はじめに
BERTをはじめとする昨今のディープラーニングによる主流な自然言語処理の多くは、Transformerというモデルを構成要素(ビルディングブロック)にしているため、Transformerの理解は避けては通れないのであるが、このTransformer自体が難解であり、さらにCNNやRNNではなく、Attentionという仕組みを構成要素としていることが、私を含めディープラーニングの初学者の理解を難しくしているのではないかと思われる。
そこで、本記事では、Transformerの要点だけを、なるべく平易かつ直感的に説明したいと思う。直感的な理解を目的とするため、数式は使わないので、全体の流れがつかめたら、本家の論文や他の素晴らしい記事を見て理解を深めて頂きたい。
本家の論文は以下。
Attention Is All You Need
※内容については、誤っている箇所が多分にあると思われるので、ご指摘頂けると幸いです。
前提知識
分散表現
単語を高次の実数ベクトルとして扱うこと。ベクトルの各次元は、それぞれの属性(特徴)を表す。埋め込み層に単語(一意なidで区別)を渡すことにより、分散表現(ベクトル表現)に変換する。

例)
リンゴ
赤い 0.8 甘い 0.7 丸い 0.5 ・・・
単語をベクトル化することで、例えば単語間で以下のような演算が出来るようになる。
- 「王様」-「男性」+「女性」=「女王」
本記事で扱うタスク
以降、本記事では以下の英語→日本語の翻訳タスクを考える。
- 入力:This is an apple
- 出力:これはリンゴです
Attention
queryとmemory
