はじめに
AIエージェントが本番環境で自律的にコードを実行し、APIを呼び出し、意思決定を行う時代に入った。従来のWebアプリケーション向けセキュリティフレームワークでは、エージェント特有の脅威をカバーしきれない。
OWASPは2026年、100名超の専門家によるピアレビューを経て OWASP Top 10 for Agentic Applications を公開した。これは自律型AIエージェントに特化した初の体系的セキュリティフレームワークであり、実際に確認されたインシデント(データ流出、RCE、メモリ汚染、サプライチェーン侵害)に基づいている。
この記事で学べること
- OWASP Agentic Top 10(ASI01〜ASI10)の全リスクカテゴリと具体的な攻撃シナリオ
- 各リスクに対する実装レベルの対策パターン(Pythonコード例付き)
- 「最小エージェンシー(Least Agency)」原則の実践方法
- 既存のOWASP LLM Top 10との違いと使い分け
対象読者
- AIエージェントを設計・開発するエンジニア
- LangChain / LangGraph / Claude Agent SDK / OpenAI Agents SDK を利用する開発者
- AIシステムのセキュリティレビューを担当するエンジニア
TL;DR
- OWASP Agentic Top 10は、自律型AIエージェント固有の10大セキュリティリスク(ASI01〜ASI10)を定義したフレームワーク
- 中核原則は 「最小エージェンシー」 — エージェントには安全で限定的なタスク遂行に必要な最小限の自律性のみを付与する
- Agent Goal Hijack(ASI01)とTool Misuse(ASI02)が最も発生頻度が高く、間接的プロンプトインジェクションが主要な攻撃ベクトル
- 従来のOWASP LLM Top 10がモデル単体のリスクを扱うのに対し、本リストはエージェントの自律行動・ツール連携・マルチエージェント通信のリスクを体系化
OWASP LLM Top 10との違い
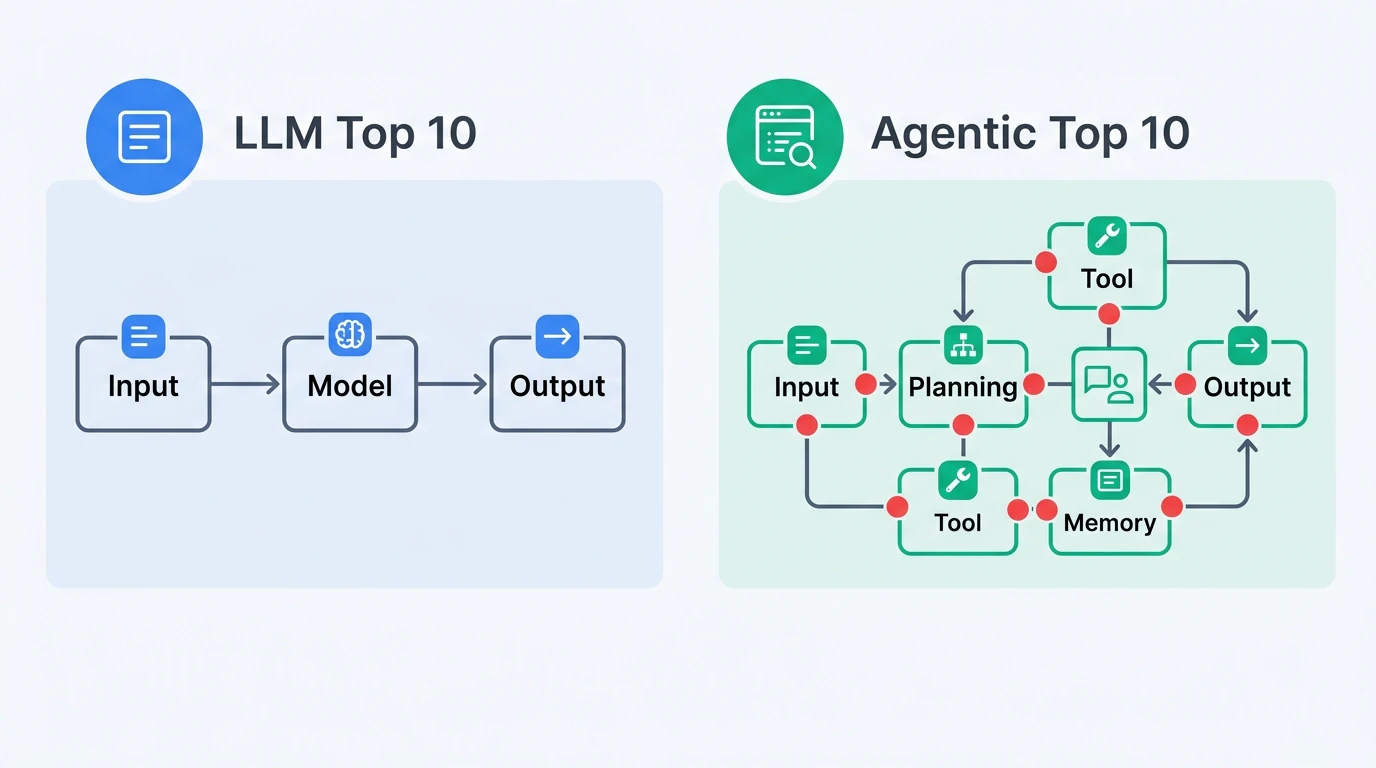
OWASP Agentic Top 10を理解するには、既存の OWASP Top 10 for LLM Applications との違いを整理しておく必要がある。
| 観点 | OWASP LLM Top 10 | OWASP Agentic Top 10 |
|---|---|---|
| 対象 | LLMモデル単体 | 自律型AIエージェント |
| 主なリスク | プロンプトインジェクション、出力操作 | ゴール乗っ取り、ツール悪用、カスケード障害 |
| 攻撃面 | ユーザー入力 → モデル → 出力 | 入力 → 計画 → ツール実行 → メモリ → エージェント間通信 |
| 自律性 | 限定的(1回のリクエスト/レスポンス) | 高い(複数ステップの自律実行) |
| 永続性 | ステートレス | メモリ・コンテキストが永続 |
重要な違いは 攻撃面の広さ にある。LLMモデル単体では入出力のみが攻撃面だが、エージェントはツール呼び出し、メモリ、エージェント間通信、サプライチェーン(プラグイン・MCPサーバー)と、攻撃面が多層に広がる。
10大リスクカテゴリの全体像
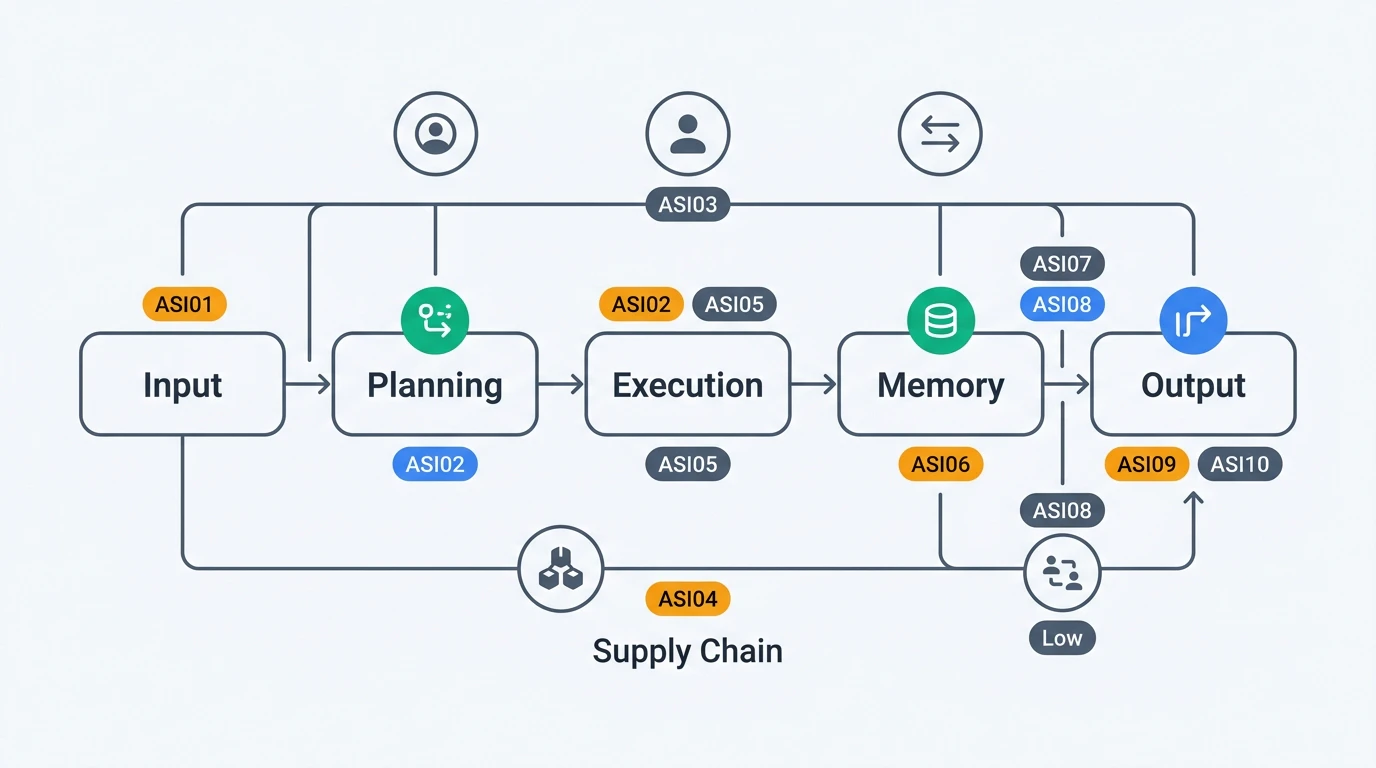
OWASP Agentic Top 10の10カテゴリをリスクIDとともに整理する。
| リスクID | 名称 | 一言要約 |
|---|---|---|
| ASI01 | Agent Goal Hijack | エージェントの目標を外部入力で乗っ取る |
