クラウドワークスアドベントカレンダー2020年12月21日の記事になります。
はじめに
初めまして。株式会社クラウドワークスに2018年に入社したまよまよ(@mayoxtuna)です。
最近ハマっていることはApex LegendsというバトロワFPSゲームです。

Apex Legendsは『タイタンフォール』から数百年後の世界のお話でそれぞれのレジェンドと呼ばれるキャラクターを使用して3vs3で戦うゲームとなっております。
最近ではクロスプラットフォームにも対応した為、PS4やXBoxの方と一緒に遊ぶことも出来るようになりました。
ぜひ一緒にやりましょう〜!
じゃなくて(はよ本題へ)...
2020年の1年間を振り返った時に、Elasticsearchを頑張ったなーという感想だったので
溜まった知見などを放出してElasticsearchチュートリアル的なものを出そうかなと思いました。
これから、Elasticsearchをやってみたい方や気になる方、名前だけ聞いたことあるけどどんな事できるの?ってことを知りたい方はぜひ覗いてみてください。
Elasticsearchの概要
◯ Elasticsearchとはなんぞや?
公式より引用:
Elasticsearchは高速でスケーラブル、しかも多様なコンテンツをインデックスすることができ、幅広いユースケースにお使いいただけます。
・アプリ検索
・Webサイト検索
・エンタープライズサーチ
・ロギングとログ分析
・インフラメトリックとコンテナー監視
・アプリケーションパフォーマンス監視(APM)
・地理空間データ分析と可視化
・セキュリティ分析
・ビジネス分析
とあります。
ものすごく噛み砕くと、高速な検索エンジンです。
◯ RDBと何が違うの?
まずはそもそもの呼ばれ方が異なります。
| RDB | Elasticsearch |
|---|---|
| データベース | インデックス |
| テーブル | タイプ |
| カラム | フィールド |
| レコード | ドキュメント |
そしてデータの投入方法として、SQLではなくRESTful APIを用いてJSON形式にてデータの追加削除を行っています。
「呼び方が違うのとSQL文ではなくJSON形式投入するくらいの違いで、基本的にはRDBと作りは同じだけど、早いってだけなんですね!」って最初は疑問に思っていましたが、RBDは汎用性の高い機能が豊富で、それを真似するようにElasticsearchにも様々な機能的改善が見られRDBみたいと思う事はありますが、Elasticsearchは全文検索に特化しており、Analysisのような機能はRDBではありません。また、RDBでは複数のデータベースを持つことは少ないけどElasticsearchではそれが普通だったりもします。
更にいえばRDBでデータベースを消すということはローカル環境ではない限り滅多にしないけど、Elasticsearchでは不要なインデックスは消してしまう。RBDとElasticsearchの使い方は似て非なるものだと思いました。
◯ データの持ち方について
RDBでは1つデータベースを持って複数のテーブルを持つとは思うのですが、Elasticsearchでは日時別やユーザー別などでデータベース(インデックス)持ったりします。
つまりテーブルのような概念はあまりありません。タイプと呼ばれるもので実現は可能ですがElasticsearch 7以降タイプレス化が進んでいるため、RDBとElasticsearchではここが大きな違いだと思います。
RDBでは1つのデータベースに仕事やユーザー情報を持ちますが、Elasticsearchでは仕事別、ユーザー別に分けたりすることが多いです。
Elasticsearchでは1つのデータベースにすべてのテーブルを置くというわけではなく、必要最低限の検索対象を1つのデータベースとして定義するという形になると思います。
複合条件で検索したいのであれば複合のインデックスを作ります。
また、データベースの削除などをRDBでは行いませんが、Elasticsearchでは不要なインデックスを消したりします。データの持ち方によっては定期的に再構築するケースもあるでしょう。
◯ おまけ: analysisなどのテキスト分析(解析)
RBDではデータをそのまま保持しますが、Elasticsearchではテキストデータを必要な形に分割、変換を行い保持します。
テキスト分析を行い最適な形に変換しておく事で、親しい文章の抽出などが容易になります。
ここはRDBとは違ってかなり重要かつ美味しいポイントでもあります。
AnalyzerではCharacter Filters、Tokenizer、Token Filtersという3つの要素で構成されています。
kuromojiとかicu_normalizeとかそういったものですね。
ここは省かせてください。
Text analysis | Elasticsearch Reference [7.10] | Elastic
細かいElasticsearchの仕様については、公式を見ていただいければと思います。
ドキュメントも細かく、Releaseノートなどでは、どういった理由で変更を行ったのかなどが書いてあって読みやすかったです。
Elasticsearchの準備と確認
直接installすると破棄が面倒なのでdockerを利用して行きます。
Elasticsearchの方にインストールの詳細が載っておりますが大事な部分だけを抜き出します。
Docker Hubの方でも公開されています。
Elasticsearchのdocker imageですが、OSS版とそうではないものがあります。
OSS版では、 x-packがデフォルトで入っていないものとなっています。
ローカルで検証する分にはx-packは不要な為OSS版を利用します。
環境構築
1. 公式通り最新のElasticsearchをpullします
2. 起動の確認を行います
3. アクセスしてみる
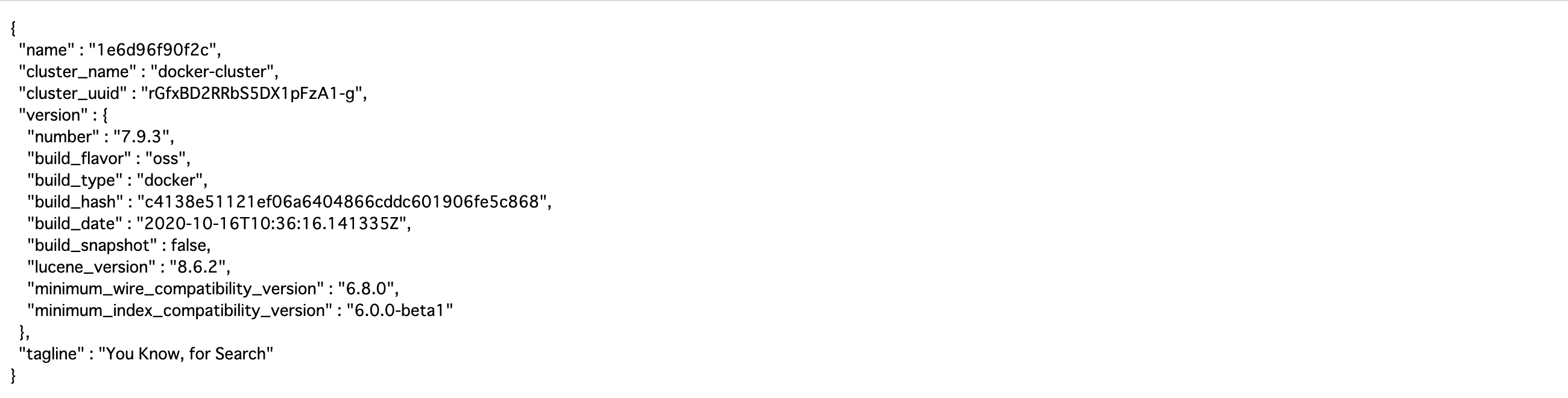
ここまでで、起動の確認はできました。
ターミナル上で Cntl+C でプロセスを終了しましょう。
4. Dockerfileにする
pluginなどもインストールしておきたい為Dockerfileを用意しましょう。
入れるものとしては日本語のAnalyzeをしてくれるkuromojiなどです。
FROM docker.elastic.co/elasticsearch/elasticsearch-oss:7.9.3
RUN elasticsearch-plugin install analysis-kuromoji && \
elasticsearch-plugin install analysis-icu
USER elasticsearch
5. Kibanaを用意する
Elasticsearchを扱う上でterminal上でjson形式でやり取りをするのは非常に面倒くさいので Kibana も用意していきます。
KibanaではElasticsearchでインデックスされたデータの検索と可視化の機能を提供してくれます。
6. docker-compose.ymlを作る
kibanaでElasticsearchと繋いだりDockerfileを指定したりするのでdocker-compose.yml を用意しましょう
version: "3"
services:
elasticsearch-v7.9.3:
container_name: "elasticsearch"
build:
context: .
