2025/11/18 追記
システム全体を LlamaIndex で再構築しました。
今度は raggify という PyPI ライブラリとしても公開してみました...!
今回新たに音声、動画モダリティと、テキストは BM25/Vector のハイブリッド検索もサポートしています。ぜひ見ていってやって下さい。
はじめに
近年の AI 関連技術の進歩と新ツール・新機能の登場ペースは目まぐるしいものがありますね。SNS のタイムラインを追っているだけでも次々に新情報が入ってくるので、何かに興味を持っても手を動かす前に目移りしてしまいそうになります。嬉しい悩みです。
そんな中、特に「社内 RAG システムの構築」に興味を持ち、
- マルチモーダルで
- ローカルモデルベースな
- RAG システムを構築するための REST API サーバ
のようなものは無いかと探してみたところ、意外と全部揃ったツールが見つからなかった(多分探し方が悪いだけ)ので、よっしゃ勉強がてら作ってみるか、と思い立って作り始めたのでした。
前置きが長くなりました。この記事は、上記実装が一段落したので、誰かの参考になればと思い、実装過程を振り返りつつまとめたものです。
Git リポジトリ
成果物はこちら↓
結局何が作りたかったか
ragserver 実装中に気付いたのですが、LlamaIndex がイメージに近そうです。
要は、
- Embedding モデル
- 差し替え可能
- マルチモーダル対応
- ローカルモデル対応
- Rerank モデル
- 同上
- ベクトル DB
- 差し替え可能
という特徴を備えた、Ingestion → Embeddings → Retriever → Reranker (→ LLM) というパイプライン構築のための、自分だけのオーケストレーションフレームワークっぽいものを作りたかった。RAG システムそのものではなく。色々な埋め込みモデル、リランカ、ベクトル DB を試しつつ、用途に合った RAG システムを作れるような基盤を。
認識がずれていたからなかなか探せなかったのかもしれません。独自の RAG システムを構築する向きで調べるとLangChain で実装するか Dify 使うかの二強(※個人の感想です)みたいな感じで記事がわんさか出てきますが、2025 年 9 月現在はテキストデータのみを扱う RAG システムが主流で、画像、音声、動画等のマルチモーダルなデータをネイティブに扱えるフレームワークは意外と未だ多くないのですね。LangChain や Dify でさえ、埋め込みはテキストが前提というのは、調べてみるまで知りませんでした。
RAG Server システム構成
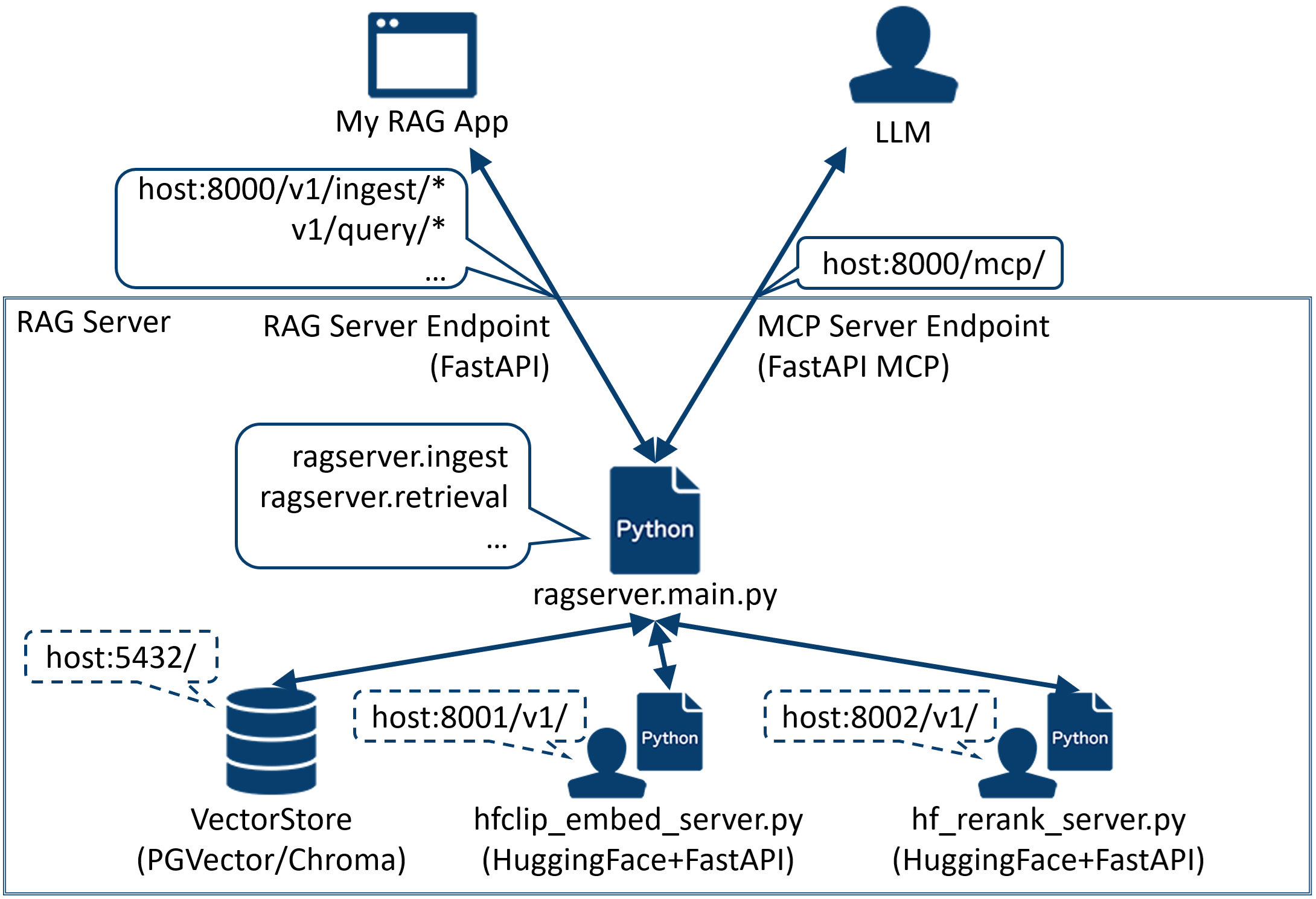
成果物のシステム構成は図の通りです。図下半分の青枠内が RAG Server 関連モジュール全体を示しており、主に以下の4つのコンポーネントからなります。
-
RAG Server 本体(ragserver.main)
- LangChain の Document クラス単位でナレッジデータを扱う。ただし本家のツールチェーンは基本的にテキストデータを扱う前提の作りになっているため、画像を扱う処理周りは独自にクラスを定義したり、変則的な使い方(doc.page_content に画像の URL を入れる運用とする等)をしたりしている。
