この記事では、近年のマテリアルズインフォマティクスの動向をまとめたレビュー論文である"Methods, progresses, and opportunities of materials informatics"について紹介します。マテリアルズインフォマティクスそのものの概要、機械学習技術の解説から近年の研究動向までいい感じにまとめられているので、参考にしてもらえれば幸いです。なるべく機械的な翻訳ではなく読みやすい日本語になるように気を付けましたが、私はこの分野の専門家ではないので間違った意訳を行っているかもしれませんので、間違っている記述があればご指摘いただけるとありがたいです。なお、記事が冗長になりすぎないようにいくつかのセクションは割愛させていただきました。ご了承ください。
この記事からわかること
- マテリアルズインフォマティクスの概要
- 材料科学の分野で一般的に使用されるML(機械学習)モデリング手法の紹介
- 近年の研究動向のレビュー(ペロブスカイト、触媒、合金等の材料系における応用事例の紹介)
- 今後の展望と課題
1. イントロダクション
従来の材料研究プロセスでは、候補材料の選択は研究者の直感や経験に基づいて行われてきました。このような従来の手法では新材料の開発、製造、応用まで約20年かかるといわれています。このような背景から、材料開発の効率化や低コスト化が強く求められています。
マテリアルズインフォマティクス(MI)は近年のコンピュータの記憶容量や計算能力の向上に伴って発展してきている学問です。材料に関するデータセットが徐々に整備されてきていることも背景にあります。MLを活用して大量の材料データを分析し、PSPP(プロセス(Process)、組織(Structure)、特性(Property)、 性能(Performance)の頭文字をとったもの。材料開発ではこれらの関係を明確化することが重要であると言われている。)関係を推測することで新材料の開発を加速し、開発サイクルとコストの削減を行うことが大きな目的となっています。
過去20年間で、MIは多くの進歩を遂げています。データが十分に豊富な材料分野では、MLは数多くの優れた候補材料を予測するなど一定の成果を挙げています。一方で、データが十分に集まらない分野では予測は困難であったり、データの選択は依然として研究者の直感に依存するなど、まだまだ課題も多いと言われています。
2. 材料科学と機械学習技術
2.1 データ収集
データはMLモデルの学習のため十分な大きさをもつことが求められますが、データ量が大きすぎるとモデルの学習が遅くなります。そのため、研究対象に密接に関連した分野のデータセットを効果的に収集する必要があります。
今日ではオープンソースのデータセットが多数公開されており、様々な材料のデータが誰でも簡単に取得できるようになってきています。またその他にも、先行研究などの出版物からデータを集めたり、ハイスループット実験(材料の調整や合成、物性測定などの実験を自動化・並列化することで効率よくデータセットを蓄積する手法)などの手法を通じてデータ収集が行われることもあります。また、DFT(密度汎関数理論)計算などのシミュレーション技術を使用して大規模なデータセットを作成することもしばしば行われます。
