はじめに
私はプログラム知識はほぼありませんが、最近なにかとAIを聞くので興味がありました。そこでAidemyプレミアムプランというものを知り、さらに今なら教育訓練給付制度が利用出来る(最大70%OFF)ということなので、プログラム超初心者ですが思いきって受講させて頂きました。
今回は成果物として為替を予測してみましたので紹介させて頂きます。
本記事の概要
・Twitterからツイートを取得
・VADERによる感情分析
・Yahooから為替データを取得
・感情分析結果と為替データからロジスティック回帰、SVN、ランダムフォレスト、KNNのモデルで予測
実行環境
OS: Windows10
Python: 3.8.5
pandas:1.1.3
numpay:1.19.2
tweepy:3.10.0
nltk: 3.5
scikit-learn:0.23.2
作成したコードの説明
import tweepy
consumer_key = '' # Consumer Key
consumer_secret = '' # Consumer Secret
access_key = '' # Access Token
access_secret = '' # Accesss Token Secert
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth)
初めにTwitterからツイートを取得するために、Twitter API利用登録すると発行されるConsumer key, Consumer Secret, Access Token, Accesss Token Secertを入力し、ツイートを取得する準備をします。
Twitter API登録の仕方は下記を参考にさせて頂きました。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ
import csv
# ツイート取得
tweet_data = []
tweets = tweepy.Cursor(api.user_timeline,screen_name = "ツイッターユーザー名",exclude_replies = True,tweet_mode = 'extended')
for tweet in tweets.items():
tweet_data.append([tweet.id,tweet.created_at,tweet.full_text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
# tweets.csvという名前で保存
with open('./tweets.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id", "text", "created_at", "fav", "RT"])
writer.writerows(tweet_data)
ツイッターユーザー名(@~~の形で表示されるもの)からツイートを取得し、tweet_dataのリストへ入れたら、tweets.csvという名前で保存します。
import pandas as pd
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# VADERによる感情分析
vader_analyzer = SentimentIntensityAnalyzer()
df_tweets = pd.read_csv('tweets.csv', names=['id', 'date', 'text', 'fav', 'RT'], index_col='date')
df_tweets = df_tweets.drop('text', axis=0)
df_tweets.index = pd.to_datetime(df_tweets.index)
df_tweets = df_tweets[['text']].sort_index(ascending=True)
scores = []
for tweet in df_tweets['text']:
result = vader_analyzer.polarity_scores(tweet)
scores.append(result['compound'])
df_tweets['score'] = scores
df_tweets = df_tweets.resample('D').mean()
取得したツイートをVADERで感情分析を行います。出力される結果のうち1つの「compound」は 'すべての単語のスコアの合計を[-1~1]の間で正規化した値' ということなので、今回はこの値を使用して感情分析を行ってみます。1日ごとのcompound値を平均でまとめたものをdf_tweetsに格納しました。
VADERに関しては下記を参考にさせて頂きました。
3. Pythonによる自然言語処理 5-2. 感情強度分析ツール VADER
import pandas_datareader.data as pdr
# Yahoo Financeから為替レート(ドル円)を取得
df = pdr.get_data_yahoo('JPY=X',end='2021-04-07',start='2020-09-01')
df = df.drop(['High','Low','Open','Volume','Adj Close'],axis=1)
df = df.sort_index(ascending=True)
df.to_csv("./time_data.csv")
Yahoo Financeから為替データ(ドル円)を取得し、dfに格納しました。
Yahooから為替データ取得は参考サイトを参考にさせて頂きました。
【Python Coding】pythonで為替レートを取得する方法を紹介
table = df_tweets.join(df, how='right').dropna()
table.to_csv("./table.csv")
dfとdf_tweetsの二つのテーブルを結合し、Nan(欠損値)がある箇所は不要なので消去します。
その後table.csvとして出力します。
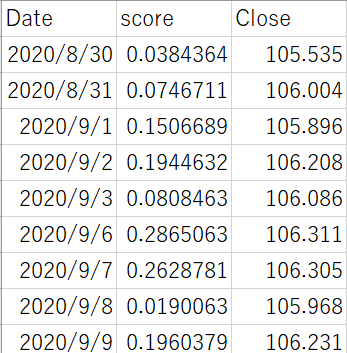
ここまで上手くいけばtable.csvは下図のようにDate, score, Closeで出力されているはずです。
from sklearn.model_selection import train_test_split
X = table.values[:, 0]
y = table.values[:, 1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False)
X_train_std = (X_train - X_train.mean()) / X_train.std()
X_test_std = (X_test - X_train.mean()) / X_train.std()
テクニカル分析を用いて為替の予測を行うための準備をします。
