamlsteps: ingest: using: parquet location: "./data/sample.parquet"出力されるアーティファクト
-
ingested_data: ロードされたPandas DataFrame形式のデータ
-
-
split
ingestステップで生成されたデータセットに対して、学習用、検証用、テスト用のデータセットに分割します。また、分割後のデータに対する処理(例えばレコードのフィルタリングやクレンジングなど)を書き加えることもできます。
下記の例では、学習用、検証用、テスト用でそれぞれ75%、12.5%、12.5%の割合で分割するようにしています。また、分割後のデータ処理としてcreate_dataset_filterメソッドを指定しています。
recipe.yamlsteps: … split: split_ratios: [0.75, 0.125, 0.125] post_split_filter_method: create_dataset_filter出力されるアーティファクト
-
training_data: DataFrame形式の学習用データセット -
validation_data: DataFrame形式の検証用データセット -
test_data: DataFrame形式のテスト用データセット
-
-
transform
ユーザーが定義した変換処理を行います。現時点で定義されている変換処理の種類は
customのみで、変換処理のメソッドを指定します。この変換処理は、scikit-learnのtransformersと互換性のある形式で定義する必要があります。recipe.yamlsteps: … transform: using: custom transformer_method: transformer_fnもし、このrecipe.yamlでtransformセクションの記載を省略すれば、Identity Transformer(入力と出力が同じになるTransformer、要は何も処理しない)が呼び出されます。
出力されるアーティファクト
-
transformed_training_data: 変換後のDataFrame形式の学習用データセット -
transformed_validation_data: 変換後のDataFrame形式の検証用データセット -
transformer: sklearn の変換器(transformer)
-
-
train
変換後の学習データセットを使用して、AutoML または ユーザ定義の推定器(estimator)にfitさせます。この推定量と、transformステップで出力された変換器(transformer)を組み合わせて、モデルレシピを作成します。そして、学習用データセットと検証用データを使ってパフォーマンスのメトリクスを計算します。
recipe.yamlsteps: … train: using: custom estimator_method: estimator_fn出力されるアーティファクト
-
model: trainステップで生成されたモデル
-
