Amazon, Google, IBM, Microsoftの音声認識サービスを使用
各社の音声認識サービスのAPIの名称です(呼び方は人によって違いますが間違っていたらすいません)
- Amazon:
- Transcribe
- Google:
- Cloud Speech-to-Text
- IBM:
- Watson Speech-to-Text
- Microsoft:
- Azure Speech-to-Text
Speech-to-TextというAPIを探せば見つかるはずです.AmazonだけはTranscribeと呼ばれていますが...
本記事では各APIを使うための準備(アカウント登録など諸々)は済ませてある前提の内容です
アカウント登録の方法は,検索すればわかりやすく説明してくれているサイトがあるので頑張って登録してみてください
Amazon Transcribe の使い方
-
まず,認識させたい音声ファイルをS3というAWSのクラウドストレージの置く必要があります.
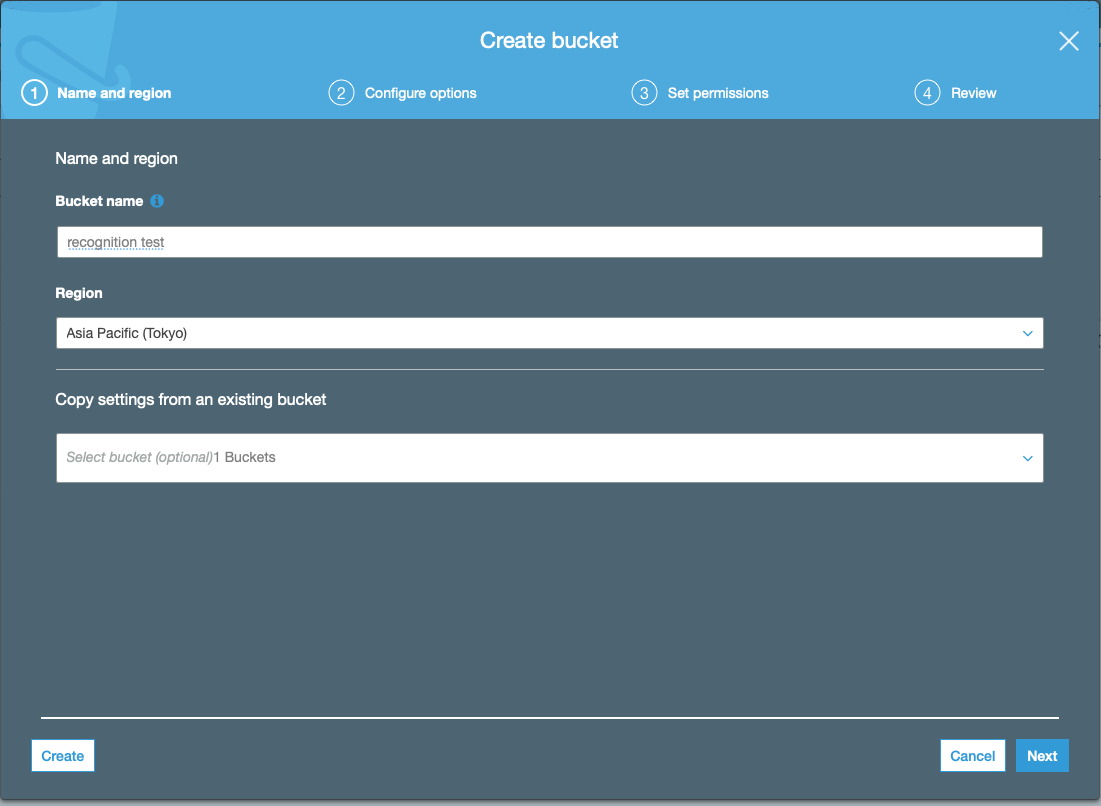
- S3のページの左上辺りにあるCreate bucketをクリックしてバケットを作成します.バケット名はなんでもいいです.地域(region)はtokyoにしておきました.
- Bucket name: recognitiontest(なんでも良い)
- Region: Asia Pacific(Tokyo)
- バケットを作成したら,作成したバケットに音声ファイルをアップロードすれば準備完了です.左上辺りにUploadというボタンがあるので,クリックすればアップロードできます.フォルダを作成して複数の音声ファイルをまとめることもできるのでお好みでやってください.