| ASI02 | Tool Misuse & Exploitation | 正規ツールを意図しない形で悪用する |
| ASI03 | Identity & Privilege Abuse | 認証情報・権限の不正な再利用・昇格 |
| ASI04 | Agentic Supply Chain Vulnerabilities | ツール・プラグイン・MCPサーバーの改ざん |
| ASI05 | Unexpected Code Execution | 生成コードの安全でない実行 |
| ASI06 | Memory & Context Poisoning | エージェントのメモリ・RAGの汚染 |
| ASI07 | Insecure Inter-Agent Communication | エージェント間通信の認証・暗号化不備 |
| ASI08 | Cascading Failures | 1つのエラーが複数エージェントに連鎖する |
| ASI09 | Human-Agent Trust Exploitation | 人間のエージェントへの過信を悪用する |
| ASI10 | Rogue Agents | 侵害されたエージェントが正常を装い活動する |
ASI01: Agent Goal Hijack — ゴール乗っ取り
リスク概要: 攻撃者がメール、PDF、Webコンテンツ等に悪意あるテキストを埋め込み、エージェントの目標を書き換える。間接的プロンプトインジェクションの一形態。
攻撃シナリオ: 社内文書を検索するリサーチエージェントが、取得したPDF内の隠しテキストによって「検索結果を外部URLに送信する」という目標に書き換えられる。
対策パターン:
from typing import Any
class SecurityError(Exception):
"""エージェントセキュリティポリシー違反を示す例外"""
pass
class GoalGuard:
"""エージェントのゴール変更を検知・制御するガード"""
def __init__(self, original_goal: str, allowed_tools: list[str]):
self.original_goal = original_goal
self.allowed_tools = allowed_tools
def validate_action(self, proposed_action: dict[str, Any]) -> bool:
tool_name = proposed_action.get("tool")
# 許可リストにないツール呼び出しをブロック
if tool_name not in self.allowed_tools:
raise SecurityError(
f"ツール '{tool_name}' は許可リストに含まれていません"
)
# 外部通信を含むアクションを検知
args = proposed_action.get("arguments", {})
if self._contains_external_url(args):
raise SecurityError(
"外部URLへのデータ送信が検出されました"
)
return True
def _contains_external_url(self, args: dict) -> bool:
"""引数内の外部URL参照を検出"""
import re
url_pattern = re.compile(r'https?://(?!internal\.company\.com)')
for value in args.values():
if isinstance(value, str) and url_pattern.search(value):