訓練データとテストデータに分け、訓練データを標準化した後、訓練データの平均と分散を用いてテストデータの標準化を行います。
df_train = pd.DataFrame(
{'score': X_train_std,
'close': y_train},
columns=['score', 'close'],
index=table.index[:len(X_train_std)])
df_train.to_csv('./df_train.csv')
df_test = pd.DataFrame(
{'score': X_test_std,
'close': y_test},
columns=['score', 'close'],
index=table.index[len(X_train_std):])
df_test.to_csv('./df_test.csv')
df_trainというテーブルを作りそこにindexを日付、カラム名をscore、closeにしてdf_train.csvという名前で出力します。
残りのデータを同様にdf_testに入れ、 df_test.csvで出力します。
import numpy as np
def make_dataset(filepath):
rates_fd = open(str(filepath), 'r',encoding='utf-8')
rates_fd.readline() #1行ごとにファイル終端まで全て読み込み
next(rates_fd) # 先頭の行を飛ばす。
exchange_dates = []
score_rates = []
score_rates_diff = []
exchange_rates = []
exchange_rates_diff = []
prev_score = df_train['score'][0]
prev_exch = df_train['close'][0]
for line in rates_fd:
splited = line.split(",")
time = splited[0] # table.csvの1列目日付
score_val = float(splited[1]) # table.csvの2列目score
exch_val = float(splited[2]) # table.csvの3列目為替のclose
exchange_dates.append(time) # 日付
score_rates.append(score_val)
score_rates_diff.append(score_val - prev_score) # scoreの変化
exchange_rates.append(exch_val)
exchange_rates_diff.append(exch_val - prev_exch) # 為替の変化
prev_score = score_val
prev_exch = exch_val
rates_fd.close()
INPUT_LEN = 3
data_len = len(score_rates_diff)
test_input_mat = []
test_angle_mat = []
for i in range(INPUT_LEN, data_len):
test_arr = []
for j in range(INPUT_LEN):
test_arr.append(exchange_rates_diff[i - INPUT_LEN + j])
test_arr.append(score_rates_diff[i - INPUT_LEN + j])
test_input_mat.append(test_arr) # i日目の直近3日間の為替とscoreの変化
if exchange_rates_diff[i] >= 0: # i日目の為替の上下、プラスなら1、マイナスなら0
test_angle_mat.append(1)
else:
test_angle_mat.append(0)
feature_arr = np.array(test_input_mat)
label_arr = np.array(test_angle_mat)
return feature_arr, label_arr
データセットを作成するための関数make_datasetを作成します。
この関数を実行すると直近3日間の為替とscoreの変化データがfeature_arrに格納され、為替がプラスなら1,マイナスなら0にしたデータがlabel_arrに格納され、それぞれ返されます。
train_feature_arr, train_label_arr = make_dataset("./df_train.csv")
test_feature_arr, test_label_arr = make_dataset("./df_test.csv")
作成した関数make_datasetを使用して、訓練データとテストデータを作成します。
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
# train_feature_arr, train_label_arr,test_feature_arr, test_label_arrを特徴量にして、予測モデル(ロジスティック回帰、SVM、ランダムフォレスト、KNN)を構築し予測精度を計測
for model in [LogisticRegression(), RandomForestClassifier(n_estimators=200, max_depth=8, random_state=0), SVC(), KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')]:
model.fit(train_feature_arr, train_label_arr)
print("--Method:", model.__class__.__name__, "--")
print("Cross validatin scores:{}".format(model.score(test_feature_arr, test_label_arr)))
最後に、訓練データとテストデータから予測モデル(ロジスティック回帰、SVN、ランダムフォレスト、KNN)を構築し、予測精度を出力させます。
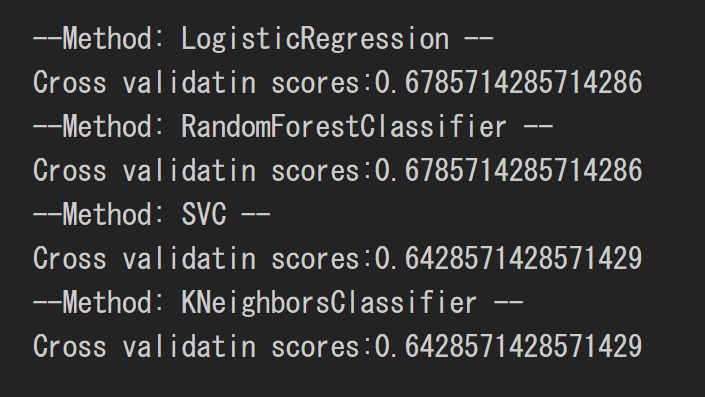
予測結果はすべての予測精度が6割越えというという結果となりました。
おわりに
為替を予測するというのはかなり困難な事だと思いますが、今回は練習の題材として為替の予測をしてみました。結果は正解率6割と正直、良すぎると思います。一時的なバラツキなのかもしれないし、後出しジャンケン(為替が動いた後のツイートで分析している)になってしまっているので、そうなったのかもしれません。そこは後に見直したいと思います。
以上、「超初心者がツイッターを感情分析して為替(ドル円)を予測した結果」でした。
読んでいただきありがとうございました。