初めまして、武田雄也(@kagamikarasu)と申します。
「SOLD OUT 2 市場情報サイト」の開発などを行っております。
2020年8月頃から「市場情報サイト」の再開発を進めて9月にリプレース、
1ヶ月以上経過して落ち着いたので「市場情報サイト」について記事にしたいと思います。
SOLD OUT 2 とは?
mu様が運営している「オンラインお店ごっこ」です。
https://so2.mutoys.com/
チュートリアル
https://so2-docs.mutoys.com/common/tutorial.html
アイテムを消費して新しいアイテムを手に入れて、それを元に新しい商品を作ったり販売したりします。
NPC向けに売ったり、ユーザーに向けて売ったり、イベントに参加したり、プレイスタイルは人それぞれです。
SOLD OUT 2 市場情報サイトとは?
私(@kagamikarasu)が開発している市場情報サイトです。
https://market.kagamikarasu.net/
mu様の方でAPIが公開されているので、それを利用して開発しました。
商品毎の価格/在庫推移や店舗毎の在庫減少数などをグラフ/表形式で把握する事ができます。
エンドユーザーが出来る事は参照のみです。
なぜ再開発したのか?
自宅サーバー + Conoha(LB役割) + Java 1.8 + MySQL(後にMariaDB)で運用していたのですが、
開発が行いづらくなったので再開発をしました。
Javaのゴタゴタだったり、証明書の取得やデプロイが面倒だったり、
データベースの肥大化、自宅サーバー(ただのPC/UPS無し)を辞めたかったりしたかったので....
データベース肥大化との戦い
大きいテーブルでは10億レコード超えていました。
当初何も考えてなかったのでデータ量は考えていませんでした。
明らかに遅くなっているのを感じたので、インデックスや検索条件を見直したりしたのですが、
焼け石に水状態だったので、ストレージを変更してIOPSを稼ぐことで解決しました。
3年間でHDD→SSD→SSD(NVME)です。
NVMEとても速いです、甘えと言われたらそれまでですが、