dockerfile: ./Dockerfile
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- logger.deprecation.level=debug
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
ports:
- "9200:9200"
volumes:
- elasticsearch-v7.9.3-data:/usr/share/elasticsearch/data
kibana-v7.9.3:
image: docker.elastic.co/kibana/kibana-oss:7.9.3
ports:
- "5601:5601"
restart: always
environment:
- "ELASTICSEARCH_HOSTS=http://elasticsearch:9200"
volumes:
elasticsearch-v7.9.3-data:
driver: local
8. 起動して確認

http://localhost:5601 へアクセスし以下のような画面になれば成功です
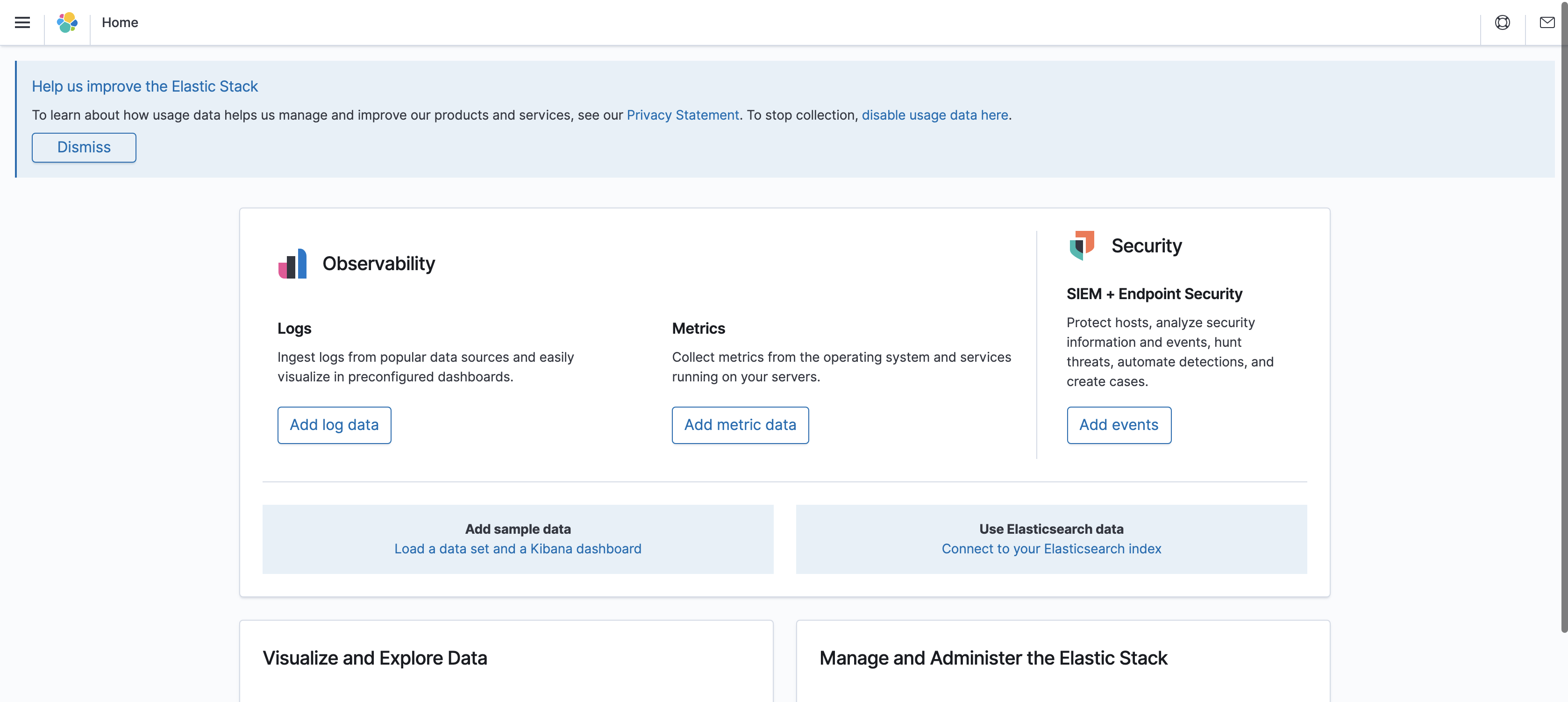
以上で環境の構築は完了しました。お疲れさまでした。
簡単な使い方の説明
まずは Dev Tools を開きましょう。
- 画面右上の
三アイコンをクリック
-
Dev Toolsをクリック
この画面上からElasticsearchに向けてデータの投入参照削除(POST/GET/DELETE)を行うことが出来ます。
試しに参照をしてみましょう。以下の文章を貼り付けてください。
GET _cat/aliases
以下の部分を押すことで実行する事が可能です。
もしくは ⌘+ENTER で可能です。
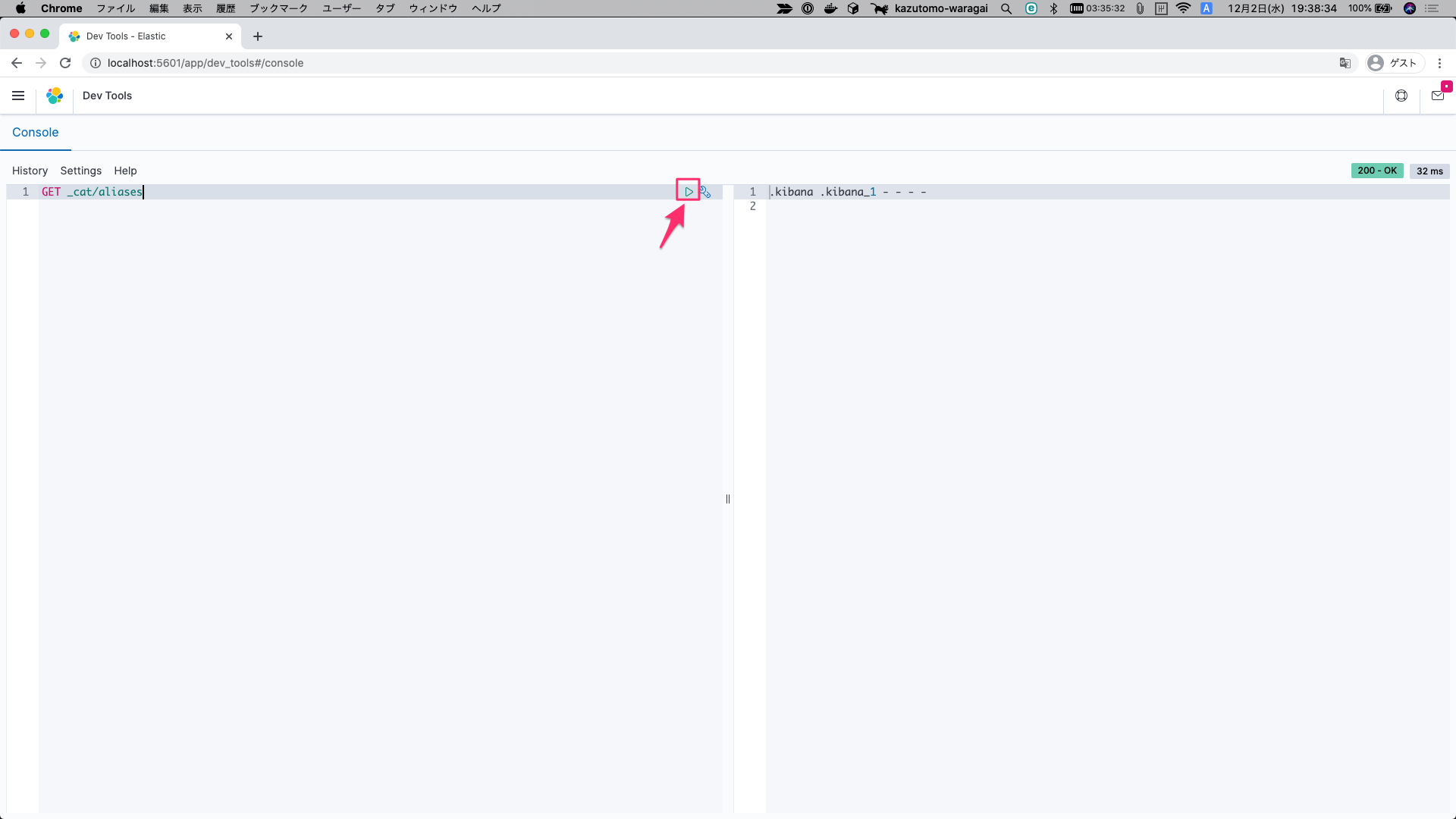
実行が完了すると右側に結果が出力されます。
Elasticsearchを実際に触ってみよう
空のIndexを作成する
indexを作成するにはPOSTではなくPUTを利用します。
以下の文をコピペして実行してみましょう。
PUT job_offers
以下のようなものが返却されれば成功です。
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "job_offers"
}
Indexを確認する
基本的に参照系はすべてGETで行えます。
実際に作られたIndexを確認してみましょう。
以下の文をコピペして実行してみましょう。
GET _cat/indices
以下のような形式のものが返却されます。
yellow open job_offers Y99rqJqOSQ6RHnnmOG8jow 1 1 0 0 208b 208b
green open .kibana_1 3WOY-fXOSiGGCyX8qwEo-A 1 0 13 19 46.2kb 46.2kb
作られていそうなのは確認できたのでこのIndexの詳細を覗いてみましょう。
以下の文をコピペして実行してみましょう。
GET job_offers
以下のような形式のものが返却されます。
{
"job_offers" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1607079649046",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "Y99rqJqOSQ6RHnnmOG8jow",
"version" : {
"created" : "7090399"
},
"provided_name" : "job_offers"
}
}
}
}
まだDBでいうデータベースを作成した状態なので何もありません。
作成したIndexを削除する
作ったばかりで申し訳ないですが削除をしてみましょう
RDBなどでカジュアルにデータベース消されたら怖いが、ElasticsearchではIndexの削除などが結構カジュアルに行われます。
というのも先述で述べた通り、RDBなどと持ち方の考え方が全く異なるためです。
以下の文をコピペして実行してみましょう。
DELETE job_offers
以下のような形式のものが返却されます。
{
"acknowledged" : true
}
同じようにIndex一覧を確認してみましょう。
以下の文をコピペして実行してみましょう。
GET _cat/indices
以下のような形式のものが返却されます。
green open .kibana_1 3WOY-fXOSiGGCyX8qwEo-A 1 0 21 0 23.3kb 23.3kb
先程とは異なり1つのみになりましたね。
ということで作成・削除の工程は終わりましたので次はデータを実際に差し込んで参照する流れを説明していきます。
データを作成する
Indexは1つ以上のタイプを持つことが出来ます。
個々のドキュメントにはそれぞれ一意な識別子(ID)が設定されるようになっています。
ちなみにElasticsearchでは事前にmappingと呼ばれるテーブル定義みたいなものをせずに、いきなりデータを投入してもよしなに解釈してデータとして保持してくれます。
素晴らしいですね。
ただし、裏を返せばPOSTした際に不正なタイプを指定して挿入してしまった場合受理されてしまいますのでそこは注意が必要です。
また、勝手に型を指定されてしまうので思ったのと違うということにもなりかねません。
そして現在はそのようなやり方は非推奨となっているはずなのでやめましょう。
なので事前定義をして挿入するやり方で今回は進めたいと思います。
ではさっそく、今回は以下のようなものを作成します。
qiitaというindexを作成しtitle,description,screen_nameを入れましょう。
そしてIDは2434にしましょう。
(構造関係を文字で書くとややこしいのでJSONで表現します。)
{
qiita: {
_doc: {
title: "アドベントカレンダーxx日目のタイトル",
description: "どうも初めまして。xxと申します。",
screen_name: "k-waragai"
}
}
}
このようなものを表現するには、以下の文をコピペして実行してみましょう。
1. まずはIndexの作成
以下の文をコピペして実行してみましょう。
PUT qiita
2. mappingの定義
以下の文をコピペして実行してみましょう。
PUT qiita/_mapping/
