0.ポイント
1.特許権の権利範囲は請求項として、言葉で表される。
2.請求項は、記載が厳密であるだけに、文章の構造が複雑になることも多く、読み手によっては、誤解が生じる可能性もある。
3.発明者や弁理士、審査官の間で、認識の齟齬が生じないよう、請求項を見える化してみた。
(下の絵は、見える化の一部分です。)
1.経緯
知的財産権、なかでも特許権は、新しい時代を切り開く、強力な武器だ。その特許権の効力は、「請求の範囲」に記載された文章(請求項)によって定義される。
当然のことながら、請求項の一つ一つについて、特許権の構成要素が「必要」「十分」になるよう、厳密な書き方がされているため、複雑な文章構造になることも多い。
例えば、トヨタが自動運転に関して出願した特許(「自律型車両向けの交通状況認知」、JP2018198422A)の「請求の範囲」は以下の通りとなっている(抜粋)。
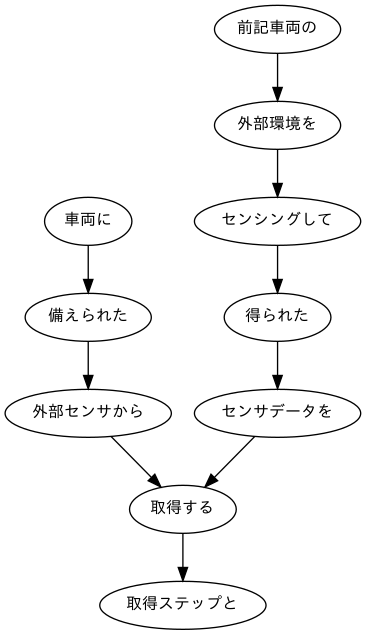
車両に備えられた外部センサから、前記車両の外部環境をセンシングして得られたセンサデータを取得する取得ステップと、
前記センサデータを分析して、前記車両の外部における交通状況を識別する識別ステップと、
前記交通状況に関する情報を視覚的に描写する視覚フィードバックを表示させるためのグラフィックデータを生成する生成ステップと、
インタフェース装置に前記視覚フィードバックを表示させるために、前記グラフィックデータを前記インタフェース装置に送信する送信ステップと、
を含む、方法。
何を言っているか、お分かりになるだろうか。最初に読んだとき、正直、僕には、何が何だか、よく分からなかった(笑)。
読み直してみて、分かったことは、①方法に関する特許であること、②その方法が4つのステップを含むこと、の2点だ。一つ一つのステップの詳細は、正直、読んでいても、「すぐには、頭に入らない」という感じ。もちろん、悪いのは発明ではなく、僕の頭の方だ(笑)。
そういう状況を踏まえて、請求項を見える化できないか、試しにやってみた。
2.準備
さて、見える化だが、AIの定番言語と言って良いPythonを使う。今回は、文章の構造を係り受けとして考えて、Cabochaを利用する。
まず、準備だが、MeCab、CRF++、Cabocha の3つが必要。インストール方法は、とっても良い記事があるので、参考に見てみて下さい。僕も参考にさせて頂きました。サイト作成者の方には、この場を借りて、御礼を申し上げます。
Google Colab で MeCab と CaboCha を使う最強の方法
▲心くじけず言語処理100本ノック==5章下準備==
形態素解析のMeCabが正しくインストールできれば、以下の通りとなる。
import MeCab
tagger = MeCab.Tagger()
print(tagger.parse("隣の客はよく柿食う客だ"))
隣 トナリ トナリ 隣り 名詞-普通名詞-一般 0
の ノ ノ の 助詞-格助詞
客 キャク キャク 客 名詞-普通名詞-一般 0
は ワ ハ は 助詞-係助詞
よく ヨク ヨク 良く 副詞 1
柿 カキ カキ 柿 名詞-普通名詞-一般 0
食う クー クウ 食う 動詞-一般 五段-ワア行 連体形-一般 1
客 キャク キャク 客 名詞-普通名詞-一般 0
だ ダ ダ だ 助動詞 助動詞-ダ 終止形-一般
EOS
また、係り受け分析に必要なCRF++、Cabochaが正しくインストールされれば、以下の通りとなる。
import CaboCha
cp = CaboCha.Parser()
print(cp.parseToString("隣の客はよく柿食う客だ"))
隣の-D
客は-------D
よく---D |
柿-D |
食う-D
客だ
EOS
3.データの加工
さて、インストールが出来たところで、データを加工しよう。
まずは、用意したテキストデータを読み込み、各行ごとに形態素解析を行う。それから、Cabochaを使って、係り受け分析をする。
file_path = 'JP2018198422A.txt'
# 空のリストの用意
c_list = []
c = CaboCha.Parser()
# テキストデータの読み込み
with open(file_path) as f:
text_list = f.read()
#改行で切り分けて各行ごとに形態素解析を行います。
for i in text_list.split('\n'):
cabo = c.parse(i)
#用意したc_listに格納します。
c_list.append(cabo.toString(CaboCha.FORMAT_LATTICE))
