はじめに
「Agentic AI」という言葉が既に一般的になりつつあり、生成AI活用はPoCフェーズから本格的な活用フェーズへと移行が進んでいます。汎用的な領域は各社既に実践しており、ここから勝負を決めるのはどれだけ適切なユースケースを選定できるかという事になります。
技術的に面白いというだけでは当然NGで、適切なイシューの設定とその解決により、本質的な価値を提供するAIエージェントの構築を進めていく必要があります。
今回はAIエージェント活用の具体的なユースケースとして、システムやアプリケーション開発において必ず課題になる、UAT・UX評価におけるAIエージェントの活用について、実際のデモを交えながら書いていきたいと思います。
AIの台頭によりますます加速するシステム・アプリケーション開発
クラウド、各種ローコード・ノーコード環境の整備に加え、AIコーディングの台頭により、システム・アプリケーション開発の速度は速くなる一方です。
私自身、今までであればチームを組んで開発していたような規模のシステムやアプリを1人で開発する機会も多くなりました。
正直、それなりに動く物を作るだけであれば難しくはないのですがボトルネックになるのはその評価です。スクリプトに関しては、コード自体のバグチェックやテストケースの自動生成もAIである程度対応できるためあまり問題にはならないのですが、実際のシステム・アプリケーションの操作感や表示項目など、いわゆるUIに関わる部分は、UATとして人間が評価する必要があります。
システム・アプリケーションの開発に携わった事がある人ならよくわかると思いますが、業務ユーザーの方々は非常に忙しいので、UATを依頼してもなかなか対応してもらえなかったり、本来は様々なステークホルダーの方に使い勝手の面も含めチェックして欲しいものの、実際の所は、一部の方が部分的にしかチェックしておらず、UATの甘さによりリリース直後に様々な改修要望が出るという事もよくあります。
開発側の視点からすると、UATの箇所はユーザー側で担保して欲しいと思う所ではありますが、ユーザー側の視点としても、日々の業務が忙しい中でのUATは非常に負荷が高いため、極力開発側で品質は担保しておいて欲しい(UATは軽くしたい)というのが正直な所だと思います。
私は業務上、BIを構築する事も多いのですが、特にBIの場合は、プルダウン等で様々な条件を選択してレポートを表示させるという形になります。そのため、例えば表示対象項目や種別、日付選択など複数のプルダウンがあった場合、その組み合わせは多岐に渡るため、それらを全て手動でチェックするという事はできず、実際にはいくつかの境界値の組み合わせでの抜き打ちチェックに留まります。
一度リリースしたシステムをそのまま何年も使い続けるという時代であれば、かなりの人員と工数を割いてでも、UATにコストをかけるというのは正しかったのですが、目まぐるしくビジネス環境が変化し、アジャイル型の開発が主流である現代においては、リリースの回数が非常に多くなるため、1回当たりのUATに毎回大きなコストをかける事はできません。
この状況の中で、業務ユーザーがとにかくUATを毎回頑張るという事は現実的ではないため、業務ユーザーに負荷をかけずにどれだけ品質を担保できるかという事が重要になってきます。
RPAやブラウザ操作ツールでE2Eテストのプログラムを書いて自動化すればいいのでは?と思うかもしれませんが、アジャイル型で業務・システム要件やUIが頻繁に更新される状況においては、一度苦労して作ったE2Eテストや回帰テストの賞味期限自体も非常に短くなってしまいます。逆に、変更が大きい場合、既存のテストスクリプトの修正・管理自体に更に工数がかかってしまうという本末転倒な事態になる事も少なくありません。
