はじめに
二か月前くらいに前回の記事を書いてみたのですが、その後も multimodal embeddings に魅せられた私は、LlamaIndex, CLIP, CLAP と、色々と試して遊んでおりました。
前回の記事では LangChain ベースで実装したものを紹介させていただきましたが、ちょっとまだ構想が散らかっていたのと、実装終盤になって LlamaIndex ならどんな実装になっただろう、というのが気になってきて、結局もう一度作り直してみることにしました。
せっかくならということで、今回は Raggify という PyPI ライブラリとしてリリースしてみました。

ちゃっかりアイコンまで用意。ChatGPT くんに「恐竜の赤ちゃんをモチーフにしたアイコンお願い!」って言ったら一発で出してくれました。かわいい。
PyPI のプロジェクトページはこちら。
Git リポジトリはこちら。
この記事では、Raggify の README をなぞりながら、前回(multimodal_ragserver)には未だなかった機能・特徴についてご紹介させて頂ければと思います。
🔎 システム概要
前回の multimodal_ragserver とざっくり目指す向きは同じなのですが、今回 Raggify として練り直した結果、システム構成は下図のように変わりました。
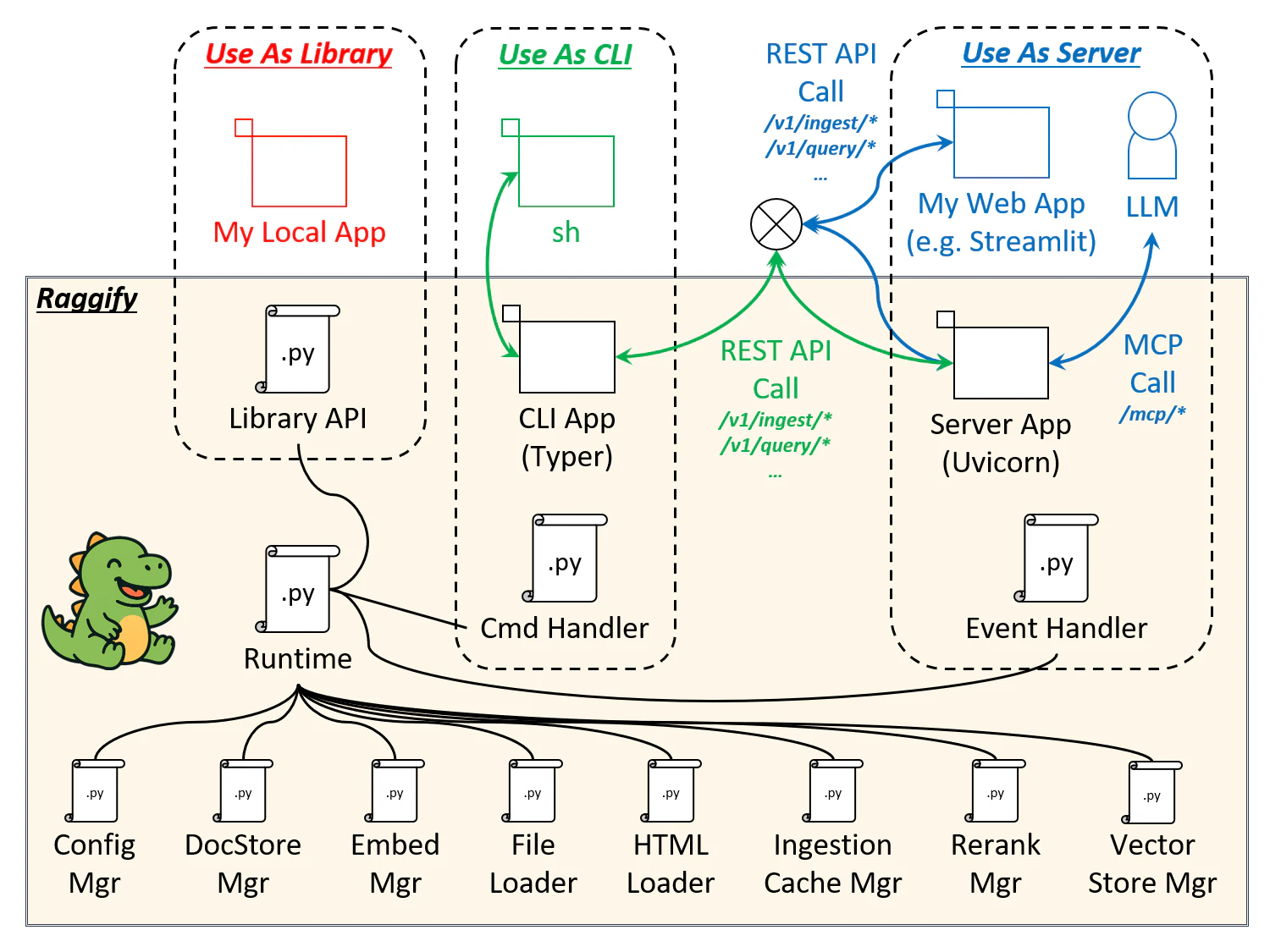
改めてご紹介させていただきますと、Raggify は、
ローカルまたはサービスとして動作するマルチモーダル RAG(検索拡張生成)システムを構築するためのLlamaIndex ベースの Python ライブラリです。ファイル、ウェブページ、URL リスト向けの非同期取り込みパイプラインを搭載し、メタデータを正規化、重複したアップサートを回避するためのキャッシュフィンガープリントを永続化、BM25 / Vector ハイブリッド検索用にドキュメントストアを同期状態に保ちます。
テキストモダリティを基盤としたシステムを繰り返し改修するのではなく、画像・音声・動画・その他未知の将来モダリティを含むマルチモーダルデータを最初からネイティブに処理することを目標に設計されています。また、各 AI プロバイダーが提供する組み込みモデルやクライアント API の様々な仕様変更を吸収する役割も担います。
です。主に以下の3つの形態での利用を想定しています。
-
Library
PyPI ライブラリとして pip install し、import してローカルアプリ実装に利用できるようにしてみました。 -
REST API Server / MCP Server
REST API サーバとして常駐させます。前回の構成に近いです。MCP サーバとしても利用できます。 -
CLI
CLI 上でドキュメントの取り込みやクエリ発行ができるようにしてみました。REST API サーバをバックエンドとするため、予めサーバとして起動済みであることが前提です。
なお、今回新たに音声(audio)モダリティと動画(video)モダリティに対応しています。扱う情報量がリッチなモダリティほど対応プロバイダが少なく、動画に関しては未だ bedrock 一択です。
この記事を書く一週間前、そろそろ Raggify 一区切りにするか~と思ったら以下の記事が彗星の如く X のタイムラインに流れてきて泣き笑い状態でした。動画をネイティブに埋め込み可能な amazon.nova-2-multimodal-embeddings-v1:0 登場。README 書き上げる前に知りたかった。そして急遽取り入れました。
※Raggify に組み込むにあたり、色々ハマったポイントは別記事に書き出しました。