-
evaluate
splitステップで生成されたテスト用のデータセットに対して、trainステップで生成されたmodelに適用して性能指標を算出します。recipe.yamlでは下記のようにメトリックとそのしきい値を定義します。メトリックがしきい値を下回るようであれば、後続のregisterステップでModel Registoryへの登録は行われなくなります。
また、カスタムのメトリックを定義することもできます。その場合はstepsセクションの外にcustom_metricsセクションを定義して、そこで指定します。カスタムメトリックの具体的な算出ロジックは、steps/custom_metrics.pyの中で定義します。
recipe.yamlsteps: … evaluate: validation_criteria: - metric: root_mean_squared_error threshold: 10 - metric: mean_absolute_error threshold: 50 - metric: weighted_mean_squared_error threshold: 50 custom_metrics: - name: weighted_mean_squared_error function: weighted_mean_squared_error greater_is_better: False出力されるアーティファクト
-
run: MLflowトラッキングに記録されるRun
-
-
register
evaluate ステップで出力された model_validation_status をチェックし、model_validation_status が 'VALIDATED' の場合は、train ステップで作成されたモデルレシピを MLflow Model Registry に登録します。model_validation_status が 'REJECTED' の場合は登録されません。
recipe.yamlsteps: … register: allow_non_validated_model: false出力されるアーティファクト
-
registered_model_version: Model Registoryに登録されたモデルバージョン
-
バッチスコアリング時

-
ingest_scoring
バッチスコアリングに使用するデータセットを読み込みます。
recipe.yamlingest_scoring: using: parquet location: "./data/sample.parquet"出力されるアーティファクト
-
ingested_scoring_data: ロードされたPandas DataFrame形式のデータ
-
-
predict
registerステップによって登録されたモデルを使用して、ingest_scoringステップで読み込んだデータセットをスコアリングし、結果のデータセットを指定された出力フォーマットとロケーションに書き込みます。特に指定がなければ、Model Registoryに登録されている最新バージョンのモデルを使います。
