はじめに
令和にもなるとSQLを2行書くだけで機械学習できてしまうようです。本記事では、表題の技術BigQuery MLの概要と使い方を調べ、世を騒がせているコロナの分析をしてみました。
「SQLで機械学習」や「コロナ分析」に興味がある方は覗いてみてください。
本記事の対象者
- SQLだけで機械学習したい人
- コロナ分析に興味ある人
- 機械学習を簡単に試してみたい人
- 機械学習はよく分からんけどデータベースはよくいじるという人
本記事の対象でない人
- データとか機械学習とか難しいから興味ない人
- 機械学習モデルのアルゴリズムとか詳しく知りたい人
- 機械学習つよつよだから自分で独自モデル作って幅広い分析したい人
BigQuery ML概要
BigQueryとは
BigQuery MLはBigQuery上のサービスです。BigQueryを知らない方のために簡単にBigQueryについて説明します。BigQueryはGoogleが提供するクラウドデータウェアハウスです。データウェアハウスとは、簡単に言うとデータ分析に特化したデータ管理プラットフォームです。BigQueryの特徴は以下のようなものが挙げられます。
- 列型アーキテクチャによる高速処理
- 柔軟で安価な料金体系
- データ分析・可視化への親和性
本記事では「BigQueryはSQLでビッグデータを操作するプラットフォームである」とだけ分かっていれば十分です。
BigQuery MLとは
BigQuery MLとは、BigQuery上で機械学習(Machine Learning)を簡単に実行できるサービスです。機械学習のプロセスには学習、評価、予測などの工程がありますが、BigQuery MLを使えばこれら全てをSQLのみで実行することができます。
また、通常の機械学習のプロセスはモデルに対してデータを入出力するモデルドリブンですが、BigQuery MLはデータを管理するデータウェアハウス上に機械学習モデルを作成するデータドリブンです。それゆえ、BigQuery MLはデータベース上のNULLデータを埋める用途で使うのに適しています。
データウェアハウスやデータベースではNULLデータは厄介な存在です。データベースの重要な列にNULLデータが含まれてしまっていると、思ったような分析ができなかったり算術や条件文でNULLが思わぬ動きをしたりします。NULLを忌み嫌うデータベース技術者は多く、NULL撲滅委員会なる組織1があるほどです。
BigQuery MLは、NULLを憎むデータベース技術者の役に立てるかもしれません。
BigQuery MLのメリット
BigQuery MLのメリットは以下の3つです。
- 機械学習がSQLだけで非常に簡単にできる
- BigQueryを通して全ての機械学習操作が可能
- 多様なインタフェースから利用できる
それぞれの特徴について説明します。
①機械学習がSQLだけで非常に簡単にできる
BigQuery MLを用いればSQLを2行追加するだけでサッと機械学習することが可能です。例として、テレワークをするかどうかの二値分類を予測する機械学習モデルを作成するSQLを見てみます。題材は適当に考えたものなので実データとかはありません。
CREATE OR REPLACE MODEL 'telework_model'
OPTIONS (model_type='logistic_reg') AS
SELECT
telework_flag AS LABEL, #テレワークフラグ
weather, #1. 天気
temperature, #2. 気温
motivation, #3. 仕事のモチベーション
amount_of_work, #4. 仕事量
number_of_meetings, #5. 会議の数
loneliness #6. 孤独感
FROM
`daily_data`
初めの2行がBigQuery MLで機械学習モデルを作成するためのSQL文です。SELECT句からFROM句はほとんど通常のSQL文と同じであることが分かると思います。通常のSQL文と違うのは予測したい目的変数にLABELと名前を付けることだけです。