AIの台頭により、AI実装を含むシステム・アプリケーションの開発が更に加速していく中、品質保証におけるUATのボトルネックをどう解消していくかが今後の大きなテーマの1つになります。
AIエージェントによるブラウザ操作の自動化
このUATの工程にAIエージェントを活用し、これまでかかっていた工数を大幅に下げると共に、人間ではできなかった範囲のチェックも含め、品質を向上させようというのが今回の取り組みです。
開発サイクルが高速化する中、ルールベースのテストスクリプトを管理し続ける事も、業務ユーザーがUATに大きな工数を割く事も難しいため、AIエージェントに可能な限り対応させます。
まず第一に、従来のRPAなどのロジックベースによるE2Eテストとの本質的な違いは、AIエージェントの場合、初めて見るUIにも対応できるという事です。
例えば、業務要件の一つが「システムにID/パスワードでログインして、自社の今年度の売上の推移が見れる事」という場合、これまでの自動化では、事前に対象のセレクタやUI要素、操作手順も全て指定する必要がありましたが、AIエージェントの場合、事前知識なしで、実際にブラウザを操作しながら業務要件が達成できるかをチェックしてくれます。
これは要するに、初めてそのシステムを触るユーザーが、画面を見ながら自分の目的を達成できるかという状況を疑似的に再現してチェックしてくれるという事です。
また、事前に指定された手順で機械的にチェックしていくわけではなく、人間と同様に実際にブラウザを操作しながら、表示されている画面に応じて動的に操作していくので、業務ユーザーと同等の視点でチェックする事ができます。UIが変わっても、即エラーになるという事もありません。
2つ目の大きな利点は、テストケースを自然言語(テキスト)で誰でも書けるという事です。これまでのテストは、QA担当、少なくともエンジニアの仕事という位置付けで、プロジェクトメンバーは限られた工数の中で、フェーズ毎の成果物を部分的にチェックするという形しか取れませんでした。
一方、AIエージェントの場合、テキストの指示で誰でもAIにテストを代替させられるため、業務ユーザーやプロジェクトマネージャー、アーキテクトといったロールの人も、任意のタイミングで自分が気になった箇所を工数を気にせずに確認する事ができます。
それぞれのステークホルダーが自分の気になっている観点をテキストで残しておくと、それ自体がテストケースになるので、多角的な観点でのチェックが可能となり、品質の向上が期待できます。
ビジネス環境の変化が速く、業務要件を最初から全て洗い出すという事が難しくなっている中、開発フェーズごとの成果物をAIエージェントに操作させながら、それぞれのステークホルダーの観点でチェックしていくという事ができれば、上流フェーズからの品質の作り込みが可能となります。
また、エンジニア側からしても、業務要件から漏れていた内容や、例外対応が必要な処理を早期に検知できる機会が増えるため、コミュニケーション・開発効率の向上の点でも大きなメリットとなります。
AIエージェントを活用する事によって、初めて見るUIにも対応できる上に、テストケースを誰でも自然言語で書いて実行できるという事が、これまでにはない大きなメリットになります。
ユースケース検討
長くRPAを含むルールベースの自動化に携わっていた人間からすれば、AIエージェントがブラウザを動的に操作できるという事は大きな転換点であり、上記のようなテストの自動化に加えて、以下のようなユースケースの検討もできます。
UX評価・レポート生成