ストレージ変更する際、移行が速すぎてコマンド打ち間違えたか?と疑うほどです。
移行目標
- クラウド環境
- 開発/デプロイが容易
- 落ちても勝手に復帰する様に
- 月額費用は抑える
ちょうどSAAの勉強をしていたのでAWSを利用することにしました。
一番大きな問題が4番目の月額費用は抑えるです。
何も考えずにRDS+EC2+ALBだと構成次第では、RDSでそれなりな金額になってしまうかと思います。
法人ならば何の事も無い金額ですが、個人(少なくとも私)ではとても辛いです('A'
利用したサービス
※以下に記載するものについては、用法用量を守ってお使いください。
- DynamoDB(オンデマンド)
- SQS(標準キュー)
- Lambda(Python+Pandas) + CloudWatchEvent
- ECS(EC2spot+ECR+ALB)
- S3(HIVE+json形式)
- Route53
- API Gateway
移行後構成図
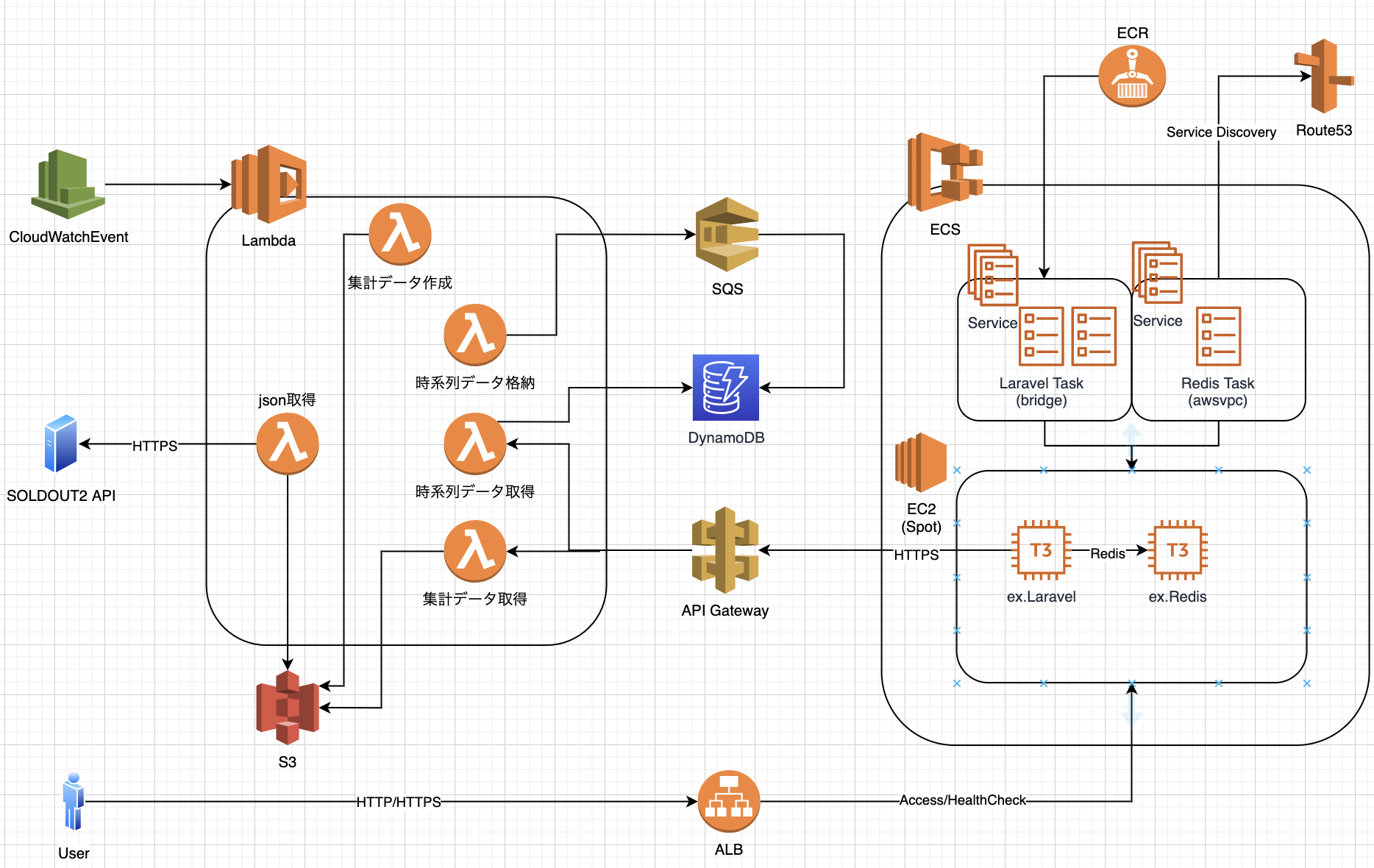
DynamoDB
RDS(MariaDB)に移行するのが最も楽ですが、数百GBのデータを移行して運用するとそれだけで運用費が詰みます。
数百GB移行と書きましたが、移行データは全てHIVE形式+JSON形式でS3に移します。
必要に応じて後述するS3→Lambda→SQS→DyanamoDBを行います。
DynamoDBの無料枠は記事記述時点で25GBの無料枠、オンデマンド25のWCU/RCU。
- 1WCUは1秒で最大1KBのデータを書き込み可能
- 1RCUは1秒で最大4KBのデータを読み込み可能
との事なので、1レコード辺りのデータは1KB内に抑えるのが望ましいです。
今回はテーブルを一つだけ使い5WCU/RCUを割り当てています。
市場情報サイトはアイテム単位で抽出する為、自ずとパーティションキーはitem_idになります。
時系列で持ちたいのでソートキーは登録日時のUNIX時間とします。
移行前のデータベース(MariaDB)では、10分間隔の店舗単位(集計前)でデータを持っていましたが、
