本記事はQmonus Value Streamの投稿キャンペーン記事です。
はじめに
本記事では、PostGraphileを使用して、簡単にGraphQL APIを作成する方法をご紹介します。
素早いAPI試作が求められるPoCや先行開発フェーズにおいては、慣れないGraphQLのスキーマとリゾルバを定義してAPI開発している時間がもったいないですよね。
そんなときは、PostgreSQLテーブル定義して、PostGraphileでAPI変換した方が何倍も早くAPI開発ができます。
本記事は、「GraphQL APIって何?」という方も読んで頂けるようにGraphQLの説明から書いています。
そのため、本題のみご興味持っていただいた方は、PostGraphileとはからお読み頂けますと幸いです。
GraphQL
GraphQLの説明と特徴は下記になります。
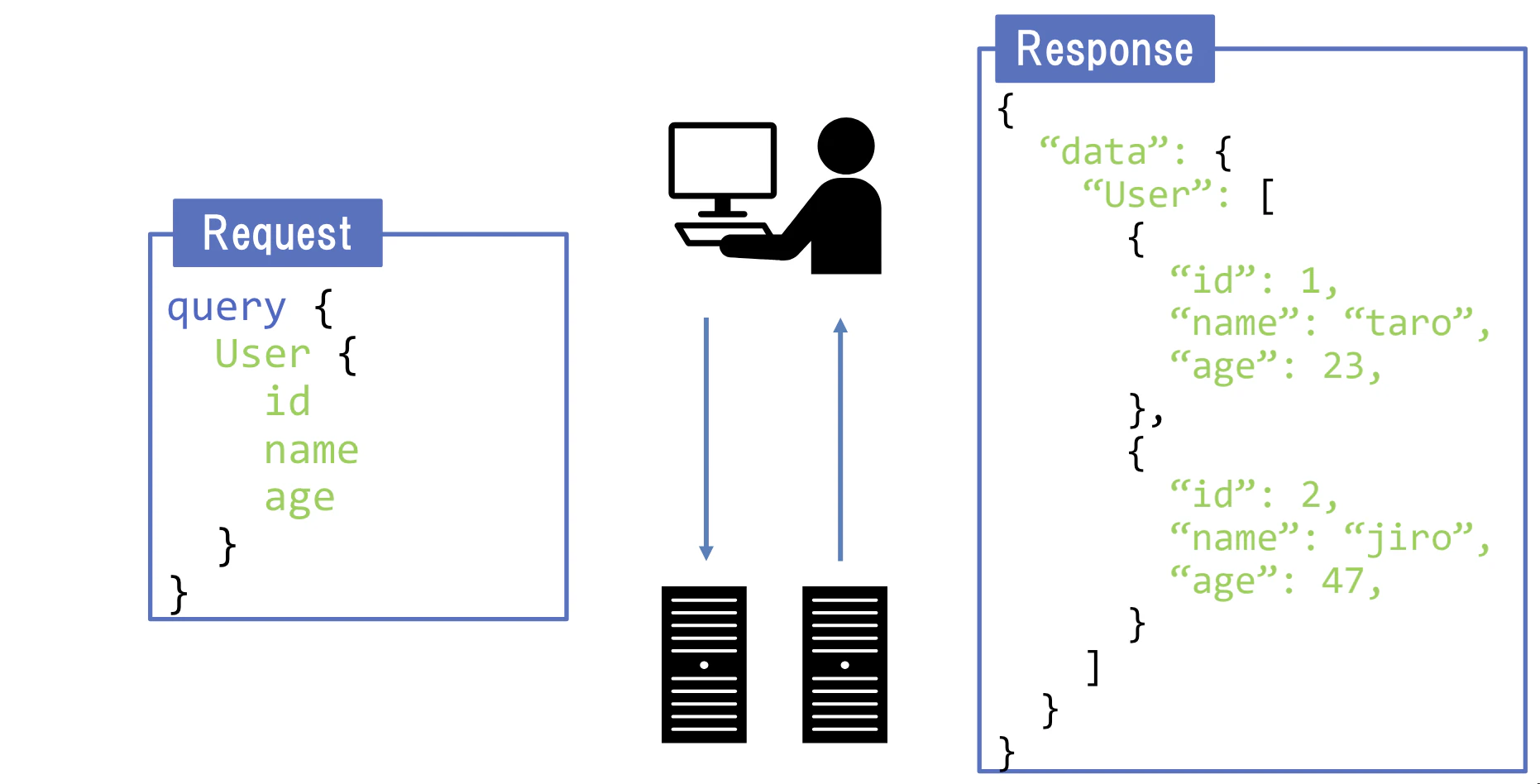
- GraphQLはMeta (Facebook)によって2012年に開発され、2015年に公開されたAPI用のクエリ言語及びサーバーランタイム
- 基本単位はクエリ
- RESTと比較すると、GraphQLはクライアント主導のアプローチであり、必要なデータやデータの取得方法、及び形式をクライアントが決定可能
- クライアントが必要なデータを特定・指定できるため、RESTのデメリットであるオーバーフェッチとアンダーフェッチの問題も解決可能
Pros & Cons
GraphQLのメリデメは下記になります。
Pros
- 無駄なデータ取得が生じない
- 必要なフィールドを正確に指定できるため、オーバーフェッチやアンダーフェッチが発生しない
- API呼び出し回数の抑制
- エンドポイント数が減るため、APIの構成が単純化される
Cons
- 標準キャッシュのサポートがされていない
- RESTに比べて複雑化してしまうケースがある
- RESTやgRPCと比較して、学習コストが高いため慣れが必要 - バックエンド開発の負担増
- クライアント側の柔軟なデータ取得を実現するためにサーバー側の処理が増え、パフォーマンスが下がってしまうケースがある
他のWeb APIとの比較
REST
- 最もよく使われていて一般的なAPI設計スタイル
- 基本単位はリソース
- URLを使用してリソースを指定して、HTTPメソッドを使用して実行するアクションを決定

HTTPメソッドには以下のような種類があります。
| メソッド | 説明 |
|---|---|
| GET | 既存リソースの取得 |
| POST | 新規リソースの作成 |
| DELETE | リソースの削除 |
| PUT | リソース全体の更新及び作成 |
