背景
Anaconda + python + tesseract で文字認識をしたみた。
tesseractがHomeBrewやMacPortを使ったりする方法しかネット上になかったため、
今回はAnacondaだけで、インストールしてやってみた方法を残します。
環境
MacOS Mojave ver10.14.4
Anaconda Navigator 1.9.7
※Anacondaのインストールは、こちらを参考にいたしました
JupiterNotebook 5.4.0
OpenCV 3.4.2
事前準備
こちらの記事を参考にやってみました。
https://qiita.com/it__ssei/items/fd804dcb10997566593b
・tesseractのインストール
・pyocrのインストール
が必要とのこと。まずはやってみましょう!
OCRツール(tesseract)概要
PythonでOCRで調べると必ず、こいつの存在が出てくるメジャーツール。
元々は米Hewlett-Packardが開発していたOCRツールでお蔵入りしていたものを
Googleが引き取って、公開しているツールのようです。(ありがたや!)
OCRツール(tesseract)インストール
まずは、公式ページのインストール方法を見ると、
Macの場合は、HomeBrew/MacPortでインストールと書かれています。
じゃあ、これらをインストールするための方法を調べると、まずはXcodeをインストールする必要があると。。。
手間が多いな&Macの容量が無くてXcode入れられない。。。
https://qiita.com/pypypyo14/items/4bf3b8bd511b6e93c9f9
ということで、Anacondaだけで、できないかと調べてみたわけです。
すると、あるじゃないですか!Anacondaでインストールできる環境が!
https://anaconda.org/search?q=tesseract
こちらはAnacondaが標準で提供していないツールを有志の方がAnacondaで使えるように
公開してくれているという涙が出るほど便利なサイトになります。
例えば、今回のtesseractで検索すると、いくつか公開してくれています!
(本当に感謝です!!)

