
数週間前から機械学習のチュートリアルを動かしつつそれっぽいものが完成したのでご紹介します。
5人の女優(新垣結衣、本田翼、堀北真希、板野友美、有村架純)のうち、誰に似ているのか判別するプログラムです。
CNNを使った画像認識
深層学習の1つである**CNN(畳み込みニューラルネットワーク)**を利用した顔の判別プログラムを作成しました。
CNNってなんぞや?という方向けに軽く説明しますと...
近年、コンピュータビジョンにおける最もイノベーションと言えるのはConvolutional Neural Networkといっても過言ではない。
コンピュータビジョンの業界におけるオリンピックとも言えるコンペティションがImageNetである。 そのコンペティションにおいて、Alex Krizhevskyのチームが2012年に圧勝したニューラルネットワークもこの手法である。 それまで26%だったエラー率を11%も下げることに成功したのだ。
引用元:定番のConvolutional Neural Networkをゼロから理解する
どうやら画像認識のコンペで彗星の如く現れた手法のようですね。均衡していた中でエラー率を大幅に低下させたCNNは機械学習の研究者に大きな衝撃を与えました。
これまでの画像判別
例えばウサギを判別するプログラムを作りたい!となると、以前は人間が耳がピンとして長い・白くて毛がふわふわしているなどのウサギの特徴を人間が判別していました。
では、以上の特徴を踏まえてウサギを判別してみます。
耳が垂れていて、茶色の毛を纏ったウサギ

この画像は耳がピンと立っていないうえに毛色が白ではありません。先の特徴と一致しないのでウサギと判別することはできないでしょう。
様々な特徴をプログラムに書き起こすとなるとコード量が膨大になるうえに汎用性が損なわれてしまいます。ウサギの特徴を少し弄ってカラスの判別はできません。特徴が全く異なるからです。
そんな苦労をなくそうよ!ということからCNNなどのニューラルネットワークを使い、たくさんのウサギの特徴をコンピュータが学習させることで人間が楽になっちゃった。めでたしめでたしって流れになります(笑)
少し脱線しました。本題に移ります。
プロセス
製作するまでの流れはこちら。全てPythonのスクリプトで実装できました、Python様様です。
- download.py...FlickrAPIを使用した画像の自動ダウンロード
- face_cut.py...ダウンロードした画像を回転させながら顔を切り取る
- rename.py...画像名を連番にリネーム
- gen_data.py...切り取った顔画像を水増しつつnumpy配列に格納
- image_cnn.py...学習の実行
- predict_image.py...画像から顔を判別
- predict_camera.py...カメラから顔を判別(MacBook Proのカメラにて動作確認)
Flickrから画像を自動ダウンロード
APIを使用するので事前にキー取得する必要があります。私はこちらの記事を参考にしました。
***で埋められている箇所にキーを入力してください。
次にダウンロードするためのライブラリをインストールします。
pip install flickrapi
import os, time
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
from pprint import pprint
# 検索ワード
search_word = "新垣結衣"
# ダウンロード枚数
img_num = 10
# 保存するディレクトリ(存在しない場合は自動で作成)
img_dir = "./yui_aragaki/"
# FlickrのAPIキー
public_key = "********************************"
secret_key = "****************"
# flickerAPIにアクセスするオブジェクトを生成
flicker = FlickrAPI(public_key, secret_key, format = 'parsed-json')
# フォルダの作成
try:
os.makedirs(img_dir)
except FileExistsError:
pass
result = flicker.photos.search(
# 検索時のパラメータ(検索ワード)を指定
text = search_word,
# データの件数を指定
per_page = img_num,
# メディアを指定(画像)
media = 'photos',
# 並びを指定(関連順)
sort = 'relevance',
# 有害コンテンツの設定(除外)
safe_search = 1,
# 返却値に取得したいオプション値を指定(画像のurl、ライセンス情報)
extras = 'url_m, lincence'
)
images = result['photos']
# 取得データ(JSON形式)
# pprint(images)
# 画像を順に取り出し、フォルダに保存する
for image in images['photo']:
# urlを格納
try:
url = image['url_m']
except KeyError:
continue
# ファイルパスを指定(画像名はid)
filepath = img_dir + image['id'] + '.jpg'
# 画像のidが重複していたらスキップする
if os.path.exists(filepath): continue
# ダウンロード
urlretrieve(url, filepath)
print("Download:{}:{}".format(search_word, url))
# 1秒待機
time.sleep(1)
$python3 download.py