- ragserver は以下の3つのレベルで API を公開している。
- ライブラリ:ragserver.ingest, ragserver.retrieval の各モジュール内に定義の関数は、ライブラリレベルの API として利用可能。
- REST API サーバ:ragserver.main モジュールは、そのまま FastAPI サーバとして上記ライブラリ API を REST API として公開している。
- MCP サーバ:上記 REST API は、/mcp に FastAPI-MCP サーバとしても公開している。
-
Vector Store
- デフォルトで Chroma の PersistDirectory モードで起動。
- PG Vector も選択可能。
- Chroma, PG Vector それぞれホストはローカル、リモート(Chroma はクラウドも)で起動可能。
-
HuggingFace CLIP Embed Server
- デフォルトで HuggingFace の CLIP モデル(openai/clip-vit-base-patch32)+FastAPI の埋め込みサーバが起動。
- 外部の埋め込みモデル(openai, cohere)も選択可能。
-
HuggingFace Rerank Server
- デフォルトで HuggingFace のリランクモデル(BAAI/bge-reranker-v2-m3)+FastAPI のリランクサーバが起動。
- 外部のリランクモデル(cohere)も選択可能。
その他に、図中で「My RAG App」として例示している部分について、Git リポジトリ内には実装例として ragclient モジュールを含めています。後ほど紹介します。
ディレクトリツリー
トップレベル
Git リポジトリに公開しているディレクトリのツリーです。
.
├── examples/.devcontainer/
│ ├── Dockerfile
│ ├── devcontainer.json
│ ├── postCreateCommand.sh
│ └── requirements.txt
├── chroma_server/
│ └── run.sh # Chroma をローカルサーバモードで起動する場合の起動スクリプト
├── embed_server/
│ ├── hfclip_embed_server.py # HuggingFace CLIP 埋め込みサーバ。受信文字列先頭が "data:image" かどうかで text/image を判断
│ └── run.sh
├── pgvector_server/
│ └── init_pgdb.sh # ragserver 用にローカルの postgres を初期化。DB を空にするので注意!
├── ragclient
├── ragserver
├── rerank_server/
│ ├── hf_rerank_server.py # HuggingFace リランクサーバ
│ └── run.sh
├── .env_sample # .env としてコピーして使用
├── run_all.sh # ragserver 関連サーバ群を起動
└── stop_all.sh # 停止
ragserver モジュール
全体像
ragserver モジュール本体のディレクトリツリーは以下の通りです。
.
