はじめに
VOICEVOXを使った音声合成を、エディターを使わずにHTTPリクエストを用いて行うための手引書です。
以下の章立てで解説をしていきます。
- VOICEVOXのHTTPサーバー機能について
- サーバーに投げるクエリの内容とその投げ方
- wavファイルの保存の仕方
- (おまけ) VOICEVOXエンジンAPIドキュメントの読み方とAPIの使い方
- (おまけ)エディターを起動せずにエンジンを起動する方法
- (おまけ)HTTPリクエストを使わずに音声を合成するVOICEVOX COREの紹介
- 音声合成のPythonサンプルコード
1. VOICEVOXのHTTPサーバー機能について
VOICEVOXにはGUIを使う他にも音声を合成する方法があり、その1つがHTTPリクエストを使用する方法です。
VOICEVOXは大まかに分割するとエディターとエンジンとコアという3つのモジュールが組み合わさってできています。エディターはVOICEVOXアプリケーションのGUI部分、エンジンはHTTPサーバー(音声合成のリクエストなどを受け取る)部分、コアは実際に音声を合成する部分となっています。通常のVOICEVOXアプリケーションを利用の際はエディターに入力することでエディターがエンジンにHTTPリクエストを送り、エンジンがコアを使って音声を合成するという流れになっています。

つまり、エンジンにHTTPリクエストを送ることができればエディターを使わなくても音声の合成が可能となるわけです。今回はPythonを例に挙げて説明しますが、他言語でも同等の機能を用いれば音声合成をすることが可能です。
2. サーバーに投げるクエリについて
続いて実際にVOICEVOXエンジンにどのようなクエリを投げればよいかを説明します。初めに、音声を合成するためのクエリに必要なjsonファイルをVOICEVOXエンジンのドキュメントにあるコード例からお借りして示します。先に言っておきますが、このようなクエリを実際に自作する必要はないので安心してください。
{
"accent_phrases": [
{
"moras": [
{
"text": "string",
"consonant": "string",
"consonant_length": 0,
"vowel": "string",
"vowel_length": 0,
"pitch": 0
}
],
"accent": 0,
"pause_mora": {
"text": "string",
"consonant": "string",
"consonant_length": 0,
"vowel": "string",
"vowel_length": 0,
"pitch": 0
},
"is_interrogative": false
}
],
"speedScale": 0,
"pitchScale": 0,
"intonationScale": 0,
"volumeScale": 0,
"prePhonemeLength": 0,
"postPhonemeLength": 0,
"outputSamplingRate": 0,
"outputStereo": true,
"kana": "string"
}
このようなjsonファイルを用いてVOICEVOXエンジンにクエリを投げることで音声データを得ることができますが、これを全て自分で作成しようとすると少し面倒です。しかし、VOICEVOXエンジンには、このjsonファイルを用意するための機能が用意されており、そのためのクエリは以下のような簡単なものになっています。
import requests
url="http://localhost:50021/audio_query" # 50021はデフォルトポートなので、変更した場合は変える
params={"text": "ここに喋らせたいテキスト", "speaker": 3} # 3はずんだもんのノーマルスタイル
timeout = 15 # timeoutは環境によって適切なものを設定する
json_synthesis = requests.post(url, params=params, timeout=timeout)
requestsライブラリは標準ライブラリではないので、未インストールの場合はpip install requestsを行ってください。
このコードを実行することで、実際に合成音声に必要なjsonファイル (先ほど例に挙げたようなもの) がjson_synthesisに格納されます。こちらの方が扱いやすく簡単なため、実際に音声合成を行う際はこちらの簡単なクエリをVOICEVOXエンジンに投げることで音声合成用のjsonファイルを手に入れます。speakerの値はここに書かれてあるのを参照してください。
※2025/09/15追記
speakerのリストURLがリポジトリ更新の際に変わってしまうようです.
VOICEVOXを起動してhttp://localhost:50021/speakers にアクセスして確認するようにしてください.
初期状態だと見づらいと思いますが,左上辺りにあるプリティ プリント(Edgeなら整形出力)をクリックすることで見やすくなります.