- S3のページの左上辺りにあるCreate bucketをクリックしてバケットを作成します.バケット名はなんでもいいです.地域(region)はtokyoにしておきました.
-
それでは認識を開始していきますが,APIを叩く前にAPIのアクセスキーなどの環境変数を通しておく必要があります.
% export AWS_SECRET_ACCESS_KEY=[自分のAWS_SECRET_ACCESS_KEY]
% export AWS_ACCESS_KEY_ID=[自分のAWS_ACCESS_KEY_ID]
% export AWS_DEFAULT_REGION=ap-northeast-1
% source ~/.zshrc
- あとはAPIを叩くだけです.サンプルプログラムを載せておきます.
recognize.py
from __future__ import print_function
import os,sys
import time
import boto3
import glob
from pprint import pprint
import re
import requests
import json
def extract_url(response):
'''
apiのレスポンスから書き起こしを保存しているS3のurl情報を抽出
'''
p = re.compile(r'(?:\{\'TranscriptFileUri\':[ ]\')(.*?)(?:\'\}\,)')
url = re.findall(p,str(response))[0]
return url
def get_json_result(url):
'''
クラウドからjson形式の認識結果を含む情報をダウンロード
'''
try:
r = requests.get(url)
return str(r.text)
except requests.exceptions.RequestException as err:
print(err)
def extract_recognition_result(_json):
'''
認識結果を含むjsonから認識結果のみを抽出
'''
json_dict = json.loads(_json)
recognized_result = json_dict['results']['transcripts'][0]['transcript']
return recognized_result
def main():
# 作業用ディレクトリ
_dir = '/Users/RecognitionTest'
# 認識結果保存用ディレクトリ(AWSというディレクトリを事前に作成しておきます.このディレクトリ内にAPIからのレスポンス情報や書き起こし結果が保存されます)
recognition_result = _dir+'/AWS'
# 認識させたい音声ファイル名が記載されたテキストファイル
speech_fname_file = _dir+'/speech_fname.txt'
# 認識させたい音声ファイル名をリストへ格納
speech_fname_list = []
with open(speech_fname_file,'r') as f:
path = f.readline()
while path:
speech_fname_list.append(path.strip())
path = f.readline()
status_file = recognition_result+'/status.txt'
json_file = recognition_result+'/json_response.txt'
recog_result = recognition_result+'/recognition_result.txt' # 認識結果保存用ファイル
with open(status_file,'w') as status_out:
for speech_fname in speech_fname_list:
transcribe = boto3.client('transcribe')
job_name = str(speech_fname) # 音声ファイル名(必ずしも音声ファイル名である必要はなくなんでも良い)
job_uri = f'https://[バケット名].s3-ap-northeast-1.amazonaws.com/{job_name}' # Bucket name -> recongnitiontest
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='wav',
LanguageCode='ja-JP'
)
while True:
# status: レスポンス情報(認識結果が保存されているS3クラウドのURLを含む)
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
status_out.write(f'{speech_fname} {status}\n')
with open(status_file,'r') as status_in, open(json_file,'w') as json_out, open(recog_result,'w') as result:
status_list = status_in.readlines()
client = boto3.client('transcribe')
for status in status_list:
job_name = status.strip().split(' ')[0]
response = client.get_transcription_job(TranscriptionJobName=job_name)
url = extract_url(response)
_json = get_json_result(url)
recog_text = extract_recognition_result(_json)
json_out.write(f'{job_name} {_json}\n')
result.write(f'{job_name} {recog_text}\n')
if __name__ == "__main__":
main()
- speech_fname.txtには認識させたい音声ファイル名が記載されたテキストファイルです.***S3のバケットに置いた音声ファイル名と同じでなければなりません.***以下に例を載せておきます.5つの別々の音声ファイルを認識させたい場合の例です.この音声ファイル名と同じ音声ファイルをS3クラウドストレージに置いておけば大丈夫です.
speech_fname.txt
speech_data1.wav
speech_data2.wav
speech_data3.wav
speech_data4.wav
speech_data5.wav
- APIのアクセスキーなどの環境変数を設定して,speech_fname.txtを用意できたならば,recognize.pyを実行すれば認識が開始されます.