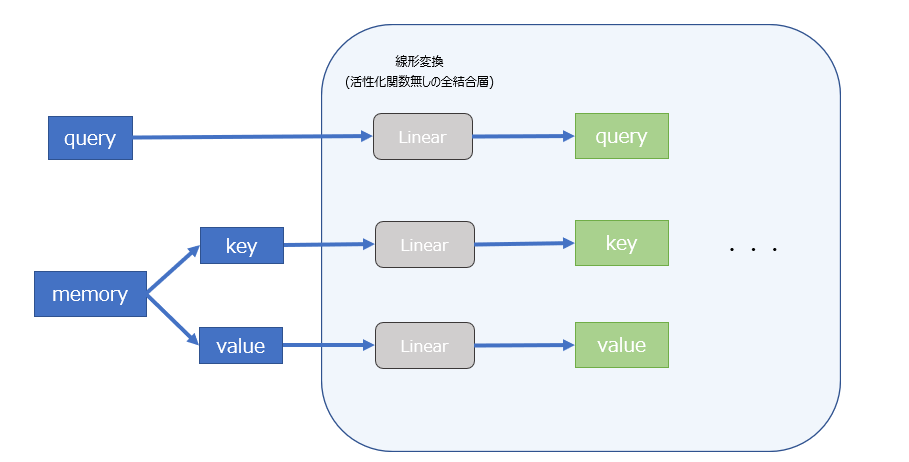
Transformerで使用されるAttentionには、queryとmemoryと呼ばれる2つの入力が存在する。それぞれ以下を指す。
- query: 入力となる文章。(出力を得るための「問い」)
- memory: 内部状態としての文章。 (過去の「記憶」として保持している文章)
要は、Attentionにqueryを入力すると、queryに対する出力が得られるのだが、得られる出力はその時の内部状態(memory)によって変わるということである。
memoryは処理の際にkeyとvalueという2つの値に分けて扱われるが、元は同じ文章である。
ただし、query, key, valueは単語ベクトルをそのまま操作するのではなく、事前に全結合層で線形変換された上で処理される。(この際に行われる変換がkeyとvalueで異なるため、内部的にはkeyとvalueは異なる値になる。)
以降、query, key, valueは、それぞれ変換済みの内部表現を指すものとする。
attention weight
Attentionとは「注意」という意味通り、queryの各単語が、memory(key)のどの単語に注目するべきかを数値化したものである。
より厳密には、keyの各単語との類似度に応じて、単語間の関連を0から1の実数(重み)で表す。また、keyのすべての単語に対するweightの和は1になる。(Softmax)
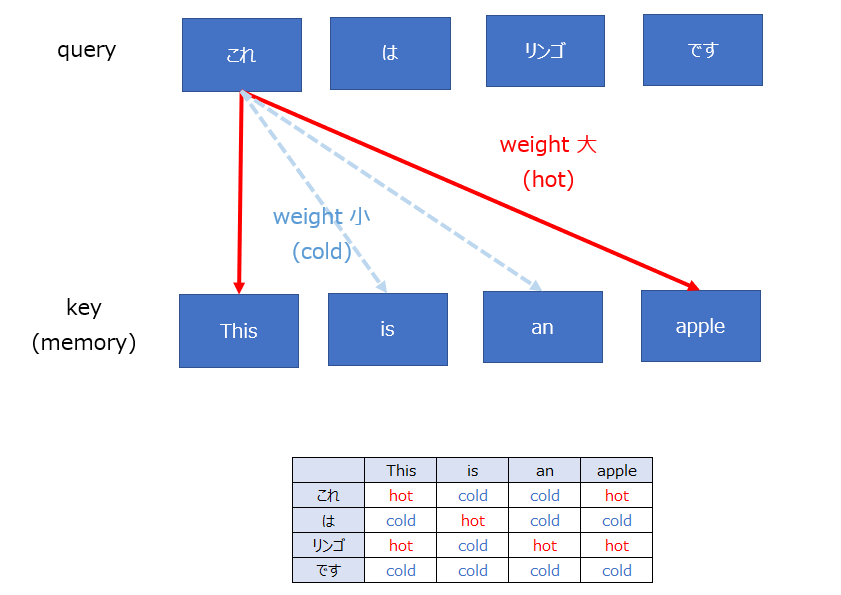
本記事では、以降weightの値が大きい(小さい)ことをhot(cold)であると表現することにする。