- シンプルに使えて、どのようなプロダクトにおいても大体使うことが可能
- オーバーフェッチやアンダーフェッチなどで必要のないリソースを取得可能性有り
- ODdataを使ってエンティティの一部取得をすることは可能(私自身、周りで使っているところをあまり見たことないですが…)
- ODataに関しては下記記事にまとめてくださっています
gRPC
- gRPCはGoogleが開発した高性能RPCフレームワーク
- Protocol Bufferを使用して、サービスインターフェースとペイロードメッセージの構造を定義します
- 軽量で高速なため高性能であるため、クライアントのリソース不足の場合に適しています
- 異なる言語を用いてサービス通信ができるため、マイクロサービス間通信でも使用されます
比較表
下記観点で、GraphQL、REST、gRPCを比較してみた結果を下表に示します。
- 結合度
- APIの呼び出し回数
- パフォーマンス
- 実装の複雑さ
- キャッシング
- コード生成
- API探索性
- バージョニングの容易さ
| GraphQL | REST | gRPC | |
|---|---|---|---|
| 結合度 | 中 | 低 | 高 |
| APIの呼び出し回数 | 少ない | 多い | 中程度 |
| パフォーマンス | 良好 | 良好 | 非常に高い |
| 実装の複雑さ | 高い | 中程度 | 低い |
| キャッシング | 設計必要 | 良好 | 設計必要 |
| コード生成 | 良好 | 乏しい | 非常に良好 |
| API探索性 | 良好 | 良好 | 乏しい |
| バージョニングの容易さ | 設計必要 | 容易 | 困難 |
GraphQLの仕様
実際にGraphQLの仕様について確認します。
基本的に公式ページに記載されていますので、併せてご確認ください。
スキーマ言語
GraphQLには型があります。この型定義ができるのが、スキーマ言語です。
GraphQLを介した通信は、このスキーマ言語による型定義をベースとしています。
スカラー型
GraphQLにおいてデフォルトで定義されている型は下記。
Int: 符号付きの32bit整数
Float: 符号付きの倍精度浮動小数点数
String: UTF-8の文字列
Boolean: trueもしくはfalse
ID: 一意な識別子 (String型)
また、GraphQL ユーザー独自に型を定義することができます。
scalar Date
オブジェクトの型とフィールド
GraphQLの型定義は、型名とフィールドから成ります。
type Character {
name: String!
appearsIn: [Episode!]!