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.- Amazon Transcribeでも確認可能
Google Cloud Speech-to-Text の使い方
- Amazon Transcribeとは違い,認識させたい音声をクラウドに置く必要はありません.
- ローカルにある音声を認識可能
- 認識させたい音声ファイルのパスを記載したテキストファイルを用意しておく
- 以下のサンプルプログラムではspeech_data_path.txt
- IBM Watson, Microsoft Azure でも同様のものを使用
- それではまずAPIキーを含む環境変数を通しておきます.APIキーの情報はjsonファイルに記載されています.このjsonファイルはGCPのコンソールからダウンロードしておく必要があります.ナビゲーションメニューのAPIとサービスへ行けばjson形式の認証情報をダウンロードできます.
% export GOOGLE_APPLICATION_CREDENTIALS="[jsonファイルへのpath]"
% source ~/.zshrc
- あとはAPIを叩くだけです.サンプルプログラムを載せておきます.
recognize.py
import io
import glob
import os
import shutil
from google.cloud import speech_v1p1beta1
from google.cloud.speech_v1p1beta1 import enums
def main():
client = speech_v1p1beta1.SpeechClient()
# 作業用ディレクトリ
_dir = '/Users/RecognitionTest'
# 認識結果保存用ディレクトリ
recognition_result = _dir+'/GCP'
# 認識させたい音声ファイルへのパスが記載されたテキストファイル
speech_data_path_file = _dir+'/speech_data_path.txt'
# 認識させたい音声ファイルのパスをリストへ格納
speech_path_list = []
with open(speech_data_path_file,'r') as f:
path = f.readline()
while path:
speech_path_list.append(path.strip())
path = f.readline()
recog_result_fname = recognition_result+'/recognition_result.txt' # 認識結果保存用ファイル
with open(recog_result_fname,'w') as recog_result:
for speech_path in speech_path_list:
# 音声ファイル名取得(認識結果を書き込むファイル名に使用)
speech_file_name = speech_path.split('/')[-1].split('.')[0] # 音声ファイル名を認識結果書き込み用ファイル名にする
# The use case of the audio, e.g. PHONE_CALL, DISCUSSION, PRESENTATION, et al.
interaction_type = enums.RecognitionMetadata.InteractionType.DISCUSSION
# The kind of device used to capture the audio
recording_device_type = enums.RecognitionMetadata.RecordingDeviceType.RECORDING_DEVICE_TYPE_UNSPECIFIED
# The device used to make the recording.
# Arbitrary string, e.g. 'Pixel XL', 'VoIP', 'Cardioid Microphone', or other
# value.
recording_device_name = "MR"
metadata = {
"interaction_type": interaction_type,
"recording_device_type": recording_device_type,
"recording_device_name": recording_device_name,
}
# The language of the supplied audio. Even though additional languages are
# provided by alternative_language_codes, a primary language is still required.
language_code = "ja-JP" # 言語を日本語に設定
config = {"metadata": metadata, "language_code": language_code}
with io.open(speech_path, "rb") as f:
content = f.read()
audio = {"content": content}
# 認識開始
response = client.recognize(config, audio)
# 認識結果の保存と表示
for result in response.results:
# First alternative is the most probable result
alternative = result.alternatives[0]
print(u"Transcript: {}".format(alternative.transcript))
recog_result.write(u"{} {}".format(speech_file_name,alternative.transcript)+'\n')
if __name__ == "__main__":
main()
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.
IBM Watson Speech-to-Text の使い方
- 使い方はGoogle Gloud Speech-to-Text とほぼ同じです.
- ***ただしAPIキーなどをプログラム内に記述する点が異なります.***Google, Amazonでは環境変数として設定していました.
- APIキーとエンドポイントのURLを取得しておく必要があります.