結果をファイルに保存し、データの加工は終了。
# 書き出し
path_w = 'JP2018198422A.txt.cabocha'
# リスト型を書き込むときはwritelines()
with open(path_w, mode='w') as f:
f.writelines(c_list)
4.見える化に挑戦
それでは、いよいよ、見える化に挑戦する。
まずは、係り受け分析の結果を読み込む。
# 係り受け分析の結果データの読み込み
path = 'JP2018198422A.txt.cabocha'
import re
with open(path, encoding='utf-8') as f:
_data = f.read().split('\n')
次に、形態素を表すクラスMorphを実装する。このクラスは表層形(surface)、基本形(base)、品詞(pos)、品詞細分類1(pos1)をメンバ変数に持つ。
class Morph:
def __init__(self, word):
self.surface = word[0]
self.base = word[7]
self.pos = word[1]
self.pos1 = word[2]
# 一文ずつにまとめたリスト
sent = []
# sentに入れるリストの仮置き場
temp = []
for line in _data[:-1]:
#リスト内の各要素を分割します。
#集合[]で「\t」と「,」と「 (スペース)」を指定します。
text = re.split("[\t, ]", line)
#「EOS」を目印に1文ごとにリストにまとめます。
if text[0] == 'EOS':
sent.append(temp)
#次の文に使用するために空にします。
temp = []
#係り受け解析の行は今回は不要なのでcontinue
elif text[0] == '*':
continue
#形態素解析の結果から指定の要素をMorphオブジェクトのリストとしてtempに格納します。
else:
morph = Morph(text)
temp.append(morph)
それから、文節を表すクラスChunkを実装する。このクラスは形態素(Morphオブジェクト)のリスト(morphs)、係り先文節インデックス番号(dst)、係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つ。
# クラスChunk
class Chunk:
def __init__(self, idx, dst):
self.idx = idx #文節番号
self.morphs = [] #形態素(Morphオブジェクト)のリスト
self.dst = dst #係り先文節インデックス番号
self.srcs = [] #係り元文節インデックス番号のリスト
import re
# 1文ごとのリスト
s_list = []
# Chunkオブジェクト
sent = []
# 形態素解析結果のMorphオブジェクトリスト
temp = []
chunk = None
for line in _data[:-1]:
#集合[]で「\t」と「,」と「 (スペース)」を区切りを指定します。
text = re.split("[\t, ]", line)
#係り受け解析の行の処理
if text[0] == '*':
idx = int(text[1])
dst = int(re.search(r'(.*?)D', text[2]).group(1))
#Chunkオブジェクトへ
chunk = Chunk(idx, dst)
sent.append(chunk)
#EOSを目印に文ごとにリスト化
elif text[0] == 'EOS':
if sent:
for i, c in enumerate(sent, 0):
if c.dst == -1:
continue
else:
sent[c.dst].srcs.append(i)
s_list.append(sent)
sent = []
else:
morph = Morph(text)
chunk.morphs.append(morph)
temp.append(morph)
# 1行目の表示
for m in s_list[0]:
print(m.idx, [mo.surface for mo in m.morphs], '係り元:' + str(m.srcs),'係り先:' + str(m.dst))
0 ['車両', 'に'] 係り元:[] 係り先:1
