分類モデルの評価指標として、適合率や再現率などがあります。Web上で多くの解説記事がありますが、scikit-learnのclassification_reportに表示される各指標を読み解くためには、プラスアルファの理解が必要です。この記事では、実際にscikit-learnで出力される内容を例にして、適合率と再現率の意味を解説します。
Webとかでよくある説明
機械学習で分類モデルを評価するとき、正解率(Accuracy)、適合率(Precision)、再現率(Recall)、F1-scoreなどの評価指標をよく利用します。これらの解説として、以下のような2値分類の説明が多くあります。
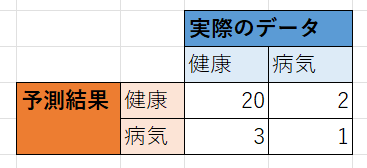
正解率(Accuracy)
正解率(Accuracy) は、全体の中で正解した割合
正解率 = (20 + 1) ÷ (20 + 2 + 3 + 1) ≒ 0.81
適合率(Precision)
適合率(Precision)は、健康と予測したうち、実際に健康だった割合
適合率 = 20 ÷ (20 + 2) ≒ 0.91
再現率(Recall)
再現率(Recall)は、実際に健康な数のうち、健康だと予測できた割合
再現率 = 20 ÷ (20 + 3) ≒ 0.87
F1-score
F1-scoreは、適合率と再現率が共に高い場合に、高くなる指標
F1-score = (2 × 適合率 × 再現率) ÷ (適合率 + 再現率) ≒ 0.89
実際にscikit-learnで分類モデルを評価した場合
有名なアヤメのデータセットを利用して分類モデルを構築。
scikit-learnのclassification_reportを使って分類モデルの評価指標を出力した結果は以下となります。
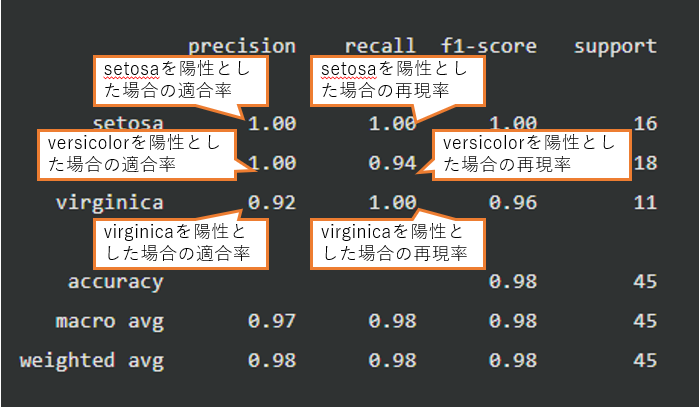
setosa, versicolor, virginicaは、アヤメの種類名です。
Precision(適合率)、Recall(再現率)、F1-scoreは分類のラベル別に複数存在します。
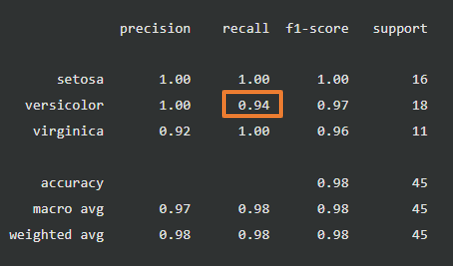
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
accuracy 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
※ソースコードは最後の方に記載しています。
この記事のテーマ:よくある説明ではPrecisionやRecallは1つずつなのに、scikit-learnで出力されるPrecisionやRecallは複数!?
よくある説明ではPrecisionやRecallは1つずつなのに、scikit-learnで出力されるPrecisionやRecallは複数あります。
この記事では、実際にscikit-learnで出力されるPrecisionやRecallを例にして、適合率と再現率の意味を解説します。
結論:適合率と再現率は、何を陽性とするかで異なる
適合率と再現率は、何を陽性として算出するかによって結果が異なります。
よくある説明は健康であることを陽性として算出しています。
scikit-learnで分類モデルを評価した場合のclassification_reportの出力は以下の3パターンの適合率と再現率を出力しています。
- setosaを陽性、versicolorとvirginicaを陰性とした場合
- versicolorを陽性、setosaとvirginicaを陰性とした場合
- virginicaを陽性、setosaとversicolorを陰性とした場合
Webとかでよくある説明の、もう少し詳しい説明
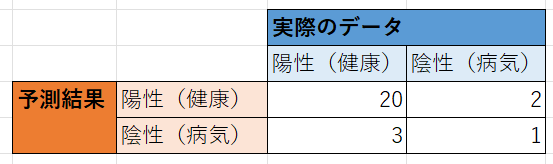
よくある説明は健康であることを陽性とした場合の適合率と再現率です。
より詳しく記載すると以下になります。
適合率(Precision)は、陽性(健康)と予測したうち、実際に陽性(健康)だった割合
適合率 = 20 ÷ (20 + 2) ≒ 0.91
再現率(Recall)は、実際に陽性(健康)な数のうち、陽性(健康)だと予測できた割合
再現率 = 20 ÷ (20 + 3) ≒ 0.87
実際にscikit-learnで分類モデルを評価した場合の、もう少し詳しい説明
以下が実際の分類(テストデータ)と予測の分類(モデルによる予想値)です。
0, 1, 2はそれぞれ、setosa, versicolor, virginicaを意味するラベルです。

