ジョブを作成する
ETL jobs→Visual ETLボタンを押下する。
左上の鉛筆マークを押下してジョブ名を変更する
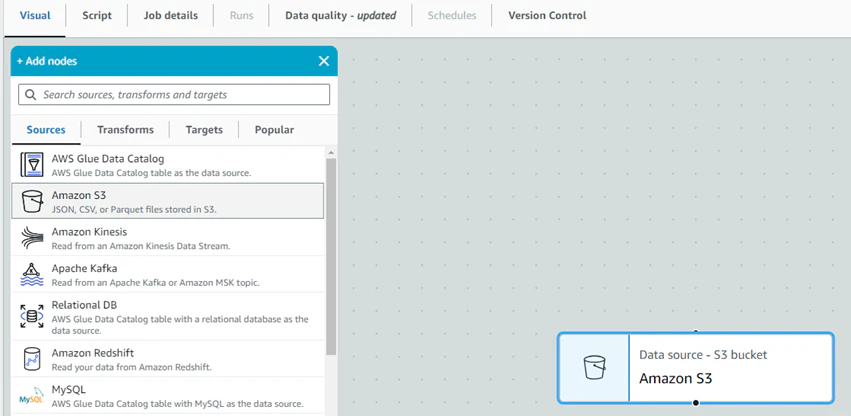
Sourcesを追加
Sourcesの中から「Amazon S3」を選択すると、画面にS3のノードが追加される。
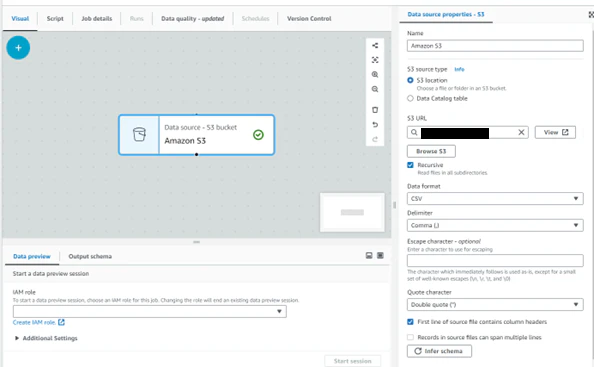
Name:任意の名前を入力
S3 URL:CSVデータの取得元になるS3を選択する。
バケットを指定する場合は、後ろに追記する。
Data format:CSVを選択
IAM role:Glue用に作ったものを選択する
他の設定は通常のCSVであればデフォルトでOK。
Transformsを追加
S3のノードを選択(クリック)した状態で、Change Schemaを選択する。
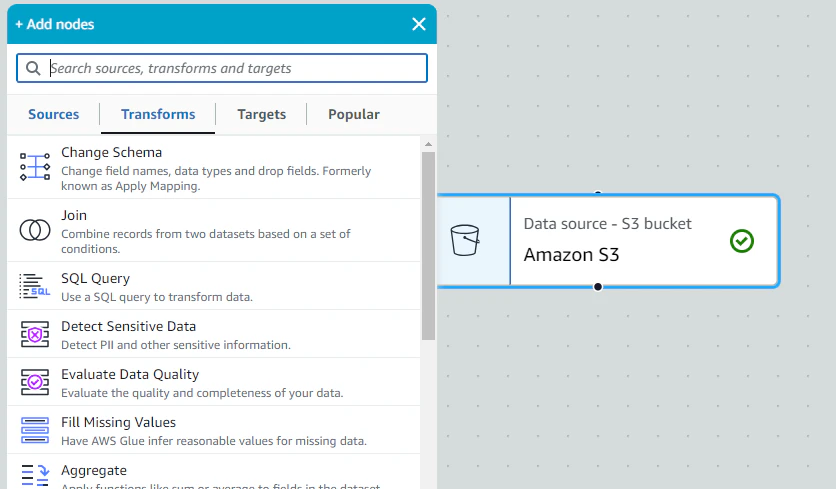
すると、S3の下にChange Schemaのノードが追加される。
Name:ご自由に
Change Shema(Apply mapping)にCSVの項目が表示されるので、Target keyに格納したいRDSのカラム名を記入する。
Data typeで型を選択できる。
取込不要な項目はDropのチェックボックスをOnにする。