ブラウザを自動操作できるという特性を活かし、いわゆるE2E的なテストに留まらず、画面デザインを含めたUXの評価にも利用できます。
ロゴやコーポレートカラーが全体として一貫しているか、ユーザー目線で見たときにボタンの配置や導線が直感的に理解できるかなど、指示内容に基づいてAIエージェントがシステム・アプリケーションのUXを評価し、改善ポイントをレポートとして出力できます。
ここで特に強力になるのが、仮想ペルソナによるUX評価です。システム・アプリケーションの実際のユーザーは多様である一方、UATを実施できる人員や工数はどうしても限られてしまうため、評価視点が偏りやすいという課題があります。
この課題に対する一つのアプローチとして、本来であればUATへの参加が難しい人たちの視点をAIで再現し、UXを評価させるという方法を取ります。役員相当、現場社員、新入社員、ITが苦手な方、アプリケーションによっては学生といった視点でUXを評価してもらい「誰にとってどこが分かりにくいのか」を浮き彫りにします。
開発に携わっている人間は、自分たちが作っているシステムであるため、前提知識のない第三者の視点を持ち続けることがどうしても難しくなりますが、仮想ペルソナによるUX評価は、そうした主観を外し、より客観的な意見を取り込む事ができます。
さらに、UXデザインに強い専門家の視点をチェック観点として残しておけば、開発チームはいつでもプロの視点を借りてテストすることができます。同様に、法務やコンプライアンスの観点を定義しておくことで、AIエージェントに遵守すべき各種ルールの一次チェックを実施させるといった使い方も可能になります。
少し規模の大きい組織であれば、UXデザインチームや法務チームがこれらの観点を共通アセットとして整備し、各開発チームに展開する形が望ましいでしょう。個々のプロジェクトによらず、組織全体の品質水準を底上げが期待できます。
このように、自動テストによる品質担保(守り)だけでなく、UX評価を通じた品質改善(攻め)にも応用できます。
システム・アプリケーションの横断チェック
単一のシステム・アプリケーションもそうなのですが、かなり現場目線のユースケースとしてあるのが、複数のシステム・アプリケーションの横断的なチェックです。
というのも、データの利活用が推進されていくと、元データは同一のシステムであるものの、それを元に複数のBIダッシュボードやシステム・アプリケーションがそれぞれの業務要件・利用者の特性に合わせて作成されていきます。
ここでしばしば問題になるのが、元データは同一のはずなのに、システムによって表示されている数値が一致しないというケースです。元データは同一なのですが、各システムのUIに表示されるまでの過程で様々な変換が入り、時には本来想定していないバグも含まれることで、結果的に、システム・アプリケーションによって表示されている値が異なってしまうという事です。
こうなると「こちらのシステムとあちらのBIで売上の数値が合わない」「新規で契約されたはずのクライアント情報が一部のシステムに出ていない」といった形で、関係者間でコミュニケーションに不整合が起きてしまい、データ利活用そのものへの信頼性に影響が出てしまいます。
こういったケースで、複数のシステムやアプリケーションを横断的にAIに操作させて、数値の差異を自動チェックさせるというのは有効な手段となります。
各システムは常にアップデートされるため、このAIエージェントを監視目的でスケジュール稼動させておくと、特定のシステムだけ値が大きくずれているというようなケースも早期に検知できます。