{
"properties" : {
"title" : {
"type" : "text"
},
"description" : {
"type" : "text"
},
"screen_name" : {
"type" : "text"
}
}
}
ここで1つ補足があります。
Elasticsearch 6 系までは、qiita/article/2434 のような形でタイプ名を指定することが可能でしたが、Elasticsearch 7 系よりタイプレス化が進み指定する場合は、include_type_name=trueというオプションを付けなければならなくなりました。ちなみにこれも非推奨でいずれなくなるそうです。
これによって、指定しない場合は_docというものが自動的に付くようになりました。
そのため qiita/_doc/2434 という形になります。
mappingの例として以下のような変更です
- before
{
"mappings": {
"article": {
"properties" : {
"title" : {
"type" : "text"
},
"description" : {
"type" : "text"
},
"screen_name" : {
"type" : "text"
}
}
}
}
}
- after
{
"mappings": {
"_doc": {
"properties" : {
"title" : {
"type" : "text"
},
"description" : {
"type" : "text"
},
"screen_name" : {
"type" : "text"
}
}
}
}
}
マルチフィールドとかも可能だったのですが、それが原因で複雑性とかが増すので
indexの役割を減らすという意味ではいいアップデートだと思いました。
補足は以上です。mappingの定義が終わったのでmappingの確認をしてみましょう。
3. mappingの確認
以下の文をコピペして実行してみましょう。
GET qiita/_mapping
以下のような形式のものが返却されます。
{
"qiita" : {
"mappings" : {
"properties" : {
"title" : {
"type" : "text"
},
"description" : {
"type" : "text"
},
"screen_name" : {
"type" : "text"
}
}
}
}
}
ちゃんとtypeに指定したtextなどが記述されていますね。
typeに関してはこちらを御覧ください。
4. データを挿入する
以下の文をコピペして実行してみましょう。
POSTではなくPUTである点に注意です。
PUT qiita/_doc/2434
{
"title": "アドベントカレンダーxx日目のタイトル",
"description": "どうも初めまして。xxと申します。",
"screen_name": "k-waragai"
}
以下のような形式のものが返却されます。
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "2434",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
上手く差し込まれていそうですね。
ではElasticsearchに_idを任せて入れてみましょう。
以下の文をコピペして実行してみましょう。
先程とは異なりPUTではなくPOSTである点に注意です。
POST qiita/_doc/
{
"title": "Elasticsearchチュートリアル書いてみた",
"description": "チュートリアルです。みんな見てね。",
"screen_name": "mayoxmayo"
}
以下のような形式のものが返却されます。
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "J32eLXYB4YEI6IRIxT4f",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
先程とは異なり_idにはランダムな英数値が設けられています。
この_idは固有値なため被らなければなんでも良いです。
ではそれぞれ差し込んだデータの詳細を見てみましょう。
5. データを個別に参照する
以下の文をコピペして実行してみましょう。
GET qiita/_doc/2434
以下のような形式のものが返却されます。
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "2434",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "アドベントカレンダーxx日目のタイトル",
"description" : "どうも初めまして。xxと申します。",
"screen_name" : "k-waragai"
}
}
同様にもう1件確認してみましょう。
以下の文をコピペして実行してみましょう。
※ ここで指定しているランダム文字列は、POST時に作成して返却された_idを指しています。
GET qiita/_doc/J32eLXYB4YEI6IRIxT4f
以下のような形式のものが返却されます。
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "J32eLXYB4YEI6IRIxT4f",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Elasticsearchチュートリアル書いてみた",
"description" : "チュートリアルです。みんな見てね。",
"screen_name" : "mayoxmayo"
}
}
全件出したい場合は以下のようにしてください。
以下の文をコピペして実行してみましょう。
GET qiita/_search
以下のような形式のものが返却されます。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "2434",
"_score" : 1.0,
"_source" : {
"title" : "アドベントカレンダーxx日目のタイトル",
"description" : "どうも初めまして。xxと申します。",
"screen_name" : "k-waragai"
}
},