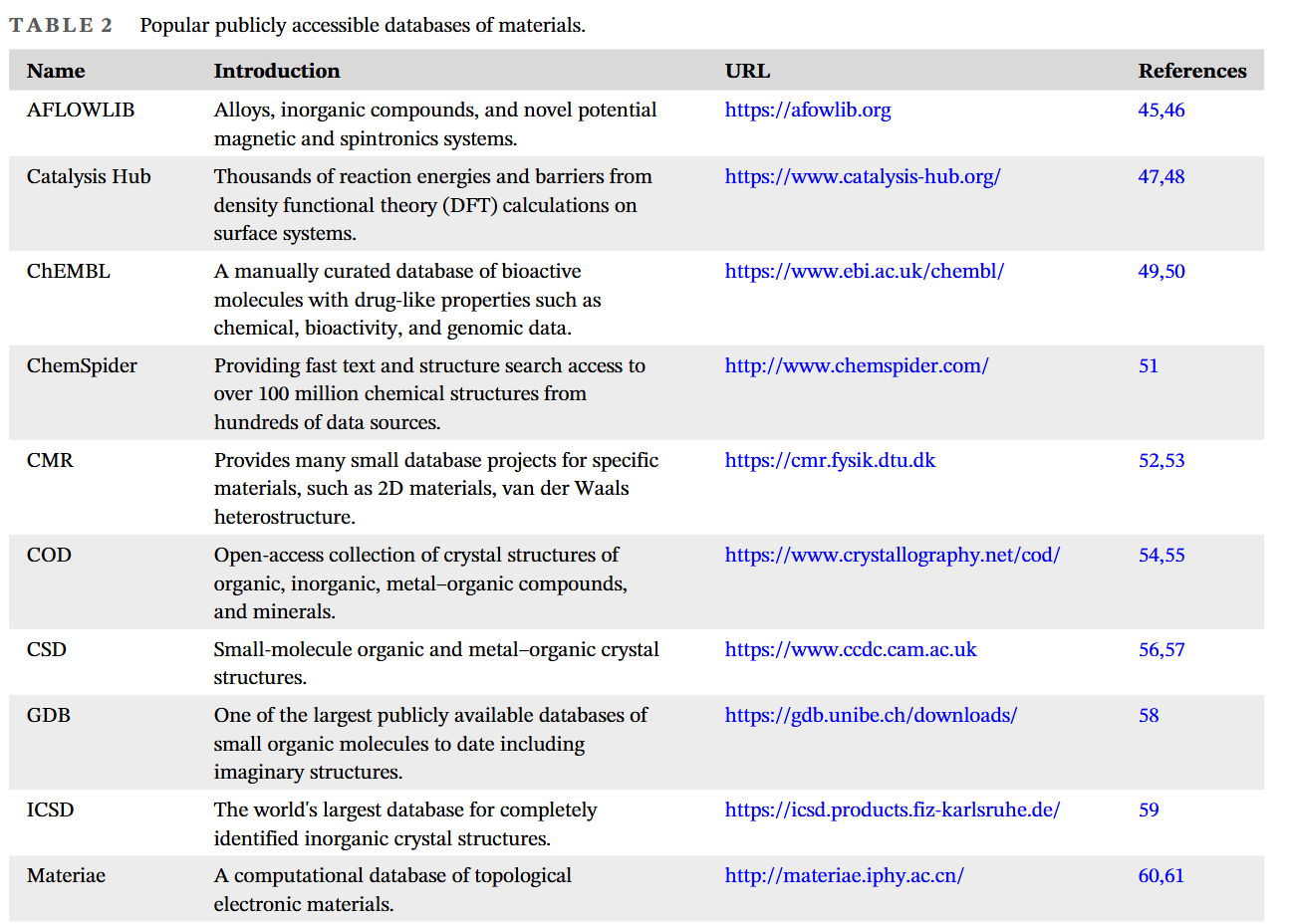
論文のページのTable 2 には代表的なデータセットの概要とURLがまとめられていますので、参考にしてみてください。
2.2 特徴量エンジニアリング
特徴量エンジニアリングはモデル構築までの前処理や特徴量選択など、MLモデルの最終的な性能を決定づける役割を果たします。予測に使用するデータセットは生データのまま使用するのではなく、欠損値の除去、正規化、次元削減、特徴選択などを経て学習させる必要があります。特徴量は多すぎるとオーバーフィッティング(過学習、あるいはデータへの過剰適合)につながりますので、適切な数まで絞られているのが理想です。また、結晶構造などのデータは単純なデジタルデータではないため、MLモデルが理解・解釈できる形式に変換する、といった工夫も必要です。
2.3 代表的なアルゴリズム
MLアルゴリズムには教師あり学習、教師なし学習、半教師あり学習、強化学習などの種類があります。
教師あり学習は最も一般的に使用され、線形回帰、SVM、k-NN、ニューラルネットワークなどが広く知られています。離散的な出力を扱うタスクは分類、連続的な出力を扱うタスクは回帰と呼ばれます。
教師なし学習はクラスタリングや次元削減の手法としてよく利用されます。以下に代表的なアルゴリズムの概要を示します。
線形回帰
線形回帰は出力$\boldsymbol{y}$と入力$\boldsymbol{x}$の関係を線形モデルで表現する手法です。
f(\boldsymbol{x}, \boldsymbol{w})=\boldsymbol{w}^T \boldsymbol{x}+b
$\boldsymbol{w}$と$b$は回帰係数と切片を表し、これらの値を与えられたデータセットから推定します。
線形回帰はモデルの解釈性に優れており、入力と出力の関係を理解しやすいことが特徴です。古くから使われている手法でもあり、論文中では非オーステナイト系亜共析鋼の降伏、引張強度、硬度の間の線形関係を予測した2008年の研究事例が紹介されています。
ベイズ推定
ベイズの定理は、18世紀にイギリスの数学者トーマス・ベイズによって提唱された定理です。詳しい説明はここではしませんが、ベイズ推定では事前確率や事後確率といった概念を使うことで、より直観的なモデリングを行うことができます。
論文中ではこの手法を用いて薄膜TiNのエピタキシャル成長プロセスを最適化し、優れた性能をもつ超伝導材料を合成した事例が紹介されています。
サポートベクターマシン(SVM)