論文中では、単語間の類似度の評価にベクトルの内積を用いている。そのため、内積の値が大きい(ベクトルの向きが近い = 単語の意味が似ている)ほど、その単語との間のattention weightの値が大きいことになる。(内積Attention)
Attentionの出力
Attentionの出力は、着目しているqueryとmemory(key)の各単語と間のattention weightを、memory(value)に乗じた上ですべて加算したものとなる。つまり、memory(value)の全ての単語のattention weightの加重平均である。
出力もベクトルであるため、何かの単語(と同じ次元を持つ情報)である。
図で示すと以下の通りである。
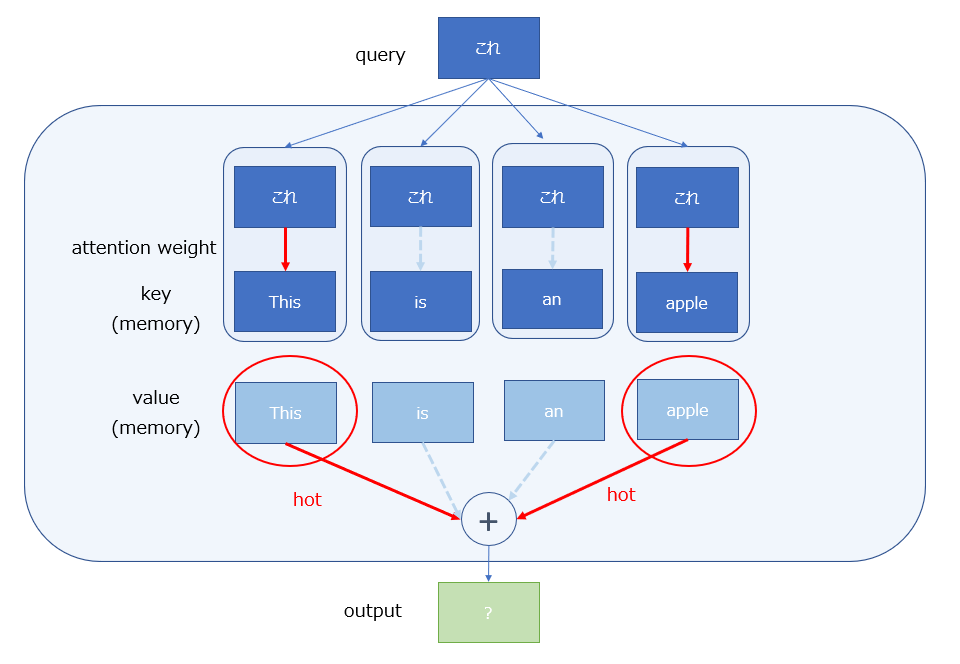
この例では、「これ」というqueryに対する出力には、「this」 と 「apple」の要素が割合として多く含まれることになる。
ここで注意すべき点は、出力はkeyに対してではなく、valueに対してattention weightを乗じた合計になるということである。
このように、keyとvalueは同じmemoryから派生した情報であるが、それぞれ役割が異なっており、keyはqueryとの関連度の評価(weightの計算)に、valueは実際の出力の計算にそれぞれ用いられる。
Attentionの使い方
Attentionの使い方にはSelf-AttentionとSource-Target Attentionの2つがある。