- サンプルプログラムです
- ***[自分のAPIキー]と[エンドポイントのURL]***は置き換えてください
- エンドポイントは"jp-tok"を指定した方がいいです.
recognize.py
import os,sys
import glob
import re
import json
from os.path import join, dirname
from ibm_watson import SpeechToTextV1
from ibm_watson.websocket import RecognizeCallback, AudioSource
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from pprint import pprint
import shutil
import jaconv
def extract_recognition_result(_json):
recognized_result = []
json_dict = json.loads(_json)
try:
transcript = json_dict['results'][0]['alternatives'][0]['transcript'].split(' ')
except:
return ' '
# 言い淀み単語はカタカナ表記なので,平仮名表記に変換
for word in transcript:
if 'D_' in word:
recognized_result.append(jaconv.kata2hira(word))
else:
recognized_result.append(word)
recognized_result = ' '.join(recognized_result)
recognized_result = recognized_result.replace('D_','') #言い淀みは'D_'で表現されているので削除する
return str(recognized_result)
def main():
# 作業用ディレクトリ
_dir = '/Users/RecognitionTest'
# 認識結果保存用ディレクトリ
recognition_result = _dir+'/Watson'
# 認識させたい音声ファイルへのパスが記載されたテキストファイル
speech_data_path_file = _dir+'/speech_data_path.txt'
# 認識させたい音声ファイルのパスをリストへ格納
speech_path_list = []
with open(speech_data_path_file,'r') as f:
path = f.readline()
while path:
speech_path_list.append(path.strip())
path = f.readline()
# jsonファイル(認識結果)格納ディレクトリ
json_result_dir = recognition_result+'/json_result'
for speech_path in speech_path_list:
# 音声ファイル名取得(認識結果を書き込むファイル名に使用)
speech_file_name = speech_path.split('/')[-1].split('.')[0]
with open(f'{json_result_dir}/{speech_file_name}.json','w') as json_out:
# set apikey
authenticator = IAMAuthenticator('[自分のAPIキー]')
service = SpeechToTextV1(authenticator=authenticator)
# set endpoint url
service.set_service_url('[エンドポイントのURL]')
lang = 'ja-JP_BroadbandModel' # 言語を日本語に設定
with open(speech_path,'rb') as audio_file:
result_json = service.recognize(audio=audio_file, content_type='audio/wav', timestamps=True, model=lang, word_confidence=True, end_of_phrase_silence_time=30.0)
result_json = result_json.get_result()
# json形式の認識結果を取得しているので,json_resultX.jsonに書き込み
result = json.dumps(result_json, indent=2, ensure_ascii=False)
json_out.write(result)
json_file_list = glob.glob(json_result_dir+'/*.json')
recog_result_file = recognition_result+'/recognition_result.txt'
with open(recog_result_file,'w') as result:
for json_file in json_file_list:
with open(json_file,'r') as _json:
print(json_file)
speech_file_name = json_file.strip().split('/')[-1].split('.')[0]
#保存したjson_resultX.jsonから認識結果のみを抽出
recog_result = extract_recognition_result(_json.read())
result.write(f'{speech_file_name} {recog_result}\n')
if __name__ == "__main__":
main()
- Watsonはデフォルトでは,言い淀み部分に"D_"を追記しています.サンプルプログラムではこの部分を除去しています.あと,言い淀み単語はカタカナ表記となっていますが,私は平仮名表記が必要であったので変換しています.
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.
Microsoft Azure Speech-to-Text の使い方
- AzureはIBM Watsonと同様にプログラム内にAPIキー(speech_key)とregionを記述します
- speech_key: [自分のspeech_key] を書き換えてください
- service_region:japaneast としました
recognize.py
import time
import wave
import glob
import re
import os
try:
import azure.cognitiveservices.speech as speechsdk
except ImportError:
print("""
Importing the Speech SDK for Python failed.
Refer to
https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstart-python for
installation instructions.