動画だけでも十分すごいですが、なんとこの nova2、テキスト、画像、音声も全て同一のベクトル空間で埋め込み可能なのです…!これにより、Raggify 的には動画モダリティに進出できるだけでなく、音声モダリティの選択肢がローカル CLAP 一択 → API 利用も可、になりました。地味にでかい。
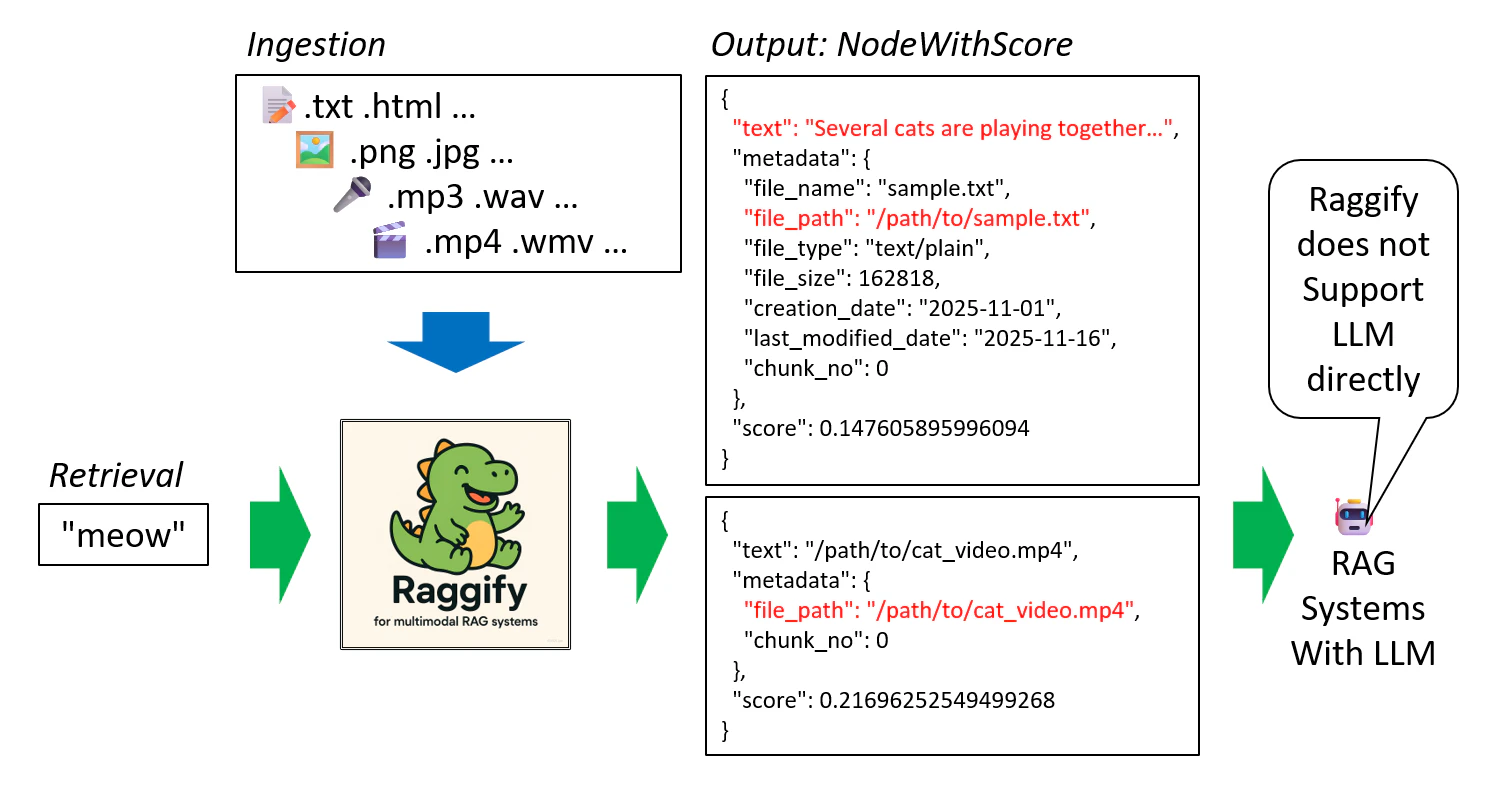
なお、Raggify は前述の通り、RAG システム全体で見ると前段部分のドキュメント取り込み(Ingestion)、検索(Retrieval)の部分を担う想定で作っておりますので、今世の中で色々盛り上がっている LLM や エージェントの部分を直接は扱いません。裏方に徹します(?)。
また、今回はより多くの人の目に触れて欲しいという願いも込めて docstring と README は全て英訳しました。以降、README の内容を軸に(安心の母語で)補足していこうと思います。
🚀 インストール方法
pip install で入ります。
pip install raggify
4モダリティ+リランカーがそれぞれローカルモデルだったり外部 API だったりするので依存はなかなか heavy です。個人的にはローカルモデルの利用が多いですが、流石に最重量構成をデフォルトにするのは気が引けたので、
"vector_store_provider": "chroma",
"document_store_provider": "local",
"ingest_cache_provider": "local",
"text_embed_provider": "openai",
"image_embed_provider": "cohere",
"audio_embed_provider": "bedrock",
"video_embed_provider": "bedrock",
"rerank_provider": "cohere",
にしてあります。設定変更方法は後程。
また、リポジトリに examples/rag として置いてある RAG 検索アプリのサンプル実装を動かすのに streamlit と openai-agents が必要なのでオプションとしています。
pip install 'raggify[exam]'
その他、embedding や rerank にプロバイダの API を利用する場合はお手元に .env ファイルを用意する等して API キーを見せてやって下さい。
OPENAI_API_KEY="your-api-key"
COHERE_API_KEY="your-api-key"
VOYAGE_API_KEY="your-api-key"
AWS_ACCESS_KEY_ID="your-id"
AWS_SECRET_ACCESS_KEY="your-key"
AWS_REGION="us-east-1" # (default)
# AWS_PROFILE="your-profile" # (optional)
# AWS_SESSION_TOKEN = "your-token" # (optional)
前述の通り、デフォルトでは外部 API プロバイダとして OpenAI, Cohere, Bedrock が指定してありますので、API キーが無い状態で該当する埋め込みを実行しようとするとエラーになります。画像埋め込みとしては他に Voyage もサポートしています。
OpenAI、AWS は言わずもがな、せっかくの(?)機会ですので、Cohere や Voyage も API キー未取得の方はぜひ。無料でも十分使えますし、LLM と違って Embed は単価も安いです。
ところで、ローカル CLIP と CLAP の利用には Git リポジトリから直接引っ張ってこなければならない依存があります。これらは PyPI パッケージ作成時の依存にも含めることができませんでしたので、CLIP と CLAP を使用する場合はお手数ですが手動インストールが必要です。