移行後のデータベース(DyanmoDB)では、3時間間隔のアイテム単位(集計済)でデータを持ちます。
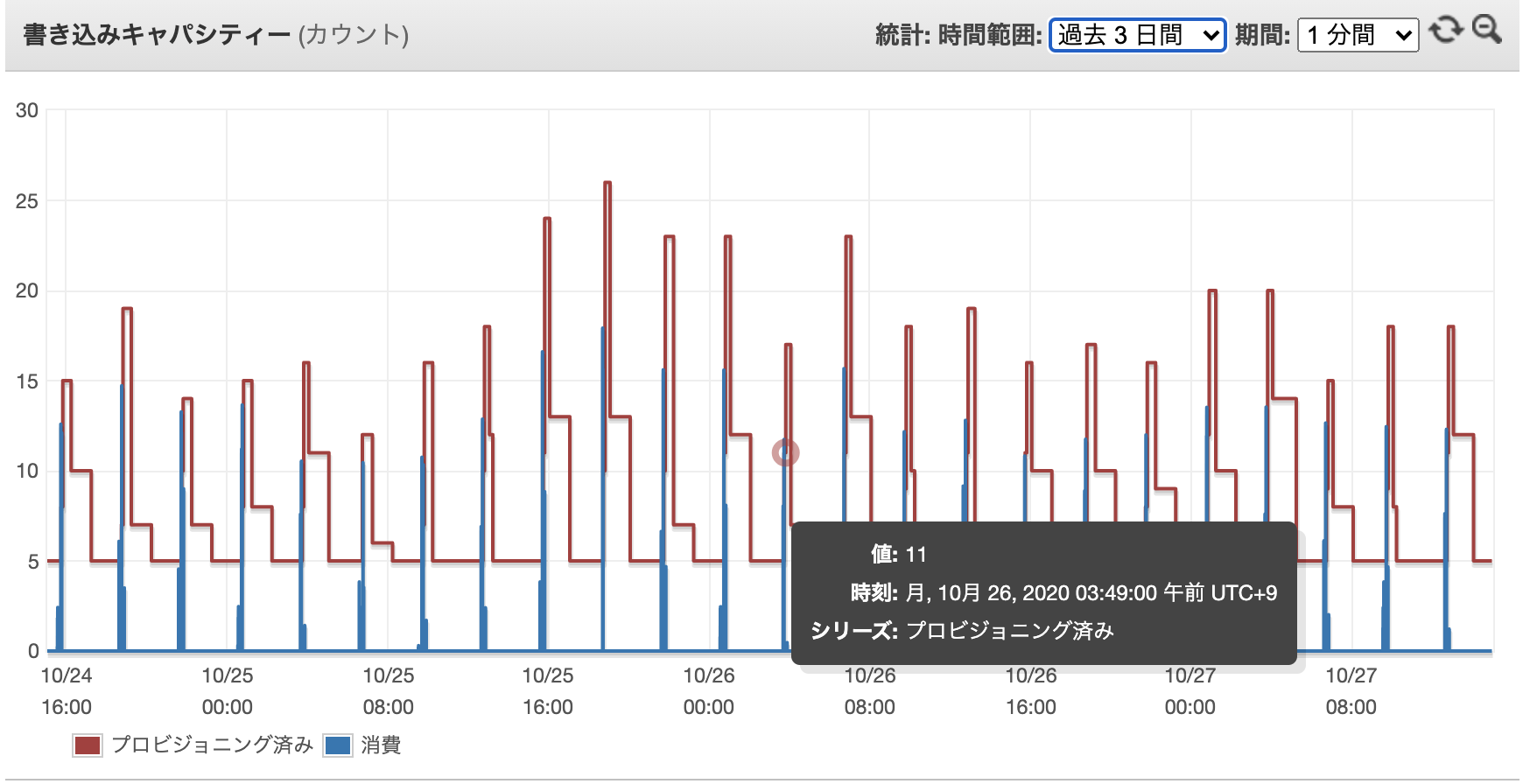
SQSも使っているので具体的な集計・格納手段は後述しますが、以下の図の様なWCU消費となります。
容量が25GBに収まっているうちはデータベースは無料で使い続ける事ができます。
SQS
次にSQSです。
キューイングという物は意識した事がありませんでしたがSAAを勉強しているうちに、これはとても良い物だと知りDynamoDBを組み合わせて使うことにしてみました。
SQSの無料枠は100万件のリクエストです。
最初よく分かっていなかったのですが、送受信で2リクエスト使うことになります。
現状2000アイテムで見積もっているので、100万リクエストで抑える為に3時間単位にしています。
2000 * 8 * 30 * 2 = 96万件
SQSなので多少足が出ても大丈夫ですが、出来るだけ無料枠で抑えたいので3時間単位です。
前述した通り、3時間毎に集計データをDynamoDBに格納しています。
アイテム単位で格納しますが、現状3時間毎に約2000アイテム格納する必要がありました。
もし1秒で2000アイテム格納するならば、1アイテム1KBとして2000WCU必要です。
月額$1000超えて破産してしまうので、今回はSQSとDynamoDBを組み合わせて書き込みタイミングをずらす様にします。
具体的にはLambda(集計)→SQS→Lambda(SQS抽出/DynamoDB格納)→DynamoDBとなります。
FIFOである必要はないので、標準キューを利用します。
最初SQSのLambdaトリガー便利と思っていたのですが、モニタリングしていると想定していない消費が発生しており、調べてみると以下のことが発生していました。
参考:https://encr.jp/blog/posts/20200326_morning/
微々たる物ですが、ちょっと気持ち悪い感じがしたのでLambdaトリガーではなく、CloudWatchEventとLambdaで自前でSQSから取ってくる様にしました。
SQSの受信数は以下の様になりました。