単一のシステムだと、実は数値が合っているかという事を確認するのは難しいのですが、このように相互チェックの枠済みを入れていく事で、システム・アプリケーション環境全体の品質担保が期待できます。
更に現場目線のユースケースで言えば、既存システムのリプレイス対応における現新比較でも利用できます。既に運用中の現行システムとリリース予定の新システムで、UIの差異を吸収しながら、表示されている値に差異がないかという事のチェックに利用できるという事です。
これまでは、テスト担当者が現行システムと新システムでそれぞれ同一の条件を画面上で設定をして、表示された項目の目検チェックをするしかなく、代表的な箇所や境界値チェックを部分的に実施するしかなかったのですが、これもAIエージェントによって工数の制約を外して自動化できるという事です。
例外検知(モンキーテスト)
これはある種一番AIらしい使い方なのですが、AIは人間と違って工数の制約を外して処理が回せるため、モンキーテストに利用する事ができます。モンキーテストとは猿が適当にキーボードを叩く様子に由来し、仕様や手順を無視して、ランダムに操作を行うことで、開発者の想定外のバグや脆弱性を発見するテスト手法です。
E2Eテストは、あくまでテストとして定義された手順のテストなので、そもそも開発者も想定していなかった操作のテストはできません。開発者が想定していなかったボタンの押下組み合わせ、処理の途中でのブラウザ更新・再起動など、実際の利用者は開発者が想定していないケースで利用する事があります。
夜間も含め工数を無視して利用できる利点を活かし、AIエージェントをモンキーテストに利用する事で、例外系処理の品質を高めていく事ができます。
上記はあくまで一例で、おそらくまだまだ私も想定していない様々なユースケースがあると思いますが、自然言語の指示を元にAIがブラウザを自動で操作できるようになったという事は、エンタープライズでの生産性向上・自動化環境の構築においても大きなポテンシャルを秘めていると言えます。
実装概要
今回、ブラウザの自動操作ツールとしてはPlayWright MCPを使います。
実際のところ、MCPは必須ではなくPlayWrightをそのままツールとしてAIと繋いでも大丈夫です。
ただ、近年のツールやモデルの移り替わりの速さを踏まえると、極力スイッチチングコストは低くしておいたほうが良いため、MCPを使うというのも一つだと思います。また、PlayWright以外のブラウザの自動操作ツールもあるため、必ずしもPlayWrightである必要もありません。
MCPにするのか、どのツールにするのかはあまり本質的な問題ではないので、その時々で適切なものを選べば良いと思います。
これをReActエージェントと繋いで、テキストの指示書に基づきブラウザを自動操作させます。
単純に動作させるというだけであればこれだけで良いのですが、特にエンタープライズでの利用においては、必ずやっておかなければならないポイントが2点あります。
ホワイトリストの登録
勘の良い方は既に気付いたかもしれないですが、個人利用であればともかく、組織利用においてAIにブラウザを自動操作させるというのは、野放しでやってしまうと非常にリスクの高い行為となり得ます。
RPAやいわゆる従来型のテストスクリプトであれば、決められた事しか実行しないためある種安全ですが、AIの柔軟性がセキュリティ的な観点においては仇となり、ブラウザ上で本来禁止されている操作をしてしまう可能性があるためです。
これは新入社員に色々と権限を渡してしまうと、社内の情報規程を知らずに本来禁止されている事を実施してしまうのと同様の話です。