1から6までナンバリングした変数が説明変数、つまり目的変数であるテレワークフラグの値の原因となりうる変数群です。天気が悪かったり会議の数が少なかったりしたらテレワークフラグが1になりやすいし、気温が快適だったり孤独感にさいなまれていたりしたらテレワークフラグが0になりやすいといった具合です。
2行目のOPTIONS句では作成する機械学習モデルに関するオプションが指定できます。BigQuery MLではOPTIONS句のmodel_typeで機械学習モデルを指定することで様々な機械学習モデルを作成することができます。現在(2020年10月)、BigQuery MLで使用することができる機械学習モデルは以下のようなものがあります。今後も追加されていくかもしれません。
| モデル名 | 概要 | 例 |
|---|---|---|
| 線形回帰 | データパターンに当てはまる線を書く | 商品の売上予測 |
| ロジスティック回帰 | データを複数に分類する | 顧客が商品を購入するかどうか予測 |
| K平均法クラスタリング | データをいくつかのグループに分ける | 顧客を特性ごとに分類 |
| 行列分解 | ユーザ×アイテムの行列使ったレコメンド実装 | 顧客への商品レコメンデーション |
| 時系列(ARIMA) | 時系列に沿った数値の予測 | 日毎の顧客数の予測 |
| XGBoost | ブースティング+決定木アルゴリズムによる汎用モデル | 売上予測、顧客分類等 |
| DNN | 多層ニューラルネット(ディープラーニング) | 売上予測、顧客分類等 |
| AutoML Tables | 特徴量エンジニアリングやモデル選択が不要の機械学習ツール | 売上予測、顧客分類等 |
| TensorFlow独自モデル | TensorFlowで作成した訓練済みモデルによる予測 | CNNによる画像認識等 |
TensorFlowモデルだけはBigQuery ML上で学習や評価をすることはできないので、あらかじめ訓練済みモデルを用意しておく必要がある点には注意してください。
②BigQueryを通して全ての機械学習操作が可能
従来の機械学習プロセスでは、データ管理、データの前処理、モデル作成、モデル学習、予測、データ可視化までをエンジニアが個別に行っていました。それぞれのプロセスに対応するプログラムを書いたりデータを個別に管理したりする必要性があったため非常に煩わしい工程でした。
BigQuery MLではこれらの煩わしかった作業をすべてBigQuery上で完結できます。データウェアハウスであるBigQueryでデータもモデルも管理できてしまうので、煩わしいデータ移動やプロセスが不要になります。
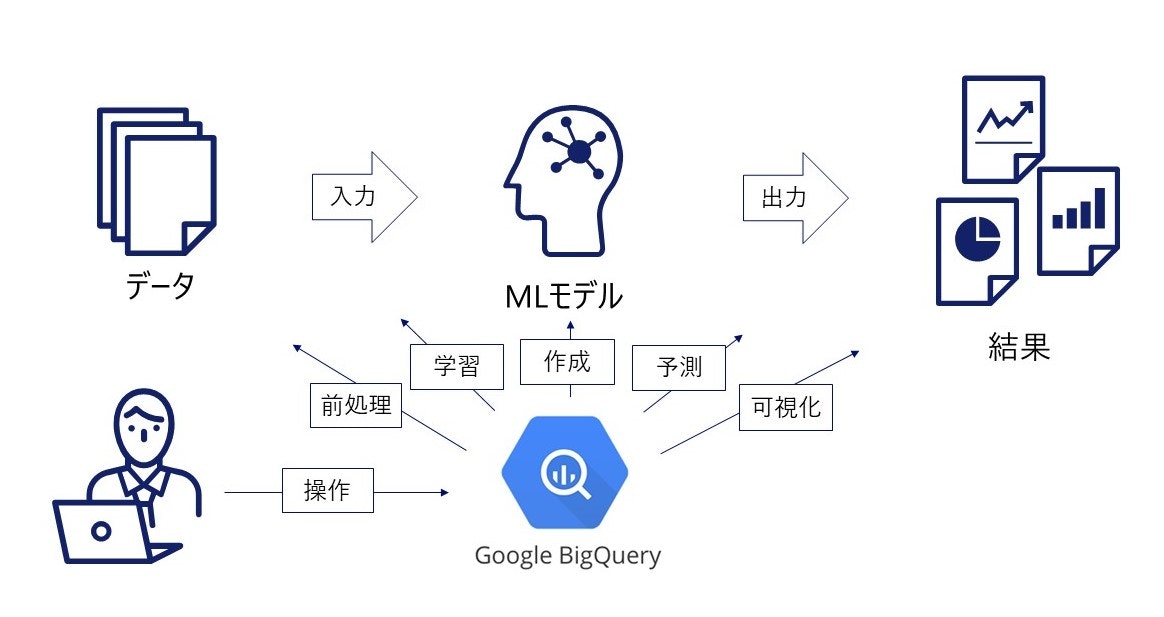
③多様なインタフェースから利用できる
BigQuery MLでは以下のインタフェースから操作が可能です。
- BigQuery Web UI
- bqコマンドラインツール
- BigQuery REST API
- Jupyter Notebookなどの外部ツール
Web UIから外部ツールまで、非常に様々なインタフェースをサポートしています。お好みのインタフェースを介して簡単にデータ分析・機械学習を行うことができます。
BigQuery MLの活用事例
実際の業務でどのようにBigQuery MLが使われているのかイメージをつかんでもらうためにいくつかの導入事例を紹介します。
Heast Newspapers社2
Heast Newspapers社ではいくつものWebメディアを運営しており、Webメディアの解約予測にBigQuery MLを用いています。Heast Newspapers社はWebメディアに関する多くのデータセットを既にBigQuery上にストアしていたため、データをBigQueryから出し入れせずに機械学習が可能なBigQuery MLの導入に至ったそうです。