}
-
Characterというオブジェクトの型を定義している -
nameとappearsInの 2 つのフィールドを持つ -
Stringは文字列のスカラー型 -
String!と最後に!をつけることで、そのフィールドがnullにならないことを示す -
Episodeはユーザー定義の型 -
[Episode]と[]で囲むことにより、配列であることを示す - !がついているので、このフィールドはnullにならないことを示している
列挙型
Episode型として指定されたフィールドには、NEWHOPE、EMPIRE、JEDIのいずれかしか入らないことを示しています。
enum Episode {
NEWHOPE
EMPIRE
JEDI
}
引数を持つフィールド
フィールドには引数を定義することができます。
type Starship {
id: ID!
name: String!
length(unit: LengthUnit = METER): Float
}
引数は必須および任意で指定することが可能です。
必須としたい場合はnull不可を示す!を引数の型に付けます。任意とした場合、引数にデフォルト値を指定することも可能です。上記の例では、unitの引数が提供されない場合にはMETERが使用されます。
Query型と Mutation型
スキーマ定義において、Query型と Mutation型は特殊な意味を持ち、APIにおけるエンドポイントを示すことができます。
例えば、以下のようなクエリ文を GraphQL サーバーに送り、データが取得できたとします。
query {
hero {
name
}
droid(id: "2000") {
name
}
}
{
"data": {
"hero": {
"name": "R2-D2"
},
"droid": {
"name": "C-3PO"
}
}
}
リクエストしたクエリ文には、heroおよびdroidの2文が含まれており、結果も取得できています。
GraphQLのエンドポイントにheroおよびdroidが存在することを示しています。
GraphQLにおけるエンドポイントの定義は、冒頭でも触れたようにQuery型又は、Mutation型を利用します。例えば以下のような型定義が必要です。
type Query {
hero(episode: Episode): Character
droid(id: ID!): Droid
}
上記は、Query型にheroフィールドおよびdroidフィールドが定義されています。
Query型に登録されたフィールドがエンドポイントとして登録されますが、型定義そのものは通常のオブジェクトと変わりません。
Query型とMutation型の2つは実行できる処理が異なります。
GraphQLにおいて、Queryはデータの取得(GET)、Mutationはデータの変更(POST、PUT)を意味します。
インターフェース
interface Character {
id: ID!
name: String!
friends: [Character]
appearsIn: [Episode]!
}
上記Characterインターフェースを実装する型では、id、name、friends、appearsInの4フィールドを実装する必要があります。
例えば、下記はCharacterインターフェースを実装したHuman型とDroid型です。
type Human implements Character {
id: ID!
name: String!
friends: [Character]
appearsIn: [Episode]!
starships: [Starship]
totalCredits: Int
}
type Droid implements Character {
id: ID!
name: String!
friends: [Character]
appearsIn: [Episode]!