Download:新垣結衣:https://farm2.staticflickr.com/1304/603073634_0a438429f8.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3612/3322172710_b3096b250a.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3537/3322177614_b4381e7c8e.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3275/2322736059_fccdee8771.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3581/3429822899_f051eeca74.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3614/3321342551_8eae87700a.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3621/3321346681_9e889e871b.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3383/3430644706_ce89601b96.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3570/3430646438_a21974917d.jpg
Download:新垣結衣:https://farm4.staticflickr.com/3598/3423217944_d0daca7c5f.jpg
実行するとカレントディレクレクトリにフォルダが作成され、画像が保存されます。
海外のサイトなのでメジャーな女優は多数ヒットしましたが、少しマイナーになってくるとガクッとヒットしなくなります。他の検索エンジンで自動化するのが今後の課題ですね。
画像から顔の判別・切り取り
OpenCVに顔を判別する機能が提供されているので使わせていただきました。
Haar-cascadeの顔検出器を使用して画像から顔を検出します。カスケードファイルはこちらから「haarcascade_frontalface_default.xml」をダウンロードしてください。
今回は画像を5度ずつ回転させて行うので、同じ顔や誤検出がどうしても多くなってしまいます。
できるだけ人間が楽をするために画像のハッシュ値を比較し、重複した画像の削除する処理を行いました。
import cv2
import glob
import shutil
import re
import os
import hashlib
# 画像を読み込むディレクトリ
img_dir = "./yui_aragaki/"
# .jpgファイルを読み込み、リストを作成
images_list = glob.glob(img_dir + "*.jpg")
images_name = []
name_regex = re.compile(r'/(\w+).jpg')
# ファイル名の拡張子を取り除く
for name in images_list:
name = name_regex.search(name).group()
name = name.strip('.jpg')
images_name.append(name)
# 取得データを表示(JSON)
# print(images_name)
# 顔認識器を生成
cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
# 顔画像の保存フォルダ作成
try:
os.makedirs(img_dir + "faces")
except FileExistsError:
pass
# 顔未検出画像の保存フォルダ作成
try:
os.makedirs(img_dir + "not_detected")
except FileExistsError:
pass
for i, image in enumerate(images_list):
face_count = 1
# 顔の識別フラグ
face_flg = False
#画像の読み込み
image = cv2.imread(image)
# ハッシュ値を格納する配列の初期化
hash_list = []
#画像を5度ずつ回転させて顔認証を実行(0度〜355度)
for angle in range(0, 360, 5):
facerect = cascade.detectMultiScale(image, scaleFactor = 1.2, minNeighbors = 1, minSize=(10, 10))
# 1つ以上の顔が検出された
if len(facerect) > 0:
for rect in facerect:
# 顔を切り出す
x = rect[0]
y = rect[1]
width = rect[2]
height = rect[3]
dst = image[y:y + height, x:x + width]
save_path = img_dir + "faces" + images_name[i] + "-" + str(face_count) + ".jpg"
face_count += 1
# 認識結果の保存
cv2.imwrite(save_path, dst)
print("save:" + save_path)
# ハッシュ値を比較し、一致する画像は削除
hash_data = open(save_path, 'rb')
# ハッシュ値の計算
hash_data = hashlib.md5(hash_data.read()).hexdigest()
# 配列に保存
hash_list.append(hash_data)
# 自らを比較対象にしない
hash_loop = len(hash_list) - 1
# ハッシュ値の比較
for j in range(hash_loop):
if hash_data == hash_list[j]:
os.remove(save_path)
hash_list.pop()
print('duplication delete:' + save_path)
break
# 顔が検出されたか
if len(hash_list) > 0 and face_flg == False:
face_flg = True
# 顔が検出された画像は削除
if face_flg == True:
os.remove(images_list[i])
else:
# 顔未検出の画像は移動
shutil.move(images_list[i], img_dir + 'not_detected')
ハッシュ値の比較がどれほど効果あるのか確認してみましょう。
download.pyで集めた10枚の画像で顔を判別してみます。
比較前
画像の枚数:1008枚

比較後
画像の枚数:14枚

凄まじい程データ量が減りました(笑)これなら前処理の手間が省けますね!