pip install clip@git+https://github.com/openai/CLIP.git
pip install openai-whisper@git+https://github.com/openai/whisper.git
📚 ライブラリとしての利用
📝 examples/ex01.py
典型的な例として、ローカルの Python アプリ実装上で Raggify を利用するパターンです。この例では、いくつかの Web サイトからドキュメントを取り込み(ingest_url_list)、テキストクエリでテキストドキュメントを検索(query_text_text)し、結果を表示しています。
import json
from raggify.ingest import ingest_url_list
from raggify.retrieve import query_text_text
urls = [
"https://en.wikipedia.org/wiki/Harry_Potter_(film_series)",
"https://en.wikipedia.org/wiki/Star_Wars_(film)",
"https://en.wikipedia.org/wiki/Forrest_Gump",
]
ingest_url_list(urls)
nodes = query_text_text("Half-Blood Prince")
for node in nodes:
print(
json.dumps(
obj={"text": node.text, "metadata": node.metadata, "score": node.score},
indent=2,
)
)
なお、retriever の返却するデータ構造は llama_index の NodeWithScore です。独自形式で包むか迷いましたが今のところ llama_index のラッパーライブラリという体裁で特に問題なさそうなのでそのままにしています。
主要な公開インターフェースは以下です。
# For reference
# Retrievers return this structure
from llama_index.core.schema import NodeWithScore
# For REST API Call to the server
from raggify.client import RestAPIClient
from raggify.config import (
DocumentStoreProvider,
EmbedModel,
EmbedProvider,
IngestCacheProvider,
RerankProvider,
RetrieveMode,
VectorStoreProvider,
)
# For ingestion
from raggify.ingest import (
aingest_path,
aingest_path_list,
aingest_url,
aingest_url_list,
ingest_path,
ingest_path_list,
ingest_url,
ingest_url_list,
)
# For logging
from raggify.logger import configure_logging, logger
# For retrieval
from raggify.retrieve import (
aquery_audio_audio,
aquery_audio_video,
aquery_image_image,
aquery_image_video,
aquery_text_audio,
aquery_text_image,
aquery_text_text,