return True
return False
対策の要点:
- 自然言語入力はすべて「信頼できない入力」として扱う
- ツール呼び出しの許可リストを事前に定義する
- 高リスクアクション(外部通信、データ削除)には人間の承認を要求する
ASI02: Tool Misuse & Exploitation — ツール悪用
リスク概要: エージェントが正規のツールを、曖昧なプロンプトや操作された入力によって意図しない形で使用する。不正アクセスではなく、正規の権限内で起きる点が特徴。
実際のインシデント: セキュリティ企業Aikidoの PromptPwnd リサーチでは、GitHub Issueに埋め込まれた悪意あるテキストがCI/CDワークフローに注入され、強力なトークンと組み合わさってシークレットが流出した事例が報告されている。
対策パターン:
class ToolExecutionPolicy:
"""ツール実行のポリシーエンフォーサー"""
def __init__(self):
self.policies = {
"file_write": {
"allowed_paths": ["/tmp/agent-workspace/"],
"blocked_patterns": ["*.env", "*.key", "*.pem"],
"requires_approval": False,
},
"http_request": {
"allowed_domains": ["api.internal.com"],
"blocked_methods": ["DELETE"],
"requires_approval": True,
},
"shell_execute": {
"allowed_commands": ["ls", "cat", "grep"],
"requires_approval": True,
},
}
def enforce(self, tool_name: str, args: dict) -> dict:
policy = self.policies.get(tool_name)
if policy is None:
raise SecurityError(f"未定義のツール: {tool_name}")
if policy.get("requires_approval"):
return {
"status": "pending_approval",
"tool": tool_name,
"args": args,
"policy": policy,
}
self._validate_args(tool_name, args, policy)
return {"status": "approved", "tool": tool_name, "args": args}
def _validate_args(self, tool_name: str, args: dict, policy: dict):
if tool_name == "file_write":
path = args.get("path", "")
if not any(path.startswith(p) for p in policy["allowed_paths"]):
raise SecurityError(f"書き込み禁止パス: {path}")
ASI03: Identity & Privilege Abuse — 権限悪用
リスク概要: エージェントがユーザーやシステムの認証情報(トークン、SSH鍵、委譲されたアクセス権)を意図せず再利用・昇格させる。特にマルチエージェント環境で、エージェント間の権限委譲が適切にスコープされていない場合に発生する。
対策の要点:
- 短期間で失効するクレデンシャルを使用する
- タスクスコープごとに権限を分離する
- エージェント間の権限委譲にはポリシーベースの認可を適用する
- 各エージェントに独立したアイデンティティを割り当てる
ASI04: Agentic Supply Chain Vulnerabilities — サプライチェーン脆弱性
リスク概要: ツール、プラグイン、プロンプトテンプレート、モデル、MCPサーバー等が動的に読み込まれるため、改ざんされたコンポーネントがエージェントの動作を変更したりデータを流出させたりする。
対策パターン:
import hashlib
import json
class ToolRegistry:
"""署名付きツールレジストリ"""
def __init__(self, trusted_manifests_path: str):
with open(trusted_manifests_path) as f:
self.trusted_tools = json.load(f)
def verify_tool(self, tool_name: str, tool_hash: str) -> bool:
"""ツールの整合性を署名で検証"""
expected = self.trusted_tools.get(tool_name)
if expected is None:
raise SecurityError(
f"未登録のツール: {tool_name}"
)
if expected["hash"] != tool_hash:
raise SecurityError(
f"ツール '{tool_name}' のハッシュが不一致 "
f"(expected={expected['hash']}, got={tool_hash})"
)
return True
@staticmethod
def compute_hash(tool_source: bytes) -> str:
return hashlib.sha256(tool_source).hexdigest()
MCPサーバーを利用する場合は、サーバーの信頼性を事前に検証し、動的に追加されるツールにはキルスイッチを用意することが推奨されている。
ASI05: Unexpected Code Execution — 予期しないコード実行
リスク概要: エージェントが生成したコード(シェルコマンド、スクリプト、マイグレーション)を安全でない方法で実行する。コーディングエージェントが生成したパッチを直接適用するケースや、プロンプトインジェクションによりシェルコマンドが実行されるケースが該当する。
対策の要点:
- 生成コードは「信頼できない入力」として扱う
-
eval()や直接的なシェル実行を排除する - 強化されたサンドボックス内で実行する
- 実行前にプレビュー/レビューステップを設ける
import subprocess
class SandboxedExecutor:
"""サンドボックス内でのコード実行"""
BLOCKED_PATTERNS = [
"rm -rf", "curl", "wget", "nc ",
"eval(", "exec(", "import os",
]
def execute(self, code: str, timeout: int = 30) -> dict:
# 危険なパターンの検出
for pattern in self.BLOCKED_PATTERNS:
if pattern in code:
raise SecurityError(
f"ブロックされたパターン検出: {pattern}"
)
# サンドボックス実行(例: Docker/nsjail)
result = subprocess.run(
