はじめに
この記事は スタンバイ Advent Calendar 2021 の15日目の記事です。
昨日の記事は @Nisi さんの【空冷自作PC】Ryzen7 5700G + ASRock DeskMini X300をノクチュア NH-P1でファンレスにした話でした。
概要
気象庁では、全国の観測点で記録した過去の気象データを公開しています。
一度に入手可能なデータ量に制限はありますが、
ユーザー登録無しで全国のアメダスのデータが無償で使えるのはとても素晴らしいです。
しかし、天気概況(晴、快晴、雨、大雨など)の種類が非常に細かく
(2020年東京の6時〜18時の気象概況では年間58種類使われている)
例えば、晴、雨、その中間の3分類程度で売上を比較したい、といった用途にはいささか不便です。
そこで、本記事では、気圧等の数値データに基づいて、一日の天気概況表現を再分類する方法を検討しました。
Contents
- データの入手
- データの概要
- データの加工
データの入手
過去の気象データは無料で入手出来ます。以下のようなフォームが用意されているので、
- 地点
- 項目(気温、気圧など)
- 期間
- 表示オプション
を選択し、CSVファイルをダウンロードでデータ入手完了です。
なお、本記事では、以下の条件で取得したデータを使用します
- 地点:東京
- 項目:日平均気温、最高気温、最低気温、降水量の日合計、日照時間、日最深積雪、日平均風速、日平均現地気圧、日平均相対湿度、天気概況(昼:06時~18時)
- 期間: 2020年1月1日〜2020年12月31日
ファイルの文字コードがShiftJISなので、必要に応じて文字コードを変換して下さい。
データの概要
早速、Pandasデータフレームに読み込んでみます。
# 必要なライブラリのインポート
import pandas as pd
# データの読み込み
df_weather = pd.read_csv('path/do/datadir/data.csv')
df_head()
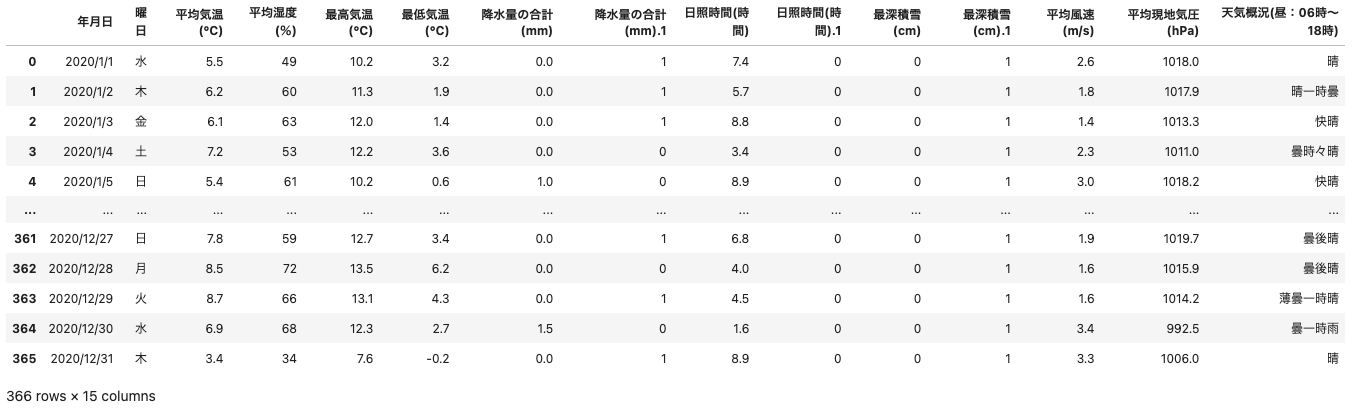
2020年はうるう年なので366行、問題なくデータを読み込めています。
次に、天気概況の分類をみてみます。
df_weather['天気概況(昼:06時〜18時)'].unique()
array(['晴', '晴一時曇', '快晴', '曇時々晴', '晴後一時曇', '曇後雨', '曇一時雨', '曇後晴', '曇後一時雨',
'雨一時晴', '曇', '雨時々みぞれ一時雪', '曇後一時晴', '雨', '雨後曇', '晴一時雨', '晴時々曇',
'薄曇時々晴', '薄曇後一時晴', '曇一時雨後晴', '薄曇', '雨時々曇', '晴後薄曇', '晴後一時薄曇',
'曇時々晴後一時雨', '曇時々雨', '曇一時晴', '晴一時薄曇', '晴後一時雨', '雨後雪時々みぞれ',
'曇一時雨後時々晴', '雨時々雪後一時曇、みぞれを伴う', '曇後雨一時晴', '晴後曇', '晴後時々曇', '大雨',
'薄曇一時晴', '晴後曇時々雨', '晴時々薄曇', '曇後一時雨、雷を伴う', '曇時々雨、雷を伴う', '雨一時曇',
'曇時々雨後晴', '曇時々晴一時雨、雷を伴う', '曇、雷を伴う', '曇一時雨後一時晴', '雨後時々曇', '曇時々雨一時晴',
'曇後時々雨', '晴後曇一時雨、雷を伴う', '晴後時々曇一時雨、雷を伴う', '晴、雷を伴う', '曇時々大雨、雷を伴う',
'晴時々曇一時雨', '曇時々雨一時晴、雷を伴う', '曇時々晴一時雨', '曇一時晴後雨', '曇後時々晴'],
dtype=object)
「時々」、「一時」等と組み合わさって、こんな分類になるのね。
種類の数は
len(df_weather['天気概況(昼:06時〜18時)'].unique())
58
58種類も!! 細かすぎる、、、。
天気予報でよく出てくる「時々」と「一時」の定義について
時々: 断続的かつその時間が予報期間の1/2未満の場合
一時: 連続的かつその時間が予報期間の1/4未満の場合
データの加工
いよいよ天気概況を再分類します。
今回は、雨、晴、その中間の3つ程度に再分類したいと思います。
この程度の分類であれば、以下の予想をもとに、再分類を進めれそう(な気がします)。
- 天候を左右するのは、気圧と湿度、風速ではないか
- 似たような天気のときは、似たような値の組み合わせになるはず
似たようなものの分類、そう、クラスター分析の出番ですね。
クラスター分析 (Try1)
今回は、k-means法を使います。分析コードは以下の通り。
# 必要なライブラリを読み込む
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# クラスター分析に使用するカラムだけ抜き出す
df_analytics = df_weather[['平均現地気圧(hPa)','平均湿度(%)','平均風速(m/s)']]
# パラメータ間のオーダーをあわせるために値を標準化する
sc = StandardScalar()