aquery_text_video,
aquery_video_video,
query_audio_audio,
query_audio_video,
query_image_image,
query_image_video,
query_text_audio,
query_text_image,
query_text_text,
query_text_video,
query_video_video,
)
# For hot reloading config
from raggify.runtime import get_runtime
🖼️ examples/ex02.py
from raggify.ingest import ingest_url
from raggify.retrieve import query_text_image
url = "https://developers.llamaindex.ai/python/examples/multi_modal/multi_modal_retrieval/"
ingest_url(url)
nodes = query_text_image("what is the main character in Batman")
次は単一 URL からの取り込み(ingest_url)と、テキストクエリによる画像ドキュメントの検索(query_text_image)の例です。
初めてのクロスモーダル検索の例です。「Batman のメインキャラクターは?」とテキストで問い合わせるとバットマンの画像が最上位にくるので、初めて試した時は「お~」と結構感動しました。
なお、画像を扱うにはデフォルトで Cohere を使用する設定になっていますが、ローカル CLIP を使用する場合は先述の通り追加インストールが必要です。また、画像埋め込みのプロバイダを CLIP に変更します。
pip install clip@git+https://github.com/openai/CLIP.git
image_embed_provider: CLIP
Raggify では冒頭の図にも出てきた Runtime というモジュールに各管理モジュールや設定値の依存を集約しているため、ライブラリとしての利用時にも各種設定値は /etc/raggify/config.yaml のものをデフォルトとして参照します。
🎤 examples/ex03.py
from raggify.ingest import ingest_path_list
from raggify.retrieve import query_text_audio
paths = [
"/path/to/sound.mp3",
"/path/to/sound.wav",
"/path/to/sound.ogg",
]
ingest_path_list(paths)
nodes = query_text_audio("phone call")
次はローカルの複数パスからの取り込み(ingest_path_list)と、テキストクエリによる音声ドキュメントの検索(query_text_audio)の例です。
paths は絶対パス表記です。音声埋め込みの対応プロバイダはテキスト、画像と比べて選択肢が大分減って、今のところローカル CLAP と bedrock のみです。CLAP を使用する場合は、CLIP 同様、追加インストールと設定変更が必要です。
pip install openai-whisper@git+https://github.com/openai/whisper.git
audio_embed_provider: CLAP
また、自分でもまだ多くの条件では試せていないため要検証ですが、日本語のテキストクエリには反応していない気がします。英単語だとそれらしい結果が返ってきているような。ナレッジの件数が少ないとスコアが安定しないのと、リランカーが ON になっているとファイル名を見てしまったりするので、これから厳密に検証していこうと思います。