Webメディアの運営では解約予測が重要になります。購買者を維持するためにも、解約するユーザの特徴を分析し、各ユーザに合わせた対応をする必要があります。Heast Newspapers社では、ユーザの購読期間や年齢、ウェブ行動履歴などをまとめた数年分のデータを用いて、解約するかどうかの二値分類を行いました。
BrainPad社3
BrainPad社はデータマイニング専門企業を謳っており、Rtoasterというデータマネジメントプラットフォームを自社製品として扱っています。BrainPad社は、Rtoasterのユーザ分析機能の1つである自動クラスタリングの実装をBigQuery MLに移行させたようです。
移行の結果、「インスタンス料金が高い」「一回のバッチに時間がかかりすぎる」「運用の対応が面倒」といった問題が解決しました。
BigQuery MLの料金体系
BigQuery及びBigQuery MLの料金は2020年10月時点で以下のようになっています。オンデマンド料金はリージョンによって異なるのですが、代表例として米国料金を掲載しています。
| ストレージ(BigQuery) | クエリ(BigQuery) | MLモデル作成クエリ | |
|---|---|---|---|
| 概要 | BigQueryに格納されているデータ量による料金 | SQLクエリの出力データ量による料金 | MLモデルを作成するSQLクエリの出力データ量による料金 |
| 無料枠 | 毎月10GBまで無料 | 毎月1TBまで無料 | 毎月10GBまで無料 |
| オンデマンド料金(米) | $0.020 per GB | $5.00 per TB | $250.00 per TB |
個人的に使ってみた感想ですが、個人で分析する程度の少量データなら無料枠の範疇で十分可能だと思われます。企業規模の多量データ分析も他のサービスと比べて安価なようです。
クエリ実行前に使用するデータ容量も表示されますし、料金上限を設定することもできるので安心して使うことができます。
BigQuery MLを用いたコロナ分析
データと基礎分析
「じゃあ機械学習でデータ分析をやってみましょう」といきなり言われても、何をどのようにすればいいのか分からないと思います。まずは分析のとっかかりを作るために、分析したいデータを可視化して考察し、分析の方向性や検証したい仮説を定める必要があります。
今回はBigQuery MLでコロナ分析をするということで、SIGNATE COVID-19 Datasetをメインに使わせていただきます。こちらのデータは全国の日毎の陽性者数や罹患者情報をオープンデータとしてまとめたものです。2020/8/29時点でのこちらのデータをBigQuery上のテーブルとして入力し、分析していきます。それぞれのデータとテーブル名の対応は以下です。
| 元データ名 | 本記事内でのBigQuery上のテーブル名 | 内容 | データ数 |
|---|---|---|---|
| 統計全般 | covid.general | 日毎の各種データ | 1/17~8/28のおよそ200日分 |
| 罹患者 | covid.affected_people | コロナを罹患した人の年齢や症状など | およそ60000人分 |
| 罹患者関係 | covid.relation | 罹患者通しの関係 | 4000弱 |
BigQueryではデータセットの中にテーブルや機械学習モデルを格納します。今回はcovidというデータセットを作成し、その中にすべてのテーブルやモデルを格納することにします。
操作のイメージがつくように、Web UIインタフェースを載せます。
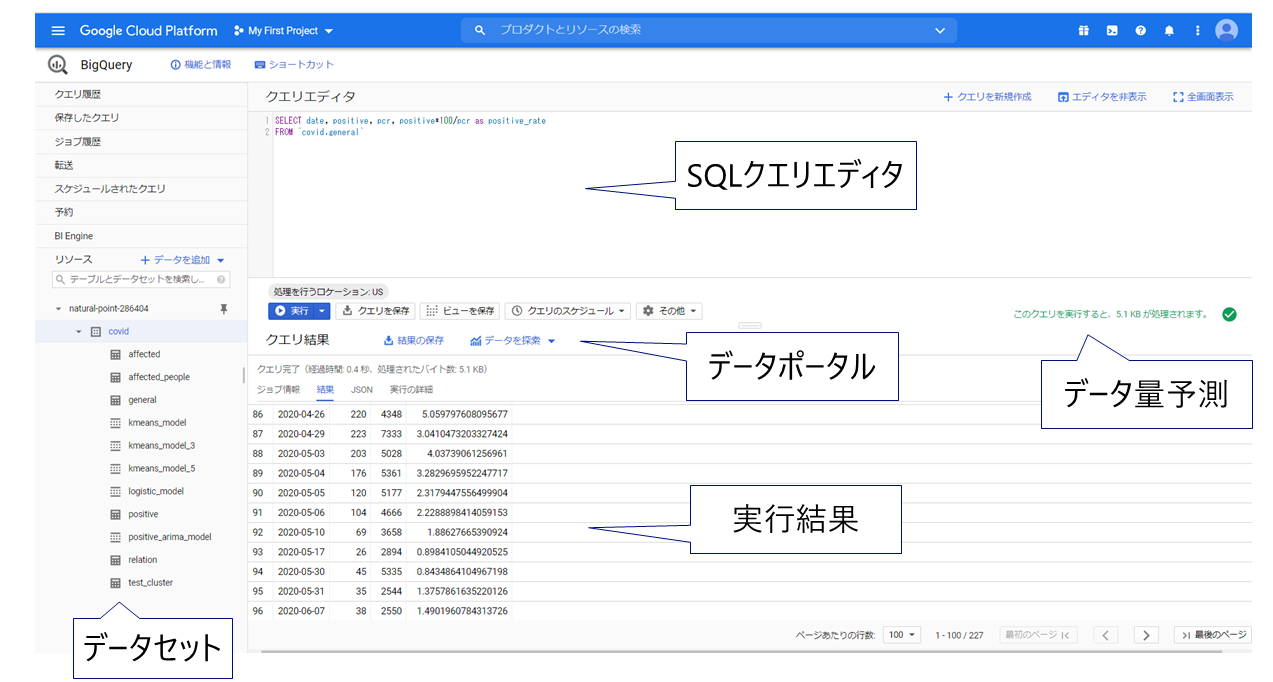
サイドバーにデータセットツリーが表示されており、データや作成したモデルはここに一覧表示されます。上部にはSQLクエリエディタがあり、ここにモデル作成クエリやモデル予測クエリを書いて実行することで下部に実行結果が表示されます。「データを探索」をクリックするとGoogle Data Portalを開くことができ、簡単にデータ可視化が可能です。SQLクエリを書くと実行結果のデータ量の予測がエディタ右下に表示されるので、課金額におびえる心配もありません。
