この記事はなに?
データ基盤を構築する上で、必ず出てくるのがデータ転送処理。
今回は、Treasure Dataが提供しているワークフローエンジンのdigdagとデータ転送ツールのembulkを用いて、Google Cloud PlatformのGoogle Compute Engine(GCE)インスタンスに、ETL基盤を構築するまでの過程をまとめてみました。
あくまで個人の勉強用の規模のため、実務で利用する場合はセキュリティなどを考慮していただく必要があることをご了承ください。
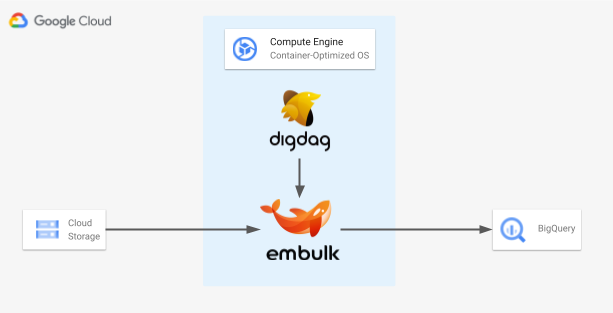
構成図とゴール
Container-Optimized OSのGCEインスタンスを立て、その中でdigdagとembulkのコンテナを起動させ、同じプロジェクト内のGoogle Cloud Storage(GCS)に保存しているCSVファイルをもとに、BigQueryにテーブルを生成するところまでをゴールとします。
GCEのContainer-Optimized OSは、予めコンテナの実行に適した環境を用意してくれているため、サクッと試すにはとても便利なOSです。
GCEのインスタンスを作成
基本的にはデフォルトの設定をいじらず、費用もかけたくなかったためこちらの情報をもとにインスタンスを作成しました。
| 項目 | 値 |
|---|---|
| 名前 | etl-practice-instance |
| リージョン | us-central1(アイオワ) |
| シリーズ | E2 |
| マシンタイプ | e2-micro(2 vCPU、1GBメモリ) |
| OS | Container Optimized OS |
| バージョン | Container-Optimized OS 85-13310.1453.1 LTS |
| ブートディスクの種類 | 標準永続ディスク |
| サイズ | 10 |
ローカルからssh接続
ローカルPCにCloud SDKをインストールし、gcloudコマンドを使って先程作ったインスタンスにsshで接続します。
※ブラウザウィンドウでも接続はできるので、この辺はお好みで。
$ gcloud compute ssh --zone "us-central1-a" "etl-practice-instance" --project "{{GCPのプロジェクト名}}"
# 作業用のディレクトリを作成しておく
$ mkdir etl-practice
$ exit
サービスアカウントの作成
embulkを通してGCSからBigQueryにデータを転送するため、それぞれのサービスを参照する権限を持つサービスアカウントを作成しておきます。
本来は必要最小限の権限を付与するべきですが、今回は勉強用のため、サービスアカウントに対してIAMにてストレージ管理者とBigQuery管理者の権限を付与しました。
また、embulk実行時に認証で必要になるため、JSON形式で認証鍵をダウンロードしておきます。
必要なファイルを揃える
GCEインスタンス内で作業をしてもいいのですが、キー入力後のレスポンスが若干遅いので、先にローカルで必要なファイルを揃えた上で、GCEインスタンスに転送することにします。
サンプルCSV
id, name
1, taro
2, jiro
3, saburo
作成したら、GCSにアップロードしておきます。
Dockerfile
FROM openjdk:8-jre-alpine
# embulk
RUN wget -q https://dl.embulk.org/embulk-latest.jar -O /bin/embulk \
&& chmod +x /bin/embulk
RUN apk add --no-cache libc6-compat \
&& embulk gem install embulk-input-gcs \
&& embulk gem install embulk-output-bigquery
# digdag
RUN wget -q "https://dl.digdag.io/digdag-latest" -O /bin/digdag
RUN chmod +x /bin/digdag
RUN echo 'export PATH="$HOME/bin:$PATH"' >> ~/.bashrc
RUN source ~/.bashrc
WORKDIR /work
余談ですが、筆者はDockerを全く触ったことがなかったため、こちらの書籍をもとに勉強しました。
すごく丁寧に解説されており、これからDockerを触る人にはオススメの1冊です。
config.yml
in:
type: gcs
bucket: {{CSVファイルをアップロードしたGCSのバケット名}}
path_prefix: {{拡張子を除いたCSVファイル名}}