サポートベクターマシンはあるクラスと別のクラスをよく分離する超平面を推定する手法で、外れ値に強いことが知られています。基本的には分類に使われる手法ですが、回帰に利用することもできます。論文中では、SVM回帰モデルを用いて非金属のバンドギャップを定量的に予測し、DFT計算に匹敵する精度を出した事例が報告されています。
k-NNアルゴリズム
k-NNは非常にシンプルな手法で、特徴空間においてあるサンプルのk個の最近傍点の多くが特定のクラスに属する場合、そのサンプルもこのクラスに属する、というように考える手法です。精度もある程度高く外れ値にも強いですが、特徴量が増えると計算量が膨大になりモデルの解釈性も悪くなるため、材料科学分野では、同じデータセットでほかのアルゴリズムの性能を測定するためのベンチマークとしてよく用いられます。
決定木
決定木は、ノードとエッジからなる木構造を使って回帰や分類を行う手法で、簡単に言うと、Yes/Noの質問を繰り返すことで分類結果にたどり着く手法です。決定木は解釈しやすく、離散値と連続値の両方を扱うことができます。
ただ、過学習しやすいことに注意が必要です。論文では、決定木を用いて金属有機構造体のメタン貯蔵容量を空隙率、密度といった特性に基づいて設計する手法を提案した研究が紹介されています。
勾配ブースティング
勾配ブースティングは、機械学習における強力なアンサンブル学習アルゴリズムの一つです。複数の弱い学習器(決定木など)を組み合わせて、より強力な予測モデルを構築する手法です。勾配ブースティングモデルの中ではXGBoost、LightGBMなどのモデルが有名です。Kaggleなどのデータ分析コンペティションでもよく使われるなど、分類、回帰など多くのタスクでパフォーマンスが高いことで人気があるモデルです。後述するペロブスカイトの応用例では、XGBoostを使用した研究を紹介します。
ニューラルネットワーク
ニューラルネットワーク(NN)は簡単に言うと人間の脳の働きをシミュレーションしたもので、入力層、隠れ層、出力層などの多数のノードから構成されます。いわゆる「ディープラーニング」と呼ばれるものはこのNNが使われたモデルを指すことが多いでしょう。近年のAI技術の中核となるもので、後述するCNN(畳み込みニューラルネットワーク)、最近では生成AIなど様々な応用がなされています。NNは活性化関数により非線形のモデリングを行うことができるため、複雑な問題に対し優れた性能を発揮します。一方で、NNはブラックボックスモデルであり、予測結果の解釈が困難であることに注意が必要です。論文では、42CrMo鋼の流動性に及ぼす変形温度、ひずみ、ひずみ速度の影響を研究し、NNが優れた性能を発揮した事例が紹介されています。
畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(CNN)は画像データなどによく適用される手法です。従来のニューラルネットワークに比べてパラメータ数を大きく削減することで、特にグリッド構造を持つデータに対して効率よく計算を行うことができます。論文では、ホウ素-窒素グラフェンの構造を画像データとして学習させることで、バンドギャップを予測するという研究が紹介されています。(原子構造を画像で与えるというアイディアはとても面白いですね。)