🎬 examples/ex04.py
from raggify.ingest import ingest_path
from raggify.retrieve import query_image_video
knowledge_path = "/path/to/videos"
ingest_path(knowledge_path)
query_path = "/path/to/similar/image.png"
nodes = query_image_video(query_path)
次はローカルの単一パスからの取り込み(ingest_path)と、画像クエリによる動画ドキュメントの検索(query_image_video)の例です。
権利関係がややこしそうなので具体的な画像ファイルや動画ファイルを例示できないのが残念ですが、私の手元では猫の画像を渡して別の猫の動画が検索上位に来たので「お~」となりました。
動画の場合、プロバイダとしては現状 bedrock が唯一の選択肢です。追加の依存はありませんが、AWS の認証情報各種を .env に記入の上、使用する必要があります。一応今後を見越してリージョンをパラメータとして浮かせてありますが nova2 を使用するのであれば us-east-1 しかないので特に書く必要はありません。また、セッショントークンを使わない場合は AWS_PROFILE や AWS_SESSION_TOKEN も要らないので、実質 AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY の二行追記で済むはずです。
AWS_ACCESS_KEY_ID="your-id"
AWS_SECRET_ACCESS_KEY="your-key"
AWS_REGION="us-east-1" # (default)
# AWS_PROFILE="your-profile" # (optional)
# AWS_SESSION_TOKEN = "your-token" # (optional)
なお、これは Raggify というより nova2 の制約なのですが、
- 動画の長さは 30 秒未満であること。
An error occurred (ValidationException) when calling the InvokeModel operation: Invalid input configuration. Source video length exceeds the 30 second limit - リクエストボディ(動画バイナリ+リクエスト JSON)のサイズが 100MB を超えないこと。
(エラーメッセージ控え忘れました)
が要求されます。動画 30 秒未満は結構つらいですね。ただ、ここを見ると、
この例では、動画ファイルのビジュアルと音声の両方のコンポーネントから埋め込み情報を抽出する方法を示します。セグメンテーション特徴量により、長い動画が扱いやすいチャンクに分割されるため、何時間にも及ぶコンテンツを効率的に検索できます。
# Amazon S3 クライアントを初期化します
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# 音声付き動画の非同期埋め込みジョブを作成します
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # 15 秒単位のチャンクにセグメント化します
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