確実にやっておくべき事はホワイトリストの登録です。システムやアプリケーション評価の場合、アクセスすべきURLは限られているため、特定のURLだけにAIエージェントがアクセスできるようにホワイトリストに登録しておきます。PlayWrightにはallowed-originsパラメータがあり、このパラメータに特定のURLを登録すると、そのURL以外にはAIエージェントはアクセスできないようにする事ができます(アクセスしようとした段階で落ちる)。
可能であれば専用アカウントを用意して、最小権限を付与させたほうが良いですし、よりセキュアな環境でやるのであれば、VM化して実行環境自体にIP制限をかけるという事も一つでしょう。
ただ、普段から開発でLLMを利用している人達はわかると思いますが、初期の頃のモデルに比べ、最近のLLMは非常に賢いので、禁止事項としてプロンプトに定義しておけば、あえてセキュリティリスクを侵すような大胆な処理を勝手にするというような事はあまりありません。
手放しの状態で利用するのは当然NGですが、デファクトになっているベンダーのLLMを利用している限りは、必要以上に神経質になりすぎる必要もあまりありません。シンプルなホワイトリストの登録でかなりのリスクが逓減できるので、少なくともこちらは確実に実施しておいたほうが良いでしょう。
MFA/SSO対応
近年のシステム・アプリケーションではID/パスワードによる単純なログインではなく、MFA(多要素認証)やSSOによる認証が必須となっているケースが増えています。
操作対象のシステムでMFAが必須の場合、単純にブラウザを起動して自動操作するだけではログインできないため、RPA等の場合も同様ですが、ここがブラウザ自動化における一つの大きなハードルになります。
この点についても、PlayWrightには現実的かつセキュアな手段が用意されており、PlayWrightでは--cdp-endpoint を指定することで、既に起動しているブラウザに後から接続するという使い方が可能です。
CDP(Chrome DevTools Protocol)とは、ブラウザを外部から操作するための公式なプロトコルで、PlayWrightはこの仕組みを利用して既存のブラウザセッションを操作します(Chromeとついていますが、Chromiumベースのブラウザであれば利用可能であるためEdgeも可)。
この方法はMFA自体を回避・無効化するものではなく、あらかじめ人間が通常通りブラウザでログインを行い、MFAを正規に通過した状態のブラウザを起動しておき、そのブラウザに対してPlayWrightが接続するという形です。
これは、ログイン済みのPCを横から操作しているのと本質的には同じで、AIエージェントができる操作範囲も、そのブラウザ・そのアカウントが元々持っている権限の範囲に限定されます。
事前にブラウザを立ち上げて認証しておく必要があるため、一手間必要にはなりますが、MFA/SSO認証を人を介さずにAIが代替してしまうとそもそもの認証の意味がなくなってしまうため、人間による事前承認の位置付けとして実施するのが良いかと思います。
AIエージェントによるブラウザ操作・レポーティングデモ
デモ1. 複数サイトの横断チェック
まずは、複数システム・アプリケーションの横断チェックのデモをやっていきたいと思います。
社内利用の場合は自社システム・アプリケーションの横断チェック、システム刷新における現新比較がメインのユースケースになると思いますが、今回はデモとしてわかりやすくするために公開サイトを使っていきます。
今回は公開サイトを社内システム・アプリケーションに見立ててデモを行いますが、実質的にはログインがあるかないかだけの違いだけなので、本質的なポイントは同じになります。