主成分分析
前述したとおり、学習に使用する特徴量はなるべく絞られているのが理想です。主成分分析(PCA)は、教師なしアルゴリズムに属しており、ML分野では次元削減手法としてよく使用されます。高次元の特徴量を、データのばらつきが最大となる方向(主成分)へ投影することで次元の削減を行います。論文では、蛍光性炭素量子ドットの合成条件を探索するMLモデルの特徴量削減にPCAを用いた事例が紹介されています。
生成モデル
生成モデルは教師なし学習のディープラーニングモデルの一種で、既存のデータの抽象的な潜在表現を推定することで新しいデータをランダムに生成するモデルです。最近話題になっている「生成AI」もこれに分類されます。生成モデルの中では敵対的生成ネットワーク(GAN)、変分オートエンコーダ(VAN)などが有名ですね。生成モデルの応用先として最も有望なのが、後述するインバースデザインへの応用です。論文では、GANを使用して200万もの無機材料を生成し、そのうち92.53%は新規材料で、かつ84.5%が電気的に安定な材料であったという研究が報告されています。
3. MLモデルの応用
MLモデルの応用には、大きく分けて材料指向(Material-Oriented)な応用と、技術指向(Technology-Oriented)な応用があります。この2つに分けてMLモデルの様々な応用例について紹介します。なお、論文のページにそれぞれの文献の引用先は記載されておりますので、ここでは引用先情報は割愛させていただきます。
3.1 材料指向(Material-Oriented)の応用例
過去20年間、MIの研究者の主な焦点は、冒頭で述べたPSPP関係の一般化、特性の予測、そして新材料のスクリーニングなどでした。しかしMIの発展は、対応する材料のデータ量に大きく依存しています。データ量が少ない場合、MLモデルはPSPP関係の一般化などの単純な予測しかできません。十分なデータ量があれば、より新材料のスクリーニング、未知の材料の特性の予測などより複雑なタスクをこなすことが期待できます。
このセクションでは、ペロブスカイト、触媒、合金などの材料に焦点を当てて最新の研究を紹介します。
ペロブスカイト
ペロブスカイトは、$ABX_3$の化学式で表される化合物であり、A、Bはカチオン、Xはハロゲンまたは酸素で構成されます。シンプルなペロブスカイトの理想的な構造は立方晶であり、立方晶の各頂点はカチオンA、体心位置はカチオンB、面心位置はアニオンXが占める、というような構造になります。これらのイオンは似たような半径をもつ原子で置き換えが可能になるため、潜在的なペロブスカイトの数は数千にも達し、ドーピングを考慮すると$10^7$種類をも超えると言われています。現在では、数千のペロブスカイトが触媒、熱電材料、強誘電体、太陽電池などの候補材料として報告されています。