実はこちらも欠点が1つあり、横顔の認識には対応していません。検出できなかった画像は「not_detected」フォルダに保存されているので各自切り出してデータを増やしてください。
画像を一括リネームする
画像をnumpyの配列に格納する前に連番を付与する処理を行います。これを行わないとエラー吐いちゃう...
正規表現使えば解決できる気がします。誰か代わりにやってください。
import glob
import os
# 画像の名前を変更するディレクトリ
img_dir = "./yui_aragaki/"
# 連番に変更する名前
name = "yui_aragaki"
images_list = glob.glob(img_dir + "*")
for i, image in enumerate(images_list):
dst = img_dir + name + "_{0:05d}".format(i + 1) + ".jpg"
os.rename(image, dst)
print("rename:" + dst)
5桁揃えの連番に変更することができました。

画像をnumpy配列に格納する
保存した画像を読み込み、学習データと確認データに分割して配列に格納します。
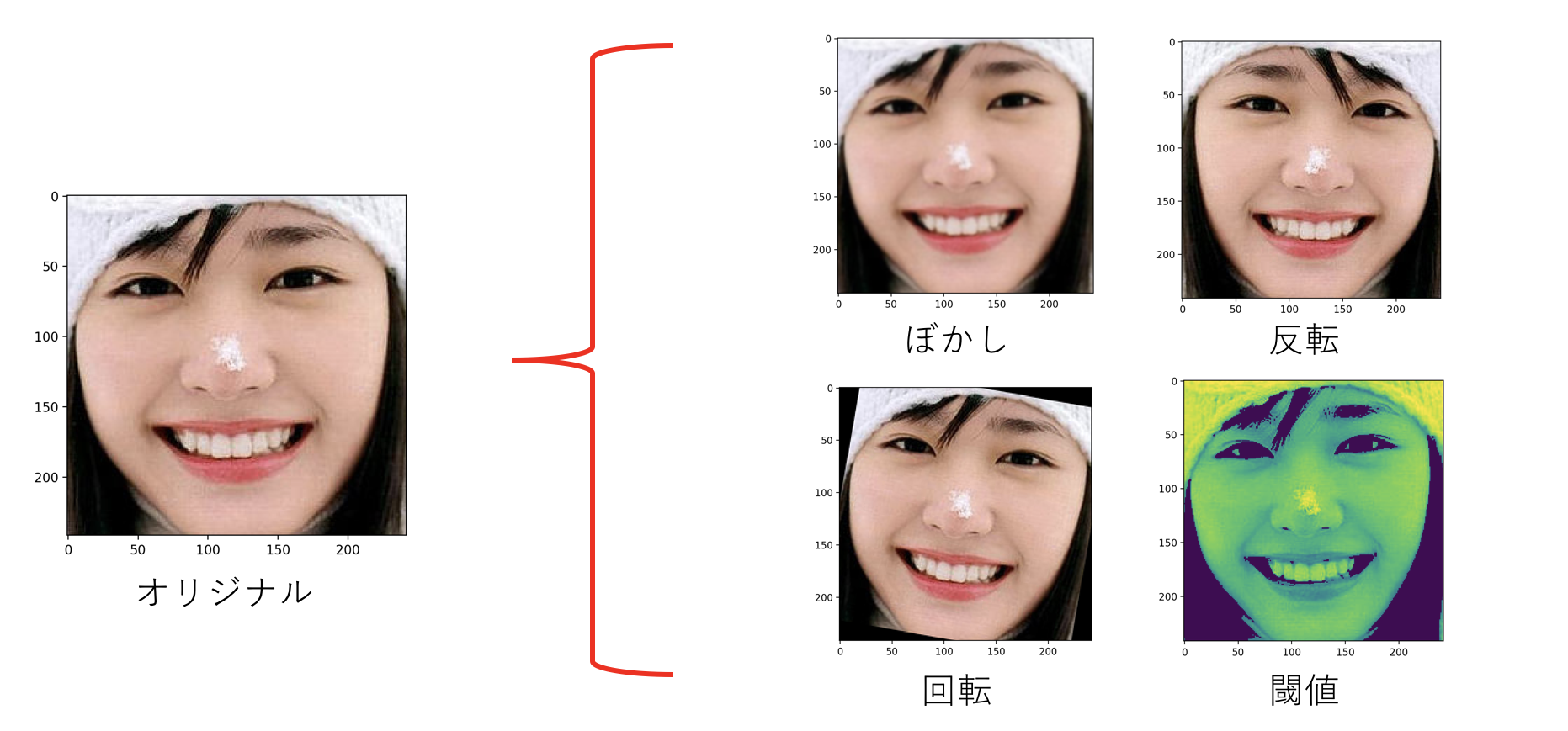
今回は各項目の画像枚数が400枚ほどと少なめだったのでついでに水増しする処理も行いました。
-5度,0度,5度の回転から各5枚生成して15倍に増やします。
import os, glob, random
import cv2
from PIL import Image
import numpy as np
# 画像フォルダが存在するディレクトリ
image_dir = "./faces/"
# カテゴリ毎に分類(フォルダ名)
category = ["yui_aragaki",
"tsubasa_honda",
"tomomi_itano",
"maki_horikita",
"kasumi_arimura"]
# 出力するnpyファイル名
out_npy = "gakky_rgb.npy"
# 画像のサイズ(縦横60px)
image_size = 60
# 画像を格納する配列
X_train = []
X_val = []
# ラベルデータを格納する配列
Y_train = []
Y_val = []
# OpenCVの画像データをPILに変換
def convert_cv2pil(image_cv):
image_pil = Image.fromarray(image_cv)
image_pil = image_pil.convert('RGB')
image_pil = np.asarray(image_pil)
return image_pil
# 学習用の配列に追加
def append_train(image, index):
image = convert_cv2pil(image)
global X_train
global Y_train
data = np.asarray(image)
X_train.append(image)
Y_train.append(index)
# 確認用の配列に追加
def append_val(image, index):
image = convert_cv2pil(image)
global X_val
global Y_val
data = np.asarray(image)
X_val.append(image)
Y_val.append(index)
# カテゴリのループ
for index, category_name in enumerate(category):
# 画像の読み込み
images_dir = image_dir + category_name
files = glob.glob(images_dir + "/*.jpg")
# 画像のシャッフル
random.shuffle(files)
# 10%の画像をテストデータに
test_num = int(len(files) * 0.1)
# 画像の取り出し
for i, file in enumerate(files):
# 画像の読み込み
image = cv2.imread(file)
print("open_img:{}".format(file))
# リサイズ
image = cv2.resize(image, (image_size, image_size))
# 読み込み枚数がtest_num以下の場合はテストに以降は訓練に格納
if i < test_num:
append_val(image, index)
else:
# 訓練データの水増し
for i in range(-5, 6, 5):
# 回転
center = int(image.shape[1] / 2)
rotate = cv2.getRotationMatrix2D((center, center), i, 1)
img = cv2.warpAffine(image, rotate, (image_size, image_size), flags = cv2.INTER_CUBIC)
append_train(img, index)
# 反転
img = cv2.flip(img, 1)
append_train(img, index)
# ぼかし
img_b = cv2.GaussianBlur(img, (5, 5),0)
append_train(img_b, index)
# 闘値
img_t = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img_t = cv2.threshold(img_t, 100, 255, cv2.THRESH_TOZERO)[1]
append_train(img_t, index)
# numpyの配列形式に変換
X_train = np.array(X_train)
X_val = np.array(X_val)
Y_train = np.array(Y_train)
Y_val = np.array(Y_val)
# 配列に変換した画像を保存
data = (X_train, X_val, Y_train, Y_val)
np.save("./" + out_npy, data)
print("Success:create ./" + out_npy)
実行すると拡張子がnpyのファイルが作成されます。これが画像を配列に変換し、1つにまとめたものです。
これで学習前の長い長い前処理が完了しました。
本題の深層学習を行なっていきましょう!