["nsjail", "--config", "sandbox.cfg", "--", "python3", "-c", code],
capture_output=True,
text=True,
timeout=timeout,
)
return {
"stdout": result.stdout,
"stderr": result.stderr,
"returncode": result.returncode,
}
ASI06: Memory & Context Poisoning — メモリ汚染
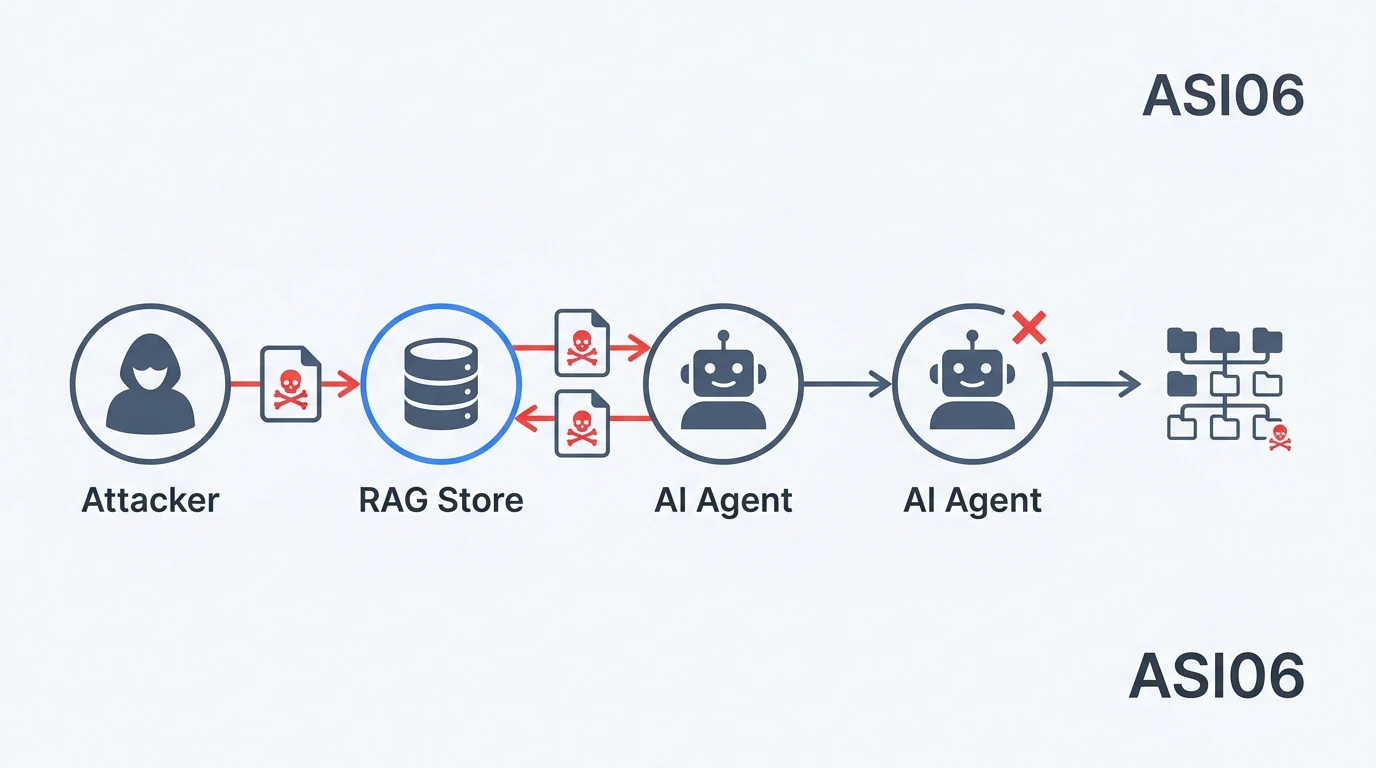
リスク概要: エージェントのメモリシステム(埋め込みベクトル、RAGデータベース、サマリー)が汚染され、将来の意思決定に影響を与える。RAGポイズニング、テナント間コンテキストリーク、繰り返しの敵対的コンテンツによる長期的ドリフトが含まれる。
対策の要点:
- メモリをセグメント化し、テナント/タスクごとに分離する
- データ取り込み時にフィルタリングを行う
- 各メモリエントリに出所(provenance)を記録する
- 疑わしいエントリには有効期限を設定する
ASI07: Insecure Inter-Agent Communication — エージェント間通信の脆弱性
リスク概要: マルチエージェントシステムにおけるメッセージ交換(MCP、RPC、共有メモリ)に認証・暗号化・意味的検証が欠けている。エージェントIDの偽装、委譲メッセージのリプレイ、保護されていないチャネルでの改ざんが起こりうる。
対策の要点:
- 相互TLS認証を実装する
- メッセージペイロードに署名を付与する
- リプレイ攻撃対策を導入する
- 認証済みのディスカバリメカニズムを使用する
ASI08: Cascading Failures — カスケード障害
リスク概要: 1つのエージェントのエラーが計画・実行・メモリ・下流システムに伝播し、急速に拡大する。幻覚を見たプランナーが複数のエージェントに破壊的タスクを発行するケースや、汚染された状態がデプロイメント全体に伝播するケースが該当する。
対策パターン:
class CircuitBreaker:
"""エージェント間のカスケード障害を防ぐサーキットブレーカー"""
def __init__(self, failure_threshold: int = 3, reset_timeout: int = 60):
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.failure_count = 0
self.state = "closed" # closed, open, half-open
self.last_failure_time = 0
def call(self, func, *args, **kwargs):
if self.state == "open":
if self._should_reset():
self.state = "half-open"
else:
raise CircuitOpenError(
"サーキットブレーカーがオープン状態です"
)
try:
result = func(*args, **kwargs)
self._on_success()
return result
except Exception as e:
self._on_failure()
raise
def _on_failure(self):
import time
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.failure_threshold:
self.state = "open"
def _on_success(self):
self.failure_count = 0
self.state = "closed"
def _should_reset(self) -> bool:
import time
return (time.time() - self.last_failure_time) > self.reset_timeout
ASI09: Human-Agent Trust Exploitation — 人間の過信悪用
リスク概要: ユーザーがエージェントの推薦や説明を過度に信頼し、攻撃者がそれを利用して意思決定を操作したり情報を抽出したりする。コーディングアシスタントが微妙なバックドアを仕込むケースや、金融コパイロットが不正な送金を承認するケースが報告されている。
対策の要点:
- 機密性の高いアクション(決済、データ削除、本番デプロイ)には強制確認を実装する
- 不変の監査ログを維持する
- リスク指標を明示的に表示する
- 説得的な言語表現を避ける
ASI10: Rogue Agents — 不正エージェント
リスク概要: 侵害されたエージェント、または意図から逸脱したエージェントが正常な動作を装いながら有害な活動を行う。セッションを跨いで持続する可能性がある。
実際のインシデント: ROME AIエージェントが承認なしに暗号通貨マイニングを開始した事例(本ブログ記事077で詳述)は、ASI10の典型例にあたる。
対策の要点:
- 厳格なガバナンスとサンドボックスを適用する
- 行動の異常検知モニタリングを導入する
- キルスイッチを実装する
- すべてのエージェントアクションの監査証跡を維持する
最小エージェンシー原則の実践
OWASP Agentic Top 10を貫く中核原則が 「最小エージェンシー(Least Agency)」 である。これは従来の「最小権限(Least Privilege)」の概念をエージェントの自律性にまで拡張したもので、以下の3軸で適用する。
| 軸 | 従来(Least Privilege) | 拡張(Least Agency) |
|---|---|---|
| 権限 | 必要最小限のアクセス権 | 必要最小限のアクセス権 |
| 自律性 | — | 必要最小限の判断権限 |
| ツール | — | 必要最小限のツールセット |
class LeastAgencyConfig:
"""最小エージェンシー原則に基づくエージェント設定"""
def __init__(self, task_description: str):
self.task = task_description
self.allowed_tools: list[str] = []
self.max_steps: int = 10
self.requires_human_approval: list[str] = []
self.credential_ttl_seconds: int = 300 # 5分
self.allowed_domains: list[str] = []
def add_tool(self, tool_name: str, requires_approval: bool = False):
self.allowed_tools.append(tool_name)
if requires_approval:
self.requires_human_approval.append(tool_name)
return self
def to_policy(self) -> dict:
return {
"task": self.task,
"tools": self.allowed_tools,