└── ragserver/
├── core/
│ ├── metadata.py # Document クラスに持たせるメタデータの構造定義等
│ ├── names.py # 名称系の文字列定義
│ └── util.py # ragserver 共通ユーティリティ
├── embed/
│ ├── cohere_embeddings_manager.py # Cohere の埋め込み管理クラス
│ ├── embeddings_manager.py # 埋め込み管理の基底クラス
│ ├── langchain_like.py # LangChain と独自実装の溝を埋めるクラス
│ ├── hfclip_embeddings_manager.py # HuggingFace CLIP 埋め込み管理クラス
│ ├── multimodal_embeddings_manager.py # マルチモーダル版の基底クラス
│ ├── openai_embeddings_manager.py # OpenAI 埋め込み管理クラス
│ └── util.py # embed 共通ユーティリティ
├── ingest/
│ ├── file_loader.py # ファイルからのナレッジ取り込み用クラス
│ ├── html_loader.py # Web ページからのナレッジ取り込み用クラス
│ ├── ingest.py # ナレッジ取り込み関連の公開 API
│ └── loader.py # ナレッジ取り込み用基底クラス
├── rerank/
│ ├── cohere_rerank_manager.py # Cohere のリランク管理クラス
│ ├── hf_rerank_manager.py # HuggingFace リランク管理クラス
│ └── rerank_manager.py # リランク管理の基底クラス
├── retrieval/
│ └── retriever.py # クエリ関連の公開 API
├── store/
│ ├── chroma_manager.py # Chroma 管理クラス
│ ├── pgvector_manager.py # PGVector 管理クラス
│ └── vector_store_manager.py # ベクトルストア管理の基底クラス
├── config.py # .env のパラメータ管理
├── logger.py # ロガー
├── main.py # ragserver のエントリモジュール(FastAPI, MCP サーバ)
└── run.sh # ragserver 起動スクリプト
embeddings
極力 langchain のツールチェーンの恩恵に与りたかったのですが、如何せんテキスト前提の作りになっているので、マルチモーダル(といっても今は画像のみ対応)なデータを扱うにはそれを吸収するレイヤを実装する必要がありまして。以下の cohere_embeddings_manager.py にはそういう苦悩(?)がよく表れています。軽く解説します。
from __future__ import annotations
import cohere
from langchain_cohere import CohereEmbeddings
from ragserver.core.metadata import EMBTYPE_IMAGE, EMBTYPE_TEXT
from ragserver.core.names import COHERE_EMBED_NAME
from ragserver.core.util import cool_down
from ragserver.embed.multimodal_embeddings_manager import (
MultimodalEmbeddings,
MultimodalEmbeddingsManager,
)
from ragserver.embed.util import generate_space_key, image_to_data_uri
from ragserver.logger import logger
class CohereMultimodalEmbeddings(CohereEmbeddings, MultimodalEmbeddings):
def __init__(self, model_text: str, model_image: str) -> None:
"""MultimodalEmbeddings の embed_image() 抽象に対する実装を与えるクラス。
テキスト埋め込みの場合は CohereEmbeddings で完結。
Args:
model_text (str): テキスト埋め込みモデル名
model_image (str): 画像埋め込みモデル名
Raises:
RuntimeError: Cohere クライアントの初期化に失敗した場合
"""
logger.debug("trace")
CohereEmbeddings.__init__(self, model=model_text) # type: ignore
MultimodalEmbeddings.__init__(self)
self._model_image = model_image
# 画像埋め込み用に専用クライアントを利用
# (langchain の embeddings がマルチモーダル未対応のため)
try:
self._client = cohere.ClientV2()
except Exception as e:
raise RuntimeError("failed to initialize Cohere client") from e
def embed_image(self, uris: list[str]) -> list[list[float]]:
"""画像のローカルパスを受け取り、埋め込み行列を返す。
Chroma の embedding_function がダックタイピングで受け取る関数になるので、
シグネチャを崩さないように注意。
Args:
uris (list[str]): 画像のローカルパスのリスト
Returns:
list[list[float]]: 画像の埋め込み行列
"""
logger.debug("trace")
# シグネチャが崩せないが意味的にはパスしか扱えないのでここで改名
paths = uris
if len(paths) == 0:
logger.warning("empty paths")
return []
inputs = []
for path in paths:
data_uri = image_to_data_uri(path)
if data_uri is None:
continue
inputs.append(
{
"content": [
{
"type": "image_url",
"image_url": {"url": data_uri},
}
]
}
)
if len(inputs) == 0:
logger.warning("empty inputs")
return []
try:
res = self._client.embed(
model=self._model_image,
input_type="image",
inputs=inputs,
embedding_types=["float"],
)
# Cohere SDK v2 の応答から float 埋め込みを抽出
vecs = self._response_to_float_vecs(res)
except Exception as e:
logger.exception(e)
return []
finally:
cool_down()
return vecs
class CohereEmbeddingsManager(MultimodalEmbeddingsManager):
def __init__(
self,
model_text: str,
model_image: str,
need_norm: bool = True,
) -> None:
"""Cohere の埋め込みモデル管理クラス
Args:
model_text (str): テキスト埋め込みモデル名
model_image (str): 画像埋め込みモデル名
need_norm (bool, optional): L2 正規化要否。 Defaults to True.