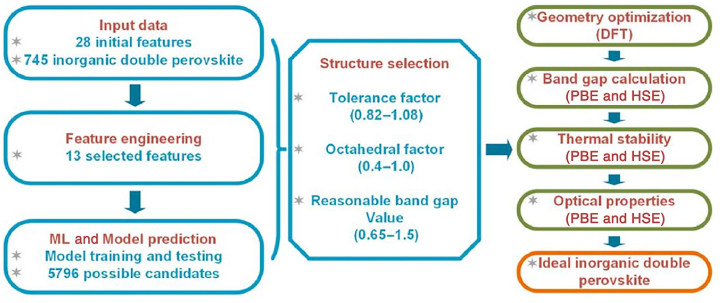
バンドギャップはペロブスカイトの最も重要な物性の一つです。2021年のGaoらの研究では、XGBoostを使用して2種類の鉛フリーの無機ペロブスカイト$Na_2MgMnI_6$、$K_2NaInI_6$を発見しました。下の図はGaoらのワークフローを示したものです。MLモデルとDFTなどの理論計算を組み合わせた以下のようなワークフローになっています。
- 28種類の特徴量を含む745種類の無機ペロブスカイトのデータを使用
- 特徴量を13種類まで削減
- XGBoostによって5796種類の候補材料を予測
- DFT計算によりバンドギャップや熱的安定性などの物性を計算し、最終的に候補材料を2種類に絞る
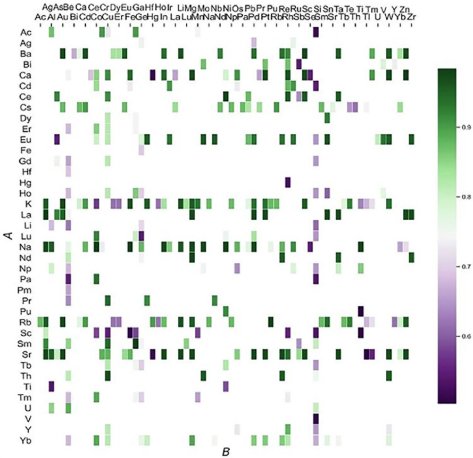
熱力学的安定性はペロブスカイトの寿命を決定づけるものであり、こちらも重要な物性として知られています。2020年のLiuらの研究では、以下のようなフローでペロブスカイトの候補材料を予測しました。
- 397個の$ABO_3$の組成を持つ化合物のデータセットを使用
- 許容因子、八面体因子、電気陰性度などを含む9つの特徴量とそれらを組み合わせた計25個の特徴量を作成
- これらの特徴量を利用し、ある化合物がペロブスカイト構造を持つかどうかを区別する勾配ブースティングモデルを作成
- $ABO_3$化合物から331種類のペロブスカイトを予測し、そのうち174個の予測をDFT計算によってテストしたところ、85%を超える精度で予測
下の表は縦軸がA、横軸がBの元素を表し、色が濃い緑になっているグリッドがペロブスカイトである可能性が高いと予測した化合物です。
触媒
触媒は化学反応に必要な活性化エネルギーを下げ、反応速度を変化させます。これは触媒作用と呼ばれ、歴史の中で長い発展を遂げてきた分野です。酸、アルカリ、金属、半導体、生体触媒など多くの種類があります。触媒の研究とその応用は生物の代謝から産業分野まで広範にわたり、非常に重要な研究分野となっています。一方で触媒は依然として研究者の直感に基づく実験により設計、合成されています。
電気触媒や光触媒は、持続可能な開発を行うためのカギとなる材料です。これらはクリーンエネルギーの生産、貯蔵、変換などの用途で検討されており、炭素排出量を削減することが期待されます。
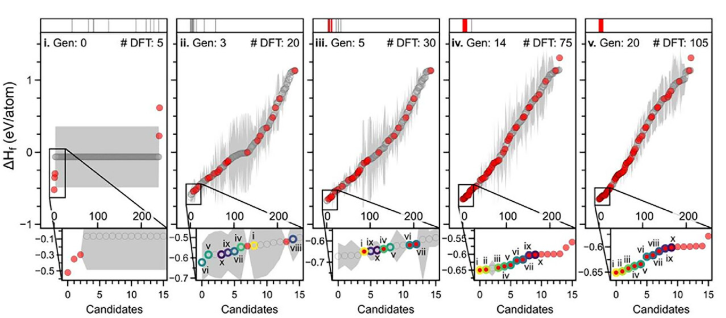
また触媒の安定性は耐用年数に大きく関わり、工業利用する際には重要な要素となります。2020年のFloreらの研究では、酸化イリジウムの安定構造を探索することを目的として、以下のような能動学習(Active Learning)を用いた材料設計を提案しています。能動学習とは、ラベル付けされていないデータの中から学習に役立つデータを選択してラベル付けを行う、という工程を何度も繰り返す手法で、データを効果的に選択してラベル付けの工数を削減する効果があります。