コンピュータに頭脳を生み出す
キモとなる学習フェーズです。
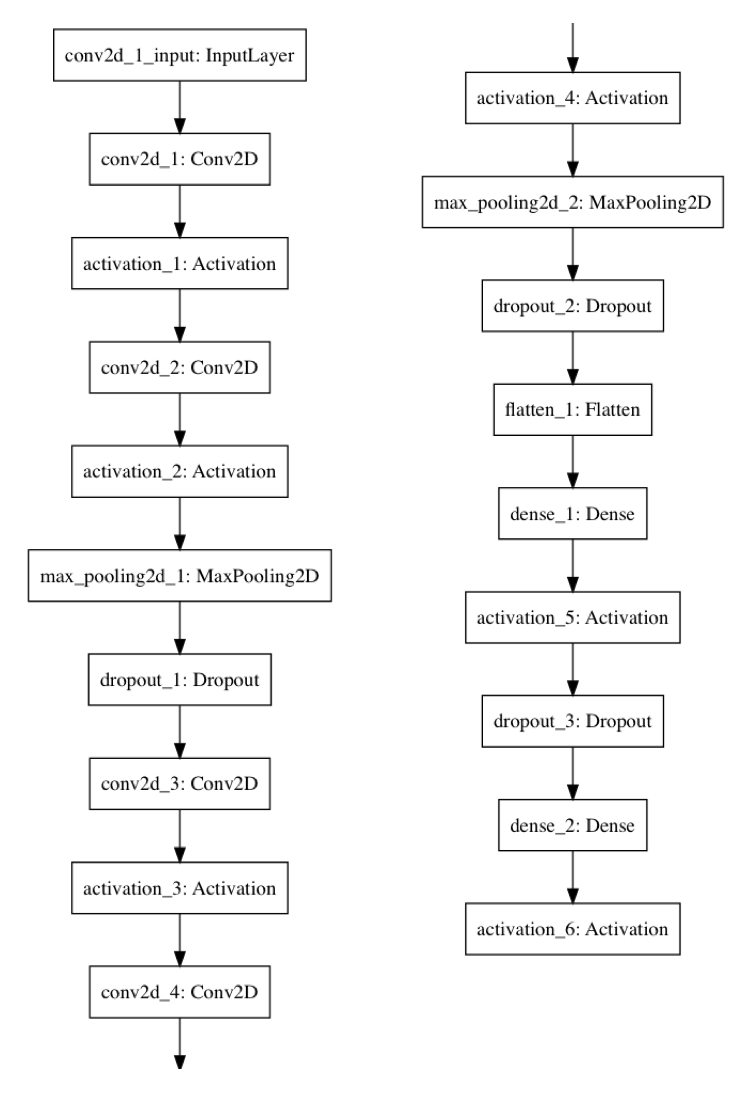
ライブラリはkerasで、keras-teamが製作したcifar10_cnn.pyのモデルを使わせていただきました。
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
from keras.utils import plot_model
# npyファイルの読み込み
in_npy = "gakky_rgb.npy"
# 出力するモデル名を指定
out_model = "gakky_model_15.h5"
# CNN設定
CATEGORY_NUM = 5
BATCH_SIZE = 32
EPOCHS = 15
LEARNING_RATE = 0.0001
def main():
# gen_data.pyで生成したRGB形式の画像データを読み込む
X_train, X_val, Y_train, Y_val = np.load("./" + in_npy)
# 正規化を行う(最大値:256で割って0〜1に収束)
X_train = X_train.astype("float") / 256
X_val = X_val.astype("float") / 256
# ラベルをベクトルに変換
Y_train = np_utils.to_categorical(Y_train, CATEGORY_NUM)
Y_val = np_utils.to_categorical(Y_val, CATEGORY_NUM)
# 学習の実行
model = model_train(X_train, Y_train, X_val, Y_val)
def model_train(X, Y, Xv, Yv):
# モデルの定義
model = Sequential()
model.add(Conv2D(32, (3, 3), padding = 'same', input_shape = X.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding = 'same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(CATEGORY_NUM))
model.add(Activation('softmax'))
# モデルの可視化
plot_model(model, to_file='model_' + str(EPOCHS) +'.png')
# 最適化処理
opt = keras.optimizers.rmsprop(lr = LEARNING_RATE, decay = 1e-6)
# モデル最適化の宣言
model.compile(loss = 'categorical_crossentropy', optimizer = opt, metrics = ['accuracy'])