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "J32eLXYB4YEI6IRIxT4f",
"_score" : 1.0,
"_source" : {
"title" : "Elasticsearchチュートリアル書いてみた",
"description" : "チュートリアルです。みんな見てね。",
"screen_name" : "mayoxmayo"
}
}
]
}
}
今までとは異なり、_searchというものを利用しました。
では、_idを指定せず_idを忘れてしまった場合どう検索するか。
通常の検索方法を試します。
6. 検索を行う
k-waragaiユーザーの記事がみたい!という場合は以下のように行います。
コピペして実行してみましょう。
GET qiita/_search?q=screen_name:k-waragai
以下のような形式のものが返却されます。
{
"took" : 49,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2199391,
"hits" : [
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "2434",
"_score" : 1.2199391,
"_source" : {
"title" : "アドベントカレンダーxx日目のタイトル",
"description" : "どうも初めまして。xxと申します。",
"screen_name" : "k-waragai"
}
}
]
}
}
とりあえずキーワード検索したい時は以下のように指定します。
GET qiita/_search?q=初めまして
それではここで返却に関する詳細を説明します。
| key | 説明 |
|---|---|
hits.total.value |
検索結果件数 |
hits.total.relation |
検索結果方式(eq=等しい) |
hits.max_score |
検索結果の重み付けの最大値 |
hits.hits._score |
ヒット時のスコアリング |
ではもっと複雑な検索を行ってみましょう。
descriptionにて「初め」を含まず「チュートリアル」を含んだものを検索した場合は以下のように記述します
GET qiita/_search
{
"query": {
"bool": {
"must": [
{"match": {"description": "初め"}}
],
"must_not": [
{"match": {"description": "チュートリアル"}}
]
}
}
}
データ量が少ないのであれですが、「チュートリアル」は含んでいないですね。
"hits" : [
{
"_index" : "qiita",
"_type" : "_doc",
"_id" : "2434",
"_score" : 1.2730759,
"_source" : {
"title" : "アドベントカレンダーxx日目のタイトル",
"description" : "どうも初めまして。xxと申します。",
"screen_name" : "k-waragai"
}
}
]
rails上で利用する場合
ひとまず簡潔なもので良いのでRailsアプリケーションを作成します。
今回はシンプルに Rails5 + MySQL の構成にします。
構成を以下のように変更します。
Dockerfileが複数存在する為、ディレクトリを作成して分けると読みやすくなると思います。
Railsの準備
**1. ruby用のDockerfileの準備 **
こちらはほぼ公式通りのrubyの記述になります。
PATH: dockerfiles/ruby/Dockerfile
FROM ruby:2.6.2
RUN apt-get update -qq && \
apt-get install -y build-essential libpq-dev nodejs
RUN mkdir /app
WORKDIR /app
COPY Gemfile /app/Gemfile
COPY Gemfile.lock /app/Gemfile.lock
RUN bundle install
COPY . /app
**2. Gemfileの準備 **
Rails6はまだいろいろと分からない部分が多いのでRails5にて行います。
PATH: Gemfile
source 'https://rubygems.org'
gem 'rails', '~> 5.2', '>= 5.2.4.4'
作成が完了しましたらGemfile.lockを作成しましょう。

3. composeファイルの修正
既存のdocker-compose.ymlを修正していきます。
mysql用のservice定義とrubyのサービス定義を追加しています。
またrails appにelasticsearch用のURLを渡したりlinkしたりしています。
version: "3"
services:
elasticsearch-v7.9.3:
container_name: "elasticsearch"
build:
context: .
dockerfile: ./dockerfiles/elasticsearch/Dockerfile
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- logger.deprecation.level=debug
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
ports:
- "9200:9200"
volumes:
- elasticsearch-v7.9.3-data:/usr/share/elasticsearch/data
kibana-v7.9.3:
image: docker.elastic.co/kibana/kibana-oss:7.9.3
ports:
- "5601:5601"
restart: always
environment:
- "ELASTICSEARCH_HOSTS=http://elasticsearch:9200"
database:
container_name: mysql
image: mysql:5.7
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: root
ports:
- "3306:3306"
app:
build:
context: .