本記事でのデータ分析は基本的に以下の手順で行ったものになります。
- SQLクエリエディタにSQLを記述
- クエリ実行
- クエリ結果やデータポータルでの可視化を見て分析
コロナ陽性者数、PCR検査数、陽性率の推移
コロナ分析をするにあたってまず気になるデータは陽性者数や陽性率でしょう。以下のSQLクエリをBigQuery上で実行してGoogle Data Portalに飛ぶと陽性者数、PCR検査数、陽性率の日毎の推移を可視化することができます。
SELECT date, positive, pcr, positive*100/pcr as positive_rate
FROM `covid.general`
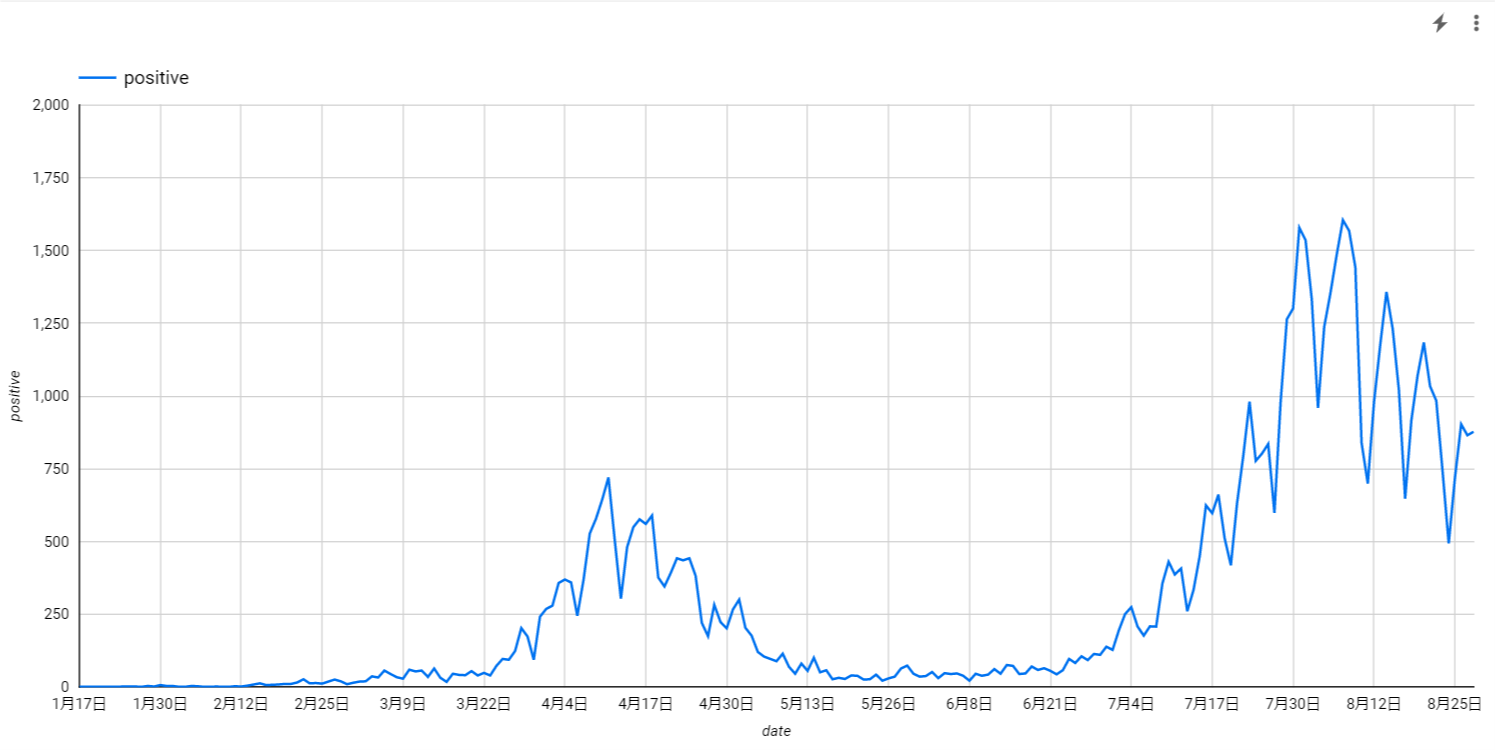
陽性者数の推移は以下です。横軸が日付、縦軸が陽性者数です。
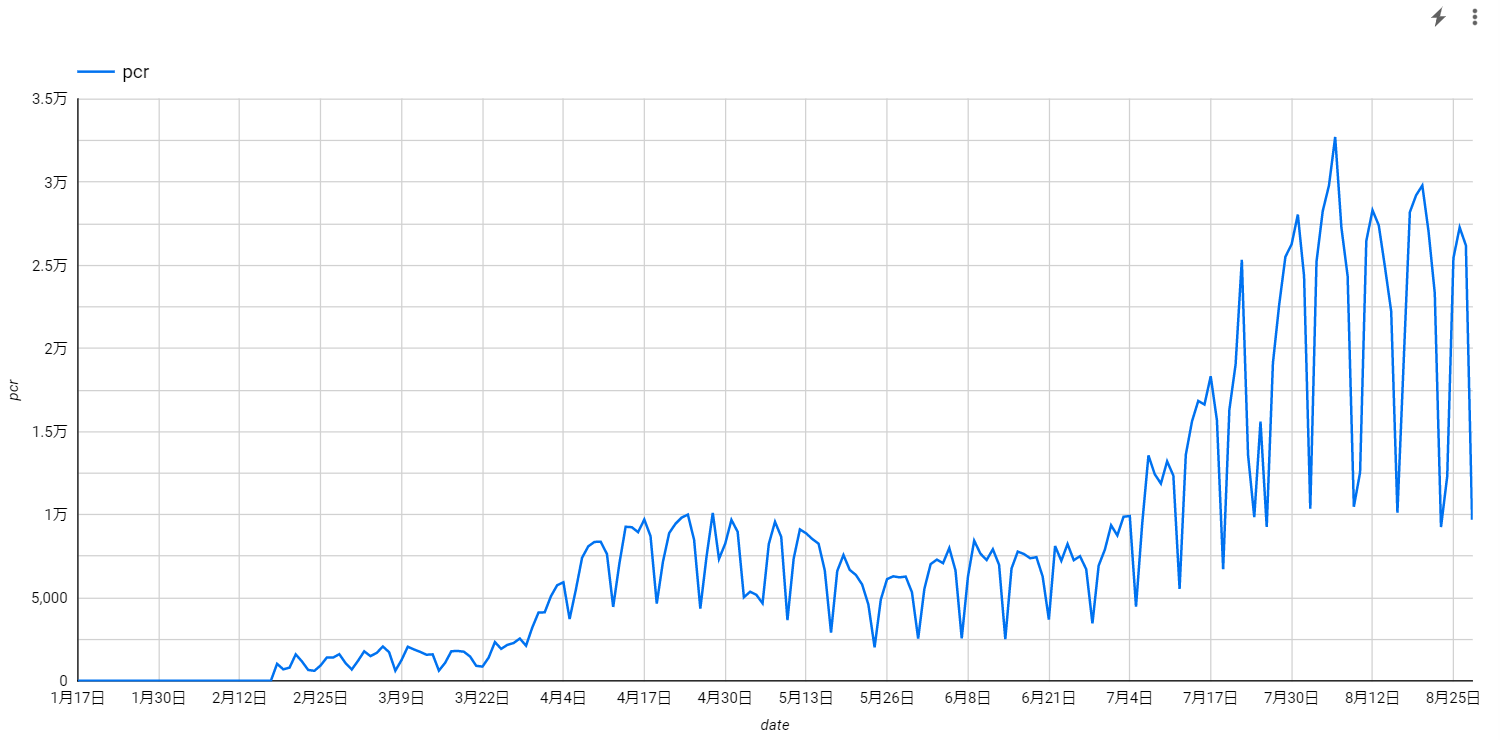
PCR検査数の推移は以下です。横軸が日付、縦軸がPCR検査数です。
陽性率の推移は以下です。横軸が日付、縦軸が陽性率です。
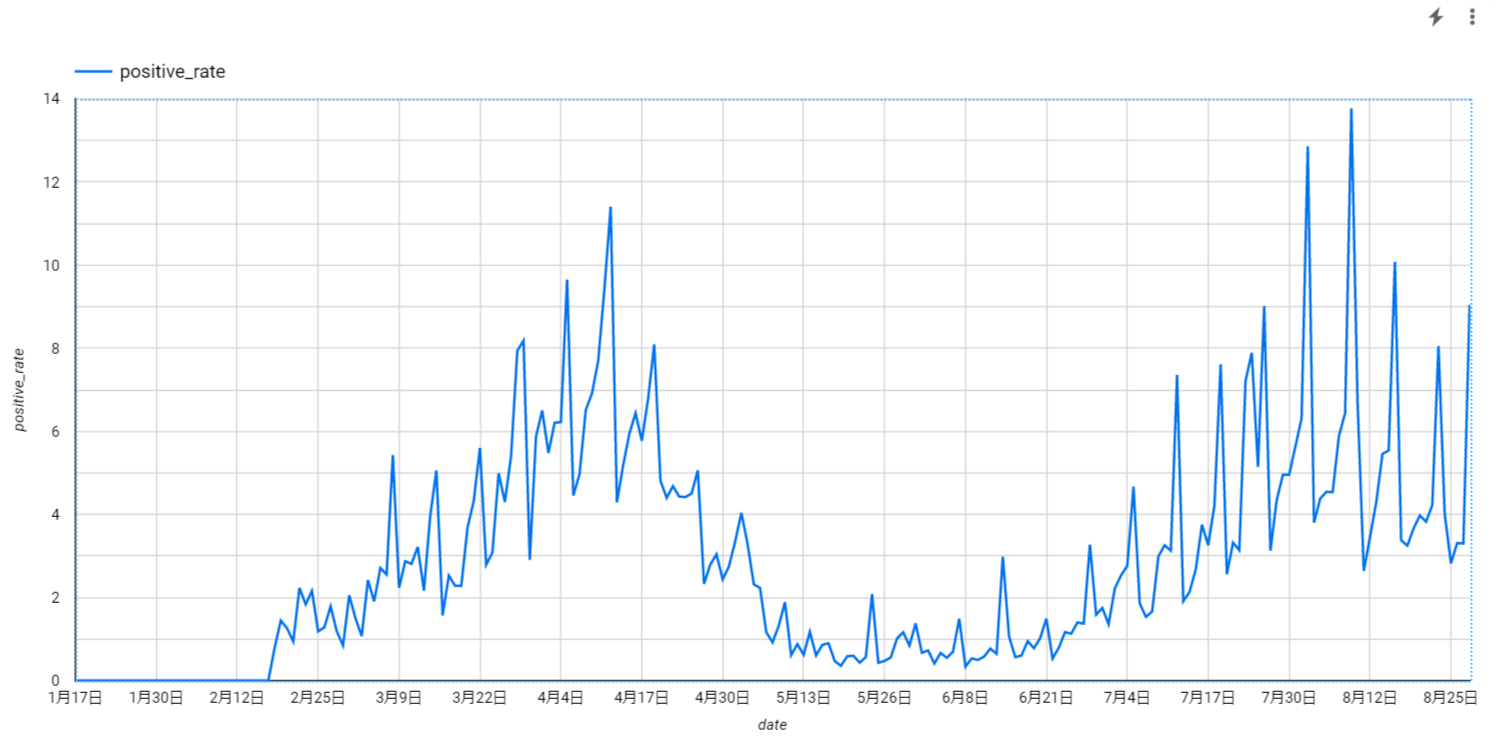
陽性者数は8月初旬にピークを迎え、若干減少傾向にあるように見えますね。陽性率の推移もおおむね陽性者数の推移に近いようです。ただし、陽性者数や陽性率はPCR検査数に強く依存しているのでコロナ情勢の指標として参考にしすぎるのも考えものです。政府としても6つの指標から感染状況を判断するようですし4、1つの指標を盲目的に信仰するのではなく多角的な視線を持つことが肝要です。
コロナ陽性者の年代分布
次にコロナ陽性者の年代分布を可視化してみようと思います。
SQLと可視化結果は以下です。
SELECT age, count(*) as number
FROM `covid.affected`
GROUP BY age
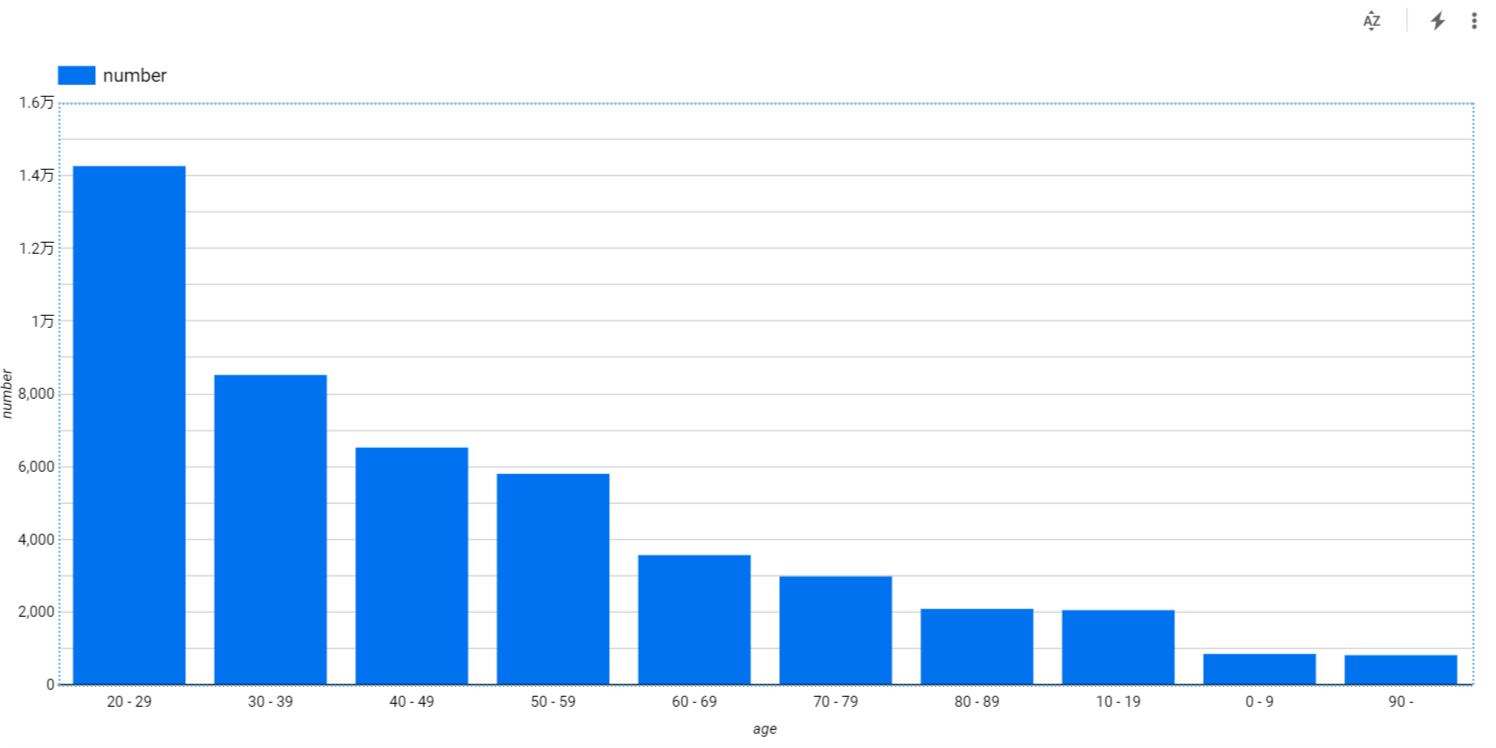
横軸が年代、縦軸が陽性者数を表しています。基本的には年代が上がれば陽性者数が下がる傾向にあります。ただし、0~19歳の子供の陽性者数は他の年代に比べると少ないです。子供はコロナウィルスに感染しにくく、症状も軽い場合が多いと話す専門家もいます。5。
コロナ陽性者間の関係
次にコロナ陽性者間の関係を可視化してみようと思います。陽性者間の関係は疑似的な感染経路とみなせるので、この分析で陽性者がどこからウィルスをもらってしまったのか見ることができます。
SQLと可視化結果は以下です。
SELECT relation, count(*) as number
FROM `covid.relation`
GROUP BY relation
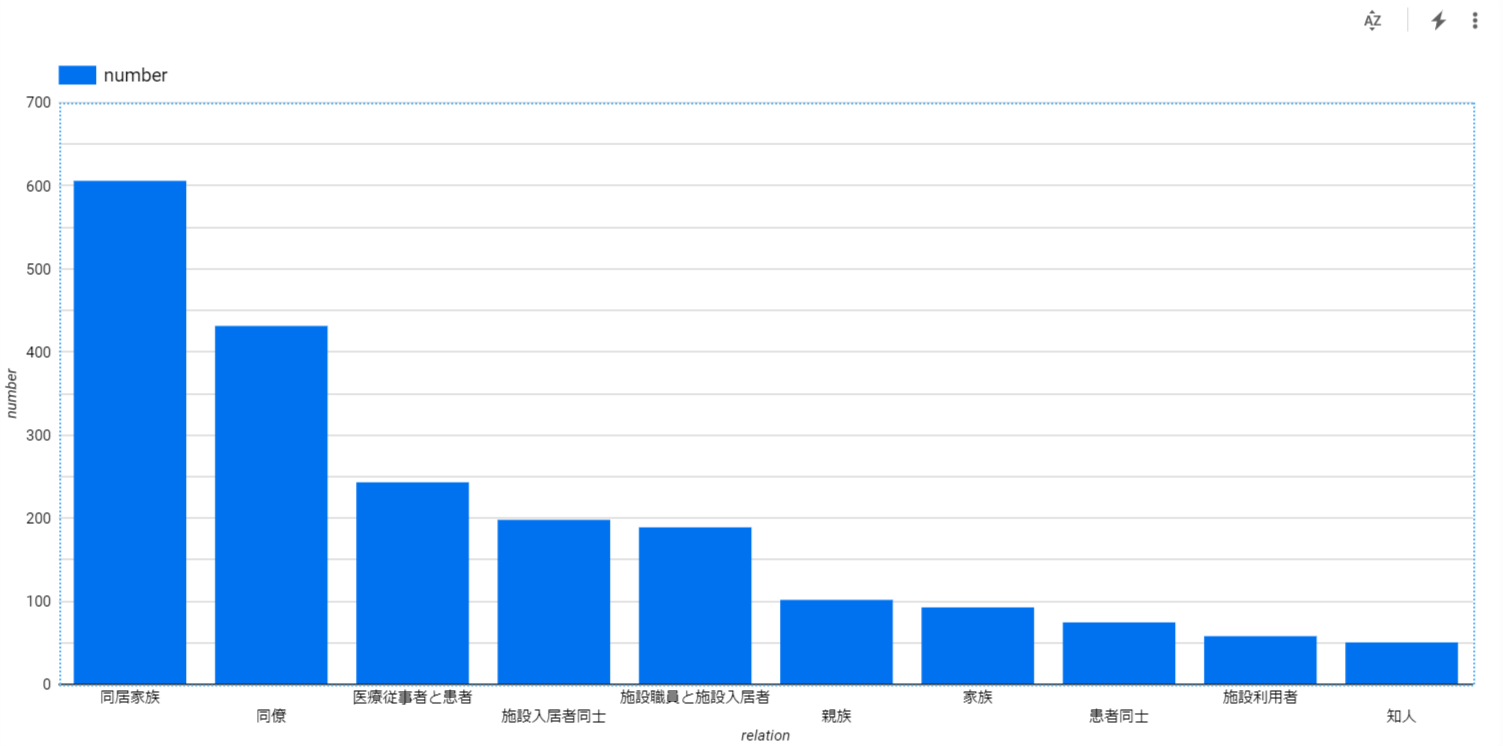
横軸が陽性者間の関係性、縦軸が人数を表しています。当たり前のようですが、同居家族や同僚など、恒常的に接触する関係が上位に来ています。また、老人ホームなどの施設での感染も比較的多いようです。
ARIMAモデルによる陽性者数推移予測
最近は陽性者数が減少傾向にあるとされていますが、果たして本当なのでしょうか。ARIMAモデルを使って陽性者数の推移を予測することで確かめてみようと思います。
ARIMAモデルは、時系列データの予測に使われるモデルです。株価予測や人口予測など、時間の経過とともに変動するデータの予測に使われます。
使用データ
使用した変数は時系列予測なので以下の2つだけです。これらはcovid.generalテーブルに入っています。
| 変数名 | 型 | 内容 |
|---|---|---|
| date | date | 日付 |
| positive | int | 日毎の陽性者数 |
今回は2020/1/17~2020/8/28の陽性者数データを使ってモデルを作成し、以後50日間の陽性者数を予測しました。