df_analytics_std = sc.transform(df_analytics)
# k-means法によるクラスタ分析
kmeans = KMeans(init='random', n_clusters=3, random_state=0)
kmeans.fit(df_analytics_std)
labels = pd.Series(kmeans.labels_, name='cluster_number')
# 各クラスタのメンバー数を確認
print(labels.value_counts(sort=False))
1 136
2 168
0 62
Name: cluster_number, dtype: int64
# クラスター番号を結合
df_weather_lbl = pd.concat([df_weather, labels], axis=1)
各クラスターの天気概況(昼:06時〜18時)で使われている表現を見てみます。
# クラスター番号0
df_weather_class0 = df_weather_lbl[df_weather_lbl['cluster_number'] == 0]['天気概況(昼:06時〜18時)'].unique()
df_weather_class0
array(['晴後一時曇', '晴', '快晴', '曇時々晴後一時雨', '晴一時曇', '晴後一時雨', '薄曇時々晴', '曇',
'曇時々雨', '晴一時薄曇', '晴時々薄曇', '薄曇', '雨一時曇', '曇後雨', '曇後晴', '雨時々曇',
'晴時々曇一時雨', '曇時々雨、雷を伴う', '曇一時晴', '曇一時雨'], dtype=object)
# クラスター番号1
df_weather_class1 = df_weather_lbl[df_weather_lbl['cluster_number'] == 1]['天気概況(昼:06時〜18時)'].unique()
df_weather_class1
array(['晴', '晴一時曇', '快晴', '曇時々晴', '晴後一時曇', '曇後雨', '曇後晴', '曇', '曇後一時晴',
'雨', '雨後曇', '晴時々曇', '薄曇時々晴', '薄曇後一時晴', '曇一時雨後晴', '曇後一時雨', '薄曇',
'晴後薄曇', '晴後一時薄曇', '曇一時晴', '晴一時薄曇', '曇時々雨', '曇一時雨後時々晴', '晴後曇',
'晴後時々曇', '薄曇一時晴', '曇一時晴後雨', '曇後時々晴', '雨後時々曇', '曇一時雨'], dtype=object)
# クラスター番号2
df_weather_class2 = df_weather_lbl[df_weather_lbl['cluster_number'] == 2]['天気概況(昼:06時〜18時)'].unique()
df_weather_class2
array(['曇一時雨', '曇後一時雨', '快晴', '雨一時晴', '雨時々みぞれ一時雪', '雨', '晴一時雨', '晴',
'雨時々曇', '曇後晴', '曇時々雨', '曇一時晴', '雨後雪時々みぞれ', '晴後一時曇',
'雨時々雪後一時曇、みぞれを伴う', '曇後雨一時晴', '大雨', '曇', '晴後曇時々雨', '曇後雨',
'曇後一時雨、雷を伴う', '雨後曇', '曇時々晴', '曇時々雨、雷を伴う', '晴時々曇', '曇時々雨後晴', '晴一時曇',
'薄曇', '曇時々晴一時雨、雷を伴う', '曇後一時晴', '薄曇時々晴', '曇、雷を伴う', '曇一時雨後一時晴',
'雨一時曇', '雨後時々曇', '曇時々雨一時晴', '曇後時々雨', '晴後曇一時雨、雷を伴う',
'晴後時々曇一時雨、雷を伴う', '晴、雷を伴う', '晴時々薄曇', '曇時々大雨、雷を伴う', '曇時々雨一時晴、雷を伴う',
'晴後一時薄曇', '曇時々晴一時雨', '曇時々晴後一時雨', '晴後薄曇'], dtype=object)
ぱっと見た感じ、各クラスターがどのような天気概況の集団なのか、良くわからないです、、、。
ここで、分類性能を簡易的に評価するため、クラスター間の重複の数を数えてみましょう。
# 重複個数を確認
# 3クラスター重複
len(set(df_weather_class0).intersection(set(df_weather_class1), set(df_weather_class2)))
12
# クラスター0,1重複
len(set(df_weather_class0).intersection(set(df_weather_class1)))
13
# クラスター1,2重複
len(set(df_weather_class1).intersection(set(df_weather_class2)))
21
# クラスター2,0重複
len(set(df_weather_class2).intersection(set(df_weather_class0)))