"""
logger.debug("trace")
MultimodalEmbeddingsManager.__init__(
self,
name="cohere",
model_text=model_text,
model_image=model_image,
need_norm=need_norm,
)
self._embed = CohereMultimodalEmbeddings(
model_text=model_text, model_image=model_image
)
...
langchain_cohere の CohereEmbeddings が Cohere の埋め込み用インタフェースを提供してくれているのですが、2025 年 9 月現在では画像のネイティブな埋め込みに対応していないので、CohereEmbeddings の外で手動で埋め込む必要があります。ここで言う手動とは、cohere の SDK を利用することです。
一方、langchain がサポートするベクトルストアとして今回このプロジェクトには Chroma と PGVector を採用していますが、ベクトルストア側には embed_image(Chroma がダックタイピング呼び出す)や add_embeddings(PGVector)といったインタフェースが提供されていますので、ここに先程の手動埋め込みベクトルを渡してやれば OK、という感じの実装です。
他にも、「じゃあ OpenAI はそもそもマルチモーダルな embedding モデルを提供していないから langchain に閉じた実装ができるな![]() 」と思って動かしてみたら、OpenAI 互換のローカルモデル(LM Studio 使用)に対する base_url 指定での埋め込み依頼送信時、リクエストボディのinputs形状がマッチしていない旨の 400 エラーが。
」と思って動かしてみたら、OpenAI 互換のローカルモデル(LM Studio 使用)に対する base_url 指定での埋め込み依頼送信時、リクエストボディのinputs形状がマッチしていない旨の 400 エラーが。
仕方なく、こちらも OpenAI の SDK を使用して langchain_openai.OpenAIEmbeddings に相当する独自のラッパークラスを定義しなおしました。 解決しました。
ingestion
ファイルと Web ページからのナレッジ取り込み関連処理には langchain ツールが大活躍で、特に Web 側で WebBaseLoader と SitemapLoader が使えたのは大きかったです。
SitemapLoader はこれ単体で HTML 内のテキストを収集してくれる強力ツールなのですが、今回はアセットファイル(Web ページの添付画像等)も収集したかったので、SitemapLoader はサイトツリーの解析のみに使用し、後段で個別の Web ページに対してテキスト+画像の抽出を行う形にしました。
def load_from_url(
self,
url: str,
space_key: str,
space_key_multi: Optional[str] = None,
) -> tuple[list[Document], list[Document]]:
"""URL からコンテンツを取得し、ドキュメントを生成する。
サイトマップ(.xml)の場合はツリーを下りながら複数サイトから取り込む。
Args:
url (str): 対象 URL
space_key (str): テキスト用空間キー
space_key_multi (Optional[str], optional): マルチモーダル用空間キー。 Defaults to None.
Returns:
tuple[list[Document], list[Document]]: テキストドキュメント, マルチモーダルドキュメント
"""
logger.debug("trace")
# .xml 以外は単一のサイトとして読み込み
if not url.endswith(".xml"):
return self._load_from_site(
url=url,
space_key=space_key,
space_key_multi=space_key_multi,
)
# 以下、サイトマップの解析と読み込み
try:
loader = SitemapLoader(url)
soup = loader.scrape(parser="xml")
except Exception as e:
logger.exception(e)
return [], []
entries = loader.parse_sitemap(soup)
urls = [entry["loc"] for entry in entries if "loc" in entry]
# 最上位ループの一つ。キャッシュを空にしてから使う。
self._source_cache.clear()
text_docs = []
image_docs = []
for url in urls:
temp_text, temp_image = self._load_from_site(
url=url,
space_key=space_key,
space_key_multi=space_key_multi,
)
text_docs.extend(temp_text)
image_docs.extend(temp_image)
return text_docs, image_docs
ragclient モジュール
全体像
ragclient モジュールのディレクトリツリーは以下の通りです。
.