モデル作成
ARIMAモデルを作成するSQLクエリは以下です。
CREATE OR REPLACE MODEL covid.arima_model
OPTIONS
(model_type = 'ARIMA',
time_series_timestamp_col = 'date',
time_series_data_col = 'positive'
) AS
SELECT
date, positive
FROM
`covid.general`
今回は日付を時間軸、陽性者数をデータ軸においています。
モデルによる予測
作成したARIMAモデルを使って予測を行うSQLクエリと結果は以下になります。
SELECT
date,
positive AS history_value,
NULL AS forecast_value,
NULL AS prediction_interval_lower_bound,
NULL AS prediction_interval_upper_bound
FROM
(
SELECT
date, positive
FROM
`covid.general`
)
UNION ALL
SELECT
EXTRACT(DATE from forecast_timestamp) AS date,
NULL AS history_value,
forecast_value,
prediction_interval_lower_bound,
prediction_interval_upper_bound
FROM
ML.FORECAST(MODEL covid.arima_model,
STRUCT(50 AS horizon, 0.9 AS confidence_level))
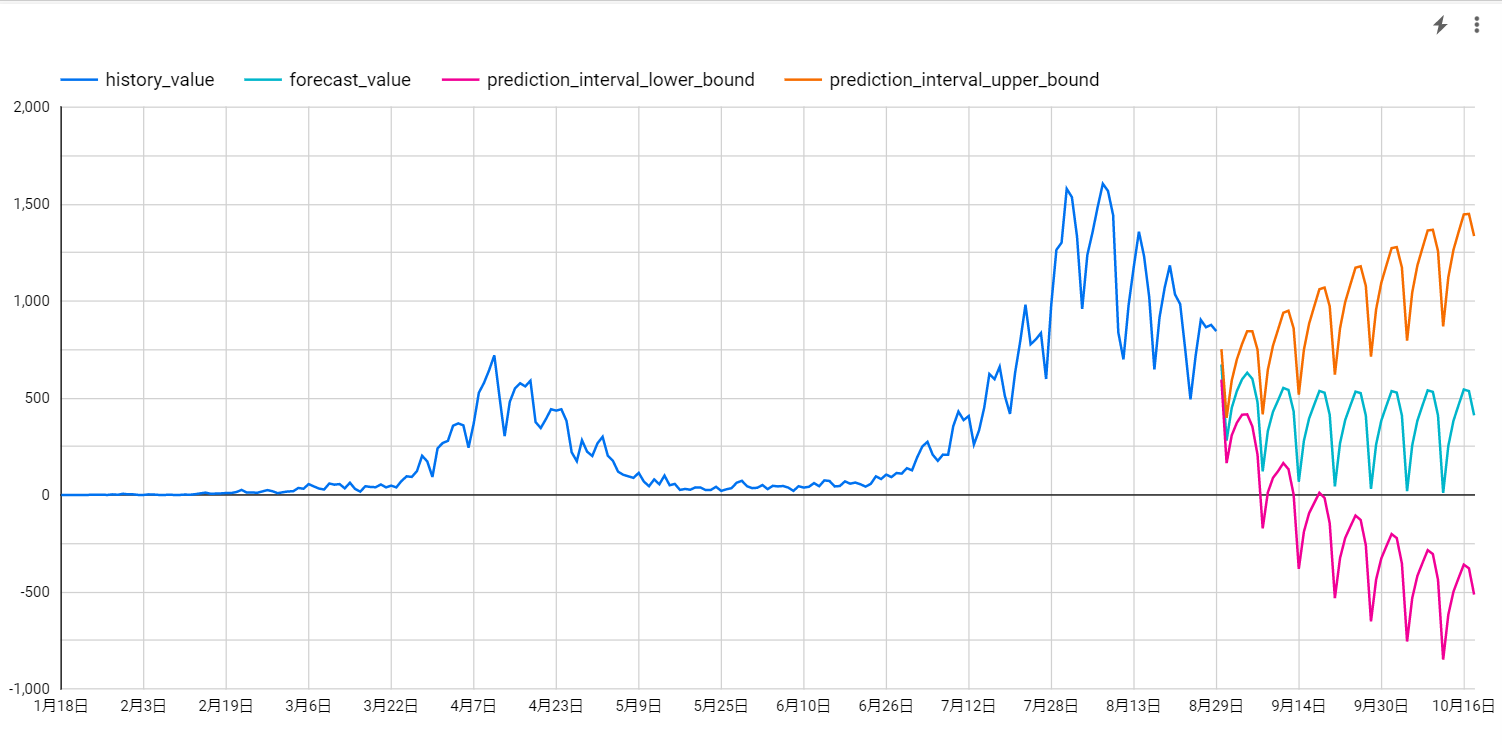
青線が実績値、オレンジ線とピンク線が信頼区間の上限と下限、水色線が予測した信頼区間の中間点を表しています。信頼区間という言葉になじみがない方は「ブレを含めた予測範囲」だと思っていただければ大丈夫です。可視化結果を非常に大雑把にとらえると、オレンジ線は「今後コロナが流行った場合の予測値」、ピンクの線は「今後コロナが収束に向かった場合の予測値」、水色線は「最も尤度が高い予測値」を表しているとみなすことができます。
水色線は上下しつつも全体的には減少しているので、作成したARIMAモデルも陽性者数は減少傾向にあると判断しているようです。
ロジスティック回帰モデルによる陽性者数増減予測
ARIMAモデルは時系列モデルなので、日数経過のみを考慮した陽性者予測でした。しかし、実際には、陽性者数は電車利用者数や繁華街滞在人口などの様々な要素が原因となって増減します。そこで、次はロジスティック回帰を用いて、これらの要素が陽性者数の増減に関係しているかどうかを考えてみようと思います。
ロジスティック回帰とは、データを複数に分類するモデルです。今回は日毎のデータを入力して「その日の陽性者数が増えるか減るか」を分類してみようと思います。
使用データ
使用したデータはcovid.generalテーブルの以下の変数群です。
| 変数名 | 型 | 内容 |
|---|---|---|
| fluctuation_flag | int | 陽性者数の増減フラグ。1なら前日より増、0なら前日より減 |
| positive_before_1d | int | 前日の陽性者数 |
| pcr | int | 当日のPCR検査数 |
| holiday_flag_before_1w | int | 1週間前の休日フラグ。1なら休日、0なら平日 |
| emergency_flag_before_1w | int | 1週間前の緊急事態宣言フラグ。1なら緊急事態宣言中、0なら緊急事態宣言でない |
| train_before_1w | int | 1週間前の都営地下鉄線の使用者数相対比(1月を0とする) |
| downtown_before_1w | int | 1週間前の歌舞伎町の滞在人口相対比(1月を0とする) |