primaryFunction: String
}
Characterインターフェースで定義されていたフィールド以外については自由に実装することができます。Human型ではstarshipsとtotalCredits、Droid型ではprimaryFunctionが実装されています。
同じインターフェースを実装している場合においても、型名が異なれば別の型となります。
query HeroForEpisode($ep: Episode!) {
hero(episode: $ep) {
name
primaryFunction
}
}
{
"ep": "JEDI"
}
{
"errors": [
{
"message": "Cannot query field \"primaryFunction\" on type \"Character\". Did you mean to use an inline fragment on \"Droid\"?",
"locations": [
{
"line": 4,
"column": 5
}
]
}
]
}
heroはCharacter型の値を取得するクエリです。
このクエリ文では"ep": "JEDI"に該当する値をもつCharacterを取得しています。
他方で、primaryFunctionはDroid型にのみ実装されたフィールドであり、Character型のすべてに含まれているとは限りません。
そのため、エラーが発生しています。
取得したデータがDroid型の場合だった場合、同時にprimaryFunctionの値を取得したい場合は、インラインフラグメントを使えば上手く取得することができます。
query HeroForEpisode($ep: Episode!) {
hero(episode: $ep) {
name
... on Droid {
primaryFunction
}
}
}
{
"ep": "JEDI"
}
{
"data": {
"hero": {
"name": "R2-D2",
"primaryFunction": "Astromech"
}
}
}
ユニオン型
union SearchResult = Human | Droid | Starship
上記の場合、SearchResultとしてHuman、Droid、Starshipの3つを指定しています。
これは、SearchResult型を指定したフィールド等では、その実装としてHuman、Droid、Starshipのどれかを入れることが可能であることを示します。
例えば、SearchResult 型の結果を返すsearchクエリが存在する場合に、以下のような処理が行えます。
{
search(text: "an") {
__typename
... on Human {
name
height
}
... on Droid {
name
primaryFunction
}
... on Starship {
name
length
}
}
}
{
"data": {
"search": [
{
"__typename": "Human",
"name": "Han Solo",
"height": 1.8
},
{
"__typename": "Human",
"name": "Leia Organa",
"height": 1.5
},
{
"__typename": "Starship",
"name": "TIE Advanced x1",
"length": 9.2
}
]
}
}
クライアントは型名を表す文字列__typenameを元に、取得できたデータの型を判断できます。
...on XXXは、インラインフラグメントです。型に応じて取得するフィールドを選択しています。
Human型とDroid型はどちらもCharacter型を実装しているため、下記のように書くことも可能です。
{
search(text: "an") {
__typename
... on Character {
name
}
... on Human {
height
}
... on Droid {
primaryFunction
}
... on Starship {
name
length
}
}
}
入力型
入力型は、クエリの引数として用いられるフィールドの組み合わせを定義できます。
例えば、ReviewInput型を書きのように定義します。
input ReviewInput {
stars: Int!