# 学習
result = model.fit(X, Y, batch_size = BATCH_SIZE, epochs = EPOCHS, validation_data = (Xv, Yv))
# モデルデータの保存
model.save('./' + out_model)
print("Success:create ./" + out_model)
# グラフ表示
plt.plot(range(1, EPOCHS + 1), result.history['acc'], label = "train-acc")
plt.plot(range(1, EPOCHS + 1), result.history['loss'], label = "train-loss")
plt.plot(range(1, EPOCHS + 1), result.history['val_acc'], label = "val-acc")
plt.plot(range(1, EPOCHS + 1), result.history['val_loss'], label = "val-loss")
plt.title(out_model)
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
return model
if __name__ == "__main__":
main()
学習結果はこちら。
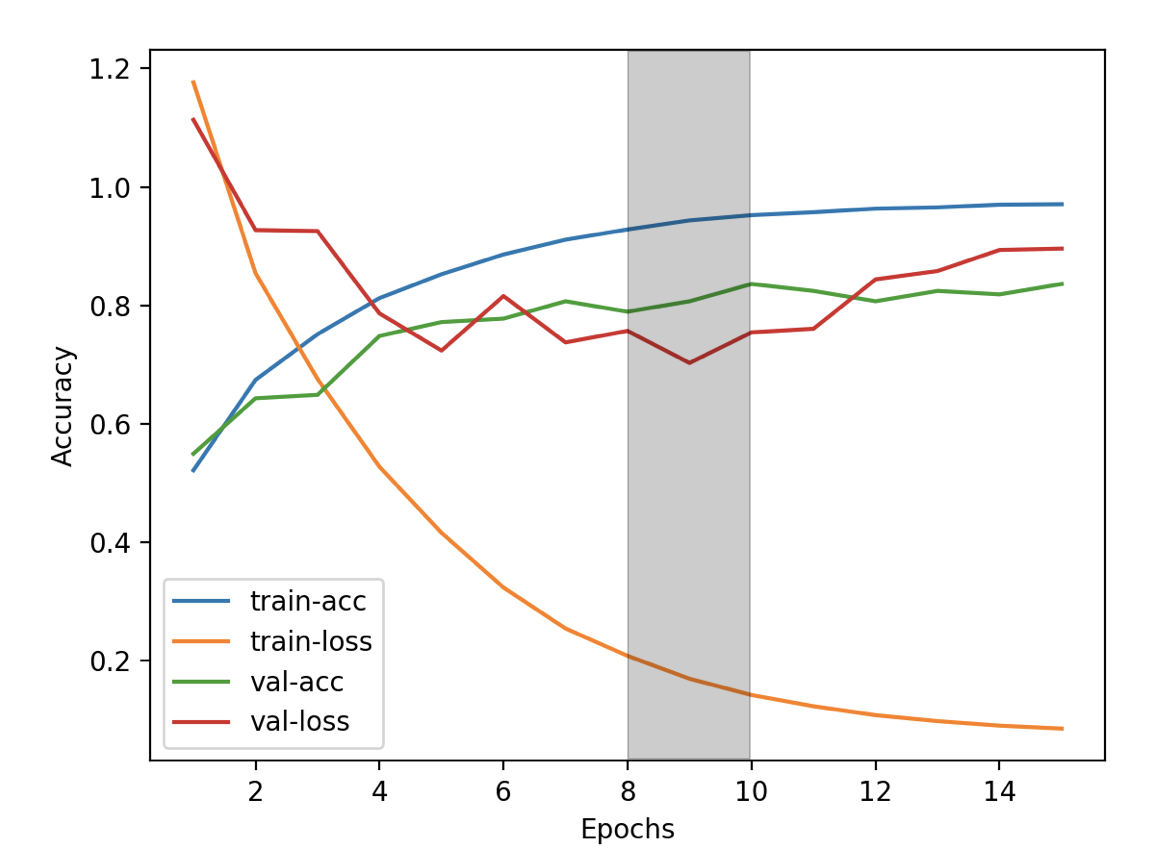
過学習の傾向がありますね、確認データの損失であるval-lossの値が9エポックから増加し、学習データにフィットしているのがグラフから読み取れます。
理想は8〜10エポックの値で終了するのが良かったでしょう。灰色の帯の辺りが最適ですね。
それでも80%近くの精度が得られたのでそっくりさんを判別するには十分な精度ではないでしょうか。女優の皆さんが美人揃いなので特徴を見出すのが難しいのかもしれません。
学習後は拡張子がh5のファイルが完成します。これが顔を判別するモデルです。
画像を使ってテスト
機械学習を使って乃木坂46を顔分類してみたを参考にプログラムを修正しました。ありがとうございます。
コマンドラインから画像のパスを受け取り、カスケード分類機で顔の座標を取得して切り取ります。
その画像を学習したモデルに入れることで顔を判別ができる仕組みです。
import sys
import cv2
import keras
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from keras.models import Sequential, load_model
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import plot_model
# カテゴリ名
category = ["yui",
"tsubasa",
"tomomi",
"maki",
"kasumi"]