classification_reportの出力は以下の3パターンの適合率と再現率を出力しています。
- setosaを陽性、versicolorとvirginicaを陰性とした場合
- versicolorを陽性、setosaとvirginicaを陰性とした場合
- virginicaを陽性、setosaとversicolorを陰性とした場合
例1:versicolorの再現率
例えば、versicolor(ラベル1)を陽性とした場合の再現率(Recall)は、
実際のversicolor(ラベル1)18個のうち、予測でversicolorであることがヒットしたのは17個なので、
再現率 = 17 ÷ 18 ≒ 0.94 となります。
例2:versicolorの適合率
例えば、versicolor(ラベル2)を陽性とした場合の適合率(Precision)は、
virginica(ラベル2)と予測した12個のうち、実際に11個がvirginicaだったので、
適合率 = 11 ÷ 12 ≒ 0.92 となります。
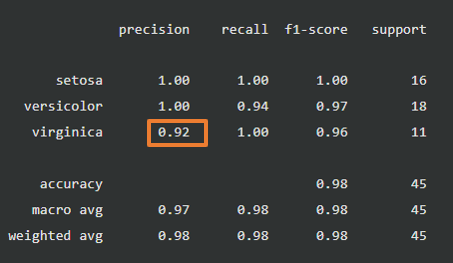
まとめ
適合率と再現率は、何を陽性として算出するかによって結果が異なります。scikit-learnで分類モデルを評価した場合のclassification_reportの出力では、各ラベルをそれそれ陽性とした場合の適合率と再現率が出力されています。
各指標の意味を理解してデータ分析を行いましょう。以下のコンテンツ(私が制作したもの)は、データ分析の前処理、可視化といったプロセスを学べます。一部無料公開されているので、無料のところから試してみましょう。
classification_reportに関する補足
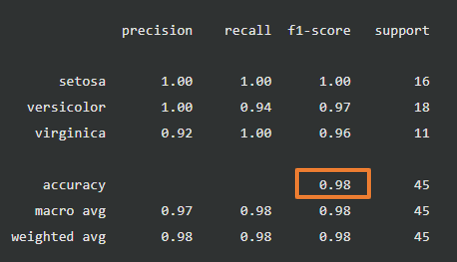
正解率(Accuracy)
正解率(Accuracy)は1つです。どのラベルを陽性にしようが変わりません。
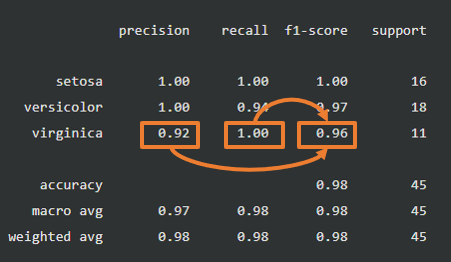
F1-score
F1-scoreも、ラベルごとに存在します。そのラベルの適合率と再現率から計算されています。
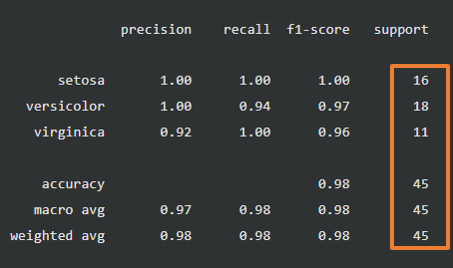
support
実際の分類のラベル数です。
実際の分類で、setosaは16個、versicolorは18個、virginicaは11個あります。
accuracy, macro ave, weighted avgのsupportには、合計値(16+18+11=45)が出力されます。
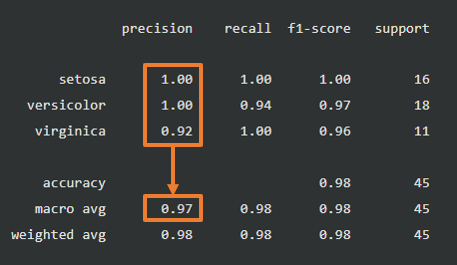
macro avg
各ラベルの平均値です。
例えばmacro avgの適合率(Precision) = 1.00 + 1.00 + 0.92 ≒ 0.97
weighted avg
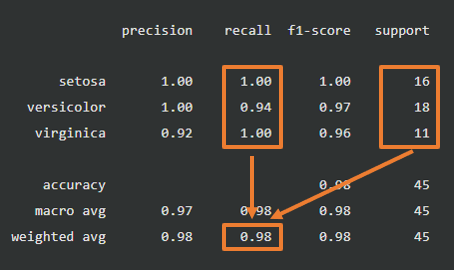
各ラベルの加重平均値です。実際の分類のラベル数で加重平均をとった値です。
例えばweighted avgの再現率(Recall) = 1.00 × 16 ÷ 45 + 0.94 × 18 ÷ 45 + 1.00 × 11 ÷ 45 ≒ 0.98
利用したソースコード
# データセットの取得
from sklearn.datasets import load_iris
dataset = load_iris()
X = dataset.data
y = dataset.target
# 学習データとテストデータに分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 決定木で学習
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=0)
model.fit(X_train, y_train)
# テストデータから予測値を算出
y_pred = model.predict(X_test)
# classification_reportを生成
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred, target_names=dataset.target_names)
# テストデータと予測値を表示
print(y_test)
print(y_pred)
# classification_reportを表示
print(report)