commentary: String
}
ReviewInput型を用いるCreateReviewForEpisodeクエリが存在する場合、以下のような処理が行えます。
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}
{
"ep": "JEDI",
"review": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
{
"data": {
"createReview": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
}
ReviewInput型は感想を登録するために必要な情報を示していると考えられます。
このように、「ある操作を行うために必要な情報」について、入力型という形式で表現することができます。
ただし、入力型は通常の型と違い、フィールドに引数を設定することはできないので注意してください。
クエリ言語
ここからはクエリ言語についてです。
クエリ言語を用いることにより、データの問い合わせやデータ変更依頼を行うことができます。
フィールド
{
hero {
name
}
}
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
heroはスキーマ言語の項目で見たように、Query型に登録されたフィールドを呼び出しています。
(nameは上記heroの持つフィールドのうち、取得したいフィールドを指定してます)。結果として、"name": "R2-D2"が取得できています。
例えば Character型のフィールドとしてfriendsを持ち、かつfriendsはオブジェクトの配列だったとします。
その場合、以下のような処理を行うこともできます。
{
hero {
name
# Queries can have comments!
friends {
name
}
}
}
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
フィールドがオブジェクトであれば、上記のように取得するフィールドを指定することができます。
Query型もオブジェクトであると考えれば、どんなクエリ文も取得するフィールドを指定しているだけと考えられます。
引数
クエリ文には引数を渡すことができます。例えば、ID が 1000 である人間を取得するクエリは以下の通りです。
{
human(id: "1000") {
name
height
}
}
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 1.72
}
}
}
RESTでデータを取得する場合、値をリクエストに含めたいときは URLまたは、クエリパラメータに入れます。
一方で GraphQL の場合、ネストしたオブジェクトのフィールドそれぞれに引数を指定することができます。
上記の例を参考に、身長をメートル表記からフィート表記に変えたい場合は下記になります。
{
human(id: "1000") {
name
height(unit: FOOT)
}
}
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 5.6430448
}
}
}
エイリアス
フィールドにはエイリアスをつけることができます。
例えば、heroクエリを2つまとめて発行したい場合、そのままでは同じheroなので両者の区別がつきません。
そこで、エイリアスをつけることで区別できるようになります。
{
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}
{
"data": {
"empireHero": {
"name": "Luke Skywalker"
},
"jediHero": {
"name": "R2-D2"
}
}
}
フラグメント
フラグメントは、フィールド取得構成を使いまわすことのできる機能です。
{
leftComparison: hero(episode: EMPIRE) {
...comparisonFields
}
rightComparison: hero(episode: JEDI) {
...comparisonFields
}
}
fragment comparisonFields on Character {
name
appearsIn
friends {
name
}
}
{
"data": {
"leftComparison": {
"name": "Luke Skywalker",
"appearsIn": ["NEWHOPE", "EMPIRE", "JEDI"],
"friends": [
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
},
{
"name": "C-3PO"
},
{
"name": "R2-D2"
}
]
},
"rightComparison": {
"name": "R2-D2",
"appearsIn": ["NEWHOPE", "EMPIRE", "JEDI"],
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
それぞれのフィールドとして..comparisonFieldsを指定しています。
これは、取得するフィールドの指定をcomparisonFieldsフラグメントに委譲しています。
また、fragment comparisonFields on Characterは、取得できたデータ型がCharacter型だった場合に取得するフィールドの指定を行っています。
heroではCharacter型が取得できるので、どちらもデータを取得できてます。
なお、フラグメントには引数が利用できます。
query HeroComparison($first: Int = 3) {
