この記事は?
新年に入ってからJuliaが少しバズっているらしいとの噂があったので、Qiitaの投稿数の時系列プロットをしてみて確かめた記事です。
Juliaがバズっている?
ちょっと前から個人的興味でJuliaを触っていたのですが、そのときいろいろ参考にさせていただいた投稿をしているかたがこのような発言をしていたので気になりました。
Juliaのブーム,どうせ1日か2日くらいで終わるだろうと思ったが,1週間経つけど未だにチュートリアルへのアクセス数がが落ちない(むしろちょっと伸びてる)。https://t.co/fDUOlGIH99 pic.twitter.com/VWpARTbeyv
— (「・ω・)「ガオー Julia㌠ (@bicycle1885) 2018年1月9日
Qiitaでの投稿数を調べてみた
Juliaのタグが付いている投稿を調べてみました。その際にQiitaのAPIのPythonラッパーを使わせていただきました。
Qiita API
Qiita APIを使うのにちょっと詰まったので備忘録的に記録を残しておきます。
qiita_v2.pyはpipを使えるので
$ pip install qiita_v2
します。使い方はこちらを参考に、と書いてあったのでヒアドキュメントを見ながら使ってみました。
今回は'Julia'タグが入っている投稿を抽出したかったのでQiitaClient.list_tag_itemsメソッドを使います。
import matplotlib.pyplot as plt
from qiita_v2.client import QiitaClient
import datetime as dt
access_token = "**************************"
client = QiitaClient(access_token)
アクセストークンは今回は自分のアカウントの認証をしましたが、qiitaアカウントを持っていなくても、QiitaClient.create_access_token()で作れるようです。自分のアカウントでアクセストークンを作る場合は自分のQiitaページの設定→アプリケーション→個人用アクセストークンで作れます。
'Julia'タグがついた投稿が欲しかったので
request = client.list_tag_items('Julia')
json = request.to_json()
としたところ、帰ってきたjsonは20要素しかないようでした。Juliaタグがついた投稿は手動検索だと220くらいあったので何かおかしいです。
ラッパーの中身
仕方がないのでラッパーのソースを読んでみたところ、client.list_tag_items('Julia')は 'https://qiita.com/tags/Julia/items' を返すことになっていました。これだと、1ページ目にある項目しか引っ張ってこれないことになります。引数paramsにクエリパラメータを入れられるようだったので2ページ目以降はparams={'page': n}のようにしてページを指定することにしました。手作業で12ページあることを確かめたので
n_pages = 12
time_stamps = []
request = client.list_tag_items('Julia') # 1ページ目
json = request.to_json()
for i in range(len(json)):
time_stamps.append(json[i]['created_at'])
for page in range(2, n_pages+1):
request = client.list_tag_items('Julia', params={'page': page})
json = request.to_json()
for i in range(len(json)):
time_stamps.append(json[i]['created_at'])
としてタイムスタンプだけ抽出しました。同じ処理が二回書いてあったりしますがお気に召されぬよう・・・
タイムスタンプ処理
このままだとタイムスタンプはstr型のままなのでdatetime型に直します。time_stampsの要素は
print(time_stamps[0]) #=> 2018-01-08T21:12:45+09:00
のようになっているのでタイムゾーン情報をカットします(本当はこの処理いらない?)
time_stamps = list(map(lambda x: x.replace("T", " "), time_stamps))
time_stamps = list(map(lambda x: x.replace("+09:00", ""), time_stamps))
その後datetime型に直します。
time_stamps = list(map(lambda x: dt.datetime.strptime(x, "%Y-%m-%d %H:%M:%S")
これでmatplotlibに渡せるようになりました。
後はヒストグラムにでもしてみればいいでしょう。
plt.hist(time_stamps, bins=20)
plt.xlabel("Date")
plt.ylabel("Number of Posts")
plt.xticks([dt.date(2013, 1, 1), dt.date(2014, 1, 1), dt.date(2015, 1, 1),
dt.date(2016, 1, 1), dt.date(2017, 1, 1), dt.date(2018, 1, 1)])
plt.show()
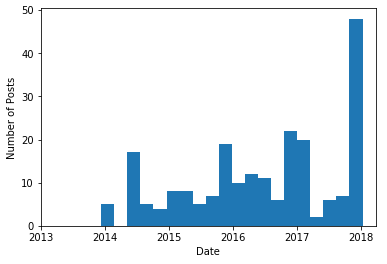
確かに最近爆発的に投稿が増えているみたいですね!