""")
import sys
sys.exit(1)
# Set up the subscription info for the Speech Service:
# Replace with your own subscription key and service region (e.g., "westus").
# サービス地域(service_region)を東日本(japaneast)に設定
# speech_key -> Azureのマイページで確認
speech_key, service_region = "[自分のspeech_key]", "japaneast"
# Specify the path to an audio file containing speech (mono WAV / PCM with a sampling rate of 16
# kHz).
def main():
"""performs continuous speech recognition with input from an audio file"""
# <SpeechContinuousRecognitionWithFile>
# 作業用ディレクトリ
_dir = '/Users/RecognitionTest'
# 認識結果保存用ディレクトリ
recognition_result = _dir+'/Azure'
# 認識させたい音声ファイルへのパスが記載されたテキストファイル
speech_data_path_file = _dir+'/speech_data_path.txt'
# 認識させたい音声ファイルのパスをリストへ格納
speech_path_list = []
with open(speech_data_path_file,'r') as f:
path = f.readline()
while path:
speech_path_list.append(path.strip())
path = f.readline()
#認識結果書き込み用ファイル作成(pre_result.txtには認識結果以外の情報も書き込まれる)
with open(f'{recognition_result}/pre_result.txt','w') as recog_result:
for speech_path in speech_path_list:
speech_file_name = speech_path.split('/')[-1].split('.')[0] # 音声ファイル名を認識結果書き込み用ファイル名に使用
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
audio_config = speechsdk.audio.AudioConfig(filename=speech_path)
speech_config.speech_recognition_language="ja-JP" # 言語を日本語に設定
profanity_option = speechsdk.ProfanityOption(2) # 不適切発言処理 0->隠す, 1->削除, 2->含む
speech_config.set_profanity(profanity_option=profanity_option) # profanity_optionを変更
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
done = False
def stop_cb(evt):
"""callback that signals to stop continuous recognition upon receiving an event `evt`"""
print('CLOSING on {}'.format(evt))
nonlocal done
done = True
# Connect callbacks to the events fired by the speech recognizer
speech_recognizer.recognizing.connect(lambda evt: print('RECOGNIZING: {}'.format(evt)))
#認識結果の書き込み
speech_recognizer.recognized.connect(lambda evt: recog_result.write('{} RECOGNIZED: {}'.format(speech_file_name,evt)+'\n'))
speech_recognizer.session_started.connect(lambda evt: print('SESSION STARTED: {}'.format(evt)))
speech_recognizer.session_stopped.connect(lambda evt: print('SESSION STOPPED {}'.format(evt)))
speech_recognizer.canceled.connect(lambda evt: print('CANCELED {}'.format(evt)))
# stop continuous recognition on either session stopped or canceled events
speech_recognizer.session_stopped.connect(stop_cb)
speech_recognizer.canceled.connect(stop_cb)
# Start continuous speech recognition
speech_recognizer.start_continuous_recognition()
while not done:
time.sleep(.5)
speech_recognizer.stop_continuous_recognition()
# </SpeechContinuousRecognitionWithFile>
def fix_recognition_result():
'''
- pre_result.txtは以下のような形式の認識結果である
- [SPEECH FILE NAME] RECOGNIZED: SpeechRecognitionEventArgs(session_id=XXX, result=SpeechRecognitionResult(result_id=YYY, text="[認識結果]", reason=ResultReason.RecognizedSpeech))
- [SPEECH FILE NAME]と[認識結果]の部分のみを抽出
'''
# 認識結果ファイル
pre_result = '/Users/kamiken/speech_recognition_data/Cloud_Speech_to_Text/Compare4Kaldi/Compare_Test1/Azure/pre_result.txt'
# 認識結果以外の情報(パラメータなど)を削除
with open(pre_result,'r') as pre, open(pre_result.replace('pre_',''),'w') as result:
lines = pre.readlines()
for line in lines:
split_line = line.strip().split(' ')
speech_file_name = split_line[0]
text = str(re.findall('text=\"(.*)\",',' '.join(split_line[1:]))[0])+'\n'
result.write(f'{speech_file_name} {text}')
if __name__ == "__main__":
main()
fix_recognition_result()
- Azureは親切なことに,Fワードなど不適切な発言を「***」のようにアスタリスクで隠してくれます.私はWERを算出しないといけなかったので,サンプルプログラムでは全て表示させるような設定にしてあります.
- profanity_option = speechsdk.ProfanityOption(2)
- 引数は0(不適切発言をアスタリスクで隠す), 1(削除する), 2(隠しも削除もしない)のいずれかです
- profanity_option = speechsdk.ProfanityOption(2)
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.