また、Self-Attentionのオプションとして、訓練時のカンニングを防止するためのMasked Self-Attentionという仕組があり、それについても合わせて説明する。
Self-Attention
Attentionの入力において、queryとmemoryが同じ文章となるケース。
代名詞が何を指しているか、形容詞がどの名詞の状態を表しているか、など、文章の単語間の関係性(係り受け)を解釈するために用いられる。
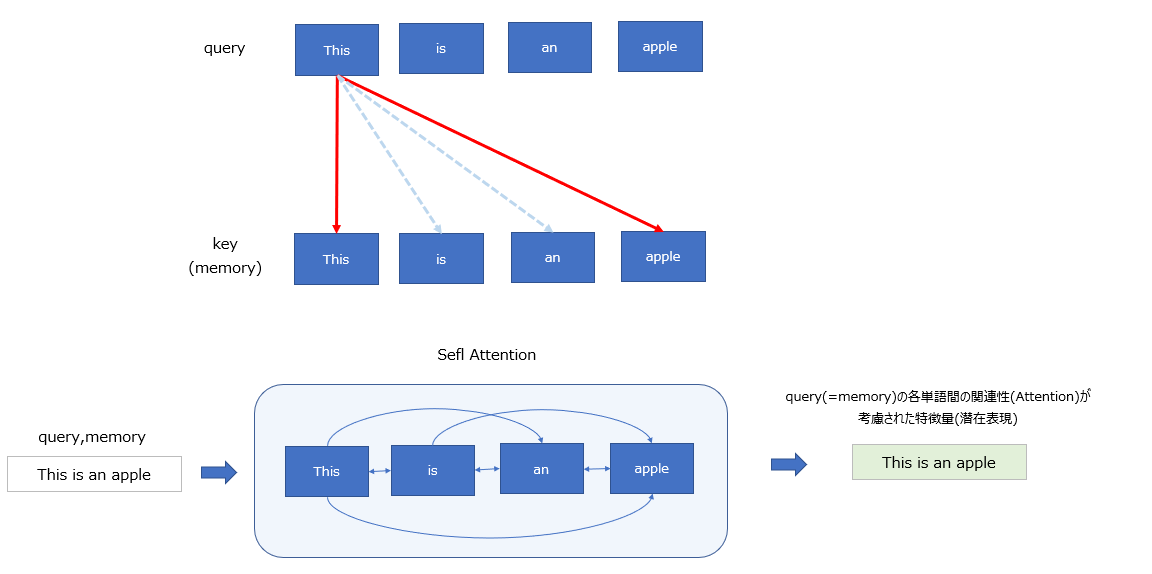
出力として、query(=memory)の各単語間の関連性(Attention)が考慮された特徴量(潜在表現)が得られる。
Masked Self-Attention
後述するが、Transformerのデコーダの役割は、入力された文章に対する応答文を、一単語ずつ順番に予測することである。
- デコーダ入力:これ は
- デコーダ出力:これ は リンゴ
Self-Attentionの仕組みは、デコーダにおいても、入力文の単語間の関連性を理解するために使用される。しかし、学習時には、正解データとして応答文の全体(「これはリンゴです」)が与えられるため、そのままSelf-Attentionを適用すると、現時点での予測結果(「これ」「は」)と未来の予測結果(「リンゴ」「です」)とのAttentionを評価してしまうというカンニングが発生する。
これを防ぐため、訓練時に未来の単語についてはSelf-Attentionの計算対象外とする仕組みが導入されており、これがMasked Self-Attentionである。
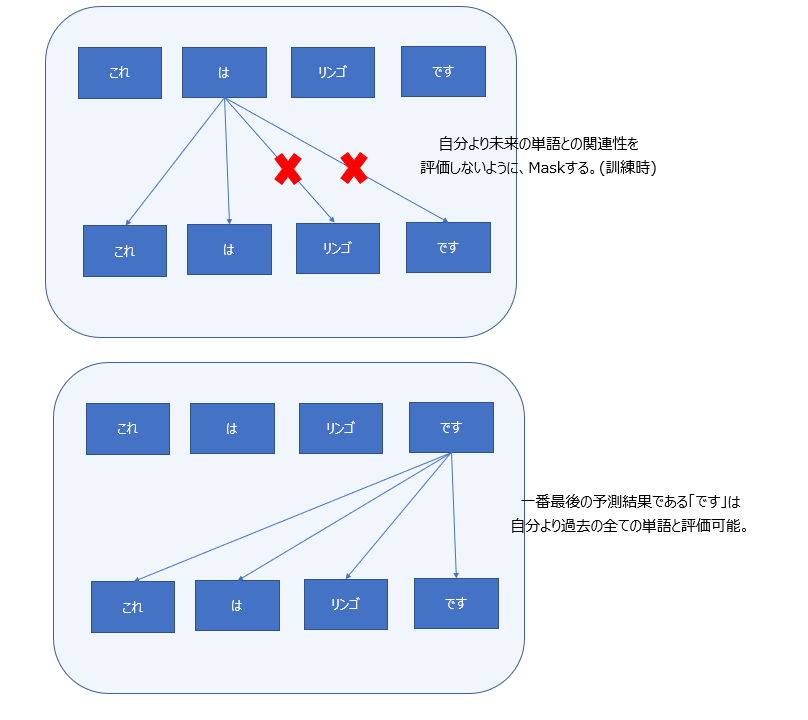