都営地下鉄線利用者数や歌舞伎町滞在人口は日毎のデータを集めることが難しかったので1月と比べた相対比になっています。1週間前の人出の多さが陽性者数に影響すると言われているので、今回は1週間前の各データを用いてモデルを作成することにします。
モデル作成
ロジスティック回帰モデルを作成するSQLクエリは以下になります。
CREATE OR REPLACE MODEL covid.logistic_model
OPTIONS (model_type = 'logistic_reg') AS
SELECT
fluctuation_flag AS LABEL,
LAG(positive, 1) OVER (ORDER BY date) AS positive_before_1,
pcr,
LAG(holiday_flag, 7) OVER (ORDER BY date) AS holiday_flag_before_1w,
LAG(emergency_flag, 7) OVER (ORDER BY date) As emergency_flag_before_1w,
LAG(train, 7) OVER (ORDER BY date) AS train_before_1w,
LAG(downtown, 7) OVER (ORDER BY date) As downtown_before_1w,
FROM `covid.general`
BigQuery MLでは作成したロジスティック回帰モデルの精度やROC曲線を一覧で見ることができます。
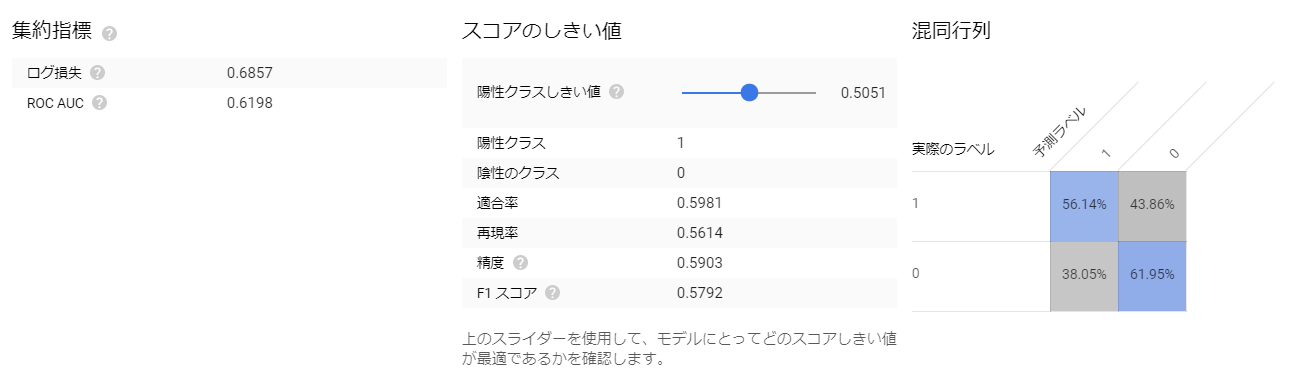
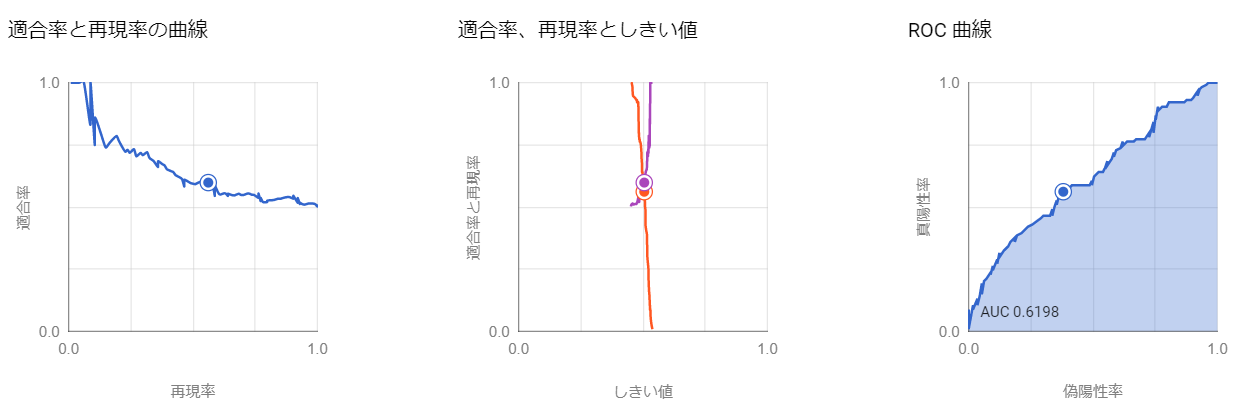
精度としては60%にも満たない結果でした。なお、しきい値設定により予測特性や精度は変わります。しきい値は適合率、再現率等を考慮し設定しますが、その詳細はこの記事等を参照ください。
作成したモデルの重みを見てみましょう。重みは、各変数が結果にどれだけ影響したかを表したものと考えることができます。モデルの重みを可視化するSQLと結果は以下です。
SELECT
processed_input,
weight,
REPEAT(IF(weight > 0,'+','-'),ABS(CAST(weight/0.01 AS INT64))) AS VIZ
FROM ML.WEIGHTS(MODEL `covid.logistic_model`, STRUCT(true AS standardize))
ORDER BY processed_input, weight
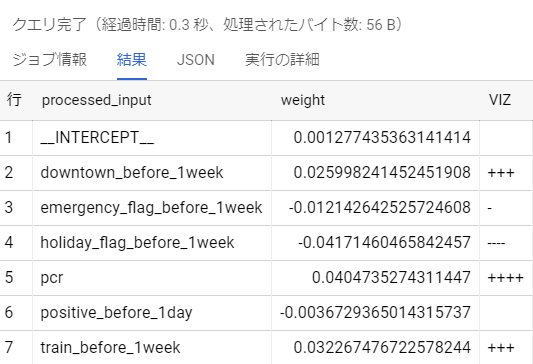
当日のPCR検査数と一週間前の都営新宿線利用者数・歌舞伎町滞在人口・休日フラグが他の変数と比べて重みが大きいようです。モデルはまだまだ改善の余地がありますが、陽性者数の増減とこれらの説明変数の関連性が示唆されます。
モデルを用いた予測
精度として実用に足るモデルではありませんが、せっかく作ったので陽性者数の増減の予測もしてみたいと思います。SQLと結果は以下です。
SELECT
*
FROM
ML.PREDICT (MODEL `covid.logistic_model`,
(
SELECT
fluctuation_flag AS LABEL,
LAG(positive, 1) OVER (ORDER BY date) AS positive_before_1d,
pcr,
LAG(holiday_flag, 7) OVER (ORDER BY date) AS holiday_flag_before_1w,
LAG(emergency_flag, 7) OVER (ORDER BY date) As emergency_flag_before_1w,
LAG(train, 7) OVER (ORDER BY date) AS train_before_1w,
LAG(downtown, 7) OVER (ORDER BY date) As downtown_before_1w,