recipe.yamlpredict: output: using: parquet location: "./data/sample_output.parquet"出力されるアーティファクト
-
scored_data: スコア値のデータセット
-
サンプルを動かしてみる
システム環境
- PC: Windows 11
- WSL2: Ubuntu 20.04
- MLflow: 2.0.1
- VSCode: 1.74.2
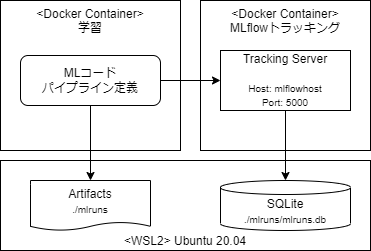
テンプレートにはローカル実行用とDataBricks実行用の2種類が用意されていますが、今回はローカルで実行しました。また、実際よく利用するML開発環境構成を意識して、学習コンテナ(パイプラインによる処理を実行する)、MLflowトラッキングコンテナ(実験管理をする)の2つを構築してこの環境で動作させてみました。具体的には、MLflowトラッキングのScenario 4に相当するような構成です。トラッキング情報はSQLiteに、アーティファクトはローカルのファイルシステムに格納するとし、これらはコンテナとボリューム共有します。2つのコンテナはDocker Composeを使って起動しました。
MLflow Pipelinesのインストールはpip install mlflowでいけます。ですので、学習コンテナ、MLflowトラッキングコンテナのDockerfileの中で実行しました。
プロファイルの修正
環境に関する情報はプロファイルで指定します。今回はローカル実行に相当するので、profiles/local.yamlを修正することになります。上記のシステム構成図のように、トラッキングサーバは別のコンテナ(ホスト名: mlflowhost、ポート番号:5000)で起動しているので、experimentの中の、tracking_uriとartifact_locationの部分を以下のように修正しました。
experiment:
name: "sklearn_regression_experiment"
tracking_uri: "http://mlflowhost:5000"
artifact_location: "mlruns"
ノートブックの実行
レシピを実行するドライバーとしてnotebooks/jupyter.ipynbが用意されています。これを開いて実行していきます。この中では、モデル開発時のレシピを実行するコードが書かれています。
見ていただければわかりますが、書かれているコードはごく簡単なもので、Recipeオブジェクトを生成して、ステップを実行するメソッドを呼び出しています。
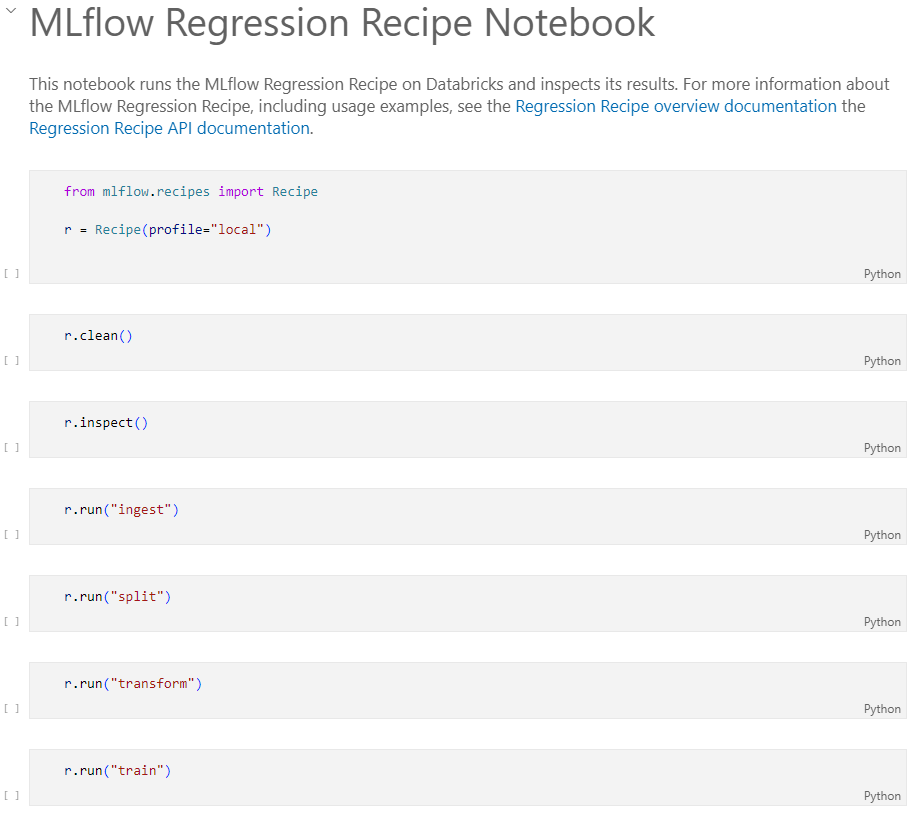
上から順次セルを実行すれば動きますが、幾つか細かい動きを記載しておきます。
-
r.clean()キャッシュをクリアする処理です。MLflow Recipeでは一度実行した結果はキャッシュに記録しています。同じステップが呼び出され際、キャッシュを確認して、前回の入力値やコード等に変更が無い場合は処理は行われずにそのステップはスキップされるという仕組みが組み込まれています。同じ処理をもう一度実行させたい場合はキャッシュをクリアする必要があります。