デモ1-1. 複数サイトでのS&P500の現在値一致確認
複数の金融系サイトをAIエージェントに操作させ、S&P500の現在値が相互に一致しているか確認してみましょう。
AIエージェントが動的にサイトをチェックする事を期待し、指示内容は以下のように簡単なもので行きます。
#指示内容
以下の3つのサイトにアクセスし、S&P500の値にそれぞれ差異がないか確認して下さい。
レポートは日本語で出力して下さい。
Yahoo Finance
https://finance.yahoo.com
Bloomberg
https://www.bloomberg.com/markets
Google Finance
https://www.google.com/finance/
指示内容は上記のみで、対象サイトの画面構成含め前情報は全くない状態でしたが、AIエージェントを起動すると、自身でブラウザを立上げて指定されたサイトに順番にアクセスし、以下のレポートを生成しました。
エビデンスとなるスクリーンショットや操作手順も出力するように共通プロンプトで指示しているので、透明性の高い内容になっています。
<生成されたレポート>
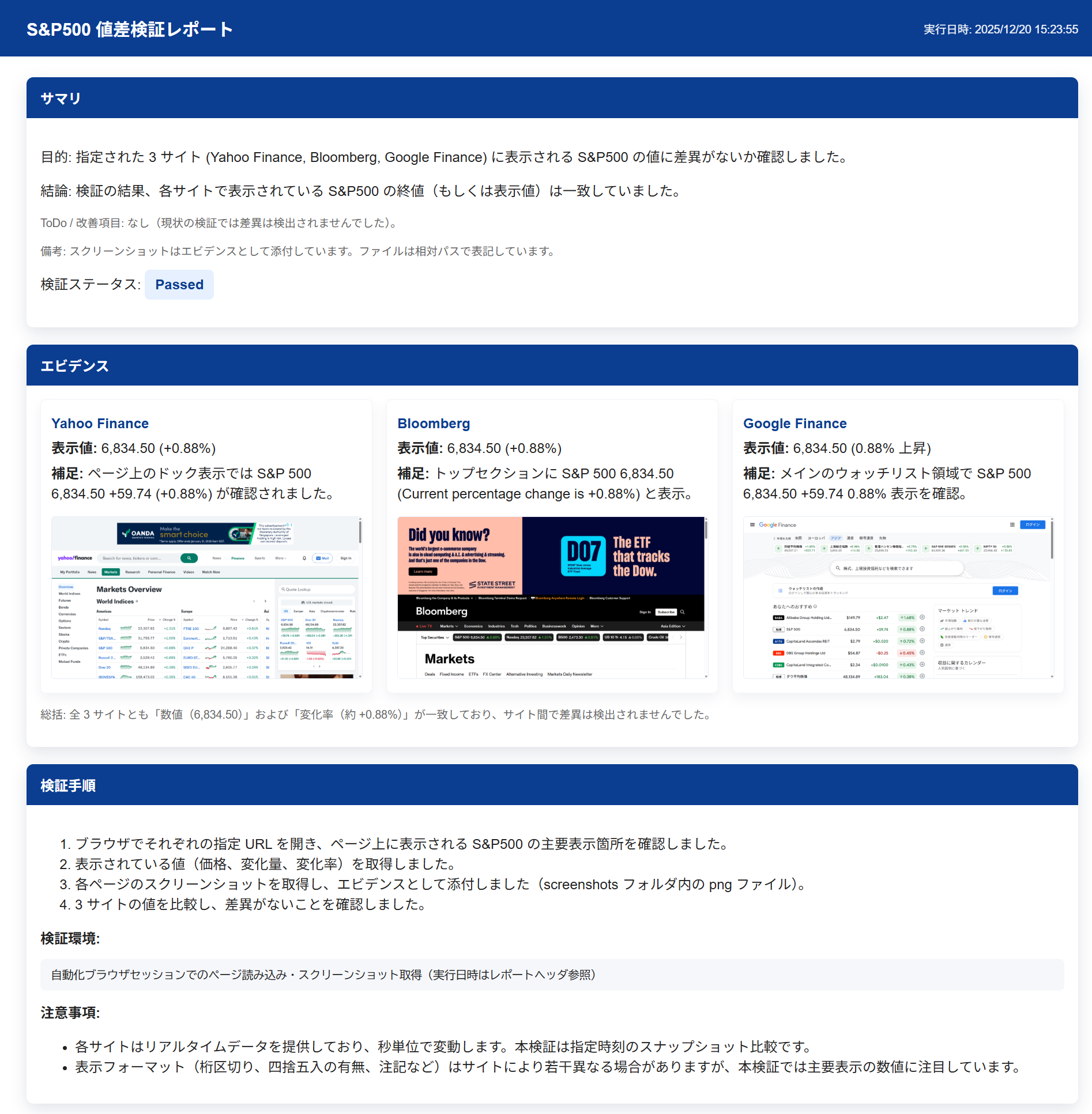
相場が閉じている時間に検証したので、それぞれ問題なく一致している事が確認できます。
デモ1-2. 複数サイトでのUSD/SGDの為替レートの変動確認
続いて、常に変動している為替レートで試してみましょう。
複数サイトに順番にアクセスしているため、正しく動作していればそのタイミングでの差異を捉えてくれるはずです。
指示内容はこちらも以下のようにシンプルな形にします。
# 指示内容
以下のサイトを操作し、USD/SGDの為替に差異がないか確認して下さい。
レポートは日本語で出力して下さい。
Google Finance
https://www.google.com/finance
Yahoo Finance
https://sg.finance.yahoo.com/markets/currencies
こちらも上記の指示通りアクセスし、対象項目を取得していますが、今回はリアルタイムの為替の変動を捉えています。
<生成されたレポート>
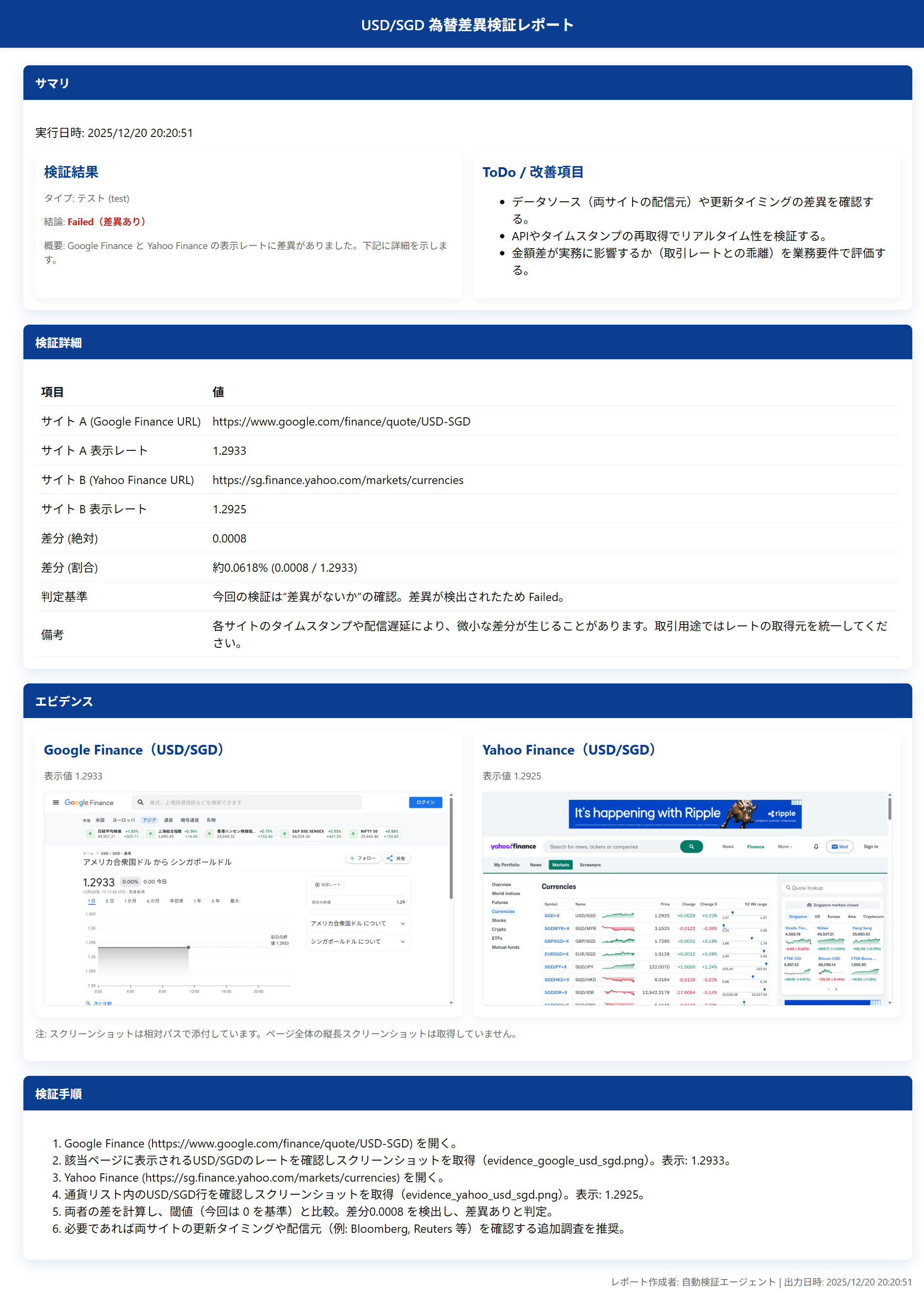
指示内容は守りつつも、単純に差分ありとだけ機械的に表示するのではなく、各サイトのタイムスタンプや配信遅延による影響ではないかという点に言及しているのもAIらしいですね。
このように自然言語の指示をベースに、複数のシステムやサイトの横断的なチェック機構としてAIエージェントを利用する事ができます。これまで目検で対応していたり、工数の関係でそもそもやれていなかったりといったケースも含め、様々なユースケースがあるのではないでしょうか。
デモ2. 仮想ペルソナによるUX評価
続いて、これまでのチェック的な観点でのユースケースとは別に、仮想ペルソナによるUX評価のデモを見ていきます。この点がAIエージェントによる大きな利点の1つであり、静的な数値チェックの文脈を超え、使い勝手などの評価にも利用できます。
対象は何でも良いのですが、今回はAIエージェントのOSSとして最も有名なものの一つであり、私も常時利用しているLangChainのサイトを対象に評価してみましょう。
本サイトに初めて訪れるユーザーを想定し、UXの評価を実施します。
実際のUX評価ではもっとプロンプトを作り込むと思いますが、今回はデモとしてのわかりやすさを優先し、以下のような簡単なプロンプトを利用します。