dockerfile: ./dockerfiles/ruby/Dockerfile
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200/
MYSQL_HOST: database
command: rails s -p 3000 -b '0.0.0.0'
volumes:
- .:/app
ports:
- "3000:3000"
links:
- database
- elasticsearch-v7.9.3
volumes:
elasticsearch-v7.9.3-data:
driver: local
4. rails new
そうしますと見知った光景になると思われます。
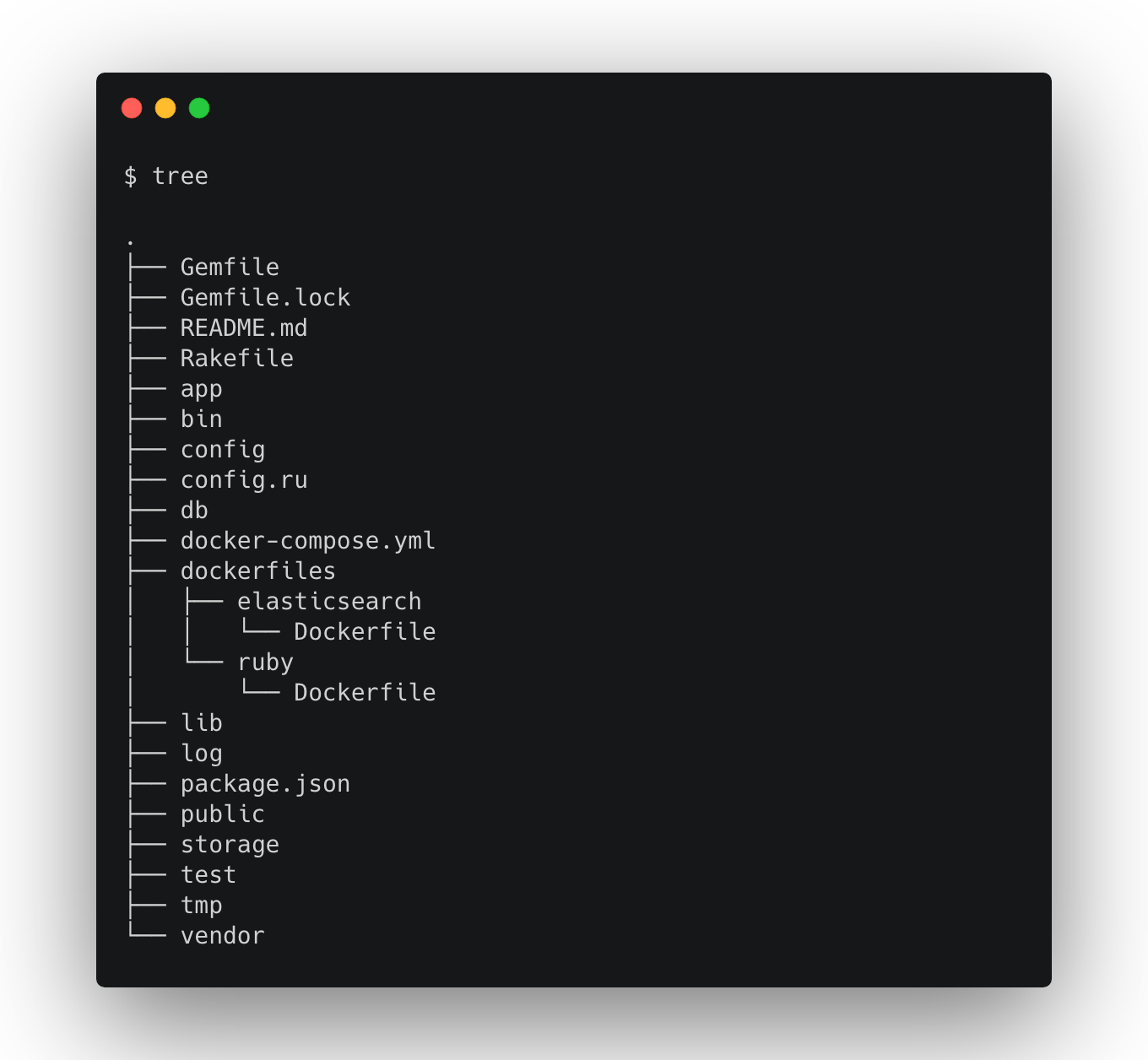
5. configの修正
database.yml の修正を行います。
default: &default
adapter: mysql2
encoding: utf8
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
username: root
password: password
host: database
development:
<<: *default
database: app_development
6. build
bundle install などを行いたい為buildをします。
gemなどを別volumeとして持つというのも良いとは思いますが、今回は更新頻度がそこまで無いと思いますので最小構成で行っています。
7. DB作成
8. docker-composeを起動
