株式会社レコチョク 新卒3年目の早坂と言います。
大規模言語モデル(LLM)を活用したシステムの技術検証を担当しています。
本記事では、音楽業界のメタデータ整備という業務課題を解決するために、LLMを活用したシステム開発の取り組みについて紹介します。
システム開発のナレッジについては記載しませんが、別記事としてこちらに記載します。
対象読者
- システム開発者: LLMやAI技術を用いた開発に興味がある方
- 音楽業界の方: 業界の効率化に対する新しい技術的アプローチに関心がある方
何をシステム化しようとしたか?
音楽業界の業務課題
近年はスマートフォンやサブスクリプション型の楽曲配信サービスの台頭で、より安価で手軽に音楽を楽しめるようになりました。しかし、アーティストにより製作された楽曲がユーザーの元に届くまでの過程には現在も様々な課題が存在します。
以下はレコード会社や個人(以後、楽曲権利者と表記)からユーザーへ楽曲が届けられるまでの大まかなフロー図です。
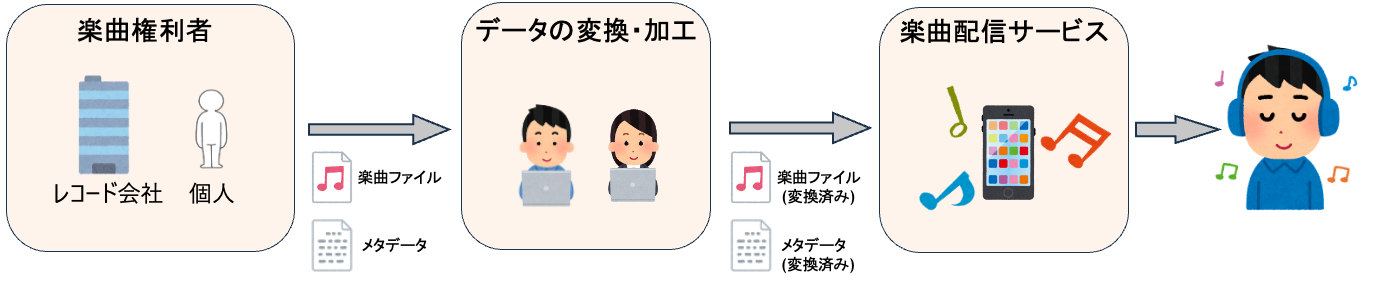
フロー図の中にメタデータという表記がありますが、これは配信する楽曲のタイトル名やバージョン情報、価格、発売日などを示したデータです。
メタデータを定義する規格の代表的なものとして、DDEXという団体により定義されたERN があります。レコチョクを含む多くの音楽配信事業者もこのERNを利用しています。
業務課題の1つとして、上図中のデータの変換・加工と表記しているメタデータの整備があります。現在、楽曲権利者ごとにメタデータの管理体系は異なり、独自の体系が多く、手動で整備を行っているケースが多いです。
ERNは非常に多くのデータを定義する必要があり、かつバージョンも複数定義されています。加えて、代表的なフォーマットとしてERNを挙げましたが、ERN以外にも配信サービスによってメタデータの規格は異なる場合があります。このため、配信サービスによって規格を合わせる必要があります。
メタデータの規格以外にも、記載する楽曲情報にはフォーマットのルールが存在し、ルールに即したメタデータの整備が必要になります。
これらをまとめると、メタデータの整備には以下が必要になります。
- 楽曲権利者独自の管理体系の把握