なお、キャッシュはホームディレクトリの
~/.mlflow/recipesに記録されています。 -
r.inspect()引数に何も指定しなかった場合は、レシピ全体でステップ間の依存関係を示す図が表示されます。この図はrecipe.yamlの定義に関係なく、毎回同じ図が表示されます。
引数にステップ名を指定した場合は、直近に実行したそのステップでの実行結果が表示されます。
-
r.run()レシピを実行します。
引数に何も指定しない場合、モデル開発時のステップ
ingestからregisterまでが実行されます。引数にステップ名を指定すると、指定されたステップが実行され、その実行結果が表示されます。この時、先行のステップが実行されていない場合(キャッシュが存在しない場合)は、先行のステップがまず実行されます。例えば、いきなり
transformのステップを呼び出しても、ingestやsplitが未実行であればまずはそれらのステップが実行されて、それからtransformが実行されます。
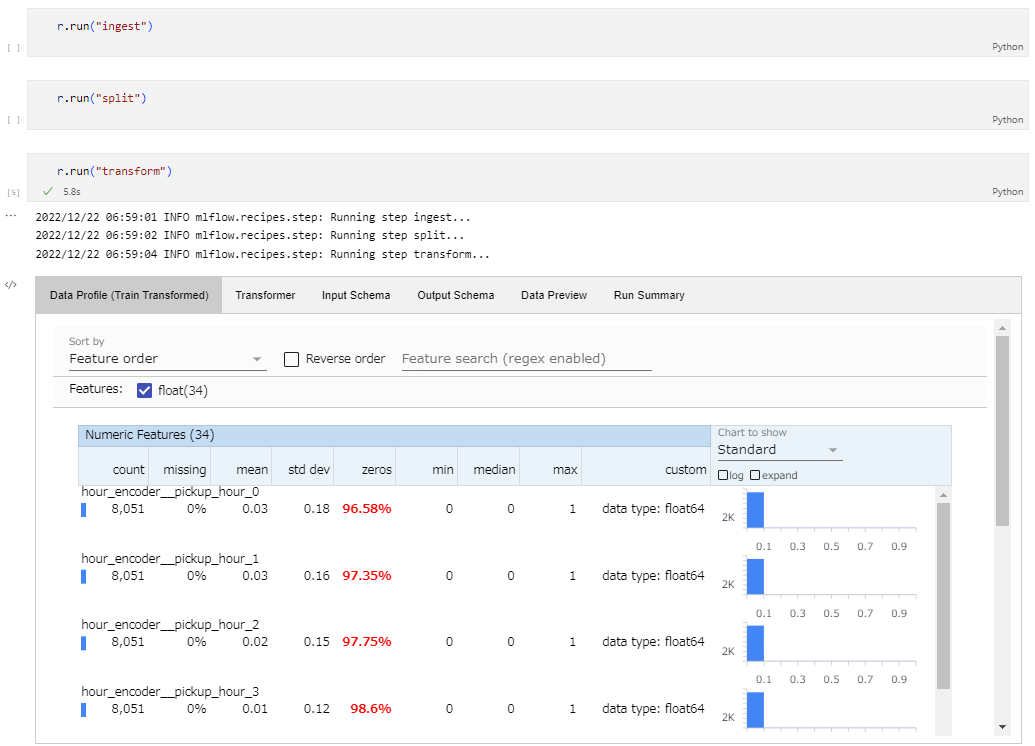
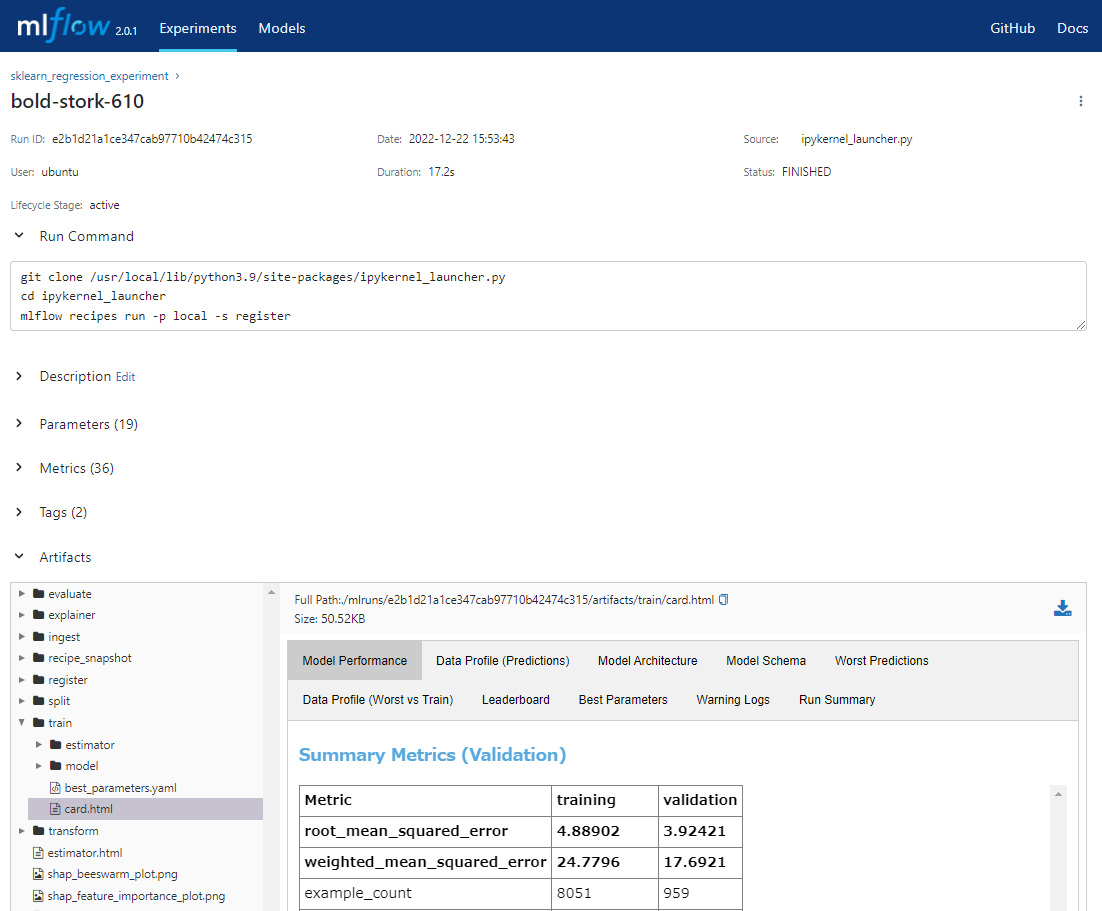
上記のようにステップを実行するとその時の実行結果が分かりやすく表示されます。この出力をMLflow Recipeではステップカード(Step Cards)と呼んでおり、これはMLflowトラッキングでアーティファクトとしても記録されます。
ノートブックを実行してMLflow UIを表示すると、下記のように実験結果がトラッキングされています。
まだ分かっていないこと
今回調べていて、ローカルでバッチスコアリング時のレシピを動かすことができませんでした。ingest_scoringのステップは問題なかったのですが、predictステップを動かそうとすると、ModuleNotFoundError: No module named 'pyspark'といったエラーが表示されてしまいます。pipでpysparkをインストールしただけではダメでRuntimeError: Java gateway process exited before sending its port numberというエラーが表示され、ちゃんとPySparkの環境を立てないとダメ?なのかもしれません。ただ、モデル開発時にPySparkは使っていないはずなんですけどね。。
なお、モデル開発時のレシピで生成されたモデルを、mlflow.pyfunc.load_model()メソッドを使ってロードして呼び出すことはできました。
所感
現時点ではscikit-learnベースの回帰と分類のみということで、利用シーンはそこまで広くはないかなと思いました。ですが、実験結果がきっちり綺麗に残せるのはMLflowの強いところだなと感じました。今後、レシピのテンプレートはMLflow側で追加されていくようなので期待したいです。