localhost:3000へアクセスして以下の画面が出たら準備完了です。
Elasticsearchの準備
1. Gemfileへの追加
elasticsearch関係のGemを挿入します。以下の3つをGemfileに追加してください。
# Elasticsearch関係
gem 'elasticsearch', '~> 7.10'
gem 'elasticsearch-rails', '~> 7.1', '>= 7.1.1'
gem 'elasticsearch-model', '~> 7.1', '>= 7.1.1'
2. bundle install
一度立ち上がっているプロセスをCtrl+Cで終了して以下のコマンドを打ちましょう。
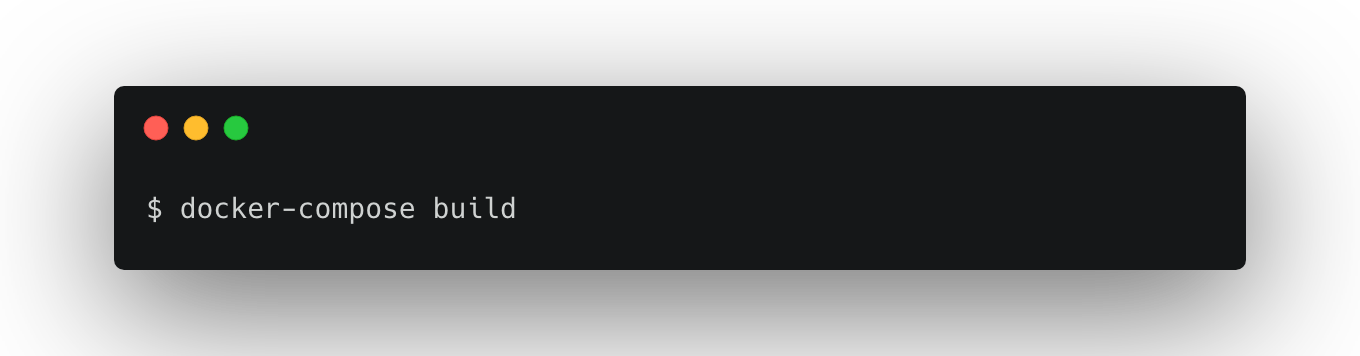
3. モデルの作成
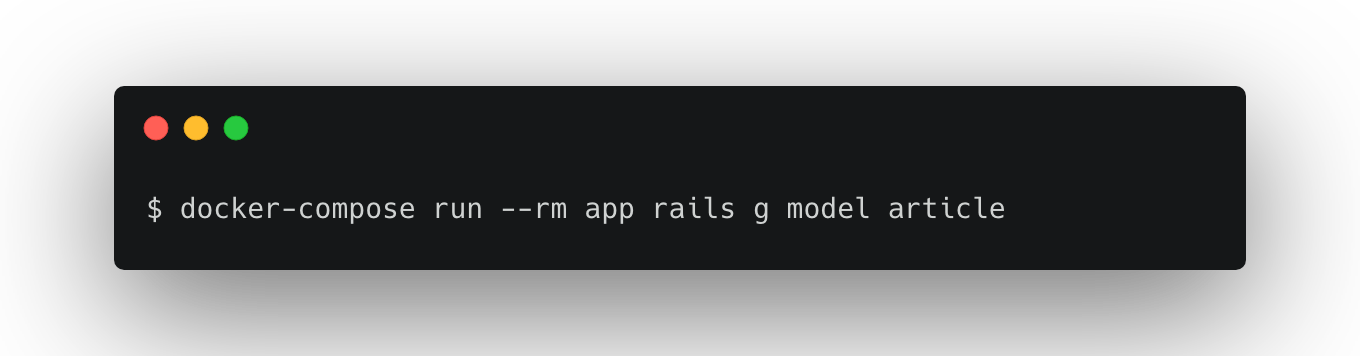
- migrationの変更
class CreateArticles < ActiveRecord::Migration[5.2]
def change
create_table :articles do |t|
t.string :title, null: false, limit: 10, comment: "記事のタイトル"
t.text :description, null: false, comment: "記事の本文"
t.string :screen_name, null: false, comment: "表示名"
t.timestamps
end
end
end
- migrate
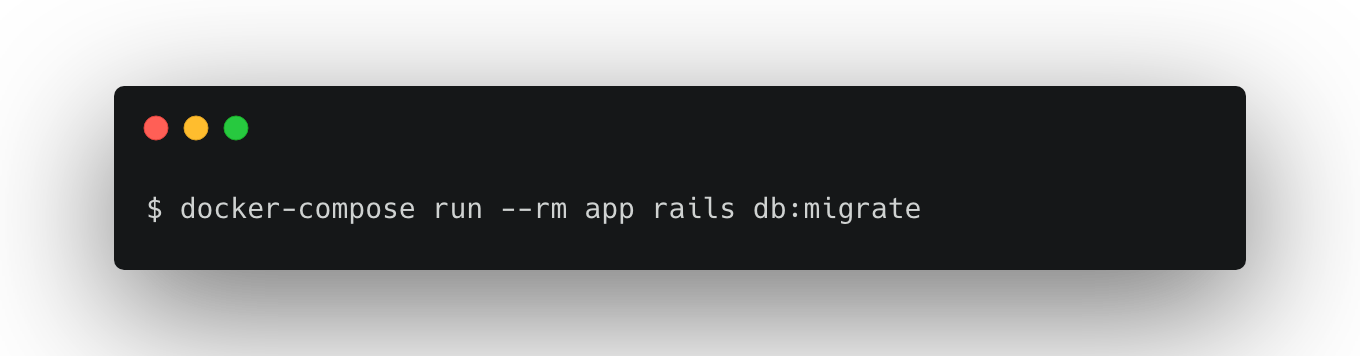
4. データ投入