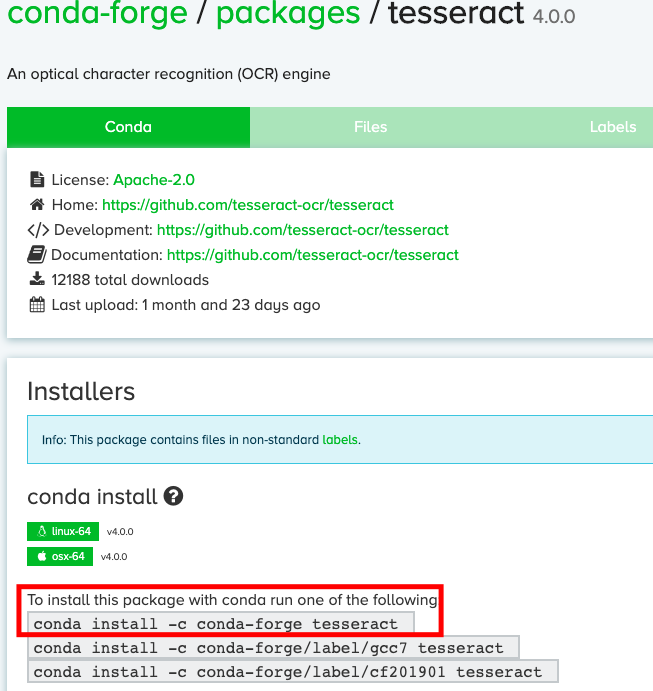
このページの、conda-forge/tesseract を開いてみると、
Anacondaにインストールするためには、
conda install -c conda-forge tesseract
を実行すれば良いと書いてあります。(なるほど)
感謝を胸に自分のAnacondaにインストールしてみましょう。
まずは、AnacondaNavigatorの
Enviroments→(自分の使う仮想環境)→矢印をクリック→ open terminal を開く
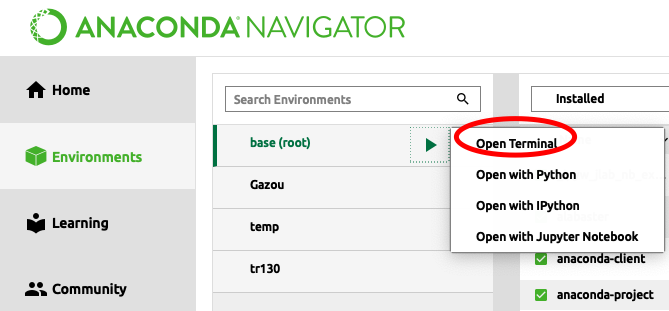
コンソール画面が開いたら、下記を打ち込みます!
途中、実行してよいか?(y/n?)と聞かれますが、迷わず y+Enter を押しましょう!
conda install -c conda-forge tesseract
Errorが出なければ、OK。インストールされているはずです。
一応、下記コマンドで、tesseractが入っているかを確認しましょう
Anacondaに入っているモジュールを一覧表示してくれます。
conda list
pyocr インストール
この調子で、pyocrもAnacondaでインストールだ!と思ったら、
pyocrは残念ながら、windowsとLinux verしかないみたい。(筆者はMac)
https://anaconda.org/search?q=pyocr
ということで、今回は、pipで入れました。
※pip:別のパッケージ管理ツール
※widows/Linuxユーザの方は、condaで入れてみても良いかも!
pip install pyocr
モジュールの動作確認
さて、ここまでで事前準備を終えることができたので、
いよいよOCRに挑戦です!とその前に、モジュールが動作するかを確認しましょう。
こちらの記事を参考にやってみました
https://qiita.com/it__ssei/items/fd804dcb10997566593b
pyocrからtesseractを呼び出す
まずは、公式コードで、確認
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
Will use tool 'Tesseract (sh)'
Available languages: afr, amh, ara, asm, aze, aze_cyrl, bel, ben, bod, bos, bre, bul, cat, ceb, ces, chi_sim, chi_sim_vert, chi_tra, chi_tra_vert, chr, cos, cym, dan, deu, div, dzo, ell, eng, enm, epo, est, eus, fao, fas, fil, fin, fra, frk, frm, fry, gla, gle, glg, grc, guj, hat, heb, hin, hrv, hun, hye, iku, ind, isl, ita, ita_old, jav, jpn, jpn_vert, kan, kat, kat_old, kaz, khm, kir, kmr, kor, kor_vert, lao, lat, lav, lit, ltz, mal, mar, mkd, mlt, mon, mri, msa, mya, nep, nld, nor, oci, ori, osd, pan, pol, por, pus, que, ron, rus, san, script/Arabic, script/Armenian, script/Bengali, script/Canadian_Aboriginal, script/Cherokee, script/Cyrillic, script/Devanagari, script/Ethiopic, script/Fraktur, script/Georgian, script/Greek, script/Gujarati, script/Gurmukhi, script/HanS, script/HanS_vert, script/HanT, script/HanT_vert, script/Hangul, script/Hangul_vert, script/Hebrew, script/Japanese, script/Japanese_vert, script/Kannada, script/Khmer, script/Lao, script/Latin, script/Malayalam, script/Myanmar, script/Oriya, script/Sinhala, script/Syriac, script/Tamil, script/Telugu, script/Thaana, script/Thai, script/Tibetan, script/Vietnamese, sin, slk, slv, snd, spa, spa_old, sqi, srp, srp_latn, sun, swa, swe, syr, tam, tat, tel, tgk, tha, tir, ton, tur, uig, ukr, urd, uzb, uzb_cyrl, vie, yid, yor
Will use lang 'afr'
呼び出すと、上のような実行結果がでてきました。
使える言語はものすごく含まれています。
もちろん、eng,jpnがあるので、英語/日本語はいけそうですね。
文字認識(OCR)
さて、本番です!!
英語と日本語の2パターンをやってみましょう。
英語のOCR
| 読み込ませたい画像 |
|---|

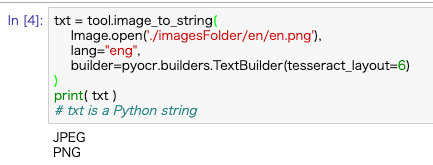
txt = tool.image_to_string(
Image.open('./imagesFolder/en/en.png'),
lang="eng",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
# txt is a Python string
言語設定を「eng」に設定するのがポイントですね。
文字として認識されました!!やったぜ!
日本語のOCR
| 読み込ませたい画像 |
|---|

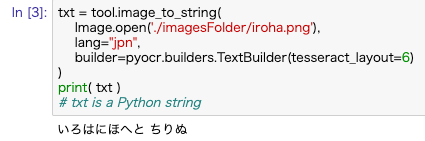
txt = tool.image_to_string(
Image.open('./imagesFolder/iroha.png'),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
# txt is a Python string
言語設定を「jpn」に設定するのがポイントですね。
文字として認識されました!!やったぜ!
終わりに
以上、Anacondaだけで環境を構築して、Python+OCRをやってみました!
思った以上に、文字が読み取れて満足です。
これを使って、会社の書類の自動読み取り処理で業務を効率化していければと思います!
参考
PythonでOCR
https://qiita.com/it__ssei/items/fd804dcb10997566593b