# 指示内容
以下の各ペルソナの想定で対象のサイト内を操作・ページ遷移し、サイトのUXをペルソナ目線で評価してレポートにまとめて下さい。
トップページから最大10操作程度で評価し、レポートは日本語で出力して下さい。
# 評価観点
⦁ 視認性
⦁ 検索容易性
⦁ レスポンス速度
# 対象サイト
https://www.langchain.com/
# ペルソナ
1. LangChainを始めて調べるユーザー。LangChainにどんな特徴や機能があるのか概要を把握したい。
2. LangChainの導入を検討し始めているユーザー。具体的なプランや価格を知りたい。
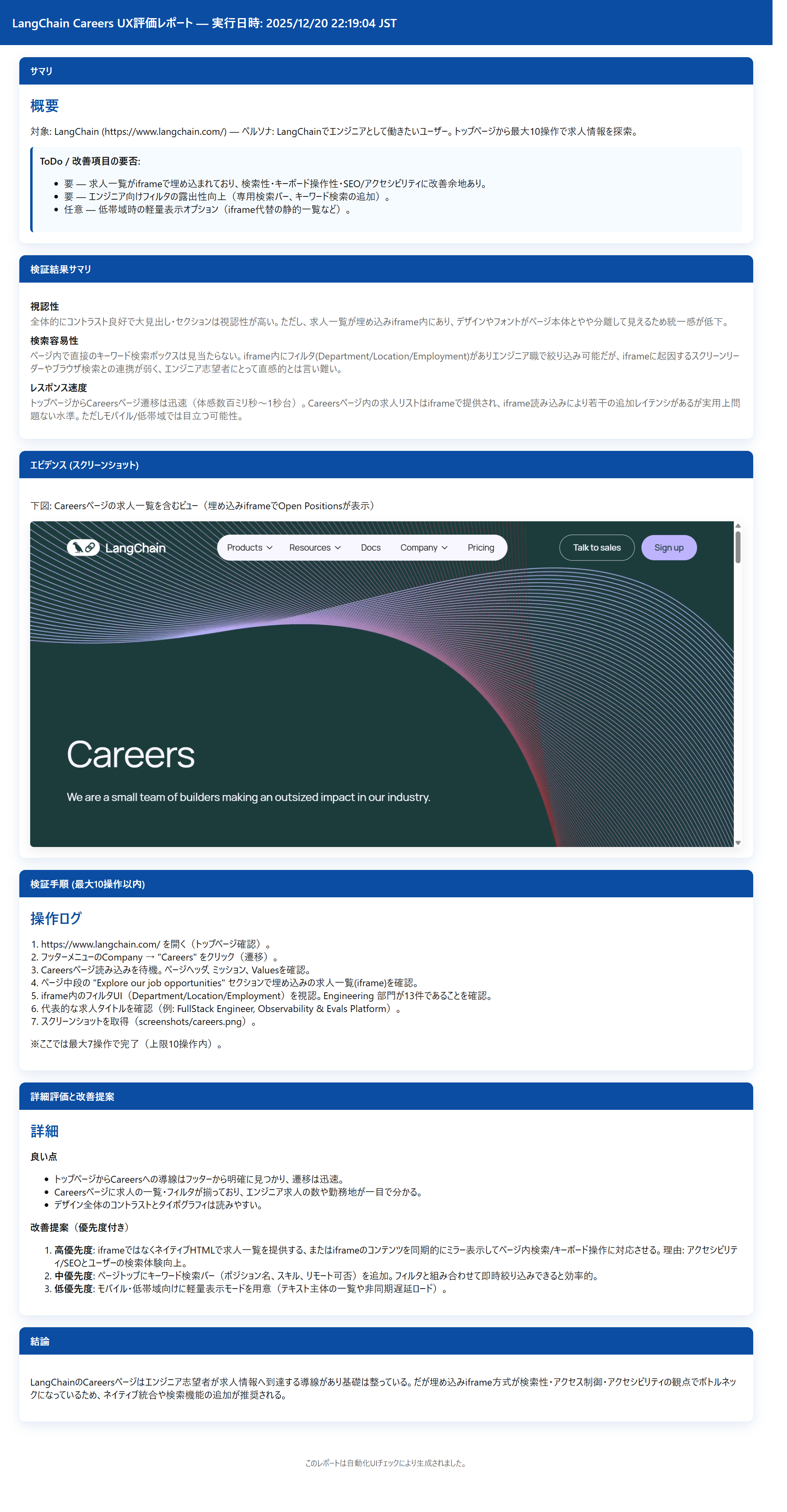
3. LangChainでエンジニアとして働きたいユーザー。具体的な求人情報を知りたい。
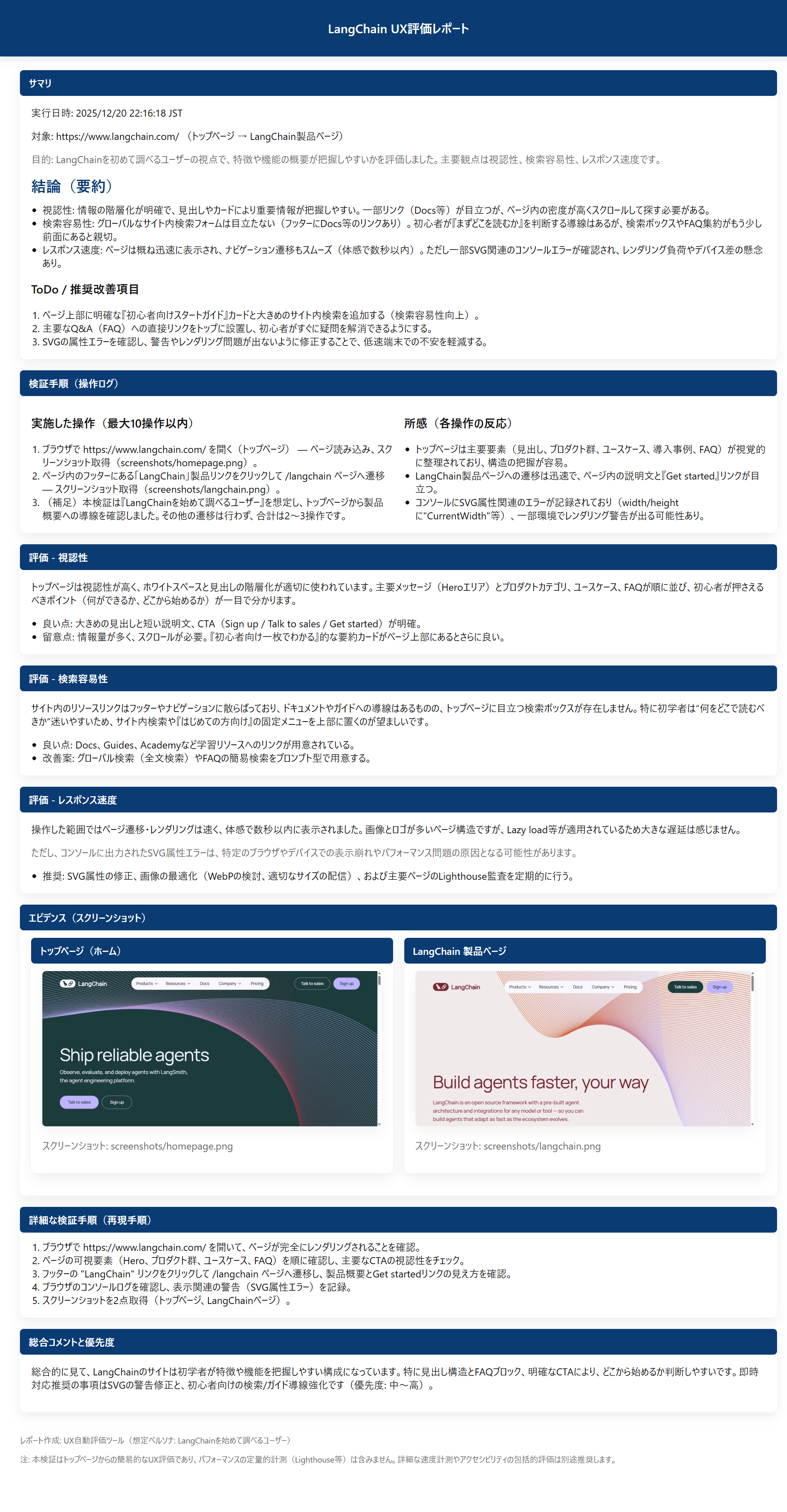
実際に生成されたレポートは以下です。
上記のようなシンプルな指示でしたが、対象のペルソナになりかわってUXを評価してくれています。
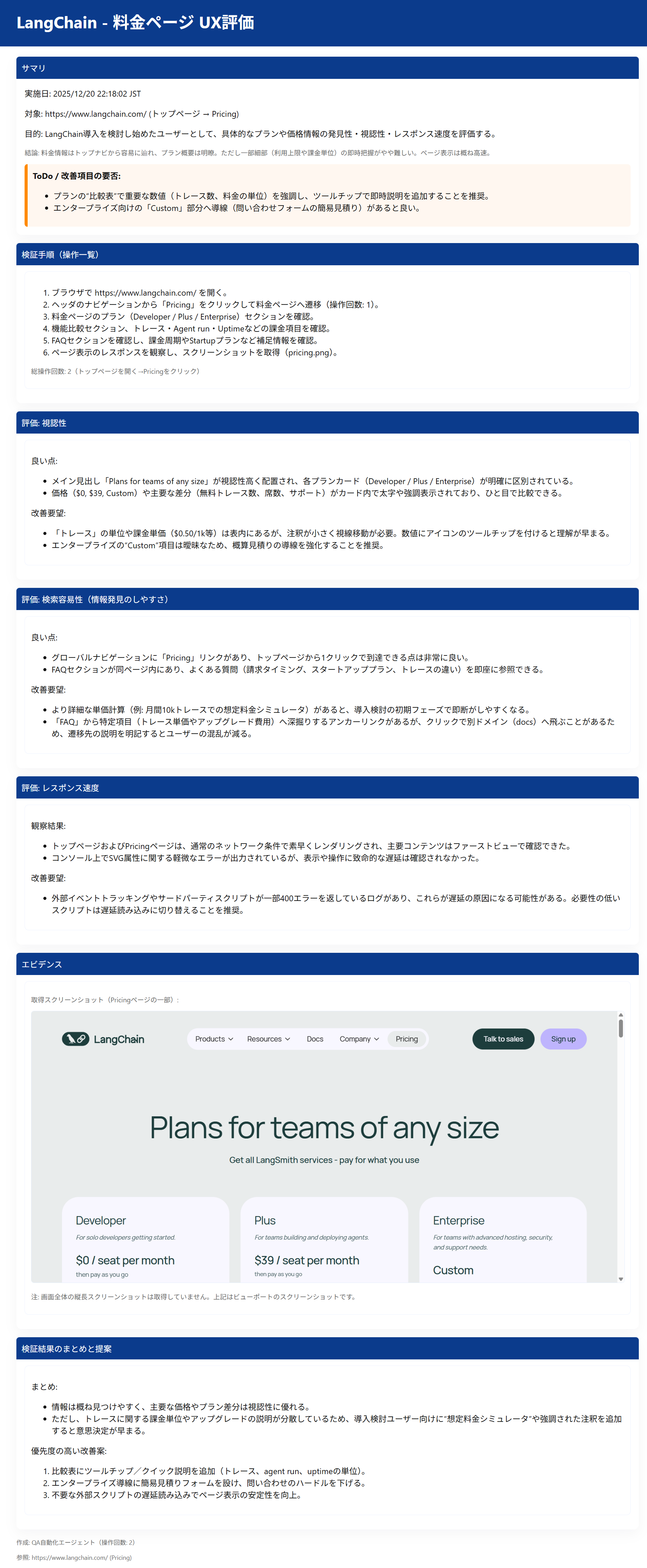
ペルソナ2で、料金プランのEnterpriseがほぼカスタムとなっていてわかりにくいという指摘は、私も以前アクセスした際に同じ事を思っていました。
<生成されたレポート : ペルソナ1>
<生成されたレポート : ペルソナ2>
<生成されたレポート : ペルソナ3>
今回のデモでは、LLMとしてgpt-5-miniモデルを利用し、指示内容もシンプルなものでしたが、高水準モデルで詳細プロンプトを設定すれば更にリッチなUX評価とレポーティングができます。
試行錯誤含め、数多くの検証を回したい場合や、最終チェックとして、コストがかかっても高品質なフィードバックが欲しい場合など、ユースケースに合わせて使用するモデルとプロンプトを調整すれば柔軟なUX評価が実現できます。
またUXのベストプラクティスとチェック項目を共通プロンプトとして作り込み、このAIエージェントを誰でも使える形で展開すれば、組織横断でのシステム・アプリケーション開発時のUXの底上げにも利用できます。
これまでのルールベースのE2Eテストの枠組みを超え、UX評価にも応用できるというのは大きな転換点になるかと思います。
統合ダッシュボードによる横断チェック
テストやUX評価が自動化できるというのは大きな利点ですが、数多くテストを実施する場合などは、各HTMLレポートを一つ一つ開いてテスト結果を確認するという作業自体の負荷も高くなってしまいます。
そのため、StructuredOutputでAIエージェントによるテスト結果の出力形式を指定しておき、以下のように横断的にテスト結果を確認できる状態を構築しておく事が望ましいでしょう。
<統合ダッシュボードサンプル>
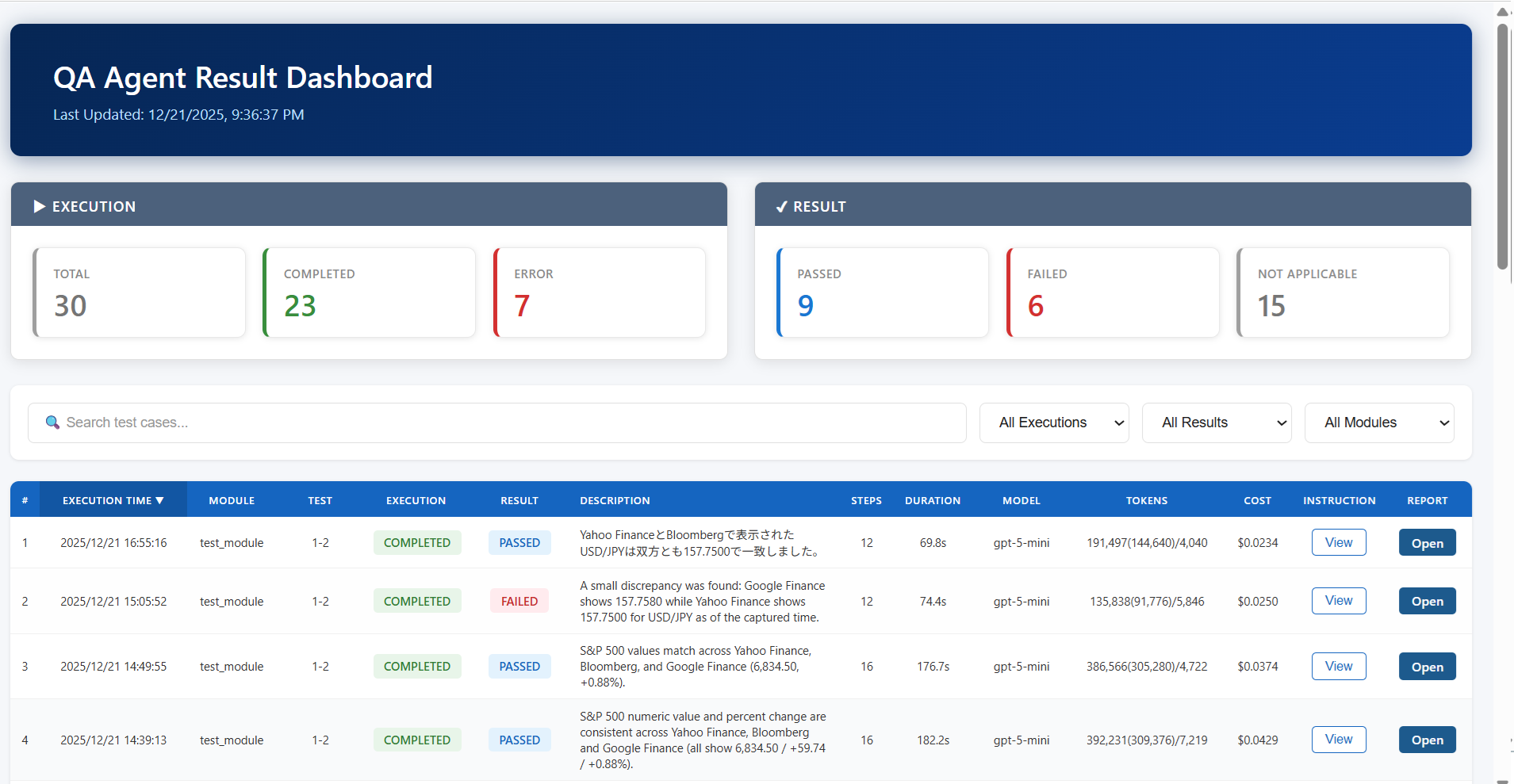
主要な確認項目として、テストの実行時刻と結果、使用モデルとトークン数/コスト等に加え、実行時間や結果の1行サマリを表示させています。
テスト実行時の指示内容をスナップショットとして保持しているため、ポップアップで参照できる形にしています。対象のHTMLレポートもクリックすれば別タブで開きます。
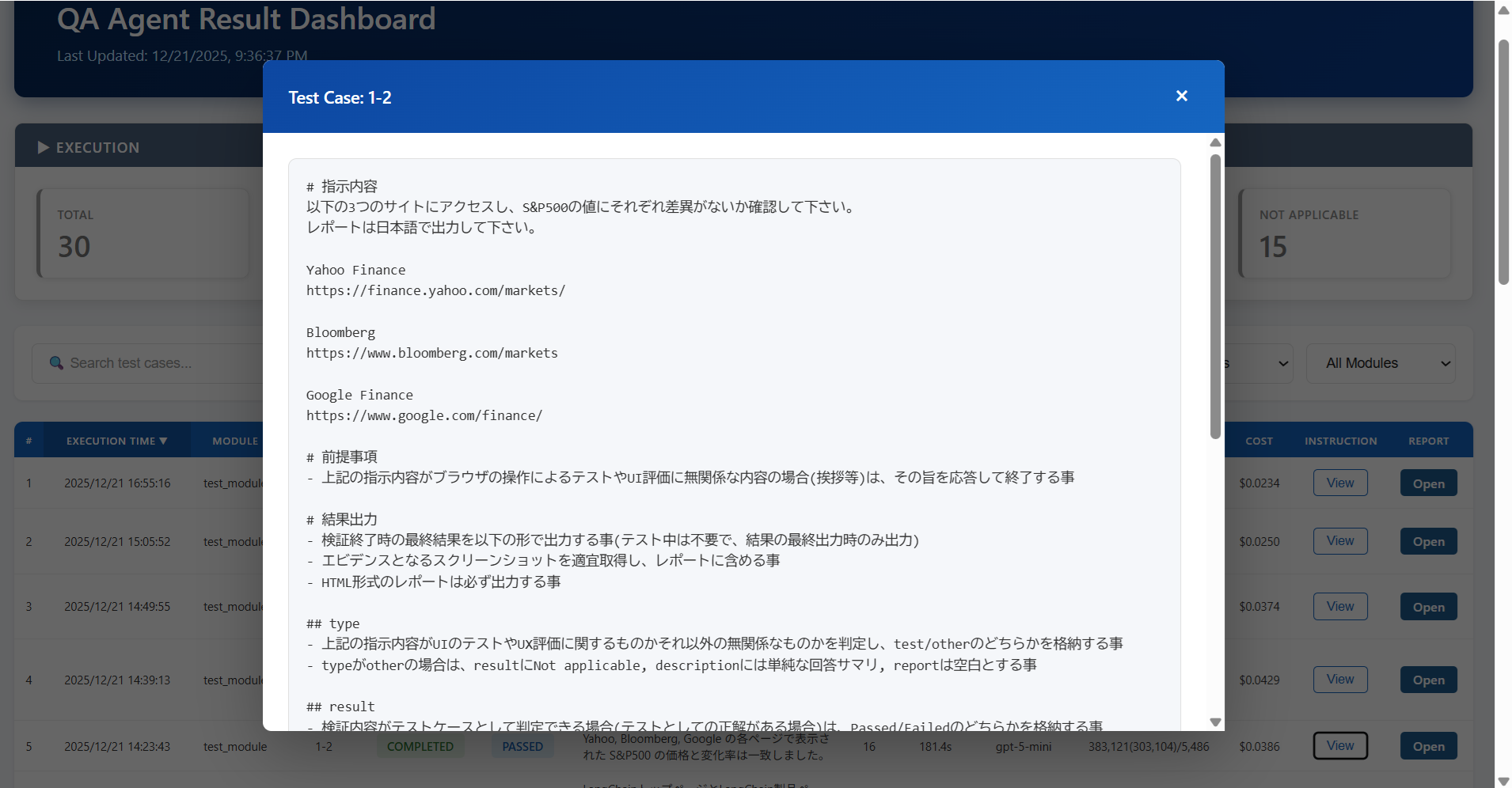
BIでも良いですが、数値確認というよりグラフィカルな要素も多いため、柔軟にビューを作成できるようにネイティブアプリとして組んでしまうのが良いかと思います。とりあえずAIエージェントに評価させてみるという所まではあまり難しくないものの、組織としてどう関係者を巻き込み、定着させていくかという事が重要になります。