- 合計71224種類のAB_2およびAB_3で表される化合物の結晶構造を収集
- 空間群による重複を削除
- A, Bをイリジウムおよび酸素で置き換え、格子サイズを原子半径に合わせて調整
- 主成分分析(PCA)による次元削減
- 能動学習によりすべての構造のエンタルピーを予測
下の図は能動学習の過程を示した図です。何度もデータの選択、ラベル付けを繰り返すことで安定構造にたどり着いている様子がわかります。最終的には10個の安定構造を発見できたと報告されています。
合金
合金は2種類以上の金属を混ぜ合わせてできた材料で、一般的に加工前の材料と比較すると融点が低く、硬度が高く、延性、耐食性、断熱性などにも優れています。合金の歴史は長く、6000年以上の古代バビロニアでも合金の精錬は行われていたといわれています。合金は機械部品、医療、航空宇宙機器、製造業などで広く利用されます。
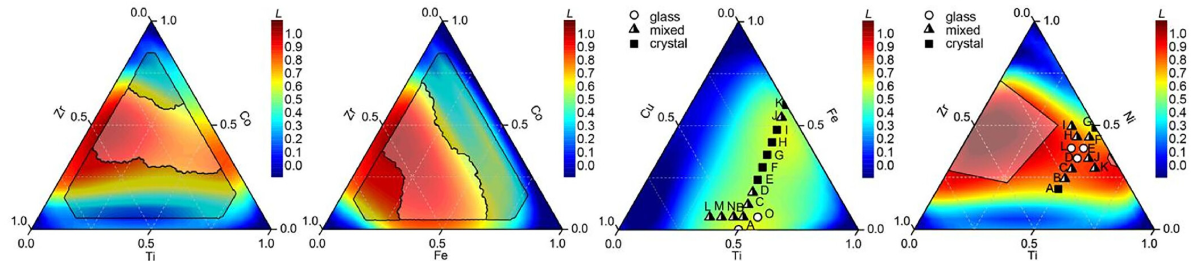
金属ガラスは金属元素を主成分とする非結晶性の合金で、アモルファス金属の一種です。金属ガラスのガラス形成能力を予測するのは大きな課題となっています。2020年のLiuらの研究では、ニューラルネットワークによって電気陰性度、原子サイズ、混合エンタルピー、体積弾性率などの特性から三元合金ガラス形成の可能性を予測しました。下の図は三元系状態図を示しており、色が赤い部分がガラス形成能力が高いと予測される組成に対応します。このモデルは実験データを使わずに作成されましたが、予測結果はTiNiZrおよびTiFeCu合金の合成実験によって検証されたとのことです。
3.2 技術指向(Technology-Oriented)の応用
3.1節では材料指向の応用例を紹介しましたが、ここでは別の観点からのMLの応用例としてインバースデザイン、微細構造の解析支援への応用を紹介します。
インバースデザイン
従来の材料設計では、ある材料の特性を調べてそれを改善したり新しい特性を持たせたりする試行錯誤をプロセスが必要不可欠です。一方でインバースデザイン(逆設計とも呼ばれます)は、まず「こういう特性を持つ材料が欲しい」という目標を設定し、その目標を達成するために必要な構造や組成を計算やシミュレーションを用いて逆算する手法です。ML技術の発展によりこの分野も近年、様々な研究が行われています。
インバースデザインには2つの重要なステップがあります。最初のステップは材料構造に対して可逆的、かつ不変的な特徴量の設計で、これは材料の表現方法に関する新たな課題となります。2つめのステップは要求に応じて新しい材料を生成するニューラルネットワークを構築することです。上で紹介したオートエンコーダ、強化学習、GANなどの技術を利用することでこれを達成できる可能性があります。
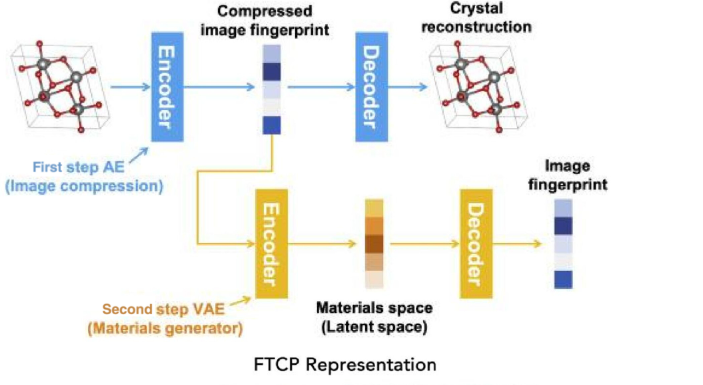