実際には、未来の単語とのweightを0にすることで実現されている。
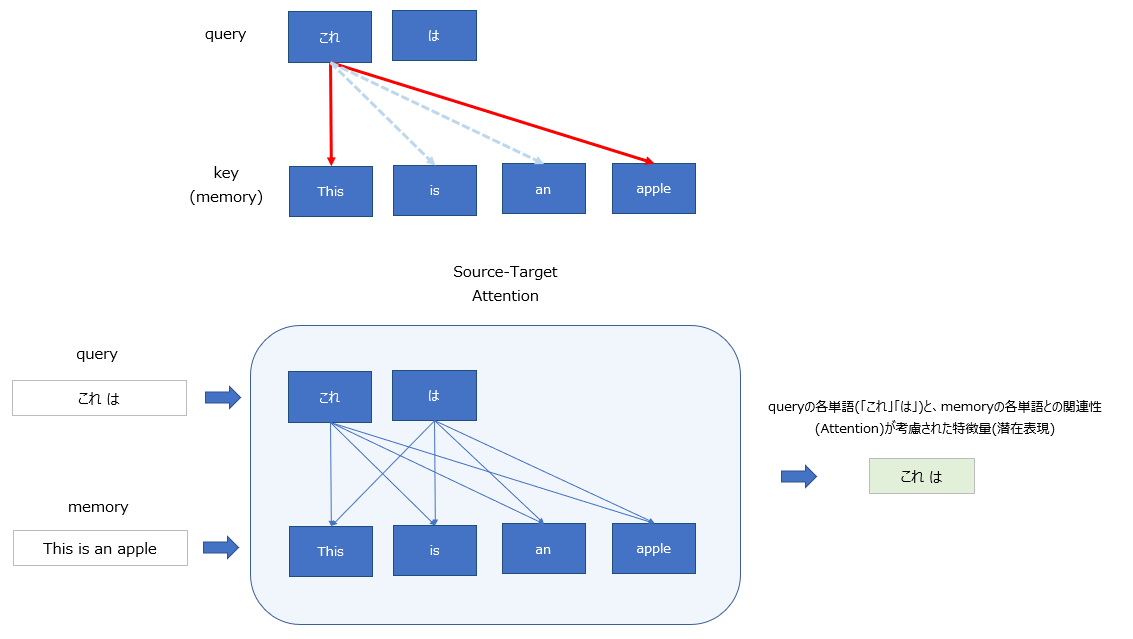
Source-Target Attention
Attentionの入力において、queryとmemoryが異なる文章となるケース。
こちらは、内部状態(memory)に応じて、入力(query)に対応する出力を生成するために用いられる。
Transformerのその他の構成要素
ここまでで、Transformerの主要な構成要素であるAttentionについて説明を行ったが、ここではその他の構成要素について簡単に述べる。
Multi Head Attention
Attentionの入力である単語ベクトルを、次元数の方向に複数分割してAttentionの計算を並列化実行し、最後に分割したベクトルを連結するというものである。処理の並列化による効率改善が目的であるが、役割としては通常のAttentionと同様であるため、詳細については割愛する。
Embedding層
単語を単語ベクトルに変換するための辞書(埋め込み行列)である。単語(IDで一意に識別)を分散表現に変換するための層であり、論文では事前に学習済みのものを用いている。
Positional Encoding層
Attention自体は、各単語の順番に関する時系列の情報を考慮することが出来ない。例えば、以下の2つの文章のSelf-Attentionの評価結果は同じになってしまう。
- ペン は 剣 より も 強 し
- 剣 は ペン より も 強 し