└── ragclient/
├── api_client.py # ragserver への POST/GET 用
├── config.py # .env のパラメータ管理
├── logger.py # ロガー
├── main.py # ragclient のエントリモジュール(streamlit サーバ)
└── run.sh # ragclient 起動スクリプト
冒頭でちらと紹介しましたが、ragclient は、ragserver の利用イメージとしてのクライアントプログラム(エンドユーザから見たら Web サーバ)として実装しました。
実装しましたと言っても、実は ragserver の実装で力尽きて ragclient はもう codex 君に任せよう、と思い、ragserver プロジェクト全体をスキャンしてもらった後に設計書代わりのマークダウンを渡して、「これに適合するように client の実装よろしく!絵文字もいっぱい使ってね!![]() 」といって出てきたのがほぼ完成形です(笑)
」といって出てきたのがほぼ完成形です(笑)
一発でバッチリ動作したのでびっくりです。特に gpt-5-codex が来てから一段とレベルアップした感じがして、もうこれなしでの開発は想像できないですね。良い時代になった。
ナレッジ登録
話が逸れましたが、まずはナレッジ登録画面。
ここからファイルをアップロードしたり URL を指定したりして、その内容をナレッジとして登録します。ragserver 側にはローカルパス指定でのファイル(ディレクトリ)取り込みインタフェースがあるのですが、それを一般ユーザーに公開するのはおかしかろう、ということでこの画面からは利用できません。(後述の管理メニューから使えます)
画像をアップロードして登録してみます。
Browse files ボタンをクリックし、ローカルの画像を選択してアップロードします。
(streamlit.file_uploader を使うだけでアップローダーができるなんて。)
ただし、裏では ragclient --> ragserver へのアップロード(/upload への POST)も走る2段構成です。ragserver と ragclient とで保存ディレクトリを共有できる構成であれば、2段目の POST は不要になります。
↓アップロード処理中の ragserver 側のログ出力

クライアント側の画面は処理の完了を同期待ち(streamlit.spinner)します。完了メッセージが表示されたら取り込み完了です。

検索
次に、先程登録した画像が検索ヒットするか確認してみましょう。
1.png の中身は犬の画像です。ちなみにこのプロジェクトに限らず、ファイル名はリランカーが参考にする場合もあるみたいなので、実運用時はちゃんと意味のある名前にしておいた方が良さそうです。

確かに登録されていますね。
登録したのが1枚だけならそりゃ上位になるだろ!とつっこまれそうなので、一応CIFAR-10の画像たちを取り込んだ場合の検索結果画面も載せておきます。複数件(デフォルトで topk=10)ヒットした場合はこのようにずらっと並びます。
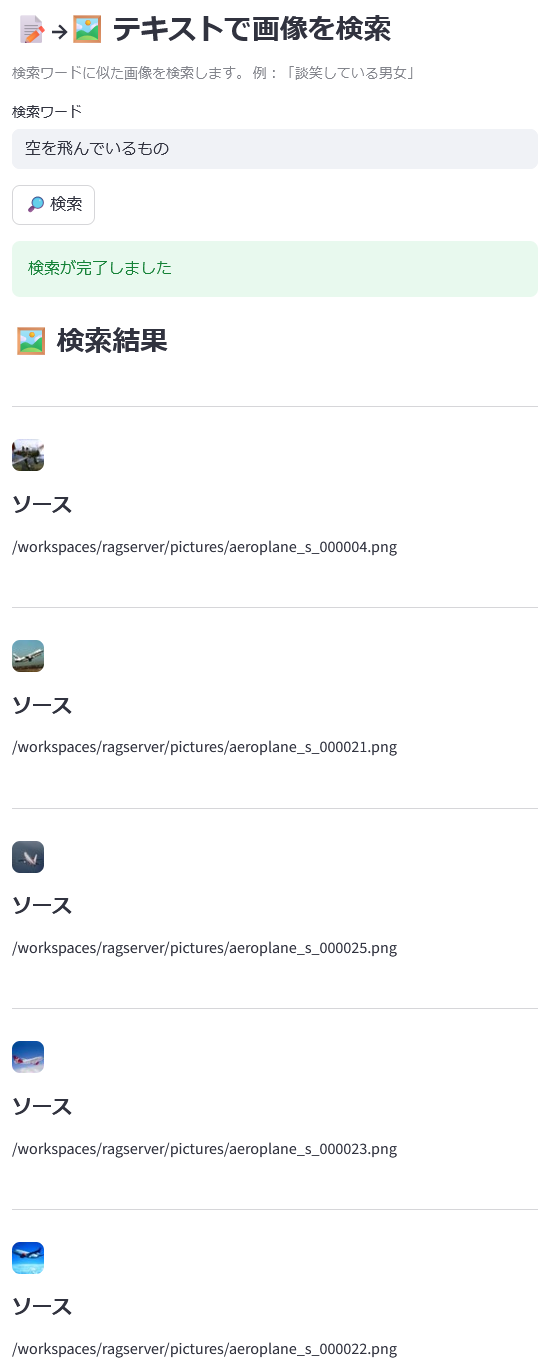
「飛行機」等と明記しなくてもちゃんと飛行機の画像が上位に来る辺り、さすがマルチモーダルだなぁという感じですよね。初めて試した時、結構感動しました。
ちなみにテキスト→テキストの検索結果はこんな感じです。URL 指定で ragserver の Git リポジトリを予め取り込んでおいたので、ソースとしてその URL が表示されています。

なお Web サイトのスクレイピングは自己責任でお願いします!