17
どのクラスターも半分以上他のクラスターと重複しており、うまく分類出来ているとは言い難いです。
改良の余地がありそうです。
クラスター分析 (Try2)
気圧、湿度、風速の値だけで分類が難しい、であれば、パラメータを増やしてみることにします。
試しに、降水量の合計、日照時間を加えてみます。
# クラスター分析に使用するカラムだけ抜き出す
df_analytics = df_weather[['降水量の合計(mm)','日照時間(時間)','平均現地気圧(hPa)','平均湿度(%)','平均風速(m/s)']]
# 先程と同様
# 各クラスタのメンバー数を確認
print(labels.value_counts(sort=False))
0 181
1 149
2 36
Name: cluster_number, dtype: int64
再び、各クラスターの天気概況(昼:06時〜18時)で使われている表現を見てみます。
# クラスター番号0
df_weather_class0 = df_weather_lbl[df_weather_lbl['cluster_number'] == 0]['天気概況(昼:06時〜18時)'].unique()
df_weather_class0
array(['晴', '晴一時曇', '快晴', '曇時々晴', '晴後一時曇', '曇', '晴時々曇', '薄曇時々晴', '薄曇後一時晴',
'曇一時雨後晴', '晴後薄曇', '薄曇', '晴後一時薄曇', '曇時々晴後一時雨', '曇一時晴', '晴一時薄曇',
'晴後一時雨', '晴後曇', '晴後時々曇', '薄曇一時晴', '晴時々薄曇', '曇後晴', '晴、雷を伴う',
'曇後一時晴', '晴一時雨', '曇後時々晴'], dtype=object)
# クラスター番号1
df_weather_class1 = df_weather_lbl[df_weather_lbl['cluster_number'] == 1]['天気概況(昼:06時〜18時)'].unique()
df_weather_class1
array(['曇後雨', '曇一時雨', '曇後晴', '曇後一時雨', '雨一時晴', '雨時々みぞれ一時雪', '曇後一時晴', '雨',
'曇', '雨後曇', '薄曇', '雨時々曇', '曇時々雨', '曇一時晴', '曇一時雨後時々晴', '曇後雨一時晴',
'晴後曇時々雨', '曇後一時雨、雷を伴う', '曇時々雨、雷を伴う', '曇時々雨後晴', '曇時々晴一時雨、雷を伴う',
'曇、雷を伴う', '曇一時雨後一時晴', '晴一時曇', '曇後時々雨', '晴', '晴時々曇', '晴後曇一時雨、雷を伴う',
'晴後時々曇一時雨、雷を伴う', '曇時々晴', '晴時々曇一時雨', '曇時々晴一時雨', '晴一時雨', '曇一時晴後雨',
'曇時々晴後一時雨', '雨後時々曇', '晴後薄曇', '薄曇一時晴'], dtype=object)
# クラスター番号2
df_weather_class2 = df_weather_lbl[df_weather_lbl['cluster_number'] == 2]['天気概況(昼:06時〜18時)'].unique()
df_weather_class2
array(['雨', '晴一時雨', '雨時々曇', '雨後雪時々みぞれ', '曇時々雨', '雨時々雪後一時曇、みぞれを伴う', '大雨',
'雨一時曇', '曇後雨', '雨後曇', '雨後時々曇', '曇時々雨一時晴', '曇時々大雨、雷を伴う',
'曇時々雨一時晴、雷を伴う', '曇時々雨、雷を伴う', '曇'], dtype=object)
ぱっと見た感じ、おおよそ
- クラスター番号0 : 晴
- クラスター番号2 : 雨
- クラスター番号1 : 中間
のように再分類出来ていそうです。
先程と同じように、クラスター間の重複をカウントしてみます。
# 重複個数を確認
# 3クラスター重複
len(set(df_weather_class0).intersection(set(df_weather_class1), set(df_weather_class2)))
2
# クラスター0,1重複
len(set(df_weather_class0).intersection(set(df_weather_class1)))
13
# クラスター1,2重複
len(set(df_weather_class1).intersection(set(df_weather_class2)))
9
# クラスター2,0重複
len(set(df_weather_class2).intersection(set(df_weather_class0)))
2
先程と比較してだいぶクラスター間の重複を減らせたのではないかと思います。
まとめ
- 降水量合計、日照時間、平均現地気圧、平均風速、平均湿度をもとに、天気概況を3分類程度に分けられそう。
- 他の地域でも試してみたい。(例えば、北海道など)