適当なデータを3件程用意します。
自分はSeedを使って入れましたが、rails consoleから投入でも良いです。
Article.create(
title: "犬の気持ち",
description: "吾輩は犬である。名前はまだない。",
screen_name: "k-waragai"
)
Article.create(
title: "ねこのすべて",
description: "猫はとても気まぐれです。気まぐれロマンティック。構って欲しい時にしか寄ってきません。ぴえん。",
screen_name: "t-suzuki"
)
Article.create(
title: "私VTuberになる",
description: "どうも初めましてVTuberの酢飯マグロです。VTuberを始めて1年経って分かった5つの大事な事を紹介します。",
screen_name: "m-sumeshi"
)
5. elasticsearch-railsを使うためにincludeする
Articleのモデルファイルにinclude Elasticsearch::Modelを追加します。
class Article < ApplicationRecord
include Elasticsearch::Model
end
これを追加することによってmodel.__elasticsearch__.methodsが使えるようになり
importやsearchなどが容易になります。
Elasticsearchへ投入・参照をする
1. consoleへ接続
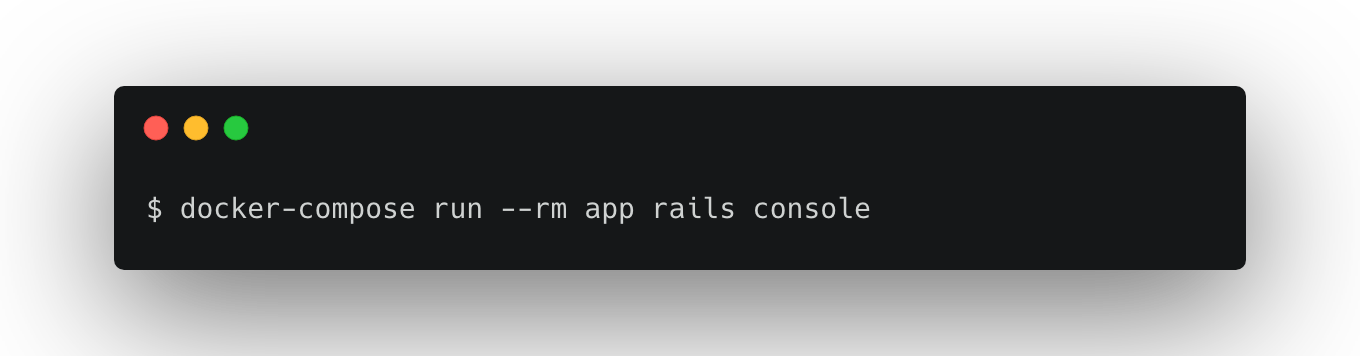
2. indexの作成
create_index!を使うことでindexの作成ができます。