FROM
`covid.general`
WHERE
date between '2020-08-24' and '2020-08-28'
)
)
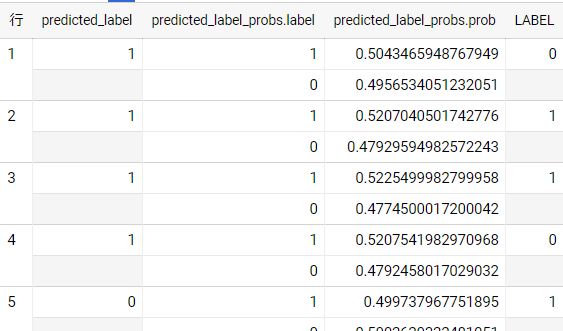
2020/8/24~2020/8/28の5日間について予測しています。LABEL列が実績値、predicted_label列が予測値です。このようにして実際の陽性者数の増減を予測することができます。
K-meansクラスタリングモデルによる陽性者分類
次に年齢や症状をもとに陽性者のグループ分け(クラスタリング)をしてみます。この分析をすることで陽性者の年齢や症状に関連性があるかどうかを考察することができます。
K-meansクラスタリングモデルは、座標空間上の距離を用いて自動的にデータのグループ分けをするモデルです。ここで使われる「クラスタ」という単語は、コロナに同時感染した集団という意味ではなく、機械学習的にグループ分けしたときのデータグループを指します。
使用データ
使用したデータはcovid.affected_peopleの以下の変数群です。
| 変数名 | 型 | 内容 |
|---|---|---|
| sex | string | 陽性者の性別。 |
| age | int | 陽性者の年代。30なら年齢が30台。 |
| cough | int | 咳の症状の有無。1なら症状有、0なら症状無し。 |
| fever | int | 熱の症状の有無。1なら症状有、0なら症状無し。 |
| pneumonia | int | 肺炎の症状の有無。1なら症状有、0なら症状無し。 |
| malaise | int | 倦怠感の症状の有無。1なら症状有、0なら症状無し。 |
| headache | int | 頭痛の症状の有無。1なら症状有、0なら症状無し。 |
| joint | int | 関節痛の症状の有無。1なら症状有、0なら症状無し。 |
| breath | int | 呼吸器系の症状の有無。1なら症状有、0なら症状無し。 |
| taste | int | 味覚障害の症状の有無。1なら症状有、0なら症状無し。 |
元データでは症状を文章としてまとめているので、文章内に各症状を表す名詞が入っていたら1、入っていなかったら0という2値データを作成しました。また、年齢は10刻みの年代データとして格納されていたものをそのまま流用しています。
データ数は元々65000件ほどありましたが、そこから症状の記載があるデータを抜き出して今回は約7000件を用います。
モデル作成
K-meansクラスタリングモデルを作成するSQLクエリは次のようになります。
CREATE OR REPLACE MODEL covid.kmeans_model
OPTIONS(model_type='kmeans', num_clusters=3) AS
SELECT
CASE sex WHEN '男性' THEN 1 WHEN '女性' THEN 0 END AS sex,
age,
cough,
fever,
pneumonia,
malaise,
headache,
joint,
breath,
taste
FROM `covid.affected_people`
K-meansクラスタリングモデルでは、データ群をいくつのクラスタに分けるかを指定する必要があります。適正のクラスタ数には諸説あるのですが、今回はBigQuery MLのクラスタ数デフォルト値を参考にすることにします。BigQuery MLのクラスタ数のデフォルト値6はlog10n(nはデータ数)なので、クラスタ数の候補は3~4です。実際にクラスタ数を3~5個にして試しにモデルを作成すると、クラスタ数3が最もバランスよく分類できていそうでした。
作成したK-meansモデルの各クラスタのセントロイド(重心)を可視化すると以下のようになります。