- フォーマットルールに準拠するように楽曲情報を整備
- 配信サービスが受領できるバージョンや規格に合わせたメタデータの変換
このように単純なデータの作成だけではなく、事前知識の把握や変換作業にもかなりの工数がかかっているのが現状です。このメタデータの整備における作業工数を削減するため、作業のシステム化を検討しました。
今回のターゲット
メタデータの整備をシステム化する、と一言で示しても、前述した通り項目数が多いため、システム化する対象を絞る必要があります。
今回ターゲットとなったのは、楽曲のタイトル情報における作業です。
具体的には、以下の2点です。
- 国内表記のタイトルから、カナ表記、海外向けの表記を作成
- 楽曲のタイトル情報からバージョン情報やアーティストの情報を分割
それぞれのイメージ図が以下になります。
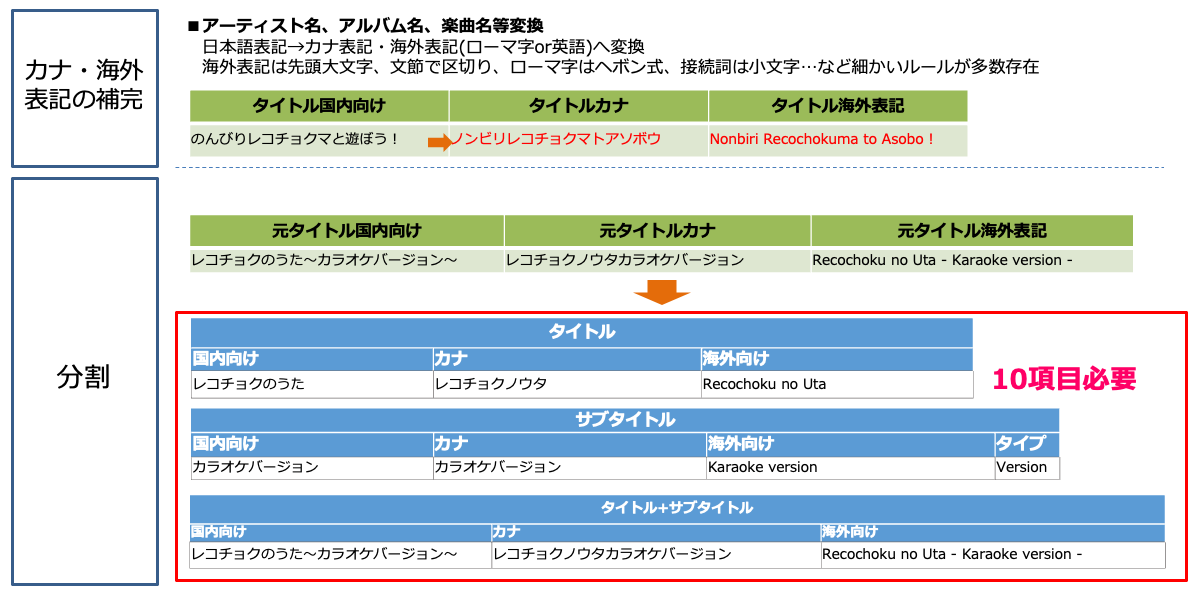
もちろん2点の作業にも、前述したように配信におけるフォーマットのルールが存在します。例えば、Apple社が定義しているスタイルガイドがあります。この中には、英語表記はシカゴスタイル、ローマ字表記はヘボン式とするなどのルールが定義されています。スタイルガイドに沿ったタイトル情報のリフォーマットもシステム化の対象となります。
なぜリフォーマット作業が必要なのかというと、楽曲配信サービスが国内外問わず様々な地域で利用される、いわゆるグローバル化が業界として進んでいることが背景にあります。
日本の楽曲を海外のユーザーがわかるように外国語で表記し、配信したいというニーズが楽曲権利者の中で高まっています。なお、今回上記の作業がターゲットになったのは、ニーズが高く、実現における価値が高いといったことが理由になります。
なぜLLMを活用しようとしたのか?
2023年に話題となったChatGPTを契機として、LLMを業務に活用していく機運がさまざまな業界で高まりました。音楽業界の枠組みである弊社も同様、LLMを積極的に取り入れています。ただ、LLMの活用といっても、大きくに分けて2つあります。
- 人間が直接LLMを使用し、個人のタスクを効率化する
例:プログラムの生成、アイデア生成、意見の壁打ち etc. - システムに組み込み、業務課題を効率化する
例:RAG、チャットボット etc.