leftComparison: hero(episode: EMPIRE) {
...comparisonFields
}
rightComparison: hero(episode: JEDI) {
...comparisonFields
}
}
fragment comparisonFields on Character {
name
friendsConnection(first: $first) {
totalCount
edges {
node {
name
}
}
}
}
{
"data": {
"leftComparison": {
"name": "Luke Skywalker",
"friendsConnection": {
"totalCount": 4,
"edges": [
{
"node": {
"name": "Han Solo"
}
},
{
"node": {
"name": "Leia Organa"
}
},
{
"node": {
"name": "C-3PO"
}
}
]
}
},
"rightComparison": {
"name": "R2-D2",
"friendsConnection": {
"totalCount": 3,
"edges": [
{
"node": {
"name": "Luke Skywalker"
}
},
{
"node": {
"name": "Han Solo"
}
},
{
"node": {
"name": "Leia Organa"
}
}
]
}
}
}
}
操作名
操作名は、発行するクエリに任意指定することができる名称です。クエリ発行ごとに毎回指定可能です。
これまでに例として記述されたクエリ文は、クエリ操作(query、mutationなど)と操作名の指定を省略した記法になります。操作名を指定する場合、クエリ操作についても明記が必要です。
以下に例を示します。
query HeroNameAndFriends {
hero {
name
friends {
name
}
}
}
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
省略記法を用いる場合、操作名は不要です。不要な操作名をあえて明記する理由は、サーバーのログ記録です。
クエリを発行する際に操作名を記述し、GraphQLサーバーで記録することにより、不具合や問い合わせなどの際にログを追いかけることを容易にします。
変数
GraphQL では、クエリ文と同時に変数の指定も送信することができます。
query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}
{
"episode": "JEDI"
}
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
クエリ文には、Episode型を指定できる$episode変数が引数として存在します。変数定義では、この episodeにJEDIを代入しています。
ディレクティブ
ディレクティブは、変数を与えることで取得するデータの構造を動的に変化させることができます。
query Hero($episode: Episode, $withFriends: Boolean!) {
hero(episode: $episode) {
name
friends @include(if: $withFriends) {
name
}
}
}
{
"episode": "JEDI",
"withFriends": false
}
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
@includeディレクティブにより、friendsフィールドを含むかどうか選択しています。今回は false を引数に与えたため、friends`フィールドを除く結果となりました。
GraphQL には、上記の@include、および逆の操作を行える@skipの2種類が定義されています。
ライブラリやユーザーで独自に追加定義が可能で、Apollo Serverでは@keyや@provides等のディレクティブが定義されています。
Mutations
RESTでは、GET リクエストではデータの取得のみを行います。データの変更を行うにはPOSTやPUTなどのリクエストメソッド使います。
QraphQL でもデータの変更を伴わない操作にはQueryを、データの変更を伴う操作にはMutationを利用すると使い分けされています。
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}
{
"ep": "JEDI",
"review": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
{
"data": {
"createReview": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
}
レビューを新規作成するクエリ文です。mutation CreateReviewForEpisodeと示されています。
PostGraphileとは
PostGraphileは、PostgreSQLのスキーマからGraphQL APIを構築するミドルウェアです。PostGraphileはサーバーのセットアップやGraphQLスキーマの手動生成を省略して、GraphQL APIを生成してAPIの開発スピードをアップさせることができます(すぐに使って試したいPoCに最適)。
下記、PostGraphileの特徴です。
- データベースのスキーマを基にして、自動的にGraphQLスキーマとリゾルバーを生成します
- データベースに対してGraphQLクエリを直接発行することができます
- PostGraphileはセキュリティに重点を置いており、権限設定をサポートしています