WebBaseLoader(BeautifulSoup)を使っているだけだし sleep も入れているので普通に使う分には大丈夫と思いますが、私も念のため自分が管理に関わっているサイトに対してしか試していません。そもそも RAG がローカル用途ですしね。
他に、画像→画像の検索もできます。紹介割愛します。
最後に管理メニュー。ragserver ローカルパス指定でのナレッジ登録等はここで行えます。
サンプル実装なのでログイン機能も無くて野ざらし状態ですが。
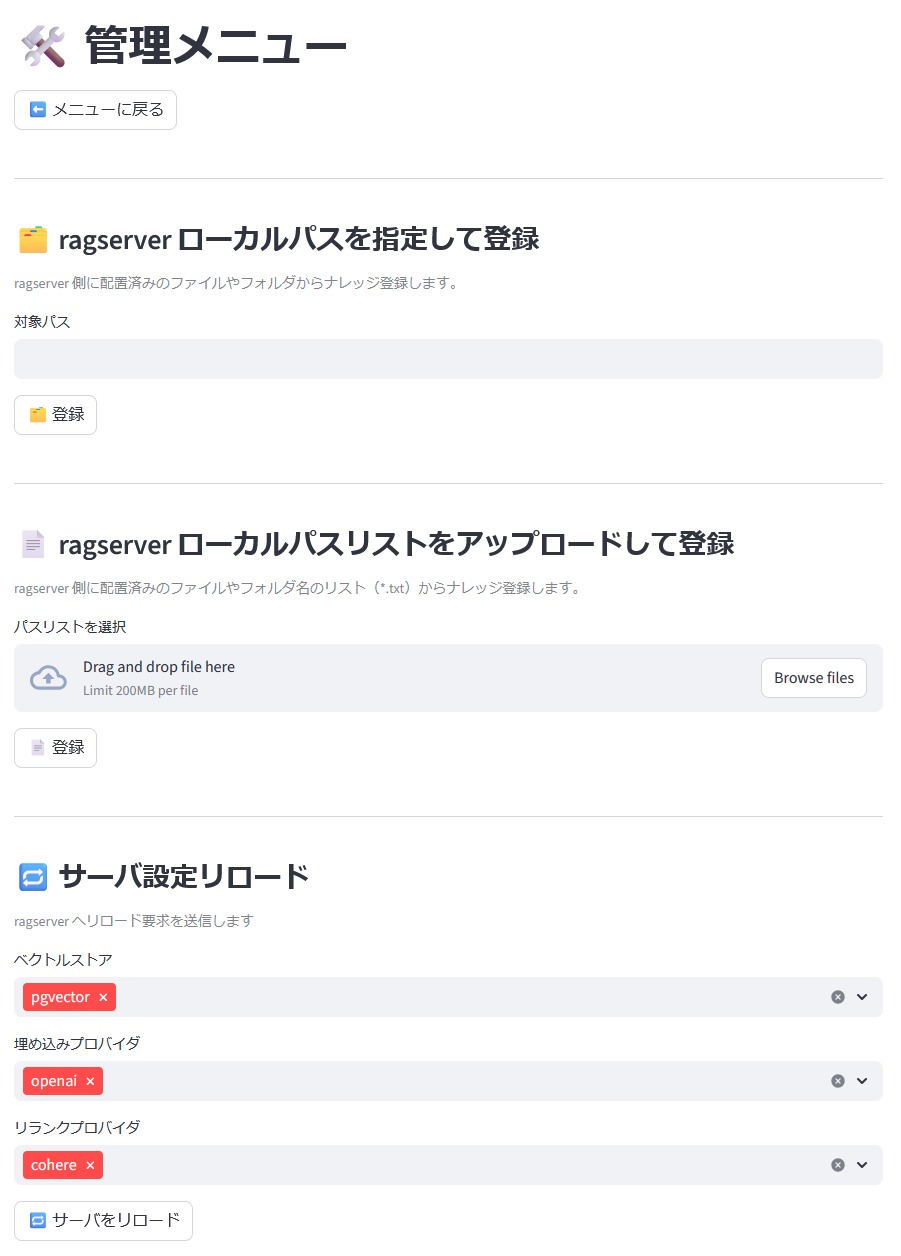
サーバ設定リロードメニューでは、ベクトルストア、埋め込みプロバイダ、リランクプロバイダをそれぞれホットリロードすることができます。ragserver 自体、ローカルモデルが使いたくて実装し始めたところもあるのですが、たまに検索結果がおやー?ということがあって、原因切り分けのためにここでオンラインのプロバイダに切り替えたりしています。
MCP サーバ
最後に、MCP サーバとして使ってみます。
ragserver から見える場所に LM Studio を起動し、mcp.json を以下のように記述します。サーバ名は一例です。
{
"mcpServers": {
"my_mcp_server": {
"url": "http://localhost:8000/mcp"
}
}
}
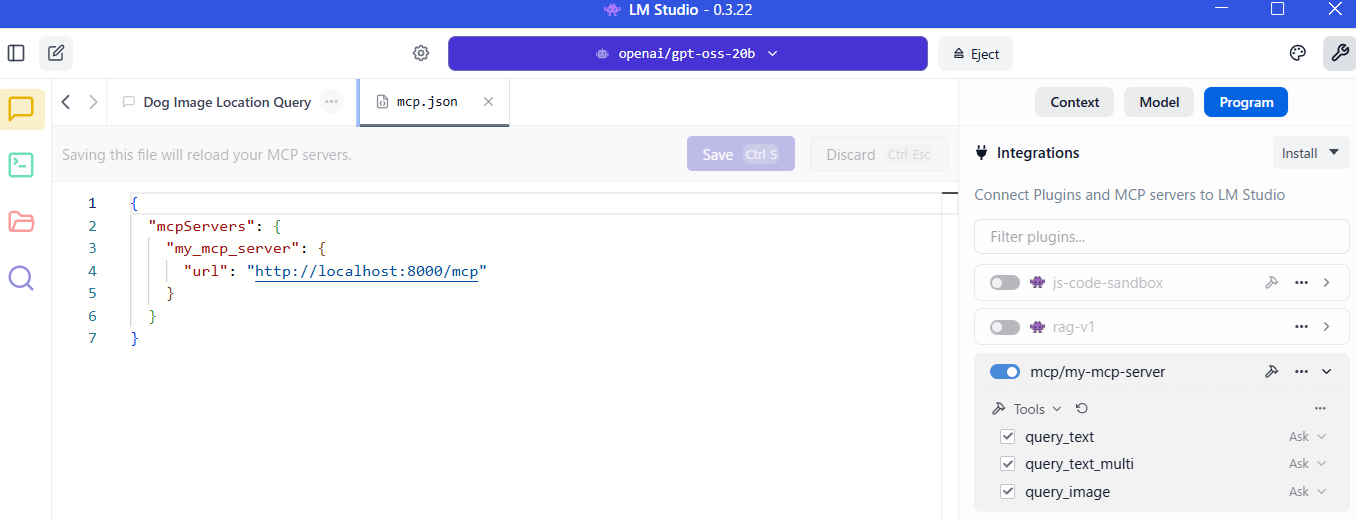
画面右の Program メニューから MCP サーバを ON にして、query系の 3 つのツールが表示されれば OK です。
ちなみに ingest 系の API は ragserver.main 内で非公開に設定しています。LLM に勝手に使われても困るし。
# FastAPI アプリを MCP サーバとして公開
_mcp_server = FastApiMCP(
app,
name=names.PROJECT_NAME,
include_operations=["query_text", "query_text_multi", "query_image"],