これは、Attentionが「ペン」と「剣」の位置の違いを考慮できていないためである。この問題を克服するために、単語の出現位置に応じた情報を、ベクトルの各要素に加算することによって、位置に関する情報を付加しているのがPositional Encoding層である。
出力層(Linear, SoftMax)
Transformer全体の出力層に相当する部分である。
デコーダからの出力が出力層への入力となり、デコーダからは入力文と現時点まで予測されたの応答文との関連性(Attention)を考慮した特徴量が与えられる。出力層では、それらの情報から応答文の次の単語を予測する必要がある。
- 現時点までの応答文の予測: これ は
- 入力文: This is an apple
- 次の予測結果: これ は リンゴ
上記の通り、出力層では最終的に「リンゴ」という単語を予測する必要があるが、その入力はデコーダから得られた潜在表現であり、単語ベクトルの次元数となっている。
そのため、出力層では、Linear層の重みにデコーダの入力部分のEmbedding層と同じ重みを使用することで、単語ベクトルから該当する単語への変換に利用している。
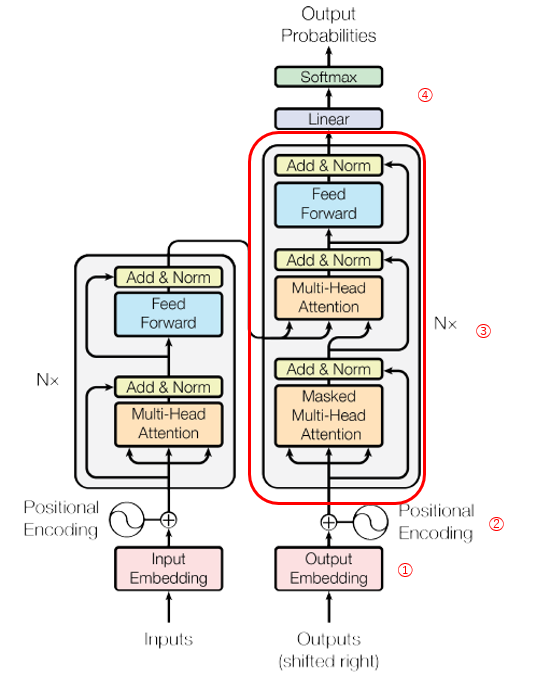
Transformer全体の処理の流れ
エンコーダの処理
ここまでの情報を踏まえて、まずエンコーダ全体の流れを俯瞰してみる。
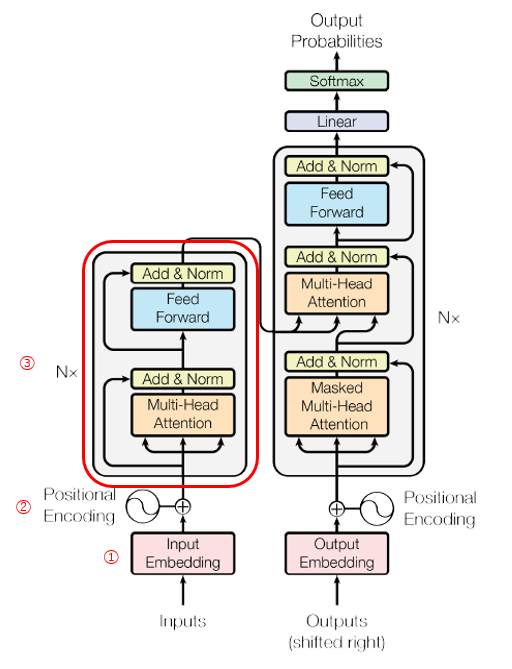
まず、エンコーダの入力は、「This is an apple」という文章であるが、最初にEmbedding層により、それぞれの単語を単語ベクトルに変換する。(①)