- データベースのテーブルとカラムごとにアクセス権限を制御することができます
- GraphQLのクエリを簡単にテストするためのグラフィQLインターフェースを提供してます
- データベースのスキーマが変更された場合、自動的にGraphQLスキーマを更新し、変更内容を反映します
- 必要に応じてPostGraphileの動作をカスタマイズできます
- プラグインや設定オプションを活用して、カスタムリゾルバーやGraphQLの拡張機能を追加するなど、APIの振る舞いを調整することができます
Hasuraとの違い
- PostGraphileには、Hasuraよりもカスタマイズを行うための設定オプションが多くあります
- また、上記の通りプラグインや設定オプションなどでAPIの振る舞いを調整できます
- Hasuraの方が認証やアクセス制御を簡単に設定できます
- PostGraphileでは時間はかかりますが、Hasuraよりも自由度の高い認証やアクセス制御が可能です
→ 簡単に早く作る必要があるのであれば、Hasura
→ 高度なカスタマイズが必要なのであれば、PostGraphile
実際に使ってみる
PostGraphileを使用する場合
# データベースへの接続
$ psql -U username -d database_name
# データベースの作成
$ createdb my_database
- 下記でテーブルを作成します
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
body TEXT,
author_id INTEGER REFERENCES users(id)
);
- 次にテーブルにデータを登録します
-- ユーザーの挿入
INSERT INTO users (name, email) VALUES
('John Doe', 'john@example.com'),
('Jane Smith', 'jane@example.com');
-- 投稿の挿入
INSERT INTO posts (title, body, author_id) VALUES
('First Post', 'This is John''s first post', 1),
('Hello World', 'Jane''s greeting to the world', 2),
('Another Post', 'John''s second post', 1);
- 下記でテーブルの確認できます
my_database=# \dt
List of relations
Schema | Name | Type | Owner
--------+-------+-------+--------
public | posts | table | junffy
public | users | table | junffy
(2 rows)
- 下記で
server.jsを作成して、nodeサーバー立ち上げ- PostGraphileが起動して、GraphiQLがlocalhostで閲覧できます。
const express = require("express");
const { postgraphile } = require("postgraphile");
const app = express();
app.use(
postgraphile(
process.env.DATABASE_URL || "postgres:///my_database",
"public",
{
watchPg: true,
graphiql: true,
enhanceGraphiql: true,
}
)
);
app.listen(5000, () => {
console.log("PostGraphile server is running on http://localhost:5000/graphql");
});
- GraphiQL画面
query {
allPosts {
nodes {
id
title
body
userByAuthorId {
id
name
email
}
}
}
}
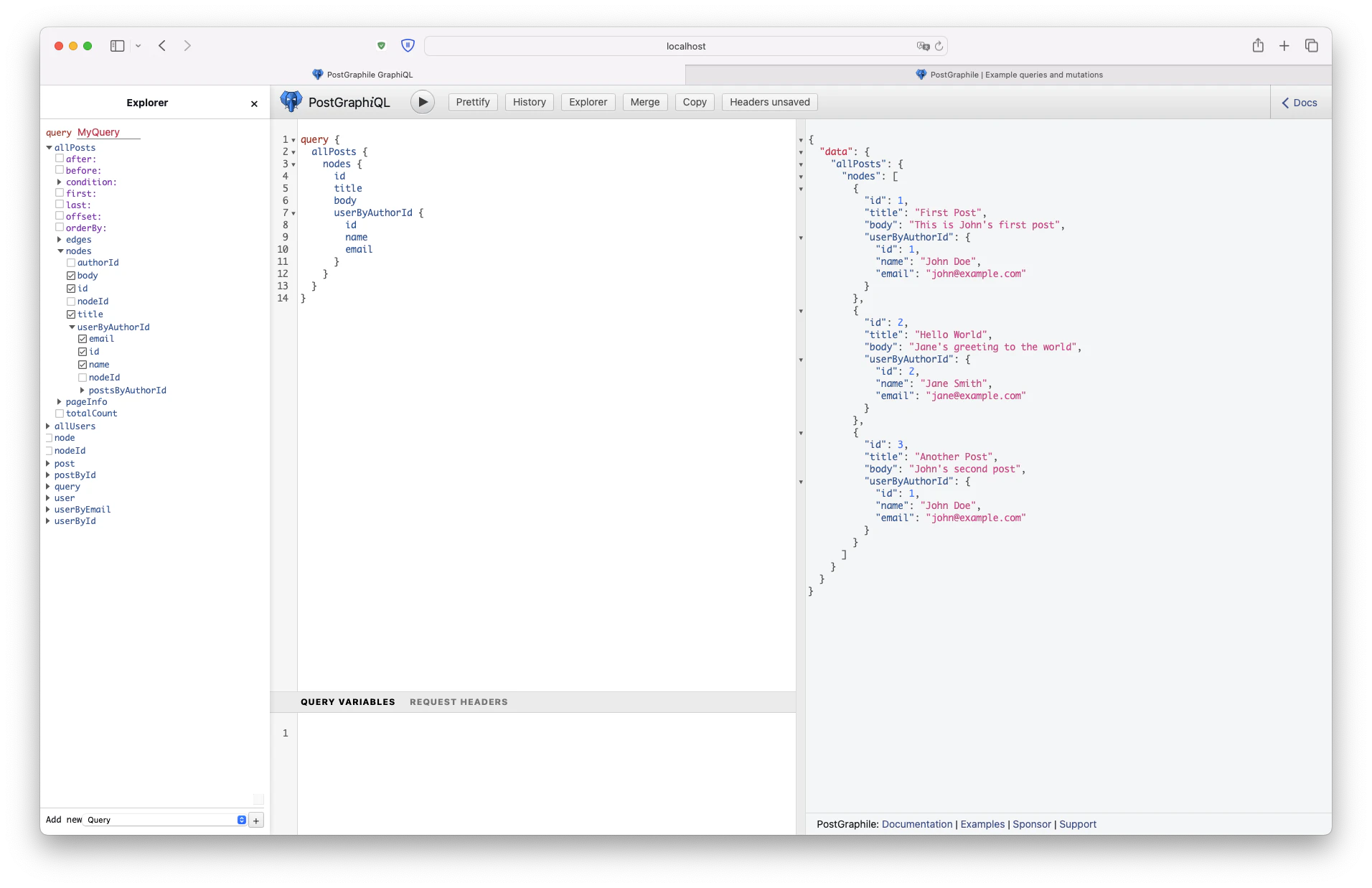
PostgreSQLテーブルに追加したデータをクエリで呼び出すことができました。
テーブルにデータを追加して、PostGraphileサーバーを立ち上げれば、すぐにGraphQL API化できて呼び出せるので便利ですね。爆速でAPI開発できそうです。
PostGrahile有り無し比較
使う場合
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
body TEXT,
author_id INTEGER REFERENCES users(id)
);
const express = require("express");
const { postgraphile } = require("postgraphile");
const app = express();
app.use(
postgraphile(
process.env.DATABASE_URL || "postgres:///my_database",
"public",
{
watchPg: true,
graphiql: true,
enhanceGraphiql: true,
}
)
);
app.listen(5000, () => {
console.log("PostGraphile server is running on http://localhost:5000/graphql");
});
使わない場合
const { gql } = require('apollo-server-express');
const typeDefs = gql`
type User {
id: ID!
name: String!
email: String!
posts: [Post!]