そしてここで受け取った音声合成用のjsonファイルを以下のようにそのままVOICEVOXエンジンに投げることで音声データを得ることができます。
params = {"speaker": 3} # paramsは先ほどと同じものを流用しても良い
response = requests.post(
"http://localhost:50021/synthesis",
params=params,
json=json_synthesis.json()
)
3. wavファイルの保存の仕方
先ほどのクエリを送信した際の応答を格納したresponseから、wavデータを取り出し保存する方法を説明します。
まずはresponseから生成されたwavデータを取り出します。responseからボディデータ(今回は音声データ)を抜き出す方法は2つ用意されており、1つはresponse.textのようにテキストデータとして抜き出す方法、もう1つはresponse.contentのようにバイナリデータとして抜き出す方法です。これは実際に返されたデータに合わせる必要があり、VOICEVOXエンジンではバイナリデータとして返されるので今回はcontentを使用します。そして、そのバイナリ状態の音声データを保存することでwavファイルにすることができます。保存方法はいくつかありますが、以下に具体例を挙げます。
from pathlib import Path
wav = response.content
path = "sample.wav" # 保存場所
out = Path(path)
out.write_bytes(wav)
これで、sample.wavという名前で音声が保存されます。
4. (おまけ) VOICEVOXエンジンAPIドキュメントの読み方
音声の合成自体は3章までの内容でできますが、辞書登録などの他のAPI機能を使おうと思ったとき、そのための解説を探すのは大変だと思います。そこで、VOICEVOXエンジンを利用する上でのAPIドキュメントの読み方と使い方を解説するので参考にしてください。
まず、APIドキュメントへのアクセス方法です。APIドキュメントは、VOICEVOXを起動した状態でhttp://localhost:50021/docs にアクセスすると閲覧することができます。WEB検索しても出てきますが個人的にはこちらの方が読みやすいかと思います。アクセスすると以下のようなページが開きます。各機能の簡単な説明がそれぞれ書かれており、クリックすると詳細が展開されます。

まずこの画面について説明していきます。それぞれの機能に左側に、POST、GET、PUT、DELETEのいずれかが書かれていると思います。これは、この機能を使うときに使用するHTTPリクエストの種類を表しています。例えば、一番上の/audio_queryのクエリを作成するためにはPOSTリクエストをすればいいということが分かります。2章に戻って音声合成のクエリを作成する部分のコードを見るとrequests.postとなっていることが分かると思います。Pythonのrequestsライブラリを使う場合は、このように簡単にリクエストの種類を使い分けることができます。例えばputを使いたければrequests.putに変更するだけでパラメータの指定方法などは同じです。
続いて、URLの指定方法について説明します。URLについては簡単で、POSTやGETのすぐ右に書かれているスラッシュから始まる文字列をhttp://localhost:50021の後ろにつなげるだけです。例えば、/audio_queryであれば、http://localhost:50021/audio_queryとなります。
では、パラメータ指定の方法についても解説します。一番上の/audio_queryを展開してみると、ParametersとResponsesというのがあると思います。Parametersがparamsに指定するもので、Responsesが応答です。赤字でrequiredと付いているものが必ず必要なパラメータです。/audio_queryであれば、textとspeakerというパラメータの指定が必ず必要であることが分かります。それぞれのパラメータの真下に書かれているstringやintegerはそのパラメータに渡すデータの種類です。stringであればテキストデータを、integerであれば整数データを渡します。そのため、/audio_queryのパラメータは以下のようになります。
params={"text": "喋らせたいテキスト", "speaker": 3}