つづいて、Positional Encoding層により、各単語ベクトルに、単語の出現位置に応じた時系列の情報を付加する。(②)
そして、ここからがエンコーダのメイン部分であるが、その内容はSefl-Attentionと全結合層(Feed Forward)とのN回の繰り返しである。(③)
まず、Sefl-Attentionで入力文の単語同士の関係を解釈し、その後の全結合層でより本質的な特徴量に変換するという処理を複数回繰り返している。
(この際、skip connectionを使用することで、各層での処理前の情報を引きついでいる。)
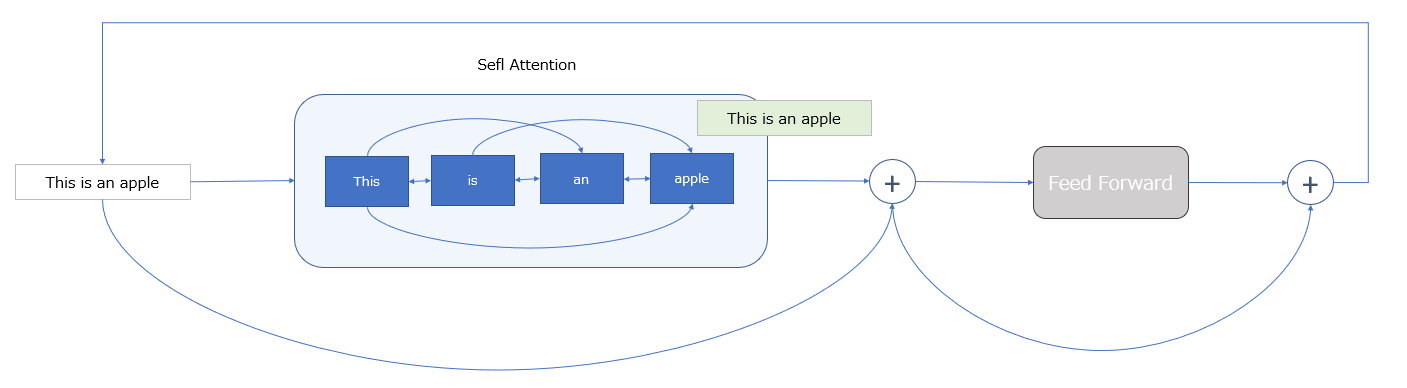
この繰り返しの処理により、エンコーダの出力は、「入力文の単語間の関係を考慮した潜在表現」となる。
デコーダの処理
続いて、デコーダ全体の流れを俯瞰してみる。
Embedding層、Positional Encoding層については、エンコーダと同様である。(①、②)
デコーダのメイン部分(③)の構造については、最初にデコーダの入力(現時点までで予測した応答文)の単語間の関連性を把握するためのSelf-Attention層がある。(エンコーダと異なり、訓練時のカンニングを防ぐため、Masked Self-Attention層となっている。)
続いて、Source-Target Attention層が来るが、もう一つの入力(memory)としてエンコーダからの出力を受けとり、Self-Attention層を通過してきたデコーダの入力(query)とのAttentionを計算している。