# 読み込むモデル
in_model = "gakky_model_15.h5"
def detect_face(image):
# 顔抽出
image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
# 顔認識の実行
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
#顔が1つ以上検出された
if len(face_list) > 0:
for rect in face_list:
x,y,width,height=rect
img = image[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
if image.shape[0] < 64:
print("エラー:顔が小さすぎて読み込めませんでした。")
continue
img = cv2.resize(image,(60,60))
img = np.expand_dims( img, axis = 0)
name = detect_who(img)
cv2.rectangle(image, tuple(rect[0:2]), tuple(rect[0:2] + rect[2:4]), (255, 0, 0), thickness = 3)
cv2.putText(image, name, (x, y + height + 20), cv2.FONT_HERSHEY_DUPLEX, 1, (255 , 0, 0), 2)
#顔が検出されなかった
else:
print("エラー:顔を検出できませんでした。")
return image
def detect_who(face_image):
# 結果を格納
result = model.predict(face_image)[0]
# 一番可能性の高い配列の添字を返す
predicted = result.argmax()
percentage = int(result[predicted] * 100)
# カテゴリ名と確率を表示
print("{0} ({1})%".format(category[predicted], percentage))
return category[predicted]
try:
model = load_model('./' + in_model)
except OSError:
print('エラー:./' + in_model + 'が見つかりません。')
exit()
# コマンドラインの引数で与えられたパスの画像の確認
if len(sys.argv) == 2:
try:
image = cv2.imread(sys.argv[1])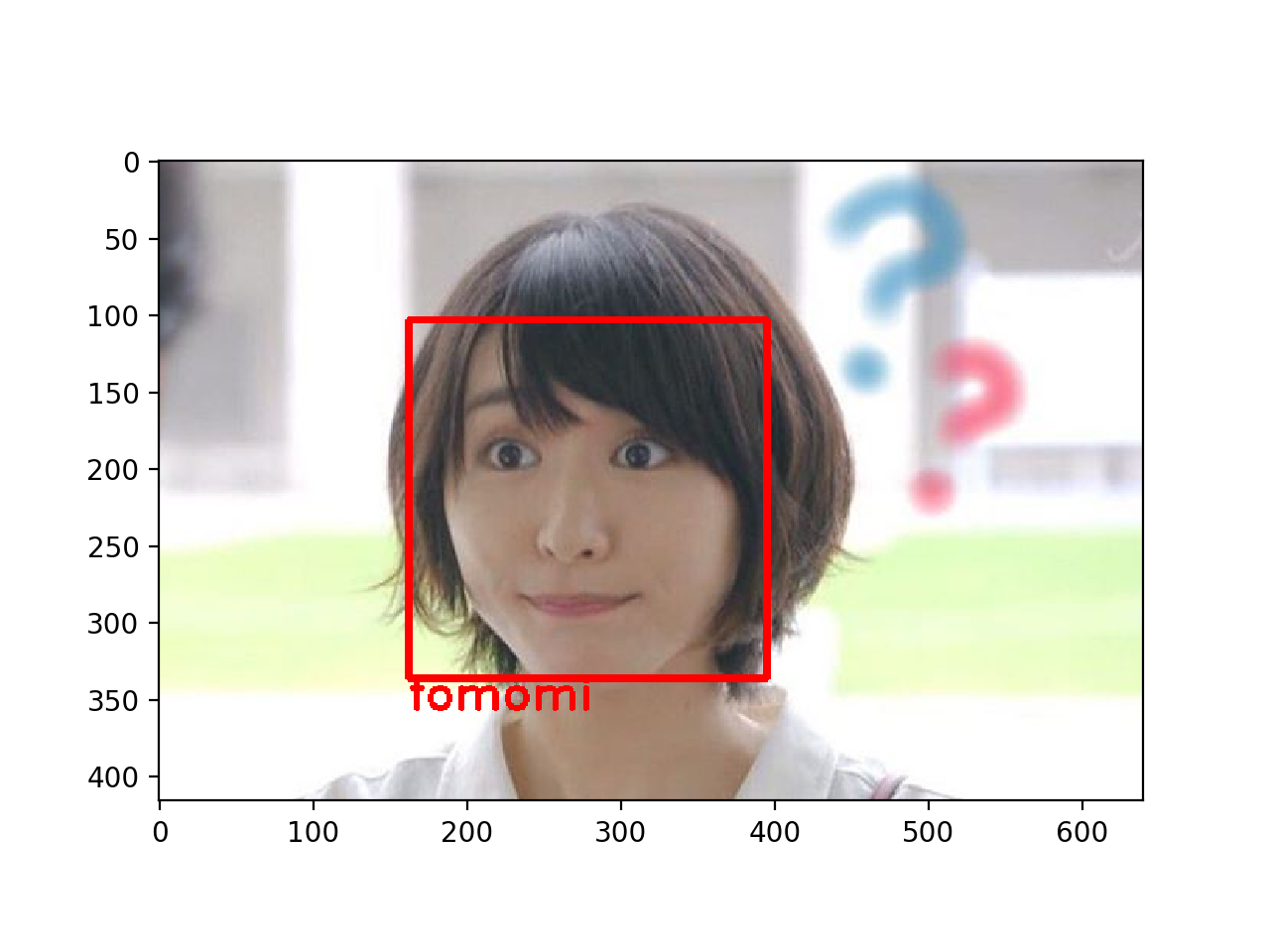
except FileNotFoundError:
print('エラー:パスに指定された画像が見つかりませんでした。')
exit()
