初めに
皆さん始めまして。今回は学校の課題研究の成果を書こうと思います。
自己紹介
moyaretaと言います。高校2年生です。高校からプログラミングに触れ始めました。まだまだ初学者ですが成長していけたらいいなと思います。
この記事について
筆者の高校では主に先生から生徒に教科や部活、委員会などの連絡においてClassiを用いており、このアプリでは様々な不便なところがあります。それが次の3つです。
1.パソコンでClassiを見る場合毎回ログインしなければならない
2.不要な情報が表示される
3.Classiのプッシュ通知を切っている場合情報が即座に入ってこない
今回はこれらの不満点を改善するアルゴリズムを考えました。そしてそれをpythonを使って書きました。
Classiについて
"スマートフォン、タブレット、PCなどのデバイスを問わずに利用できるクラウドサービスです。授業や面談、ポートフォリオの蓄積といった学校内の活動にとどまらず、学校と保護者間のコミュニケーションツールとしても積極的に活用されています。"
https://classi.jp
参照
今回使うもの
プログラミング言語としてpythonを、そしてClassiは動的サイトなのでseleniumを使ってweb上の操作を自動化します。webdriverはChrome Driverを利用します。そして後ほど解説しますが今回はClassiの更新をラインに通知するのでLINE Notifiyを活用します。それぞれのurlを貼ります。
1.Visual Studio Code
https://code.visualstudio.com/download
2.selenium
https://www.selenium.dev/downloads/
3.ChromeDriver
https://sites.google.com/chromium.org/driver/
4.LINE Notifiy
https://notify-bot.line.me/ja/
⚠️2025年3月をもってサービスが終了してしまいました。
アルゴリズム
今回のアルゴリズムをざっくり解説します
①以前に取得したClassiの情報をテキストドキュメントCから読み込み、変数Bに代入します。
②Classiに自動ログインし、限られた情報を集めます。そしてそれを変数A(新しい情報)に代入します。変数AはテキストドキュメントCに書き込まれます。この変数Aは次回の変数Bになります。
③変数Aと変数Bの文字列の違いを検知し、もし違いがあった場合その違いをLINEに通知します。
④①~③を一時間ごとに実行します。
プログラムの流れ
1.必要なライブラリをインストールする
#1
#様々な定義
#coding:UTF-8
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
#Keysは別の方法でログインするときに必要です
from selenium.webdriver.common.by import By
import requests
import schedule
from time import sleep
import time
import json
#Keysは別の方法でログインするときに必要ですについて
後ほど解説しますがcookieを活用してログインする以外に無理矢理ユーザーIDとパスワードを入れてログインをする方法があります。一応それを活用するときがあるので残しています。
2.ファイルのパスの指定
#2
#様々なファイルのパスの指定
cookies_file=R"cookieのログイン情報がjsonで書かれているテキストドキュメントを指定する"
kakikomifile_path = R"過去の情報が書かれているテキストドキュメントを指定する"
driver_path = R"ChromeDriver.exeがある場所を指定する"
ファイルのパスの前にRと記述することでエスケープシーケンスを無視することができます。筆者のwindowsのユーザー名のせいで/aとなってしまう部分があり正常に読み取れなかったのでRと記述しています。
3.過去の情報を読み取りChromeDriverを作成する
#3
def job():
#kakikomiyoufairuを読み込む
def read_last_written_data(file_path):
try:
with open(file_path, "r", encoding="utf-8") as file:
last_data = file.read().strip()
return last_data
except FileNotFoundError:
return None
#ChromeDriverの作成
service = Service(executable_path = driver_path)
driver = webdriver.Chrome(service = service)
文字通りです。
4.Cookieを使ってクラッシーに自動ログインする
#4
#classiへのログイン作業
#1回目のアクセス
URL1="https://id.classi.jp/login/identifier"
URL2="https://platform.classi.jp/"
driver.get(URL1)
with open(cookies_file, 'r') as file:
cookies = json.load(file)
for cookie in cookies:
driver.add_cookie(cookie)
# 2回目のアクセス
driver.get(URL2)
#一覧へ移動
sleep(1)
itirann = driver.find_element(By.CLASS_NAME, "menu-txt")
itirann.click()
sleep(2)
ここのCookieを使ったログインについて解説します。筆者もよく理解しているわけではないのでご了承ください。
まずクラッシーのログイン画面のURLにアクセスします。ここで以前に取得したCookieのログイン情報(取得の仕方は後で解説)を取得してそれをドライバーに追加します。そのあとにクラッシーホーム画面のURLに飛ぶとログインが完了しています。この方法であれば約1秒くらいでログインを完了することができます。
Cookieの取得について
取得方法はいろいろありますが今回は二つの方法を解説します。
1.Chromeの拡張機能からCookieを取得する
リンク
https://chromewebstore.google.com/detail/editthiscookie/fngmhnnpilhplaeedifhccceomclgfbg
これを利用します
2.seleniumを利用して取得する
#様々な定義
#coding:UTF-8
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
#様々なファイルのパスの指定
driver_path = R"chromedriver.exeがある場所"
#webdriverの作成
service = Service(executable_path = driver_path)
driver = webdriver.Chrome(service = service)
#classiへのアクセス
URL = "https://id.classi.jp/login/identifier"
driver.get(URL)
#classiへのログイン作業
def login():
USER_NAME= "ユーザー名"
id_text = driver.find_element(By.NAME,"username")
id_text.send_keys(USER_NAME)
id_text.send_keys(Keys.RETURN)
sleep(1)
PASSWORD="パスワード"
password_text = driver.find_element(By.NAME,"password")
password_text.send_keys(PASSWORD)
password_text.send_keys(Keys.RETURN)
login()
sleep(1)
cookies = driver.get_cookies()
# 取得したCookieを表示
print("取得したCookie:")
print("[")
for cookie in cookies:
print(cookie)
print("]")
これでクッキー情報を読み取ることができます。ちなみにこれは前述した無理矢理ユーザーIDとパスワードを入れてログインする方法をとっています。"#Classiへのログイン作業"の部分をもとのプログラミングに書き換えることもできます。
しかしこれら二つの方法に共通するデメリットがあります。それがjsonを書き直さなければならない点です。なぜかこれらの方法で読み取るとsleniumがjsonを読み取れずエラーが発生します。エラー文を読みとって一個ずつ直していくとseleniumがログイン情報のCookieを読み取ることができます。筆者はedit this Cookieを利用してCookie情報を取得したのでjsonの直すべき部分を書きます。
「unspecified」→「None」
「lax」→「Lax」
「platform.classi.jp」→「classi.jp」
これで筆者はseleniumがjsonを読み取れるようになりました。
一応seleniumで読み取ったほうの直すべき部分も記述します。
「platform.classi.jp」→「classi.jp」
「'」→「"」
「False」→「false」
「True」→「true」
「}{」→「},{」 (中括弧と中括弧の間にカンマを追加してください。)
さらにもう1つデメリットがあります。それが定期的にCookieの有効期限が切れるのでCookieを手動で更新しなければならない点です。これを改善するためにseleniumから定期的にCookieのログイン情報を読み取り、適切な形に直してから更新するという方法があります。しかしかなり面倒くさいのでそのプログラムを書くのはかなり先になりそうです。
5.Classiから必要な情報を読み取り新しい情報と過去の情報を整理する
#5
# 検出したい複数の文字列のリスト
#ページ内のすべてのリンクから各文字列を持つ要素を取得
search_texts = ["取得したい教科","取得したい教科"]
elements_with_texts = []
for search_text in search_texts:
elements_with_text = [elem for elem in driver.find_elements(By.XPATH, "//a") if search_text in elem.text]
elements_with_texts.extend(elements_with_text)
#新しい情報を変数に代入
new_all_text = str('\n'.join(elem.text for elem in elements_with_texts))
new_data = new_all_text.replace(" ","").replace(" ","")
print("新しい取得した文字",new_data,"新しく取得した文字")
gtec=new_data.split()
#過去の情報を変数に代入
last_data = str(read_last_written_data(kakikomifile_path))
print("過去の情報",last_data,"過去の情報")
#書き込み用ファイルに新しい情報を書き込む
with open(kakikomifile_path, "w", encoding="utf-8") as file:
file.write('\n'.join(gtec))
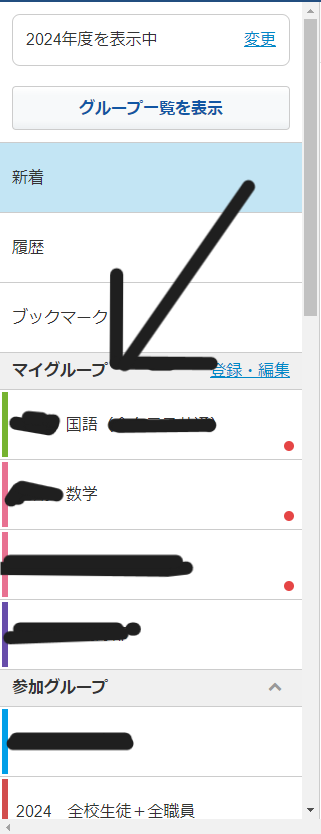
search_textsのところには情報を取得したいマイグループ(下記の写真参照)を書き込んでください。(何個でも大丈夫です)ごちゃごちゃしていて改善の余地はありそうですがとりあえずはそのままにしています。
6.新しい情報と過去の情報の差異を取得する
#6
#差異の取得
common = 0
for moji1, moji2 in zip(last_data, new_data):
if char1 == char2:
common += 1
else:
break
common1 = 0
for moji1, moji2 in zip(reversed(last_data), reversed(new_data)):
if char1 == char2:
common1 += 1
else:
break
ここでは二つの文字列の差異を検出しています。ネットで調べたところ意外と二つの文字列の違いを検出できるものがなくすべてchatgptに書かせました。少しわかりやすく書き換えています。
7.もし差異があった場合にLINEに通知する
#7
# 更新された部分を抽出してLINEに送る
if common == len(new_data) == len(last_data) and common1 == len(new_data) == len(last_data):
print("差異なし")
else:
updated_part = new_data[common:len(new_data)-common1]
print(updated_part)
def sinntarou():
url = "https://notify-api.line.me/api/notify"
token = "ここにトークンを貼り付けてください"
headers = {"Authorization" : "Bearer "+ token}
message = str(updated_part)+"が更新されました"
payload = {"message" : message}
r = requests.post(url ,headers = headers ,params=payload)
sinntarou()
job()
差異があった場合は差異なしと、差異があった場合は差異の部分だけをLINEに送っています。ここでLINE Notifyを使っています。詳しくは参考文献をご覧ください。
https://qiita.com/pontyo4/items/10aa0ba0a17aee19e88e
8.一時間ごとに動くように設定する
#8
# 1時間ごとにjob関数を実行
schedule.every().hour.do(job)
while True:
schedule.run_pending()
time.sleep(1)
文字通りです
完成したもの
#1
#様々な定義
#coding:UTF-8
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
#Keysは別の方法でログインするときに必要です
from selenium.webdriver.common.by import By
import requests
import schedule
from time import sleep
import time
import json
#2
#様々なファイルのパスの指定
cookies_file=R"cookieのログイン情報がjsonで書かれているテキストドキュメントを指定する"
kakikomifile_path = R"過去の情報が書かれているテキストドキュメントを指定する"
driver_path = R"ChromeDriver.exeがある場所を指定する"
#3
def job():
#kakikomiyoufairuを読み込む
def read_last_written_data(file_path):
try:
with open(file_path, "r", encoding="utf-8") as file:
last_data = file.read().strip()
return last_data
except FileNotFoundError:
return None
#ChromeDriverの作成
service = Service(executable_path = driver_path)
driver = webdriver.Chrome(service = service)
#4
#classiへのログイン作業
#1回目のアクセス
URL1="https://id.classi.jp/login/identifier"
URL2="https://platform.classi.jp/"
driver.get(URL1)
with open(cookies_file, 'r') as file:
cookies = json.load(file)
for cookie in cookies:
driver.add_cookie(cookie)
# 2回目のアクセス
driver.get(URL2)
#一覧へ移動
sleep(1)
itirann = driver.find_element(By.CLASS_NAME, "menu-txt")
itirann.click()
sleep(2)
#5
# 検出したい複数の文字列のリスト
#ページ内のすべてのリンクから各文字列を持つ要素を取得
search_texts = ["取得したい教科","取得したい教科"]
elements_with_texts = []
for search_text in search_texts:
elements_with_text = [elem for elem in driver.find_elements(By.XPATH, "//a") if search_text in elem.text]
elements_with_texts.extend(elements_with_text)
#新しい情報を変数に代入
new_all_text = str('\n'.join(elem.text for elem in elements_with_texts))
new_data = new_all_text.replace(" ","").replace(" ","")
print("新しい取得した文字",new_data,"新しく取得した文字")
gtec=new_data.split()
#過去の情報を変数に代入
last_data = str(read_last_written_data(kakikomifile_path))
print("過去の情報",last_data,"過去の情報")
#書き込み用ファイルに新しい情報を書き込む
with open(kakikomifile_path, "w", encoding="utf-8") as file:
file.write('\n'.join(gtec))
#6
#差異の取得
common = 0
for char1, char2 in zip(last_data, new_data):
if char1 == char2:
common += 1
else:
break
common1 = 0
for char1, char2 in zip(reversed(last_data), reversed(new_data)):
if char1 == char2:
common1 += 1
else:
break
#7
# 更新された部分を抽出してLINEに送る
if common == len(new_data) == len(last_data) and common1 == len(new_data) == len(last_data):
print("差異なし")
else:
updated_part = new_data[common:len(new_data)-common1]
print(updated_part)
def sinntarou():
url = "https://notify-api.line.me/api/notify"
token = "ここにトークンを貼り付けてください"
headers = {"Authorization" : "Bearer "+ token}
message = str(updated_part)+"が更新されました"
payload = {"message" : message}
r = requests.post(url ,headers = headers ,params=payload)
sinntarou()
job()
#8
# 1時間ごとにjob関数を実行
schedule.every().hour.do(job)
while True:
schedule.run_pending()
time.sleep(1)
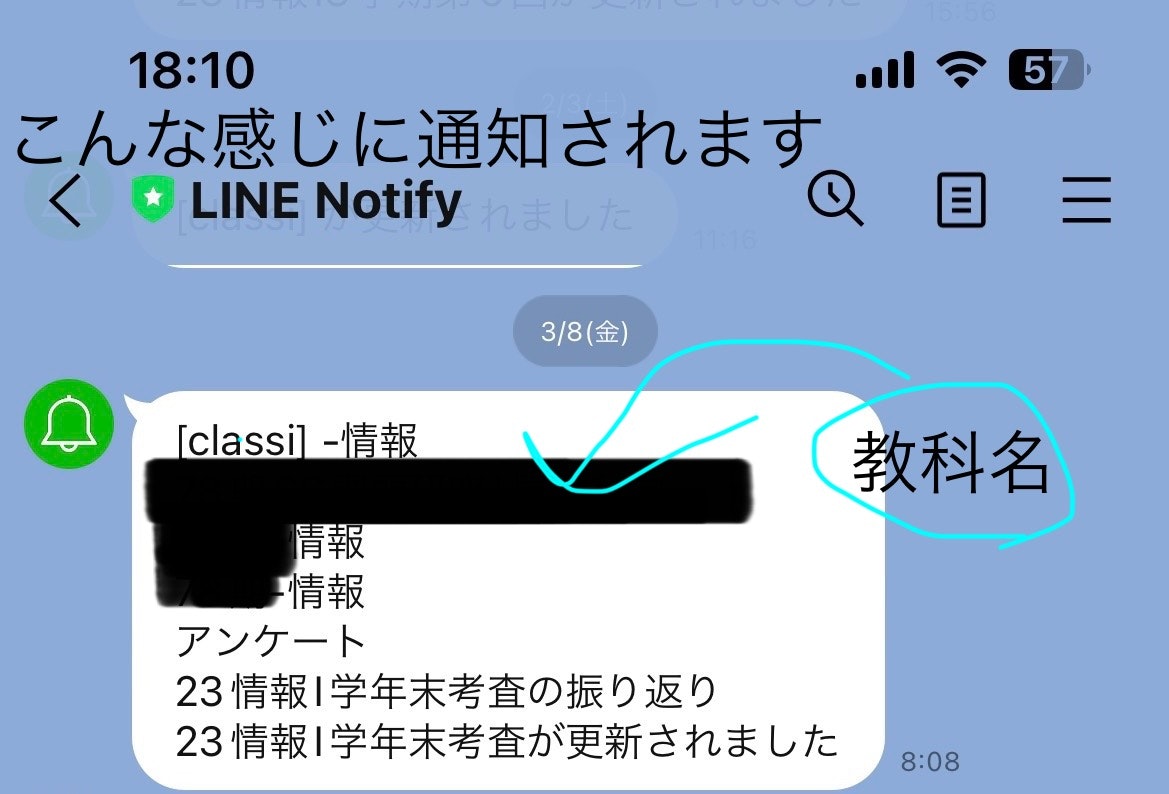
最後に
今回この記事を書いた目的は2つあります。1つ目は様々な意見が欲しいためです。ぜひコメントをお待ちしております。2つ目は課題研究発表会で参考文献を書いたという人を見つけてその人との連絡先を交換しとけばよかったと後悔しているからです。もしその人が見ているならば連絡をもらえるととても嬉しいです。
見てくださりありがとうございました!
参考文献