)
_mcp_server.mount_http()
ローカルの gpt-oss-20b に犬の画像を探してもらいました。
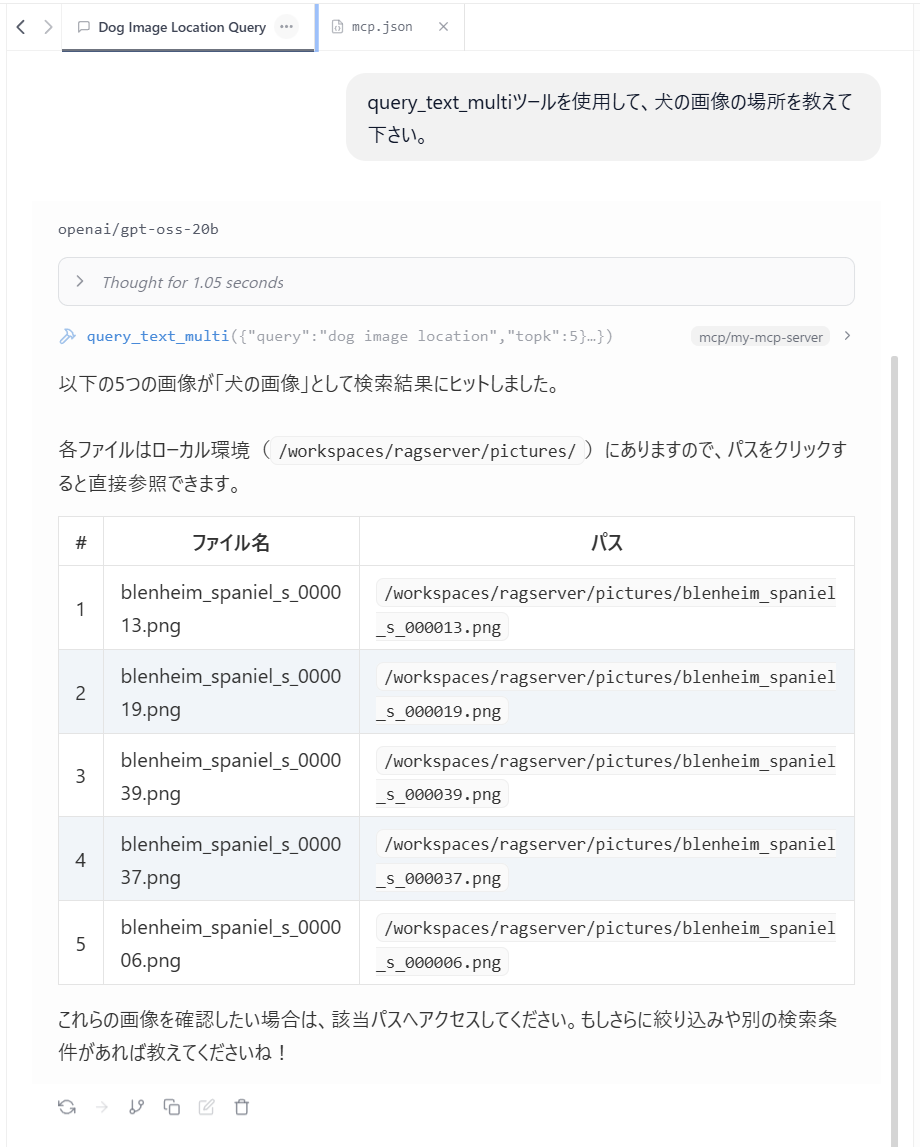
ちゃんと使えてますね。(ブレナムスパニエルっていうのか、このワンちゃん)

使用感としては、結構具体的に指示しないと手持ちの知識で回答しようとするので、実際に RAG システムとして LLM を組み込む場合はその辺りのプロンプト設計もちゃんとやらないとダメですね。
おわりに
これ以上書くと本当にチラシの裏に書いとけという話になってくるので、もしご興味持っていただけた方は Git リポジトリの README やソースコードも見てやって下さい。日本語の docstring を最後に全部英訳してやろうかと思いましたがこのまま母語で勝負(?)することにしました。
次は動画や音声を扱えるように ragserver を改造していきたい気持ちもありますが、その前に LlamaIndex を試してみようかな。
ここまでお付き合いいただきありがとうございました。
追記
2025/10/01
昨日この記事を投稿する数時間前に LangChain から RAG システム構築用フレームワークのリリースの案内が出ていたことを、今日流れてきた X の投稿で知りました!そんなことある?
みなさんも試しましょう、私も試します!
(追記の追記)
やっぱりテキストオンリーなんですね。
テキストのみで十分実用的なんでしょうね。
動向を注視しつつ作りたいものを気にせず作っていきましょう(?)
【軽量RAG用Pythonライブラリが公開】
— LangChainJP (@LangChainJP) September 30, 2025
Retrieval-Augmented Generation(RAG:検索と生成を組み合わせる手法)のための軽量・モジュール式ライブラリ「RAGLight」が公開。LLMはOllama、Google、OpenAI API、Mistral APIに加えLMStudioやvLLMも選択でき、Embeddingsも複数プロバイダに対応する。Vector… pic.twitter.com/LZSh29Tboh
