すぎゃーんさんが自作された顔検出器を、Google Machine Learning Engineを使って学習してみました。
以下に実行手順と費用等をまとめます。
github
注意事項
- GPUが有効なリージョンを指定してください(参考: GPU が有効なマシンをリクエストする)
- 最新のtensorflow/modelsだと不具合が発生するので、使わないでください。
1. プロジェクトのセットアップ
https://github.com/k-yamada/tf-face-detector をgitでcloneし、セットアップをしてください。
git clone https://github.com/k-yamada/tf-face-detector.git
cd tf-face-detector
virtualenv --system-site-packages ~/tf-face-detector
source ~/tf-face-detector/bin/activate
git submodule update --init
pip install -r requirements.txt
2. Cloud Platform Console プロジェクトを作成してセットアップする
上記を参考に、プロジェクトを作成して必要なセットアップをして下さい。
プロジェクト名は「tf-face-detector」にします。
3. パッケージング
- 参考: Packaging
パッケージングします
cd models
protoc object_detection/protos/*.proto --python_out=.
python setup.py sdist
(cd slim && python setup.py sdist)
4. モデルトレーニングやバッチ予測の実行中にデータを読み書きするための Google Cloud Storage バケットを作成する
PROJECT_ID=$(gcloud config list project --format "value(core.project)")
BUCKET_NAME=${PROJECT_ID}-mlengine2
REGION=asia-east1
# バケットを作成
gsutil mb -l $REGION gs://$BUCKET_NAME
5. データファイルを Cloud Storage バケットにアップロードする
gsutil を使用して data ディレクトリを Cloud Storage バケットにコピーします。
# TODO: data/fddbはコピーする必要がないので、除外する
gsutil cp -r data gs://$BUCKET_NAME/data
6. configファイルを Cloud Storage バケットにアップロードする
perl -pe "s|PATH_TO_BE_CONFIGURED|gs://$BUCKET_NAME/data|g" ./ssd_inception_v2_fddb.config.base > ssd_inception_v2_fddb.config
gsutil cp -r ssd_inception_v2_fddb.config gs://$BUCKET_NAME/ssd_inception_v2_fddb.config
7. クラウドで単一インスタンスのトレーニングを実行する
分散トレーニングをする前に、まず単一のインスタンスでトレーニングを実行し、動作確認をします。
JOB_NAME=object_detection_`date +%Y%m%dT%I%M%S`
TRAIN_DIR=${BUCKET_NAME}/train
OUTPUT_PATH=gs://$BUCKET_NAME/$JOB_NAME
HPTUNING_CONFIG=./hptuning_config.yaml
gcloud ml-engine jobs submit training $JOB_NAME \
--runtime-version 1.2 \
--job-dir $OUTPUT_PATH \
--packages models/dist/object_detection-0.1.tar.gz,models/slim/dist/slim-0.1.tar.gz \
--module-name object_detection.train \
--region $REGION \