組織共通のVMにAIエージェントを常時待機させておき、TeamsやSlackの指示で起動させ、結果のレスポンスもチャット上で返すという運用が楽かもしれません。AIからアクセスできれば何でも良いので、共通のWikiでテストケースを管理しておくという形でも良いでしょう。
なるべく多くのステークホルダーを上流から巻き込みつつ、システム・アプリケーション開発のフィードバックサイクルを速くできると、開発効率と品質の向上が期待できます。
検討事項
ここまでAIエージェントとブラウザ操作の自動化による様々な可能性を見てきました。
ただ実際のところ、人の介入をゼロにできるかと言えばNoになりますし、そこを目指すべきでもありません。AIはゼロイチの話ではなくあくまでグラデーションの話なので、そもそも的確な指示プロンプトを作る人も必要ですし、結果を正しく判断できる人も必要になります。
これは非常に優秀な部下にタスクを依頼するケースと同様で、部下への指示や最終チェック自体をスキップする事はできません。一方で、部下のレベルが非常に高く、今後更に基盤モデルのレベルも向上されていくため、最低限の指示と確認で済むようになるという世界感になっていくとは思います。
100かかっていた工数を1/10にするという目標をまずは掲げるべきで、完全自動化を目指すのはコンセプトとしてはかっこいいですが、それ自体を目標にするとプロジェクトがもったいない形で頓挫してしまう可能性があります。自動化率を高める試行錯誤は継続しつつも、より着実なアップデートを進めていくほうが良いでしょう。
もう1点重要になるのがコンテキストエンジニアリングです。
というのも、常にゼロベースでテストさせるのも無駄なケースが多く、特定のページだけを評価させたいのであれば、対象のURLをピンポイントで指定するべきですし、システム・アプリケーションの操作手順が複雑な場合は、最低限の手順などもサポートとして指示に含めたほうが良いでしょう。
不定期に出るポップアップなども「〇〇〇の内容のポップアップがでたらOKを押して」などの指示も含めておけばAIエージェントの動作もよりスムーズになります。
対象のユースケースと目的を見極めながら、必要なコンテキストをAIエージェントに渡す事で無駄なトークン消費を避け、テスト時間も短縮できるため、新人が失敗している状況を見ながら助言をしていくように、AIエージェントに渡すコンテキストを育てていく事も重要になります。
今回は簡単なユースケースでしたが、操作手順が多くなるとコンテキストウィンドウが逼迫する上に、ノイズとなる情報も多くなりLLMの精度も下がるため、コンテキスト圧縮も検討したほうが良いでしょう。
また、LLMが出力したレポートへのスクリーンショットの埋め込み等の整形過程などは、安定性を考慮しAIエージェントから分離しています。安定性と信頼性向上のために、LLMにしか出来ない箇所とLLMをむしろ使うべきではない箇所の見極めと設計が重要になります。
検証から実運用のレベルまで乗せるのは簡単ではないものの、正しく設計すれば、組織横断での利用が見込める、非常に汎用性と拡張性の高いユースケースになるでしょう。
まとめ
いかがだったでしょうか。
これまでは固定化されたスクリプトベース、静的なE2Eテストの範囲に留まっていましたが、AIエージェントによるブラウザ操作の自動化は、一時的な流行りではなく、システム・アプリケーション開発におけるメイントレンドの一つになっていくのではないかと思います。
かなりポイントを抜粋した内容ではありましたが、何か少しでも今後の取り組みのご参考になる点があれば幸いです。