2019年のNohらの研究では。インバースデザインのフレームワークとしてiMatGenを提案しています。これはオートエンコーダを利用しています。オートエンコーダはエンコーダとデコーダの2つのニューラルネットワークから構成され、エンコーダはデータを潜在空間にベクトルとしてマッピングし、デコーダはそのベクトルをもとのデータ空間にマッピングしなおします。NohらはMaterials Projectから10981種類のVxOyの組成を持つ化合物を抽出し、それらを3Dのグリッド画像に変換することでオートエンコーダをトレーニングしました。このモデルを用いることでiMatGenは既知のVxOy化合物から40を超える新しいVxOy化合物を生成し、DFT計算によって合成の可能性を確認しました。この結果はiMatGenの特徴量の可逆性を証明しており、つまり特定の特性を構造とともにデータベースに追加すれば、目的の特性を持つ機能材料の設計を容易にできる可能性を示唆しています。(下の図はiMatGenの処理フローを示したものです)
微細構造の解析
電子顕微鏡はマイクロメートルからオングストロームスケールの特徴や形態を観察するための重要な方法であり、様々な材料の特性評価に広く使用されています。近年はこの電子顕微鏡にMLを組み合わせる試みがなされており、主に教師なし学習のモデルが多く使用されているとのことです。
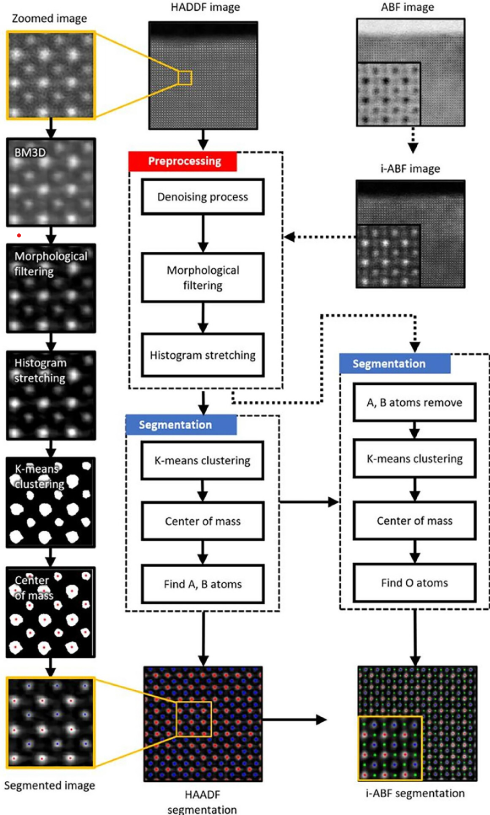
2022年のHanらの研究では、走査型電子顕微鏡(STEM)の画像解析と原子位置の特定手法を提案しています。下に処理フローチャートを載せていますが、大まかな手順としては
- 画像のノイズ除去、フィルタ処理、ヒストグラム調整など前処理
- k-meansによるクラスタリングで原子位置を特定
というようになっています。SrTiO3を解析した例では、誤差は3pm(ピコメートル)以内だったと報告されています。このフレームワークはあらゆるスケールのSTEM画像に適用可能とのことで、人力で行っていた画像解析作業を自動化できる可能性があります。
4. 今後の展望
ここまで紹介したように、材料開発にML技術を応用した研究では様々な成果が挙げられています。一方で、解決すべき課題もまだまだ多いのが現状です。ここではマテリアルズインフォマティクスの今後の課題について4つのセクションに分けて議論します。
データの共有
「データ共有」の概念はかなり昔から提唱されています。誰もが独自の専門分野を持っているため、それらの知見を共有することは科学研究にとって重要となります。しかし多くの場合、成功した実験データのみが共有されます。ここで言っているデータ共有は、失敗した実験や途中で放棄されたプロジェクトなど、通常は公開されないデータを指します。失敗した実験データもMLモデルのトレーニングに入れることでデータのバリエーションが増え、モデルの精度を大きく向上させる可能性があります。多くの実験データは研究者のノートに埋もれたままであるため、こういったデータを共有するに至るまではまだ長い時間が必要となるでしょう。