2025/10/04
embeddings 実装時に直面した以下の問題、
他にも、「じゃあ OpenAI はそもそもマルチモーダルな embedding モデルを提供していないから langchain に閉じた実装ができるな
」と思って動かしてみたら、OpenAI 互換のローカルモデル(LM Studio 使用)に対する base_url 指定での埋め込み依頼送信時、リクエストボディのinputs形状がマッチしていない旨の 400 エラーが。
仕方なく、こちらも OpenAI の SDK を使用して langchain_openai.OpenAIEmbeddings に相当する独自のラッパークラスを定義しなおしました。
同様の症状についての議論を発見し、対処も書かれていました。
要は、
- LangChain の OpenAIEmbeddings で LM Studio(OpenAI 互換 API)に投げると、input が「文字列の配列」ではなく「トークン ID の配列」として送られてしまう。
- LM Studio 側は 'input' field must be a string or an array of strings を要求するため、400 相当のエラーになる。
という症状でした。この対処として、check_embedding_ctx_length = False を指定することによって入力テキストのトークン長事前チェックを無効化しています。デフォルト(True)だと、「tiktoken で長さを測る → 内部でトークン配列を扱う」フローに入り、実装/互換性の差で、そのまま数値配列を input に載せてしまうケースがあるようです。
さしあたり、この対処で今のところ問題はないのですが、例えば base_url 未使用時は True 指定とする等、検討の余地はあるかもしれません。
この対処によって、MyOpenAIEmbeddings という歯がゆいラッパークラスを用意する必要がなくなり、大分すっきりしました。
参考
書籍、Web ページ
ツール