概要
AnacondaだけでOCR環境を構築する
ぶっちゃけ難しいことは分からないのでとにかく簡単な方法を模索
環境
Windows10
Anaconda
Python 3.6
Spyder 4.1.2
tesseractとpyocrについて
調べたら、PythonでOCRするならtesseract+pyocrのやり方がありそうなので、
この方法を試してみることにしました
tesseract
現在Googleが開発しているOCR(光学文字認識)のエンジンとのこと
v4.0以降では機械学習のLSTMベースになっていることから、
認識率を考えると最新バージョンが良さそう
pyocr
Python用のOCRツールラッパーとのこと
tesseractにも対応
参考
Anacondaだけで環境を構築して、Python+OCRをやってみる
https://qiita.com/anzanshi/items/9ee94affecd74be33159
参考にしましたが、環境違いからかちょっとハマってしまいました
tesseractのインストール
いろいろやり方はありそうですが、今回はAnacondaでインストールします
conda-forgeリポジトリにtesseractが置いてありました
https://anaconda.org/conda-forge/tesseract
素直にインストール(2020/4/14現在はv4.1.1)
conda install -c conda-forge tesseract
pyocrのインストール
こちらはbrianjmcguirkというあまり見ないリポジトリ…?
https://anaconda.org/brianjmcguirk/pyocr
こちらも素直にインストールします(こちらは現在v0.5)
conda install -c brianjmcguirk pyocr
公式ページのコードを実行してみる
上記記事を参考に、公式ページのコードで確認する
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
と、実行結果は
Will use tool 'Tesseract (sh)'
Available languages: eng, osd
Will use lang 'eng'
となります。
書いてある通り、英語だけで日本語はまだOCRできません。
日本語OCR環境作成
さて、日本語のOCRができるようにします
学習済データのダウンロード
ここからjpn.traineddataをダウンロードします
昔と場所が変わっているようで探すのに少し苦労しました。
https://github.com/tesseract-ocr/tessdoc/blob/master/Data-Files.md
versionによってデータが異なるため注意!(一回間違えた…)
適切な場所に置く
ここもちょっと厄介…
私の環境の場合は
/Anaconda3/envs/(環境名)/Library/bin/tessdata
配下に置くと読み込むことができました
(すでにeng.traineddata、osd.traineddataがあります)
(環境名)配下にもtessdataディレクトリがありますが、
こちらは読みに行かない模様
再実行
再度公式ページのコードを実行
Will use tool 'Tesseract (sh)'
Available languages: eng, jpn, osd
Will use lang 'eng'
ちゃんと「jpn」も追加されました
次は日本語を読み取らせてみます
↓テスト用の画像
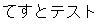
txt = tool.image_to_string(
Image.open('test.png'),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
raise TesseractError(status, errors)
pyocr.error.TesseractError: (1, b"Error, unknown command line argument '-psm'\r\n")
予期しないエラーが発生…
これも似たようなエラーが出た方の記事が参考になりました
https://xkage.com/python-ocr.html
tesseract.pyとbuilders.py
の「-psm」を「--psm」と書き換えたらいけました
再再度実行
txt = tool.image_to_string(
Image.open('test.png'),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
て す と テ ス ト
できた!
まとめ
Anacondaでも環境作れますが思ったより情報が少ないので結構ハマりました
さてOCR使ってガンガン遊ぼうと思います
補足
pythonのversionが3.7だとpyocrが使えないとの情報もありますね
3.6で環境作っておくのが無難そう