elif len(sys.argv) > 2:
print('エラー:パスは1つだけ指定してください。')
exit()
else:
print('エラー:コマンドライン引数に画像のパスを設定してください。')
exit()
b,g,r = cv2.split(image)
image = cv2.merge([r,g,b])
image = detect_face(image)
plt.imshow(image)
plt.show()
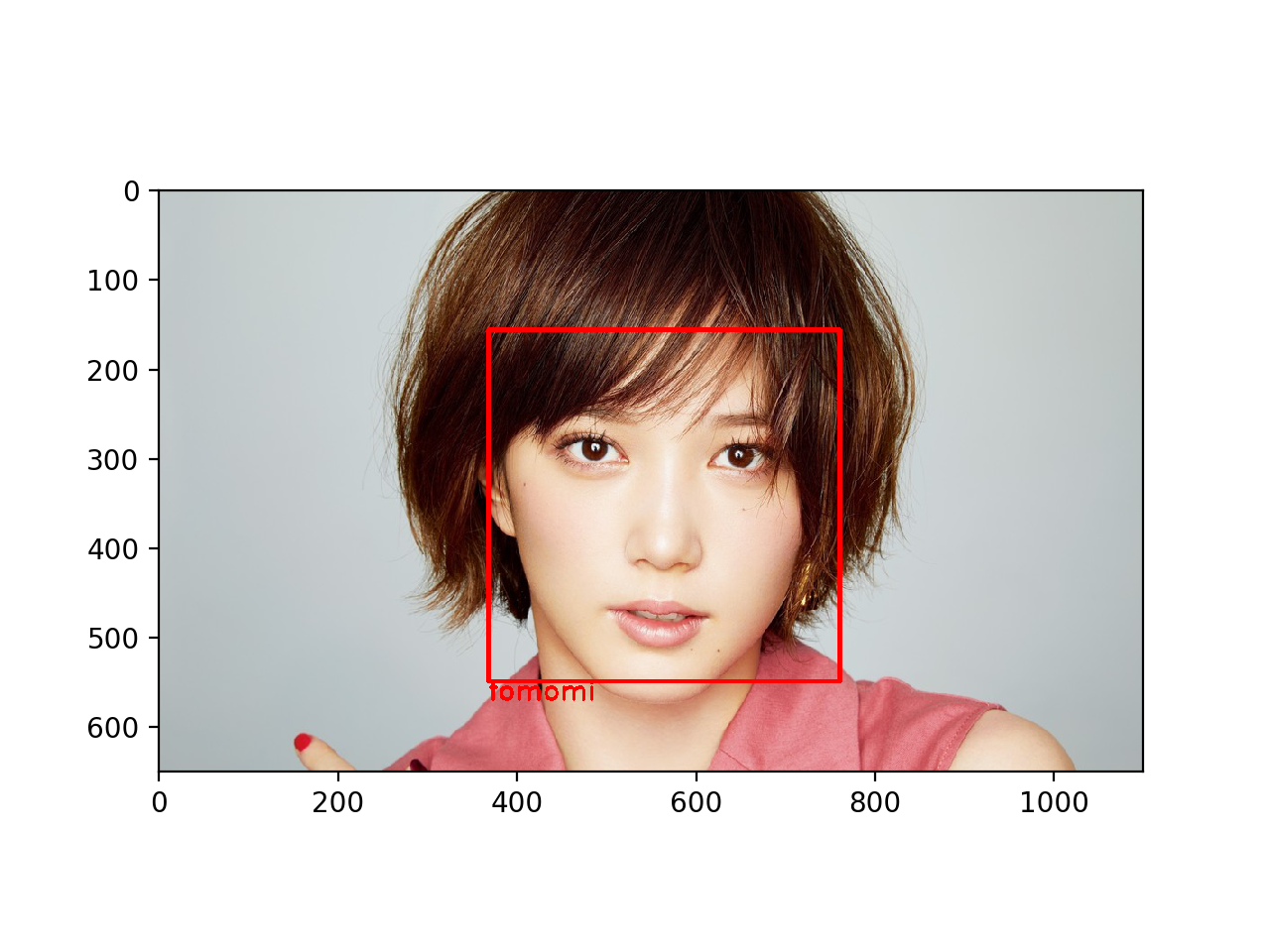
実際に本人たちで確認してみます。
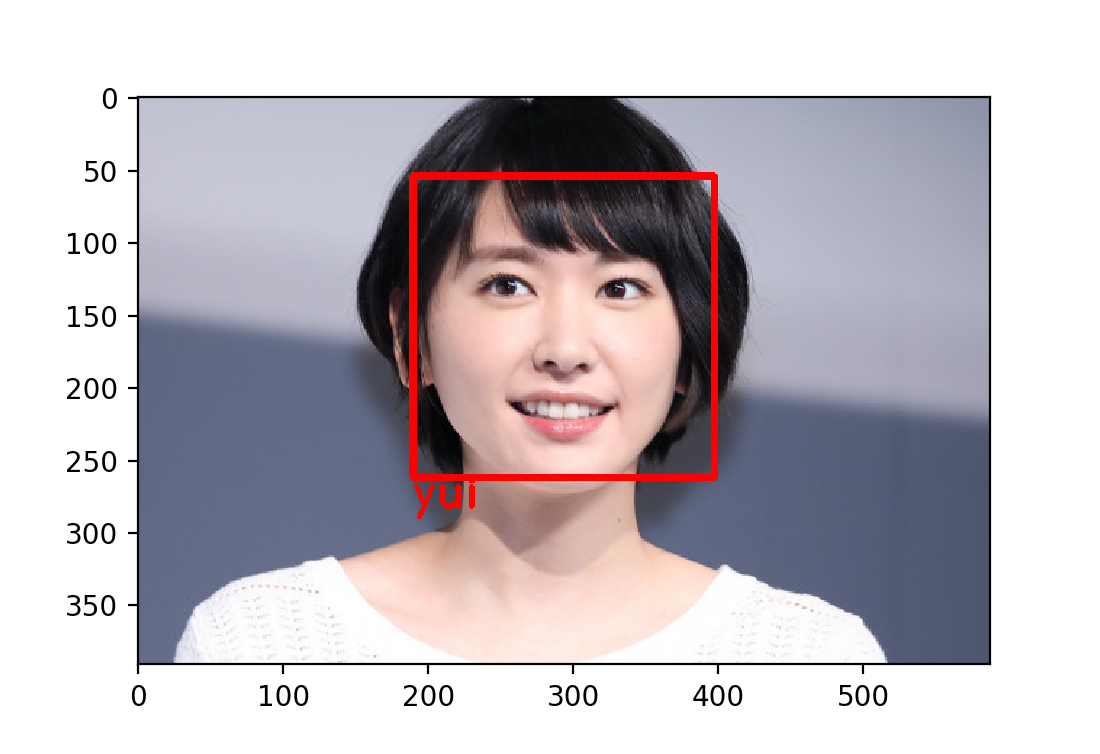
しっかり判定してますね!
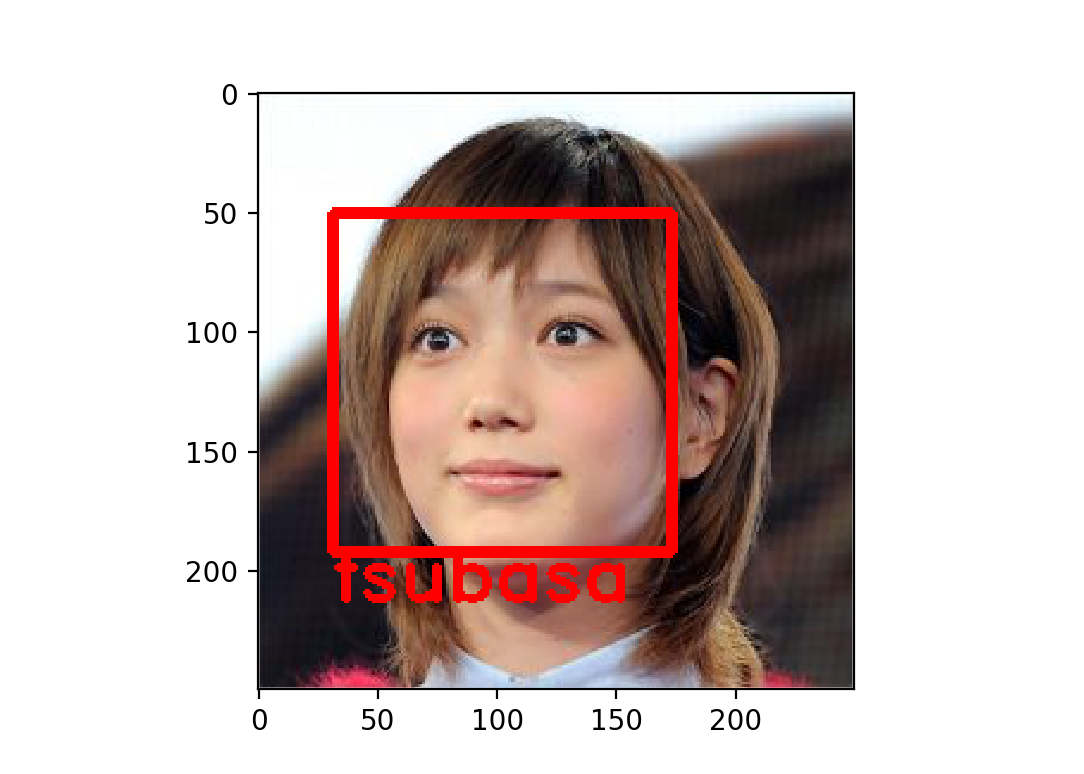
ですが、間違いもいくつか見つかりました。
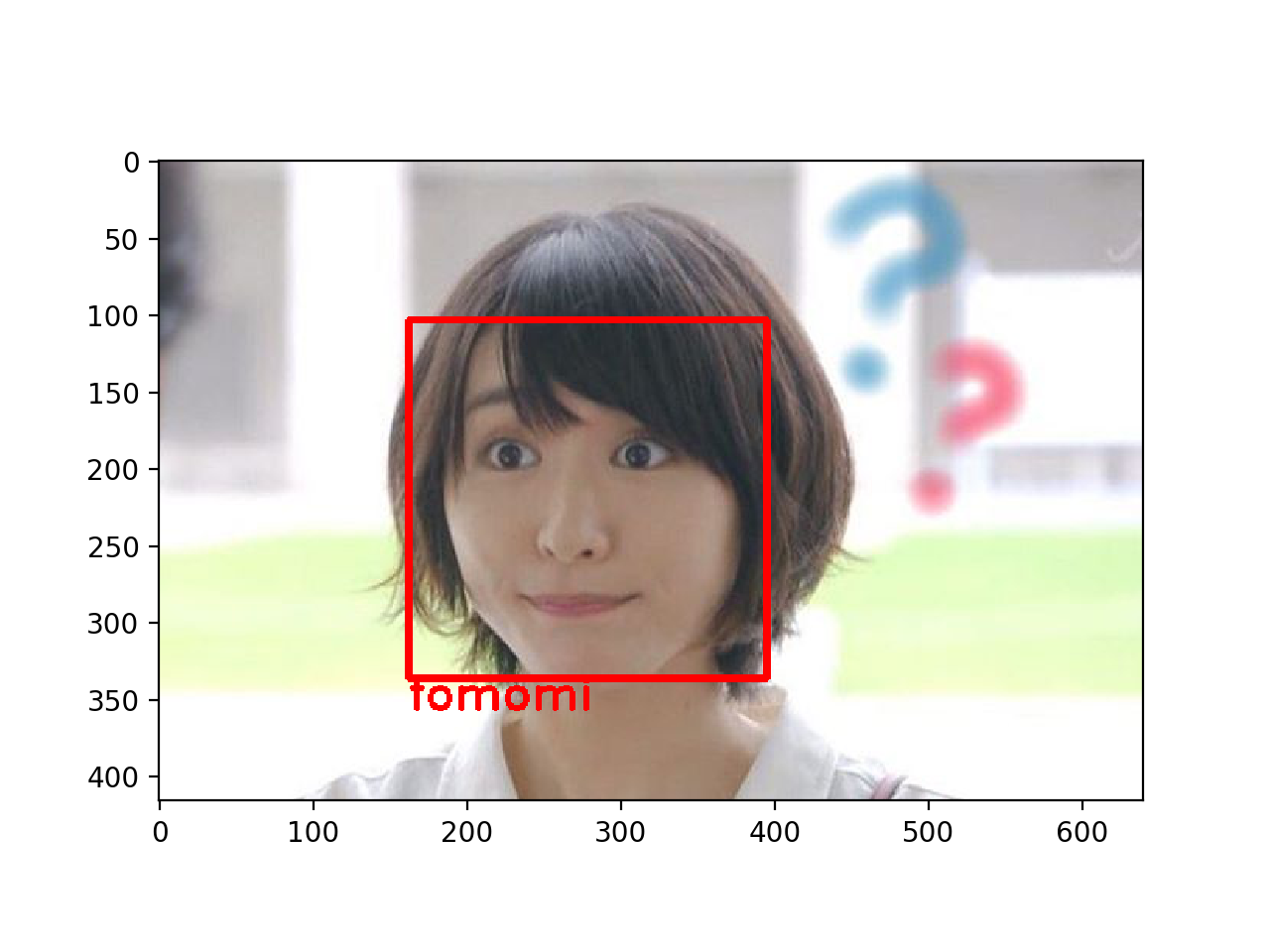
データ量を増やす必要がありそうです。モデルを少し複雑にして似ている顔をしっかり判別するのも効果的でしょう。
カメラを使ってテスト
画像と同様に、カメラから読み込まれるフレームから顔を検出し、学習したモデルから顔を判別する仕組みです。
MacBook Proがインカメラなので反転させて表示するようにしています。アウトカメラの場合は反転処理の部分をコメントアウトして実行してください。
# befor
# 画像の反転
frame = cv2.flip(frame, 1)
# after
# 画像の反転
# frame = cv2.flip(frame, 1)
import cv2
import numpy as np
from keras.models import load_model
# カテゴリ名
category = ["yui",
"tsubasa",
"tomomi",
"maki",
"kasumi"]
# 読み込むモデル
in_model = "gakky_model_15.h5"
# 画像サイズ
image_size = 60
try:
model = load_model('./' + in_model)
except OSError:
print('エラー:./' + in_model + 'が見つかりません。')
exit()
# カメラを開始
cap = cv2.VideoCapture(0)
# 分類器の指定
cascade_file = "haarcascade_frontalface_default.xml"
cascade = cv2.CascadeClassifier(cascade_file)
def window_fullscreen(frame):
cv2.namedWindow('screen', cv2.WINDOW_NORMAL)
cv2.setWindowProperty('screen', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