auth_method: json_key
json_keyfile: {{サービスアカウントのJSON鍵ファイル}}
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
header_line: true
columns:
- {name: id, type: long}
- {name: name, type: string}
out:
type: bigquery
mode: replace
auth_method: service_account
json_keyfile: {{サービスアカウントのJSON鍵ファイル}}
project: {{GCPのプロジェクト名}}
auto_create_dataset: true
dataset: etl_practice
table: sample_data
各プラグインの詳細は、下記をご参照ください。
embulk-gcs-input
embulk-bigquery-output
etl.dig
timezone: "Asia/Tokyo"
+task1:
sh>: embulk run config.yml
今回の挑戦で初めてdigdagを(というかワークフローエンジンを)触りました。
この辺は、まだまだ勉強中です。。。
ローカルからGCEに、ファイルをアップロード
gcloud compute scpコマンドを利用して、先程作成したファイルをGCEインスタンスにアップロードします。
コマンドに関する詳しい情報は、こちらをご参照ください。
# 転送するファイルは
# Dockerfile
# config.yml
# etl.dig
# サービスアカウントのJSON鍵ファイル
$ gcloud compute scp --project "{{GCPのプロジェクト名}}" --zone "us-central1-a" --recurse {{ファイルパス}} {{GCPのユーザー名}}@etl-practice-instance:/home/{{GCPのユーザー名}}/etl-practice
コンテナを起動してETL処理を実行
必要な準備がすべて完了したため、ここからは実際にコンテナを起動させ、GCSからBigQueryへのETL処理を実行してみます。
# ローカルからGCEインスタンスにsshで接続
$ gcloud compute ssh --zone "us-central1-a" "etl-practice-instance" --project "{{GCPのプロジェクト名}}"
# 作業用ディレクトリに移動
$ cd etl-practice
# Dockerfileをもとに、コンテナイメージを作成
$ docker build -t etl-image .
# コンテナイメージが作成されているかを確認
$ docker image ls
# コンテナイメージをもとに、コンテナを起動
$ docker run -it -v $PWD/:/work etl-image
# digdagを実行
$ digdag run etl.dig
BigQueryにアクセスし、etl_practiceデータセットにsample_dataテーブルができていれば成功です。
お疲れさまでした!
おまけ
ワークフローエンジンなのに手動実行で終わってしまってはなんだか味気ないので、etl.digファイルを修正して簡易的なスケジュール実行をしてみます。
etl.dig
timezone: "Asia/Tokyo"
schedule:
# 例えば毎日AM01:30に実行させたければ、 30 1 * * *
cron>: {{cron形式でスケジュール実行させたいタイミングを記載}}
+task1:
sh>: embulk run config.yml
$ digdag scheduler
cronで指定したタイミングになると、digdagがetl.digファイルのタスクを実行してくれます。
おわりに
この挑戦をする前の筆者は、digdagやembulkがどんなツールかは理解していたものの、使い方やそれ自体を動かすにはどうすればいいかが全くわからない状態でした。
しかし、データエンジニアを目指す身としてどうしても自力でETL基盤を構築してみたく、他社様のデータ基盤の事例を拝見しながら、Dockerで動かせることを知り、Dockerの基礎を身に着け、digdagとembulkの使い方を学び、最終的には実際にETL基盤を構築することができました。
実際にそれなりの規模で実装するのであればGoogle Kubernetes Engine(GKE)上で動かしたり、セキュリティやシステム構成などもしっかり考える必要があるなど、まだまだ勉強すべきことは沢山あるため、今回の挑戦で終わるのではなく、これがデータエンジニアになるための第一歩として、これからも勉強を続けていきます。
ここまで読んでくださりありがとうございました!