-- \
--train_dir=${OUTPUT_PATH}/train \
--pipeline_config_path=gs://${BUCKET_NAME}/ssd_inception_v2_fddb.config \
--train-steps 1000 \
--verbosity DEBUG
8. クラウドで分散トレーニングを実行する
JOB_NAME=object_detection_`date +%Y%m%dT%I%M%S`
TRAIN_DIR=${BUCKET_NAME}/train
OUTPUT_PATH=gs://$BUCKET_NAME/$JOB_NAME
HPTUNING_CONFIG=./hptuning_config.yaml
gcloud ml-engine jobs submit training $JOB_NAME \
--runtime-version 1.2 \
--job-dir $OUTPUT_PATH \
--packages models/dist/object_detection-0.1.tar.gz,models/slim/dist/slim-0.1.tar.gz \
--module-name object_detection.train \
--region $REGION \
--config $HPTUNING_CONFIG \
-- \
--train_dir=${OUTPUT_PATH}/train \
--pipeline_config_path=gs://${BUCKET_NAME}/ssd_inception_v2_fddb.config
tensorboardを起動
tensorboard --logdir=$OUTPUT_PATH
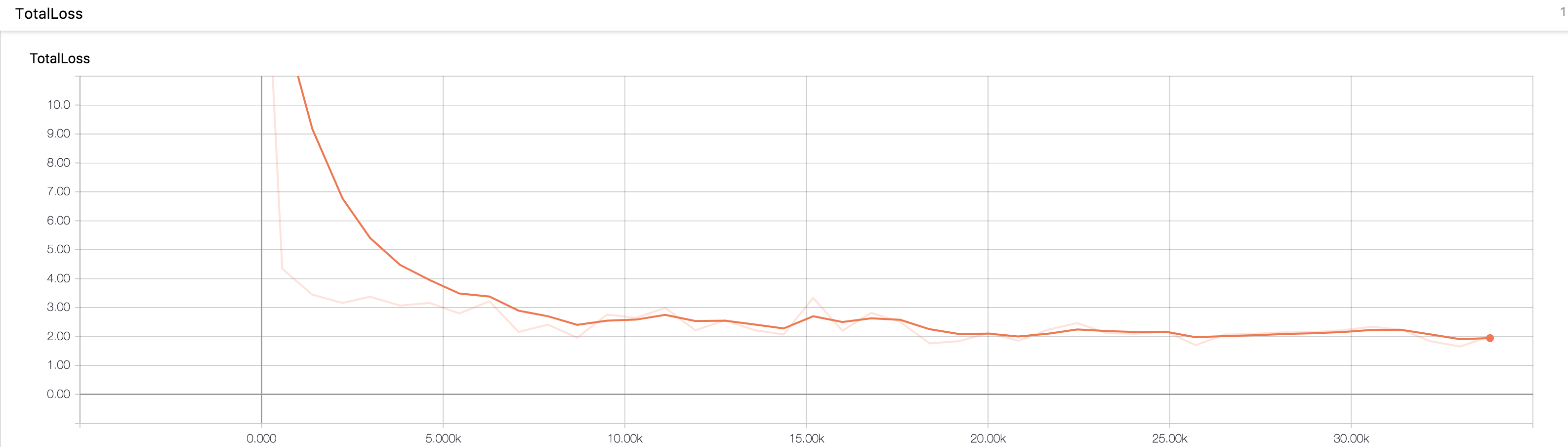
約35000ステップ回しましたが、TotalLessは10000ステップあたりで収束したようでした。
9. Export graph
export CHECKPOINT_NUMBER=<target checkpoint number>
gsutil cp ${OUTPUT_PATH}/train/model.ckpt-${CHECKPOINT_NUMBER}.data-00000-of-00001 train/
gsutil cp ${OUTPUT_PATH}/train/model.ckpt-${CHECKPOINT_NUMBER}.index train/
gsutil cp ${OUTPUT_PATH}/train/model.ckpt-${CHECKPOINT_NUMBER}.meta train/
export PYTHONPATH=${PYTHONPATH}:$(pwd)/models:$(pwd)/models/slim
export EXPORT_DIRECTORY=/tmp
rm -rf $EXPORT_DIRECTORY/saved_model
python models/object_detection/export_inference_graph.py \
--input_type=encoded_image_string_tensor \
--pipeline_config_path=ssd_inception_v2_fddb.config \
--trained_checkpoint_prefix=train/model.ckpt-${CHECKPOINT_NUMBER} \
--output_directory=${EXPORT_DIRECTORY}
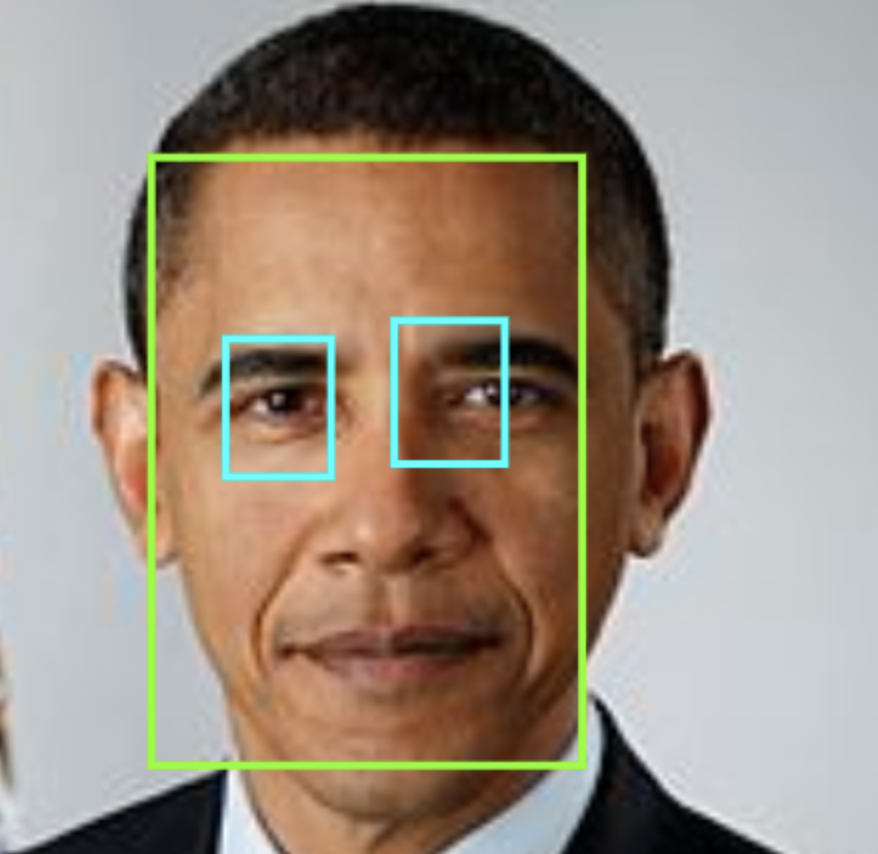
検出結果

学習データが足りないせいだと思いますが、目の位置がずれる場合もありました。
学習にかかった時間と費用
- 学習ステップ数: 約35000
- 分散学習のワーカー数: 9
- 実行時間: 1時間30分
- 消費したMLユニット: 39.37
- 費用: $25.26(2828円)
料金の計算式
参考: 料金
MLトレーニングユニットごとに 1時間あたり $0.54かかるようです。
今回消費したMLユニットは39.37だったので、かかった費用は、
$0.54 x 39.37MLユニット = $25.26 = 2828円
となります。
この他にCloud Storageの利用料もかかりますが、 数十円程度しかかからないので計算からは除外してます。