細かいmappingの設定などをする際はsettingとmappingの定義を事前にしておいてそれを元に投入すると良いでしょう。
今回は作ったmodelをそのまま使います。
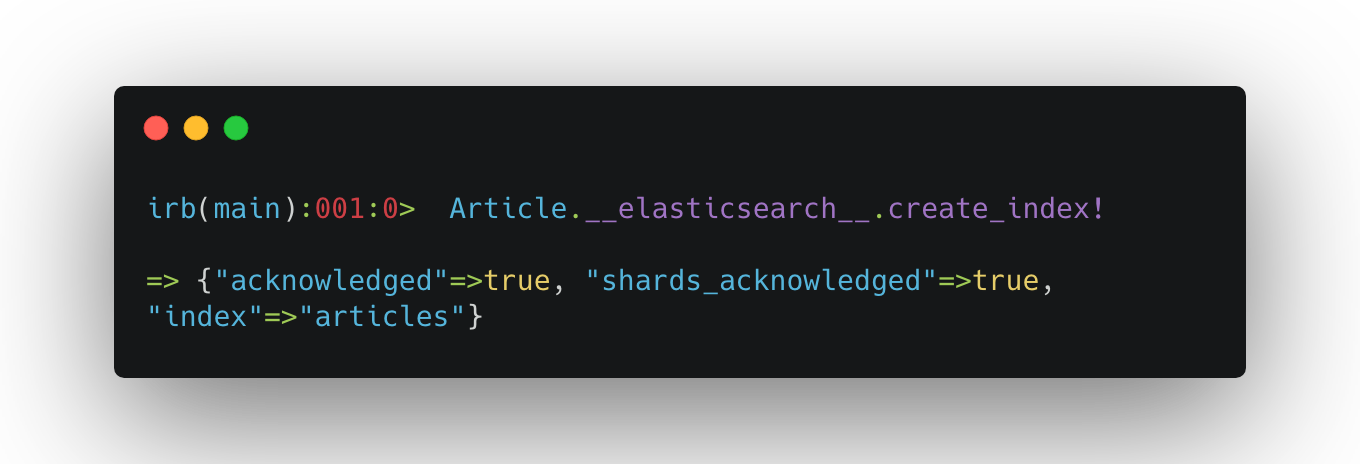
実際にkibanaで確認してみましょう。
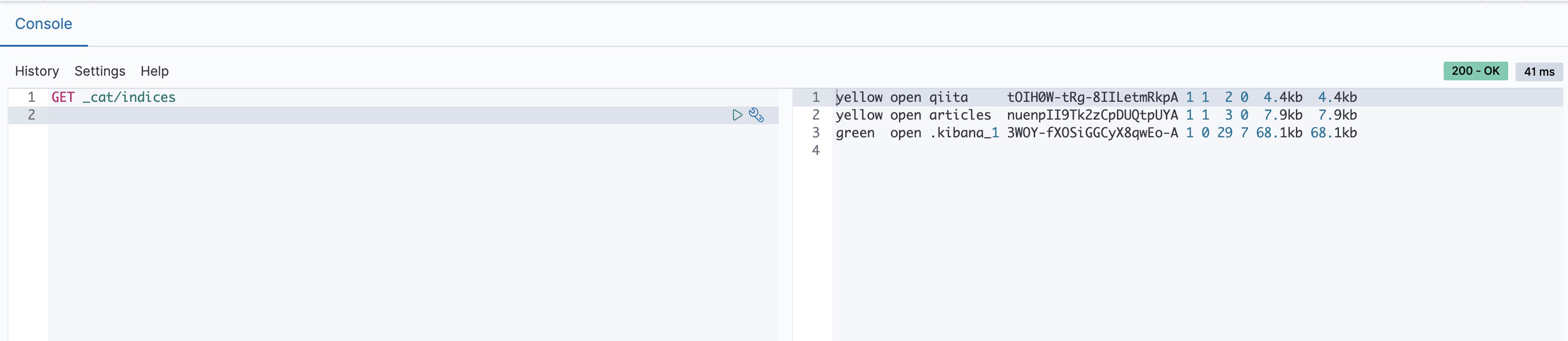
indexが作られていますね。
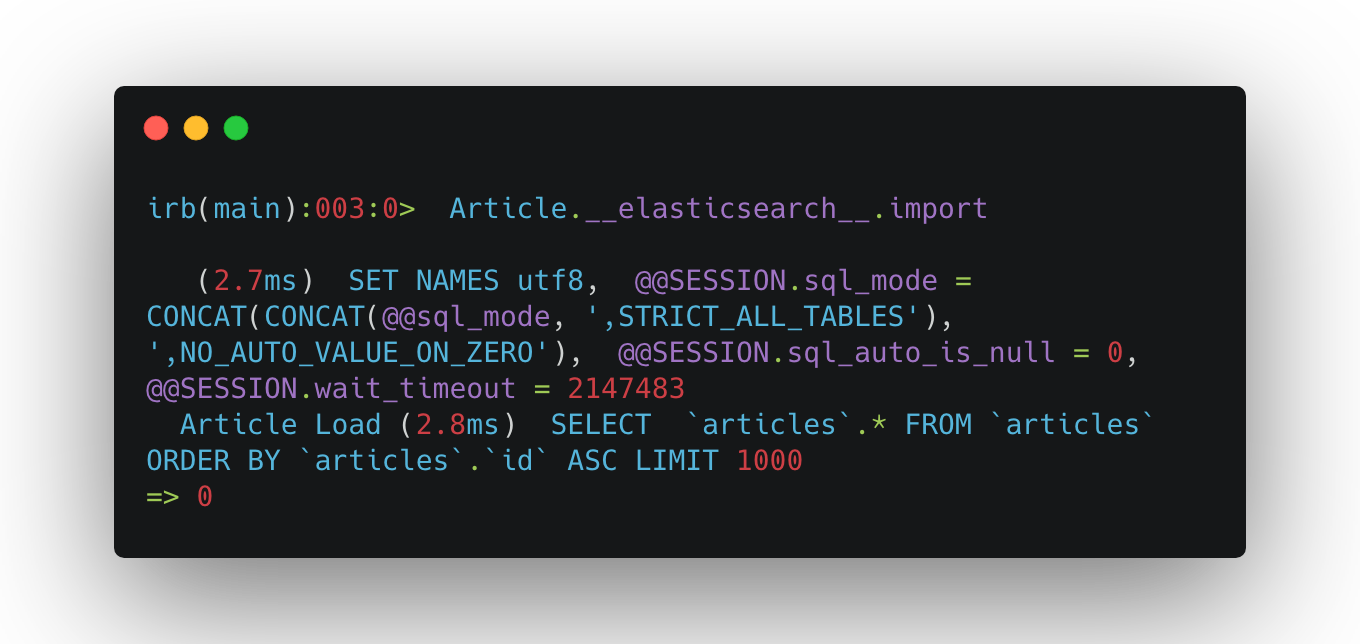
3. データの投入
importを使うだけでデータの投入が可能です。めっちゃ簡単ですね。
実際に index/_search で検索結果も見てみましょう。
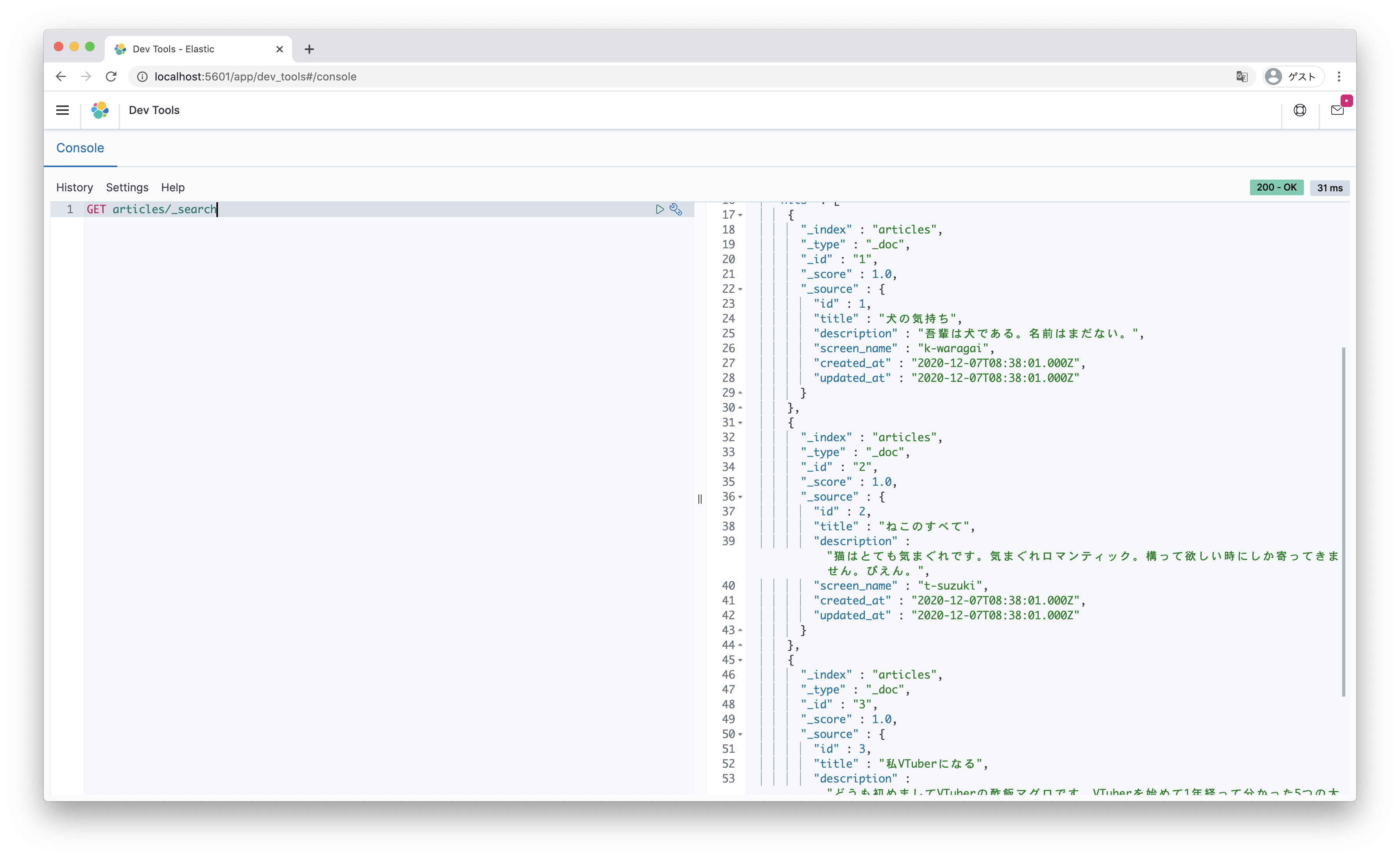
きちんとデータが入っていますね。
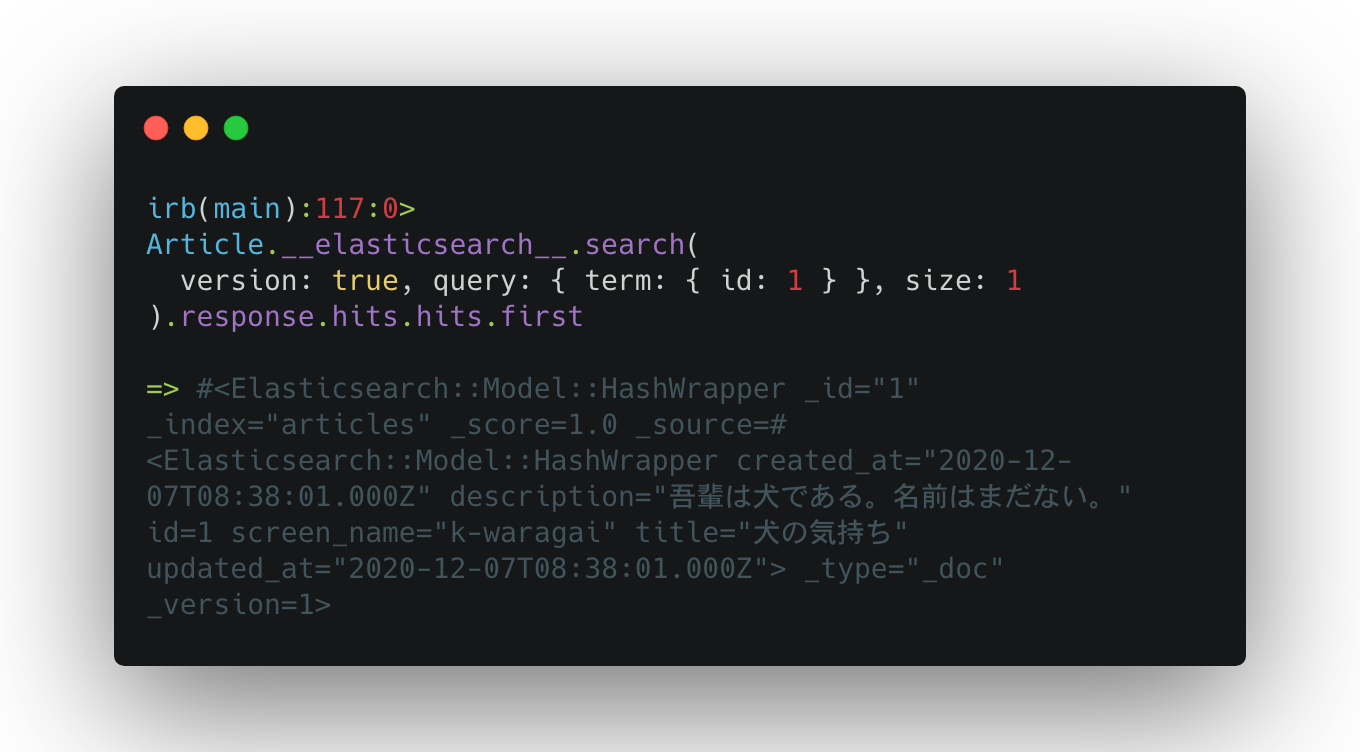
これをrails側で見るには model.__elasticsearch__.search を使います。
Article.__elasticsearch__.search(version: true, query: { term: { id: 1 } }, size: 1).response.hits.hits.first
のような形でクエリを組み立てて検索することが可能です。
4. 削除
もうお分かりだと思いますが、
Article.__elasticsearch__.delete_index! で可能です。
まとめ
Elasticsearchは非常に使い勝手が良いので皆様もこれを機に触ってみてください。
それでは〜また明日〜。