さらに、後続の全結合層(Feed Forward)を通して特徴量を得るという処理を複数回繰り返し、デコーダの出力としての潜在表現を得ている。
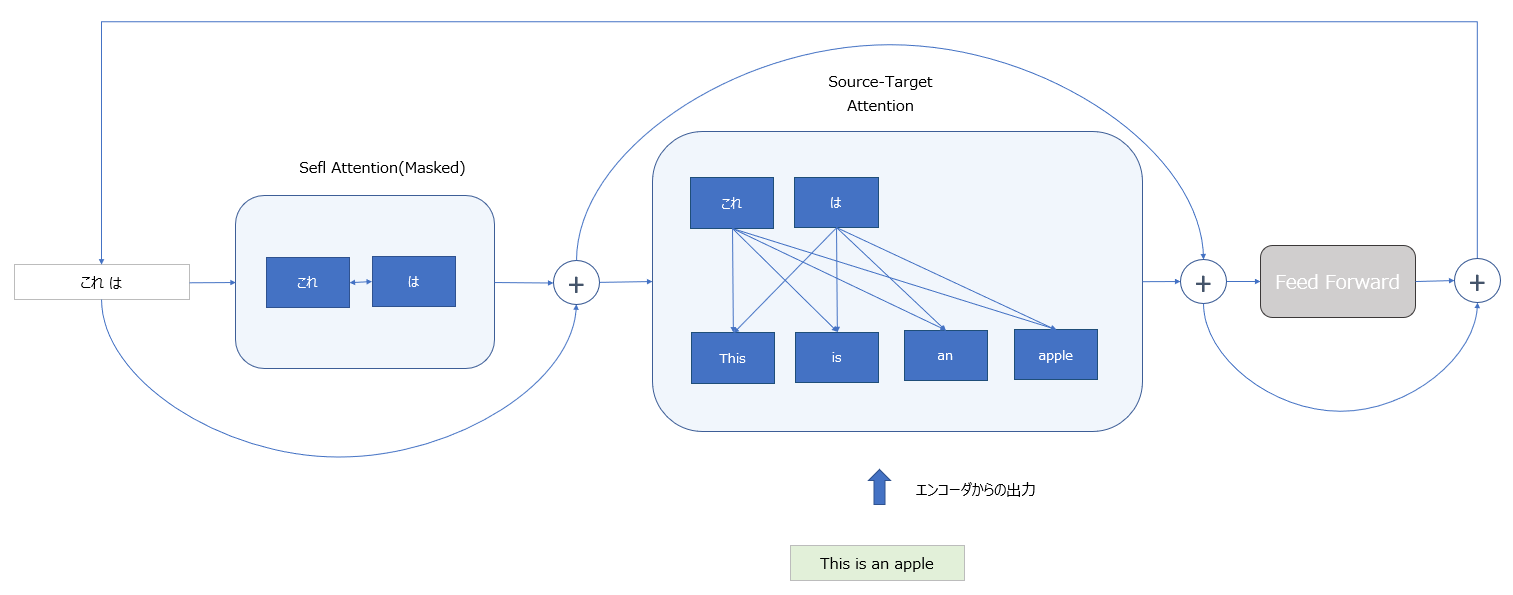
デコーダの出力は、「エンコーダからの出力と、現時点までの応答文の予測とを入力として、それぞれの単語間の関係を考慮して獲得した潜在表現」となる。
そして、その後に出力層があり、Embedding層で使用したものと同じ重みを使用して、デコーダの出力として次の単語の予測を行っている。(④)
考察
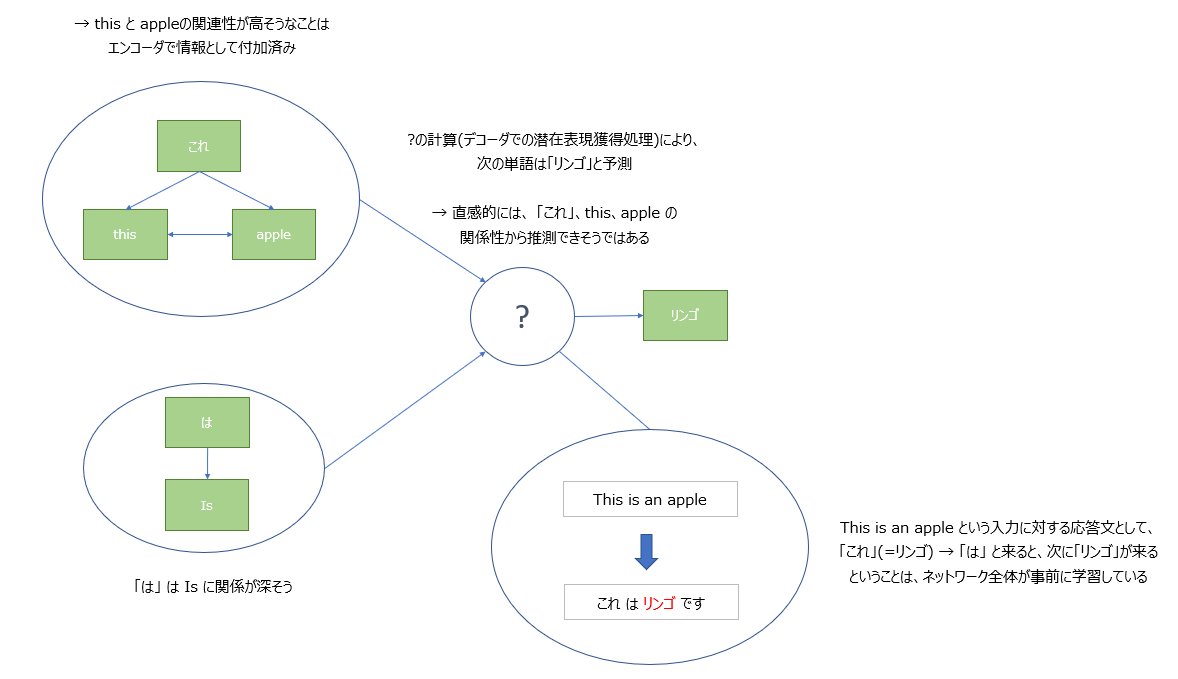
ここまでで、Transformer全体の流れを追ってみたが、最後になぜデコーダの処理で応答文の次の単語の予測が可能であるかを考察してみる。
まず、エンコーダでのSelf-Attentionの処理で、「this」と「apple」の関連性が高いことは特徴量に含まれている。
続いて、デコーダでのSource-Target Attentionの処理で、「これ」という単語と「this 」という単語の関連性が高いことが情報として付加されるが、「this」と「apple」の関連性も高いことが事前にわかっているため、間接的に「これ」と「apple」の関連性も高いことがわかる。
続いて、デコーダの処理を通して次の単語が「リンゴ」であることが予測されないといけないが、「これ」、「this」、「apple」の関連性の情報と、事前に学習された結果から、「これ(=apple)」、「は」とくると、次に来るべき単語が「リンゴ」であるということが予測できるということは、直感的に理解できるように思える。