CloudWatchEventでは1分単位でキューを見る様にして、Lambda側でキューの取得制限を設けて出来るだけキャパシティーオーバーしない様にしています。

Lambda
取得・集計は全てCloudWatchEvent+Lambdaに任せています。
Lambdaはリクエスト数と実行時間です。
無料枠は100万件のリクエストと40万GB秒となっています。
少なくとも、私の使い方で無料枠を超える事はありませんでした。
(無料枠の1割ちょっと位)
執筆時点では以下の様な関数を作っています。
- マスタデータ取得(S3保存)
- 販売・注文データ取得(S3保存)
- 販売・注文データ集計(S3取得/保存・SQS)
- 人口データ取得(S3保存)
- 人口データ集計(S3取得/保存・SQS)
- API Gateway用レスポンス関数
- その他コンテンツ作成用関数
Python+Pandasを使っているので、集計周りが非常に楽です。
最初はforでゴリ押し出来ると思っていたのですがメモリで非常に辛くなったので、Pandasを利用しました。
Serverless Frameworkを利用しているので、デプロイも楽になりました。
やっている事はCloudFormationと同じかと思いますので、API Gatewayに関する記述もしています。
※Admin権限が必要ですが、仕組み上これは致し方ないと思います...
テスト・デプロイを繰り返していくと、バージョン管理している為か無駄が増えていきます。
「serverless-prune-plugin」を利用して自動削除すると良いかと思います。
Lambdaに利用量は以下になります。
関数によって割り当てているメモリ量は異なりますが、128MB〜512MBにしています。

CloudWatchEvent
バッチ処理(定期処理)に使用しました。
EC2+cronやdigdagなど色々あると思いますが、Lambdaが使えるのでCloudWatchEventと組み合わせます。
ある時バッチ動いていないなーと思ったら、GMTなんですよね...
言語設定を日本語にしているのでJSTだと油断していました...