基本的には他のクエリも同様に作成します。そしてこの形式でクエリを投げると、成功すればCode 200と書かれている部分のデータが返ってきます。失敗すればCode 422と書かれている部分のデータが返ってきます。今回であれば、どちらの場合でもjsonデータが返ってくることが分かります。この流れは、基本的には他のVOICEVOX APIも同じようになっています。ただし、一部違っているものもあります。例えば、2章でも使った/synthesisを見てみると、Request bodyというものがあります。これはparamsとは別で指定してあげる必要があるものです。このようなbodyデータはdataやjsonとして指定するのですが、細かい説明は省きます。VOICEVOXでは投げるデータは全てjsonデータなので2章の「音声合成のためのquery」コードにあるようにjsonで指定すればいいです。つまり、2章の流れをもう一度説明すると、/audio_queryにtextとspeakerというparamsを指定してクエリを投げるとjsonが返ってくる、そして/synthesisにspeakerというparamsと先ほど得たjsonを格納した変数をjsonに指定してクエリを投げるとwavデータが返ってくるということです。このwavがどういうデータかというのは下記画像の赤下線部分のSchemaをクリックして内容を見るとstring binaryとなっており、バイナリテキストであることが分かります。
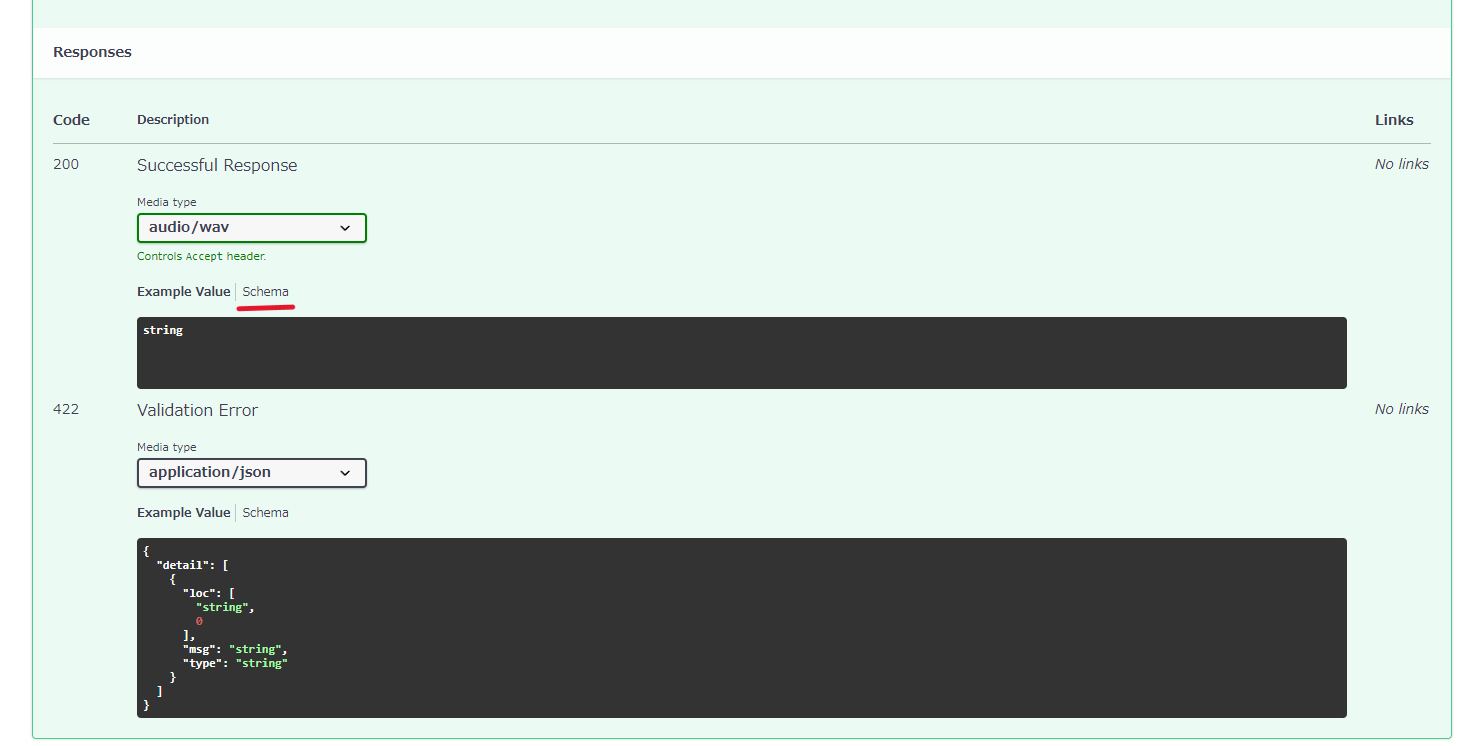
これでAPIドキュメントの読み方とおおよそのAPIの使い方が分かったかと思います。
5. (おまけ)エディターを起動せずにエンジンを起動する方法
ここまでVOICEVOXエンジンを使って音声を合成する方法を説明してきましたが、現状ではVOICEVOXアプリケーションを起動した状態でしか実行できません。しかし、エディターは不要でプログラム上で完結したいと考える人もいると思います。その場合はエンジンとコアのみを利用することもでき、そのためにはDockerというものを利用する必要があります。Dockerの詳しい使い方はそれだけで記事が書けるぐらいの情報量なので省きますが、VOICEVOXエンジンのGitHubリポジトリにDockerイメージとその実行コマンドがあるのでそれを利用してください。
6. (おまけ)HTTPリクエストを使わずにVOICEVOX COREを使って音声を合成する方法
この章はあくまで参考程度の情報ではあるのですが、HTTPリクエストではなくコアに直接アクセスして音声を合成する方法を紹介します。VOICEVOX コアは音声合成を実行するコアの部分であり、実行するためにはOpenJtalk辞書を自分でダウンロードし、読み込んでSynthesizerを初期化するなど、エンジンがやっていたことを自分でやらなければならず使用難易度が高いです。ですが完全に組み込んでしまえるのでHTTPサーバー分のリソースを削減できるというメリットはあります。ここにVOICEVOX コア ユーザーガイドへのリンクを貼っておくので興味のある人は読んでみてください。
7. サンプルコード
音声合成のためのサンプルコードです。VOICEVOXアプリケーションまたはVOICEVOXエンジンが起動している状態で実行すると、ずんだもんのノーマルスタイルで「これはサンプルボイスです」という音声が生成されsample.wavとしてカレントディレクトリ内に保存されます。
import requests
from pathlib import Path
url = "http://localhost:50021/audio_query"
params = {"text": "これはサンプルボイスです", "speaker": 3} # ずんだもん ノーマルスタイル
timeout = 15
query_synthesis = requests.post(url, params=params, timeout=timeout)
# params = {"speaker": 3}
response = requests.post(
"http://localhost:50021/synthesis",
params=params,
json=query_synthesis.json(),
)
wav = response.content
path = "sample.wav" # 保存場所
out = Path(path)
out.write_bytes(wav)
(2章でも貼りましたが再掲)
requestsライブラリは標準ライブラリではないので、未インストールの場合はpip install requestsを行ってください。