他は特にそのままで良いが、CSVの行数が多いと左下のプレビューが重くて余計な時間がかかる。
ジョブ作成時、S3には1行程度のCSVを置いておく方が良い。
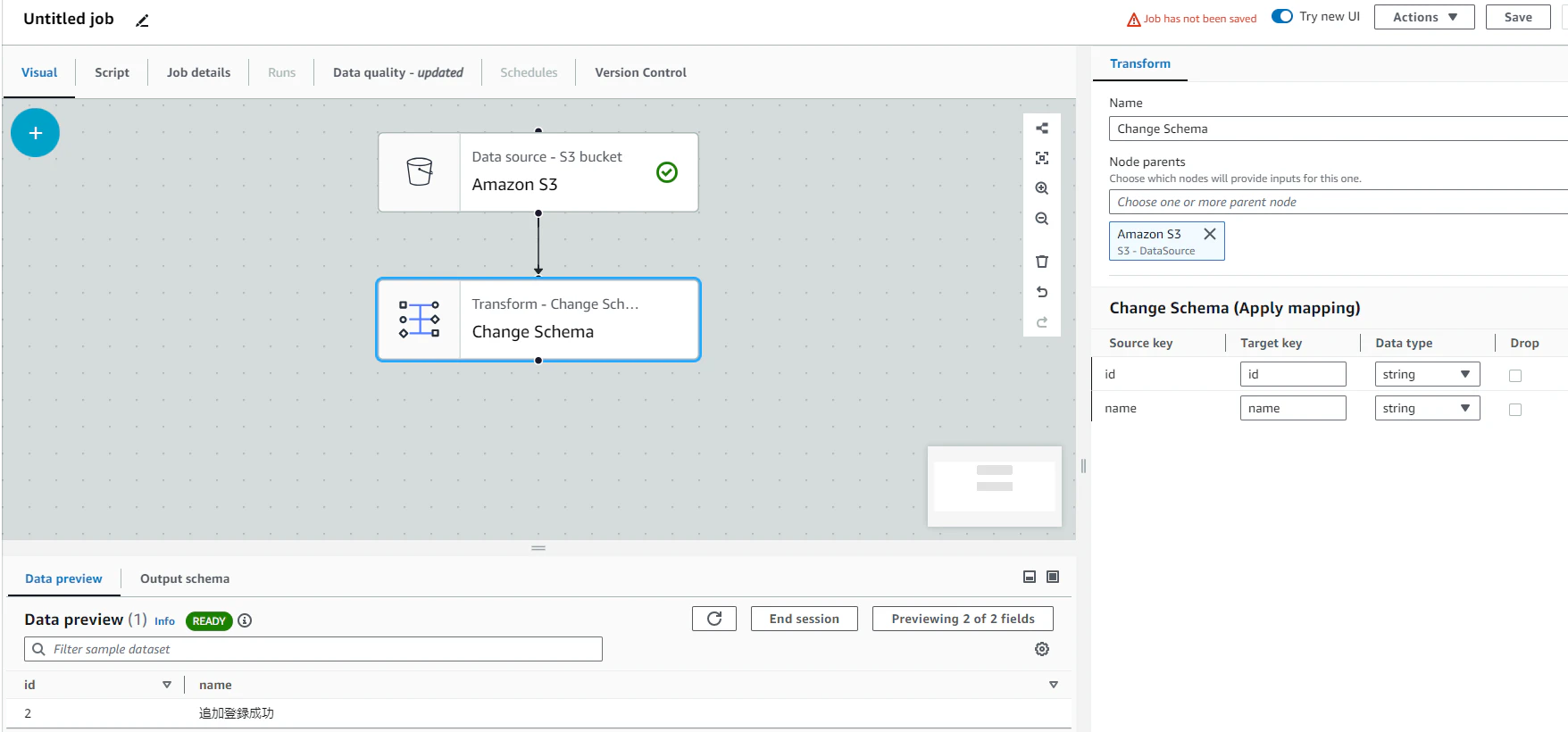
Targetsを追加
Change Schemaのノードを選択した状態で、MySQLを選択する。
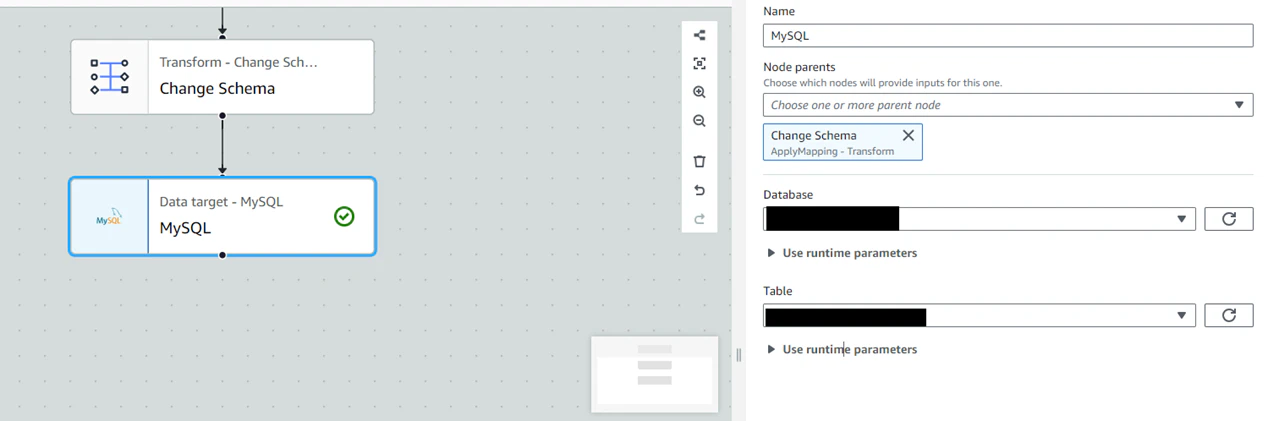
MySQLノードが追加されるので設定する。
Name:ご自由に
Database:データ格納対象のデータベースを選択する
Table:データ格納対象のテーブルを選択する
ジョブの実行
設定が完了したら右上の「Run」ボタンを押下する。
ここまでConnectionとクローラーが問題なく設定できていれば、そうそう難しい問題は起きない。
カラム名が無いとかデータ型が合わないといった内容なので一つずつ潰していこう。
これでS3のCSVをRDSのMySQLインスタンスへ取り込むことができた。
難しいことをしようとすればもっと複雑な作業が必要になるだろうが、単純に取り込むだけであればノーコードで結構簡単にできた。
Connectionで発生するよくわからないエラーだけは勘弁して欲しいが、もう少し深堀して有効活用したいと思う。