ECS(EC2)
次にECSについてですが、これがとても強力です。
ECR+ECS+ALB+Route53の組み合わせです。
- ECR - dockerイメージの保持
- ECS(Service->Task) - dockerコンテナの実行
- ALB - ECSタスク(dockerコンテナ)をターゲット
- Route 53 - ECSのサービスディスカバリを用いてdockerコンテナ間通信
Fargateでは無くEC2を使っています。(安いので...)
ECSとALBにより1つのEC2インスタンスで複数のタスク->dockerコンテナを動かすことが出来ます。
これにより新しくインスタンスを更新や追加することなくデプロイする事ができます。(インスタンスのメモリ上限で無い限り)
EC2インスタンスそのものの存在が薄くなります、dockerで動かしているのでSSHで接続する事自体ありません。
またEC2はスポットインスタンスを利用しています。
これによりインスタンスタイプにもよりますが、オンデマンドインスタンスと比べて70%料金を削減する事ができました。
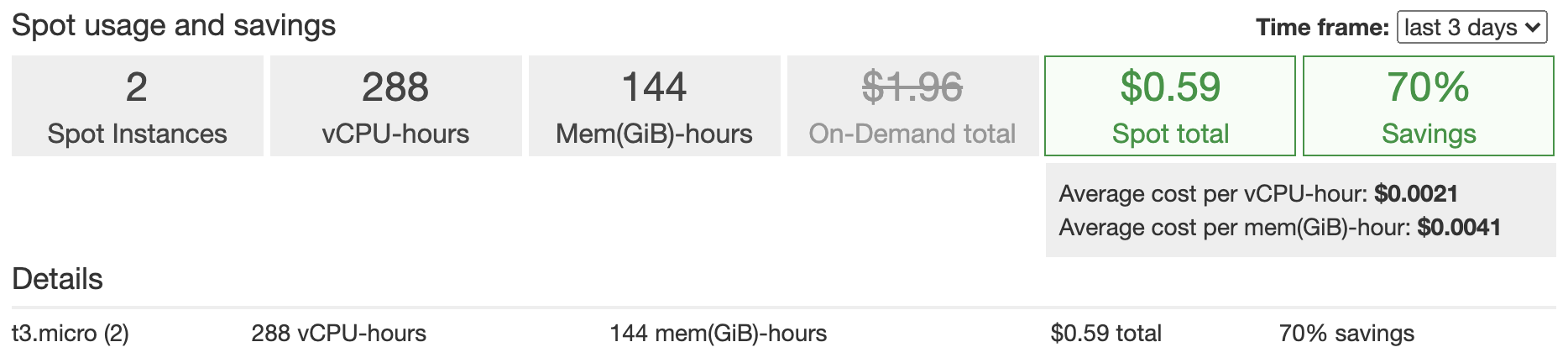
大幅に割引される代わりに、AWSからいつ中断されてもおかしく無い代物です。
もし落ちた場合、スポットフリートにより自動的に必要なインスタンスが補充され、ECSサービスにより必要なタスクが補充されます。
同時にALBによるヘルスチェックが働き、異常な物はターゲットから外され、正常な物はターゲットされるようになります。
今回はt3.microインスタンスを利用しましたので、1時間辺り約1円それが2台で1ヶ月動かすと1440円程になります。
スポットインスタンスを利用していますので、場合にもよりますが今回は70%引きとして432円となります。
ALB
先に述べた通り、ECSとの組み合わせの為に利用していますが、ACMによる証明書利用が可能です。
Let's Encryptに比べると非常に楽です、ポチポチボタン押すだけで終わるので。
ただ、アクセス数などにもよりますが恐らく2000円程掛かってしまいます。
単一のサービスだけで使うならば個人利用は少々高いですが、ホストベースルーディングが可能な為、
複数のサービスを運用しているならば、ECSやACM、ルーティング、マネージドも考慮すると高い投資では無いと思います。
また、Redisにてセッションを管理している為、スティッキーセッションはオフにしています。
オンにしていると突如EC2が落ちた際に、落ちたEC2の方にアクセスが行ってしまう為です。
Route 53
ドメイン周りになります。
ちなみにドメインに関しては昨年位に「お名前.com」から「Route 53」に移管しました。
基本的に毎月50円位掛かっていました。
それはさておき、ECSのサービスディスカバリという機能があります。
ECSにてコンテナ間で通信を実現するのは大変です。
(同一サーバの別コンテナは繋がるが、別サーバ同士やネットワークモードなどなど...)