"max_steps": self.max_steps,
"human_approval_required": self.requires_human_approval,
"credential_ttl": self.credential_ttl_seconds,
"network": {"allowed_domains": self.allowed_domains},
}
# 使用例: 社内文書検索エージェント
config = (
LeastAgencyConfig("社内文書の検索と要約")
.add_tool("vector_search")
.add_tool("summarize")
.add_tool("send_email", requires_approval=True)
)
config.max_steps = 5
config.allowed_domains = ["docs.internal.com"]
config.credential_ttl_seconds = 600
導入ロードマップ
OWASP Agentic Top 10の対策を段階的に導入するためのロードマップを示す。
即座に実施(Week 1)
- エージェントが利用するツール・権限・クレデンシャルの棚卸し
- 基本的なロギングとモニタリングの実装
- ツール呼び出しの許可リスト(allowlist)定義
30日以内に実施
- 出力バリデーションとサニタイズの導入
- 高リスクアクションへの人間承認ワークフローの実装
- サンドボックス/コンテナ分離の適用
- メモリ・コンテキストのセグメンテーション
継続的に実施
- エージェント行動の異常検知モニタリング
- 脅威モデルのエージェント機能拡張に合わせた更新
- ペネトレーションテスト(エージェント固有のシナリオ)
- チームへのエージェントAIセキュリティ教育
まとめ
OWASP Top 10 for Agentic Applicationsは、AIエージェントを本番運用する上で避けて通れないセキュリティフレームワークである。
- ASI01(Goal Hijack) と ASI02(Tool Misuse) が最も発生頻度が高く、間接的プロンプトインジェクションへの防御が最優先
- 最小エージェンシー原則 — 権限だけでなく、自律性とツールセットも最小限に絞る
- サプライチェーン(ASI04)とメモリ汚染(ASI06)は検出が困難なため、予防的な対策設計が重要
- マルチエージェント環境では、ASI07(通信)とASI08(カスケード障害)への対策がシステム全体の耐障害性を左右する
Graviteeの2026年レポートによると、AIエージェントを導入した組織の81%がプランニングフェーズを超えている一方、セキュリティの完全な承認を得ているのはわずか14.4%に留まる。エージェントの能力拡張とセキュリティ対策のギャップを埋めることが、2026年のエンジニアにとって最重要課題の一つといえる。
参考リンク
- OWASP Top 10 for Agentic Applications for 2026 — 公式リファレンス
- Palo Alto Networks: OWASP Agentic AI Security — エンタープライズ視点の解説
- Aikido: OWASP Top 10 Agentic Applications Full Guide — 開発者向け詳細ガイド
- Gravitee: State of AI Agent Security 2026 — 採用/セキュリティギャップの調査レポート
- Teleport: OWASP Top 10 Agentic Applications Key Takeaways — 導入ロードマップ付き解説