今回は2について、
- システムに組み込み、活用はできるのか
- 課題はどのようなものがあるのか
を把握するための技術検証となりました。
また、楽曲のタイトルデータは楽曲権利者が作ったクリエイティブな情報ですが、
自然言語で記述されているケースがほとんどなので、LLMでどれだけ補完、分割ができるのかを判別する検証という意味合いもありました。
やったこと
技術検証における前提
今回のターゲットとなる業務課題で説明した、以下2点を検証しました。
- 国内表記のタイトルから、カナ表記、海外向けの表記を作成(補完処理)
- 楽曲のタイトル情報からバージョン情報やアーティストの情報を分割(分割処理)
目標
以下を掲げ、検証を開始することにしました。
人間の代替となることを前提とし、精度を98%以上を目標とする
意図としては、LLMが現時点でどれだけ活用できるかを確かめるための検証であるため、
目標を高いところに設定してどこまで期待値に近づけるかを確認するものでした。
なお、精度の定義は検証の全体像で後述します。
期間
2023年10月~2024年3月
※技術選定は2023年10月時点で行いましたので、LLMに関する知見もこの時点のものとなります。
検証の全体像
以下が全体像になります。

テストデータ
配信済みの楽曲タイトルデータを利用し、一定の観点で選定したものをテストデータとして採用しました。なお、一定の観点については、LLMが得意な領域と不得意な領域を判別しやすくするため、以下のような観点を用いました。
- 固有名詞(アーティスト名・キャラクター名・アニメ等のコンテンツ名)を含む
- 言語(日本語のみで構成されたタイトル、英語のみのもの、日本語と英語が混ざったもの)
- ジャンル(ボカロ、お経等)
etc..
上記の観点を基に、約500曲をテストデータとして用意しました。
精度の定義
事前に正解のタイトルデータを用意しておき、正解データとの完全一致を判定し、その結果を精度としていました。
精度を98%以上に向上させるため、プロンプトの具体的な表現を調整し、誤解釈を減らすよう実装を改善しました。
システム構成
- インフラ環境
- Amazon EC2
- Amazon S3
- Amazon Cloud Watch
- アプリケーション環境
- Python
- Fast API
- Lang Chain(プロンプトテンプレートの使用)
- Google Custom Search API(タイトル中の固有名詞の読み検索)
- Python

使用したLLMのモデル
Azure Open AIのgpt-4-32k(0613)を使用しました。
検証結果
精度
今回対象となった補完、分割ともに30%~60%ほどの精度となりました。
この30%ほどのゆれは、主にLLMの出力が不安定であることが主な原因です。
結果として、人間の代替を前提とする98%の精度には至りませんでした。
しかし、現状のLLMにおける課題が明確になり、LLMを活用したシステムの考え方を変えるきっかけとなったため、技術検証としては1つの成果となりました。以降はこの結果となった原因、考察として検証の対象となったタスクの不確実性とLLMの活用に関して記載します。
なぜこの結果になったのか?