サービスディスカバリではECSで登録したサービスを内部ホストゾーンに自動登録/更新する事ができます。
ネットワークモードがawsvpcであればAレコードの登録が可能です。
新しいホストゾーンが作成されるので新たに50円程掛かってしまいますが、自動でサービスと内部ドメインを紐付けてくれるのは非常に助かります。
サービス(タスク)が落ちてもECSが自動的に復帰、紐付けまで行ってくれます。
今回の環境ではRedis(ElastiCacheではない)をECS内で立てている関係上、
アプリケーション側(別コンテナ)と通信する為に利用しています。
ElastiCache使えると良いのですが、コストが掛かるので....
S3
S3では保存量、GET/PUTに対して課金が発生します。
今回のシステムではS3にマスタデータ、集計前/後データを格納しています。
PUTはシステム側でしか出来ないので出来るだけ発生していない様にしていますが、GETはユーザのタイミングによってしまう為、Redisを用いてEC2内でキャッシュしてGETが出来るだけ発生していない様にしています。

クローラー対策
通信にもお金が掛かります、微々たる物ですがサービスを組み合わせている程、影響が大きくなってくると思います。
特にALBでは新規接続等に対して課金があるので、無駄は通信は行いたくありません。
robots.txtで対応できる物はいいですが、ACLでインバウンド接続を切るのも手かと思います。
約2ヶ月経って
スポットインスタンスを使ったので不安定になるかなーと思っていたのですが、一度も落ちた形跡が無いのが驚きでした。
リプレイスから数週間は新機能開発をしていたのですが、以前の環境と比べて飛躍的に開発が行いやすいです。
特にDockerでの開発なので構築時点は多少大変ですが、以降はビルドしてタスクを更新するだけです。
Lambda側のPandasも非常に扱いやすく、一度仕組みが出来ると何でも出来そうな気がしてきます。