1 ['備え', 'られ', 'た'] 係り元:[0] 係り先:2
2 ['外部', 'センサ', 'から', '、'] 係り元:[1] 係り先:8
3 ['前記', '車両', 'の'] 係り元:[] 係り先:4
4 ['外部', '環境', 'を'] 係り元:[3] 係り先:5
5 ['センシング', 'し', 'て'] 係り元:[4] 係り先:6
6 ['得', 'られ', 'た'] 係り元:[5] 係り先:7
7 ['センサデータ', 'を'] 係り元:[6] 係り先:8
8 ['取得', 'する'] 係り元:[2, 7] 係り先:9
9 ['取得', 'ステップ', 'と', '、'] 係り元:[8] 係り先:-1
さらに、係り元の文節と係り先の文節のテキストを抽出する。
for s in s_list:
for m in s:
#係り先がある文節の場合、
if int(m.dst) != -1:
#形態素解析結果のposが'記号'以外のものをrタブ区切りで表示します。
print(''.join([b.surface if b.pos != '記号' else '' for b in m.morphs]),
''.join([b.surface if b.pos != '記号' else '' for b in s[int(m.dst)].morphs]), sep='\t')
車両に 備えられた
備えられた 外部センサから
外部センサから 取得する
前記車両の 外部環境を
外部環境を センシングして
センシングして 得られた
得られた センサデータを
センサデータを 取得する
取得する 取得ステップと
前記センサデータを 分析して
分析して 識別する
前記車両の 外部における
外部における 交通状況を
交通状況を 識別する
識別する 識別ステップと
前記交通状況に関する 情報を
情報を 描写する
視覚的に 描写する
描写する 視覚フィードバックを
視覚フィードバックを 表示させる
表示させる ための
ための グラフィックデータを
グラフィックデータを 生成する
生成する 生成ステップと
インタフェース装置に 表示させる
前記視覚フィードバックを表示させる
表示させる ために
ために 送信ステップと
前記グラフィックデータを 送信する
前記インタフェース装置に 送信する
送信する 送信ステップと
を 含む
含む 方法
最後に、係り受け木を有向グラフとして可視化する。見やすさを優先して、最初のステップのみ、見える化する。
# 最初の部分を試しにやってみます
v = s_list[0]
# 文節のセットを格納するリストの作成
s_pairs = []
for m in v:
if int(m.dst) != -1:
a = ''.join([b.surface if b.pos != '記号' else '' for b in m.morphs])
b = ''.join([b.surface if b.pos != '記号' else '' for b in v[int(m.dst)].morphs])
c = a, b
s_pairs.append(c)
# 係り受け木の描画
import pydot_ng as pydot
img = pydot.Dot(graph_type='digraph')
# 日本語に対応しているフォントを指定します
img.set_node_defaults(fontname='Meiryo UI', fontsize='12')
for s, t in s_pairs:
img.add_edge(pydot.Edge(s, t))
img.write_png('pic')
出来上がりは下の通り。最初に掲載したものと同じものだが、再掲する。
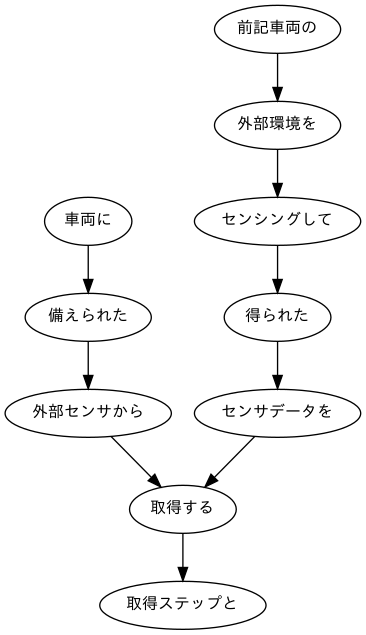
如何だろう。どんなステップなのか、頭に入りやすくなったのではないだろうか。
5.最後に
特許権が、基本的には言葉で決まっていることを初めて知った時、正直、驚いた。もちろん、図面も重要な書類であるが、特許になるか否か、また、権利範囲の確定は、直接的には、言葉で表される。そういった事実を考えると、文章構造の見える化は、とても重要だと思う。
なお、例に使わせていただいたトヨタの自動運転に関する特許は、ステイタスはペンディング。特許になるのは、大変だ。
コーデイングについては、以下のサイトを参考にさせて頂きました。とっても良いサイトで、大変、勉強になりました。この場を借りて、御礼を申し上げます。
▲心くじけず言語処理100本ノック==40~44==