}
type Post {
id: ID!
title: String!
body: String
author: User!
}
type Query {
user(id: ID!): User
users: [User!]!
post(id: ID!): Post
posts: [Post!]!
}
type Mutation {
createUser(name: String!, email: String!): User!
updateUser(id: ID!, name: String, email: String): User!
deleteUser(id: ID!): Boolean!
createPost(title: String!, body: String, authorId: ID!): Post!
updatePost(id: ID!, title: String, body: String): Post!
deletePost(id: ID!): Boolean!
}
`;
const resolvers = {
Query: {
user: async (_, { id }, { pgClient }) => {
const result = await pgClient.query('SELECT * FROM users WHERE id = $1', [id]);
return result.rows[0];
},
users: async (_, __, { pgClient }) => {
const result = await pgClient.query('SELECT * FROM users');
return result.rows;
},
post: async (_, { id }, { pgClient }) => {
const result = await pgClient.query('SELECT * FROM posts WHERE id = $1', [id]);
return result.rows[0];
},
posts: async (_, __, { pgClient }) => {
const result = await pgClient.query('SELECT * FROM posts');
return result.rows;
},
},
Mutation: {
createUser: async (_, { name, email }, { pgClient }) => {
const result = await pgClient.query(
'INSERT INTO users(name, email) VALUES($1, $2) RETURNING *',
[name, email]
);
return result.rows[0];
},
updateUser: async (_, { id, name, email }, { pgClient }) => {
const result = await pgClient.query(
'UPDATE users SET name = COALESCE($2, name), email = COALESCE($3, email) WHERE id = $1 RETURNING *',
[id, name, email]
);
return result.rows[0];
},
deleteUser: async (_, { id }, { pgClient }) => {
const result = await pgClient.query('DELETE FROM users WHERE id = $1', [id]);
return result.rowCount > 0;
},
createPost: async (_, { title, body, authorId }, { pgClient }) => {
const result = await pgClient.query(
'INSERT INTO posts(title, body, author_id) VALUES($1, $2, $3) RETURNING *',
[title, body, authorId]
);
return result.rows[0];
},
updatePost: async (_, { id, title, body }, { pgClient }) => {
const result = await pgClient.query(
'UPDATE posts SET title = COALESCE($2, title), body = COALESCE($3, body) WHERE id = $1 RETURNING *',
[id, title, body]
);
return result.rows[0];
},
deletePost: async (_, { id }, { pgClient }) => {
const result = await pgClient.query('DELETE FROM posts WHERE id = $1', [id]);
return result.rowCount > 0;
},
},
User: {
posts: async (user, _, { pgClient }) => {
const result = await pgClient.query('SELECT * FROM posts WHERE author_id = $1', [user.id]);
return result.rows;
},
},
Post: {
author: async (post, _, { pgClient }) => {
const result = await pgClient.query('SELECT * FROM users WHERE id = $1', [post.author_id]);
return result.rows[0];
},
},
};
const express = require('express');
const { ApolloServer } = require('apollo-server-express');
const { Pool } = require('pg');
const pgClient = new Pool({
connectionString: process.env.DATABASE_URL || "postgres:///my_database",
});
const server = new ApolloServer({
typeDefs,
resolvers,
context: { pgClient },
});
const app = express();
server.applyMiddleware({ app });
app.listen({ port: 5000 }, () =>
console.log(`Server ready at http://localhost:5000${server.graphqlPath}`)
);
感想
いかがでしたでしょうか?
すぐにAPIを試作しないといけないPoCや先行開発フェーズにおいては、慣れないGraphQLのスキーマとリゾルバを定義している時間がもったいないですよね。
そんなときは、PostGraphileでPostgreSQLテーブル定義して、作った方が何倍も効率的にAPI試作ができそうです。
みなさんもぜひ使ってみてください!読んでいただきありがとうございました。