→基本的にはLambdaでデータ生成、LaravelでRedisに格納してユーザーに結果を返却。
無料枠の使用量は月末前で以下の様になりました。
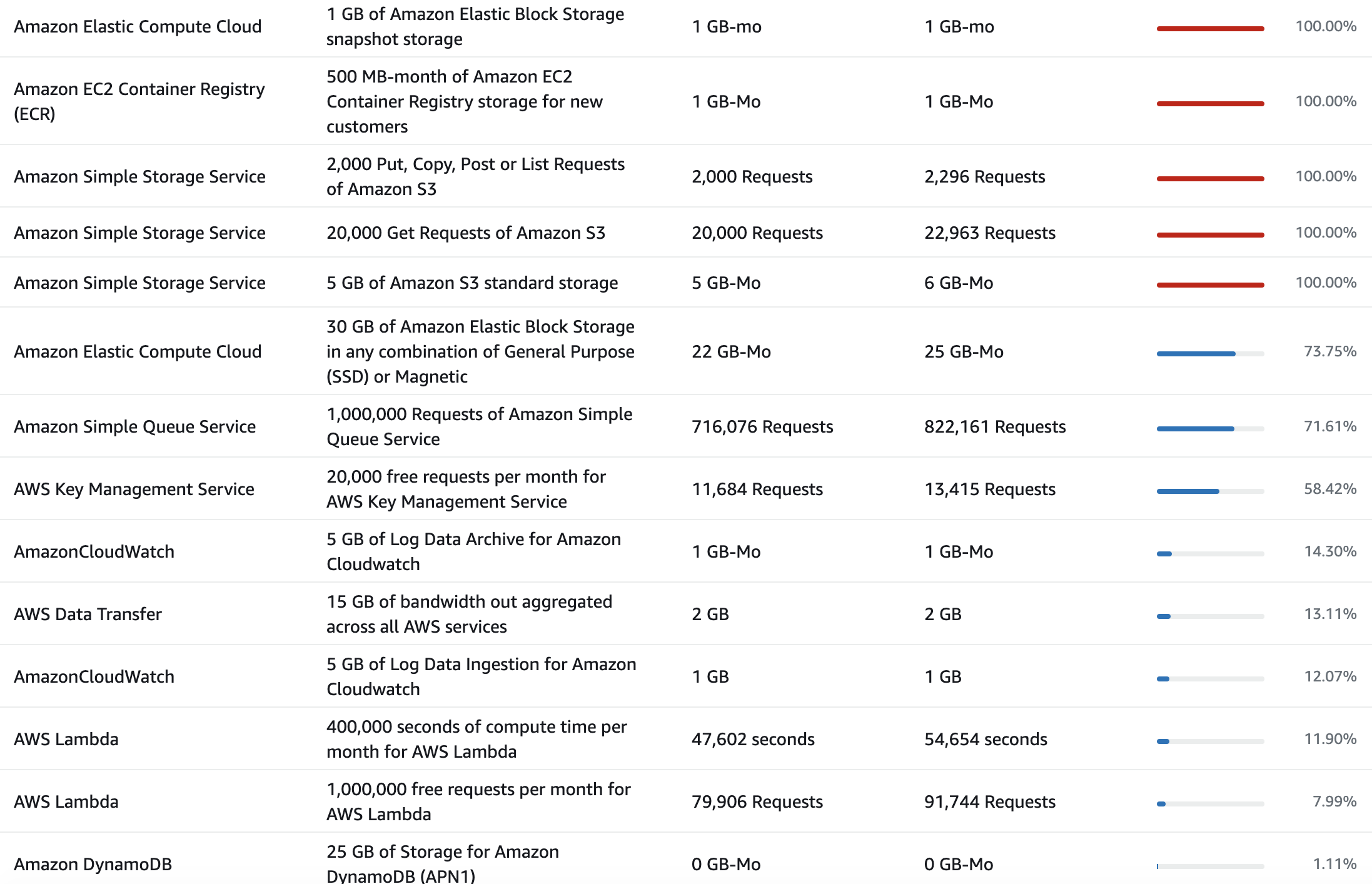
アカウント作成から1年以上経っているので、1年間の無料枠が無いと思っていたのですが、
free tierとなっており請求が発生していませんでした。
アカウント作成ではなく、初請求から1年とかだったりするのでしょうかね...?
今後の展望
今回は取り敢えず移行したという感じです。
過去データはS3に全て保存してあるので、必要があればDynamoDBにいつでも反映できる状態になっています。
(過去データはあまり必要とされていない気がする....)
設計周りばかりやっていたので、運用周りが疎かになっています。
例えばデプロイ作業は手動になっています。
追々、CircleCIとかCodeDeploy周りも組み合わせてみたいと思っていますが、一人で開発していると別にそんなに困っていないとかとか思ってしまいます。
他にも監視周りも疎かです。
外形監視はやっておらず、SNSの設定も行っておりません。
最近気付いたのですが、botが大量アクセスしておりLCUを地味に消費していたのでrobots.txtとACLを設定しました。
ログはCloudWatchに出力しているので、気軽に解析できる様な環境は整えたいです。
数値データを取り扱っているので、機械学習してみるのも面白いかと思っています。
実は少し触ったのですが(重回帰)、パラメータが多く手持ちのPCでは悲鳴を上げてしまいました('A'
Lambdaだと色々と厳しいから、インスタンスを立てて解析する感じになるのでしょうかね。
最後に
一つ一つの内容は薄い物になってしまいましたが、もし機会があれば掘り下げて記事にしたいと思っています。
ここまで読んで頂きありがとうございました!