クラスタ1は発熱(fever)の症状が出ていない陽性者が属するグループのようです。今回のデータでは文章内に発熱関連の単語がないと発熱症状がないとみなすので、データの形式に強く依存する点には注意が必要です。
クラスタ2の特徴としては、年齢層が低いこと、倦怠感(malaise)・頭痛(headache)・関節痛(joint)・味覚障害(taste)の症状が出てる人が多いことが挙げられます。このことから、年齢と各症状に関連性があることや症状間にも関連性があることが推測されます。
クラスタ3は、年齢層が高い、肺炎(pneumonia)・呼吸器系(breath)の症状が出ている割合が比較的高いという特徴があります。年齢と気管支症状には何らかの関連性が示唆され、より精微な因果推論を進めるモチベーションとなりえるかもしれません。
モデルによる予測
新たに陽性となってしまった人の年代や症状を入力してその人がどのクラスタに属するか予測してみようと思います。試しに2人分のデータを用いてクラスタ予測を行います。sqlと結果は以下です。
SELECT
*
FROM
ML.PREDICT( MODEL covid.kmeans_model_3, (
SELECT
CASE sex WHEN '男性' THEN 1 WHEN '女性' THEN 0 END AS sex,
age,
cough,
fever,
pneumonia,
throat,
malaise,
chill,
headache,
joint,
breath,
nausea,
taste
FROM
`covid.test_cluster`))

CENTROID_IDが予測クラスタ番号です。1人目は20代の女性で、咳、発熱、味覚障害等の症状があり、クラスタ2に属すると予測されています。クラスタ2は年齢層が若く味覚障害の症状が特徴的なクラスタでしたので、妥当な予測だといえます。2人目は60代の男性で、発熱、肺炎、頭痛、呼吸器障害の症状が出ています。クラスタ3は年齢層が高めで気管支症状が特徴のクラスタだったので、2人目はクラスタ3と予測されました。
クラスタ予測はこのようにして行うことができます。データを個々として評価するのでなくグループとしてみなすことにより、より詳細な分析を進める前の検討材料となりえるでしょう。
おわりに
本記事ではBigQuery MLを用いて簡単なコロナ分析をしてみました。コロナに関するいくつかの面白そうな分析ができたと思います。ただし、分析手法の選定、結果や解釈には、私見を多く含む為、その点は留意ください。
BigQuery MLのご説明の題材としてコロナ予測を選定しましたが、下記2つの理由でこのテーマが適切かどうかは議論が残ります。
- データ量が十分でない(半年程度で、通年、年跨ぎの動向は評価できない)
- アクションにつなげるには専門家(医療関係者等)による解釈が必要
一方で、BigQuery MLでできることの概要やその手順はある程度ご理解いただけたと思います。簡単に使える上に用途の幅も広いのでぜひ使ってみてください。
GoogleのサービスにはBigQuery ML以外にも機械学習サービスが多々ありますが、それらとBigQuery MLとの比較は本記事がLGTMをたくさんいただいたら書くかもしれません。LGTMください。
ご指摘や罵詈雑言もお待ちしています。
-
http://mickindex.sakura.ne.jp/database/db_getout_null.html ↩
-
https://inthecloud.withgoogle.com/saas-day-jp-20/Google_SaaS_Day_200227_Session12.html ↩
-
https://www.nikkei.com/article/DGXMZO62445300X00C20A8MM8000/ ↩
-
https://www.cedars-sinai.org/newsroom/covid19-why-are-children-less-affected/ ↩
-
https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create ↩