不正解と異なったケースの傾向
- 一般的な読みではない漢字を含む場合
- 固有名詞
- 常用漢字ではない漢字
- 人間でも判断が分かれる場合
- バージョン情報の分割における境界線
- LLMの出力ゆれ(同じ入力値、プロンプトでも、出力の内容がリクエストごとに異なる)
- 英訳する指示をしても、日本語のまま出力されるなど、プロンプトに記載した指示内容に従わない
- 入力のタイトル情報の一部を無視した出力がある
総じて、課題は
- 入力情報の多様さや複雑さによる不確実性
- LLMの出力の不確実性
にまとめられます。
考察
そもそもシステム開発は、要件や設計を明確に定義することで不確実性を減らし、どんな入力値、条件においても確実に想定しているタスクを実行させるように構築することが重要です。
しかし今回のケースでは、以下のように入力から処理、評価まで各所に不確実性が存在していたため、精度を向上させることが難しかったと考えられます。
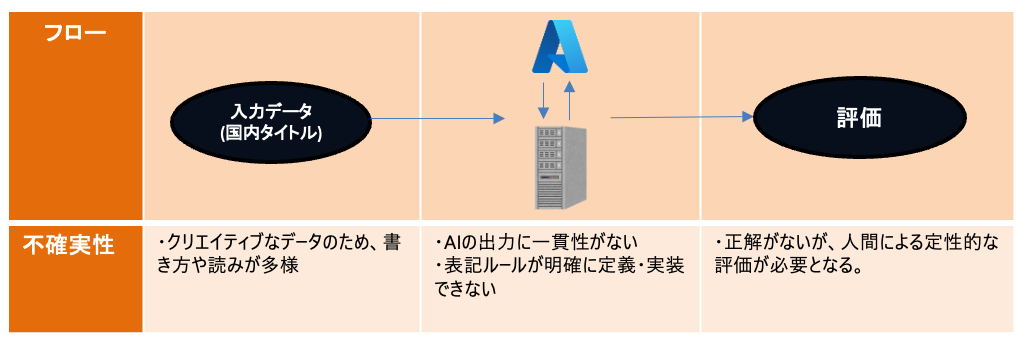
入力データである楽曲のタイトルは、楽曲権利者が独自に定めた表記や読みが存在するクリエイティブな情報とも言えるものなので、入力データにおける不確実性が非常に高いです。また、LLMにおける出力も一貫性がなく、表記ルールでさえもタイトルによって個別のルールが必要な場合もあるため、ここも不確実性が高いです。さらに、出力の評価もこれまでのフローでの確実性がないため、一貫した観点は存在しないです。
この中で唯一確実性があるのはプログラミングによるロジックですが、多様なケースが考えられる入力値に対応しきるのが難しかったと考えられます。また、入力値の制限等を設けて不確実性を減らすのは業務効率改善からは遠ざかりますし、人間の代替を目指していたこともあるので取れる選択肢ではありませんでした。
検証を経て上でのLLM活用における考え方
今回の技術検証では、LLMを用いたシステムが人間の代替となることを目標として進めていました。しかし、LLMに人間が期待する固定値のアウトプットを出力し続けることを求めるのは現状難しいという結論となりました。
よって、LLMを作業の代替とするのではなく、LLMのアウトプットをどう活用するかが重要ということになります。アイデア生成のような使い方をすることで作業のヒントを得たりするような、いわゆる補助の役割を担うツールとしての活用になると思います。言い換えると、LLMを活用したシステムでは、これまでDXとして考えられてきたような作業を完全に代替するようなユーザ体験ではなく、LLMを活用したユーザ体験をどう定義するかが重要な考え方になると思います。
今後の展望
前述した不確実性を踏まえると、システムによる完全な代替は非常に難しいタスクであったとも言えます。
ただ、人間の完全な代替はできずとも、今後は人間の補助システムという位置付けのもと、引き続き検証を進めることを検討しています。また、今回対象となった楽曲のタイトル情報だけではなく、手作業で行われているメタデータの整備は数多く存在しているので、これらに関しても効率化に向けたシステムの設計及び検証は今後も進めていく方針です。
まとめ
楽曲配信作業の効率化に向けて、LLMを用いた技術検証を行いました。LLMを含め生成AIの領域は進化が早く、モデルのアップデートや活用ナレッジもさらに増えていくことと思います。
レコチョクとしても、引き続き音楽業界の課題解決にむけて生成AI領域の情報収集や活用を進めていきます。
本記事に記載した取り組みを基にした開発のナレッジも記事にしましたので、こちらもぜひご覧ください。
最後まで読んでいただき、ありがとうございました!