強力な構造記述子
機械学習における記述子は、データから取り出した特徴量を指します。特徴量エンジニアリングのセクションでも書いた通り、MLモデルのパフォーマンスはいかに効果的な記述子を設計するかにかかっています。より効果的で強力な記述子は、 可能な限り少ない次元を持ちながらも、材料の構造やトポロジーに関する情報を失うことなくカバーしている必要があります。インバースデザインなどにも展開するためには、可逆性や不変性も重要な要素となります。
小規模データベースに基づくモデル
MLに使えるような材料分野のデータはしばしば不足しています。しかし、小規模なデータセットを使って効果的にMLモデルをトレーニングすることで、多くの新しい発見につながる可能性があります。触媒の応用例で能動学習を紹介しましたが、これは少ないデータでMLモデルをトレーニングするための効果的な手法です。また、転移学習という手法も知られています。転移学習は、他のタスクに向けてすでにトレーニングされたモデルをベースとして、目的となるデータセットにより追加で学習をしてモデルの調整を行う方法です。すでにトレーニングされたモデルを使うことである程度の精度が保証されているため、少量のデータセットでも効率的に学習をさせることができます。高精度のデータは常に高価で不足しています。逆に安価で精度が低く、ノイズが多いデータを大量に使用してMLモデルをトレーニングすると、モデルのパフォーマンスを向上させることが証明されています。データベースを充実させるために、さまざまな実験や理論計算手法を併用していくことが解決策となるかもしれません。
新しい法則の発見
MLは新しい科学法則の発見にも大きな期待が寄せられています。データが十分にある場合、MLモデルは特定の予測タスクをうまくこなしますが、モデルの解釈可能性はしばしば課題となります。特にニューラルネットワークを用いた場合、モデルに隠されている特徴量の関係を可視化することは困難です。また仮に視覚化ができたとしても、研究者が複雑な関係をすぐに理解することは難しいでしょう。しかし、このブラックボックスを突破することで新たな隠された科学法則が発見される可能性を秘めているとも言えます。
まとめ
以上、マテリアルズインフォマティクスに関するレビュー論文を翻訳して紹介させていただきました。オープンにアクセスできる記事の中では、ここまでマテリアルズインフォマティクスに関して広範にわたる研究をまとめたものは少ないのではないでしょうか。省略している部分もかなりありますので、気になる部分があった方はぜひ元の記事を見てみてください。私自身も翻訳しながら記事をまとめていく中で、近年の研究で機械学習がどのように材料分野に応用されているのか、非常に勉強になりました。今後もこのように論文の紹介や、実際にプログラミングをしてマテリアルズインフォマティクスを体験するような記事を書いていきたいと思っていますので、チェックしていただけたら幸いです。