cv2.imshow("screen", frame)
def detect_who(face_image):
# 結果を格納
result = model.predict(face_image)[0]
# 一番可能性の高い配列の添字を返す
predicted = result.argmax()
percentage = int(result[predicted] * 100)
# カテゴリ名と確率を表示
print("{0} ({1})%".format(category[predicted], percentage))
return category[predicted]
# 繰り返しカメラ画像を確認
while cap.isOpened():
ok, frame = cap.read()
if not ok: break
# 画像の反転
frame = cv2.flip(frame, 1)
face_list = cascade.detectMultiScale(frame, scaleFactor=1.2, minNeighbors=2, minSize=(10, 10))
# 顔が検出された
if len(face_list) > 0:
# 顔の数だけループ
for rect in face_list:
x, y, width, height = rect
face_image = frame[rect[1]:rect[1]+rect[3], rect[0]:rect[0]+rect[2]]
if frame.shape[0] < 400:
continue
face_image = cv2.resize(face_image, (image_size, image_size))
face_image = np.expand_dims(face_image, axis = 0)
name = detect_who(face_image)
cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2] + rect[2:4]), (0, 0, 255), thickness = 3)
cv2.putText(frame, name, (x, y + height + 20), cv2.FONT_HERSHEY_DUPLEX, 1, (0, 0, 255), 2)
window_fullscreen(frame)
if cv2.waitKey(1) == 27: break
cap.release()
cv2.destroyAllWindows()
デスクトップにフルスクリーンでウインドウが表示され、カメラが再生されます。
~~まわりにそっくりと思わしい人が見つからないので、~~中国のガッキーそっくりさん(@lializiko)の画像を使って試していきましょう。
若干有村架純に似てるってのも分かるような分からないような...笑
4人でも全然問題なし
ちなみに私の顔を判別した結果、新垣結衣に似ていると表示されましたとさ((