こんな記述があり、durationSeconds というパラメータの存在が確認できます。これを使えばいけるか…!と思って色々試したのですが、Malformed input request と言われてどうにも上手くいきませんでした。上記の見本の model_input とほぼ一致させたのですが、唯一、source だけは
"source": {
"bytes": "Jthe9QP8YgJP+Gmsz/AkcSzLTVDrnN3jtkg7WYUU1Qg0..."
}
という感じで渡そうとしていたので、見本の通り動画ファイルを S3 に置いて URI 指定で渡したらもしかしたら上手くいくのかもしれません。一旦心が折れたので、追々試そうと思います。
あと、動画埋め込みを直接扱えるプロバイダがまだまだ希少なので、use_modality_fallback というオプションを一応用意しました。
video_embed_provider: null
use_modality_fallback: true
の時、動画ファイルを複数画像+音声ドキュメントとして取り込みます。つまり、画像と音声モダリティの経路がそれぞれ生きていれば動画を取り込むことができます。ただ、この経路で取り込むと、例えば一本の動画に対して数百枚の画像が画像モダリティのストアを汚すので、使い方を工夫しないと動画と無関係の画像が埋もれてイマイチかもしれません。
🔄 examples/ex05.py
from raggify.config.embed_config import EmbedProvider
from raggify.config.vector_store_config import VectorStoreProvider
from raggify.ingest import ingest_url
from raggify.logger import configure_logging
from raggify.runtime import get_runtime
configure_logging()
rt = get_runtime()
rt.cfg.general.vector_store_provider = VectorStoreProvider.PGVECTOR
rt.cfg.general.audio_embed_provider = EmbedProvider.CLAP
rt.cfg.ingest.chunk_size = 300
rt.cfg.ingest.same_origin = False
rt.rebuild()
ingest_url("http://some.site.com")
次はプログラム実行中に設定をホットリロードする例です。
基本的にはプログラムを起動する前に /etc/raggify/config.yaml を書き換えておいて、起動時にその設定を読ませる使い方を想定していますが、get_runtime というインタフェースを使えばメモリ上の設定オブジェクトにアクセスでき、rebuild によって設定オブジェクトに依存する各種オブジェクトを再生成できます。
ただ、CLIP 等のローカルモデルを使用している場合は rebuild によってモデルのリロードが走ったりして激重です。
💻 REST API Server としての利用
✅ サーバ起動
後程ご紹介しますが Raggify には CLI があり、サーバとして利用する場合は
raggify server
というコマンドを実行することで起動します。

起動後、REST API 経由で Ingestion や Retrieval の依頼を受け付けられるようになります。

終了する場合は Ctrl + c で。

📚 RAG システムのサンプル実装
冒頭で触れた通り、Raggify 自体は LLM や エージェントを直接サポートしないのですが、API を整備する上で自分自身利用イメージが湧きにくい場面もあったので、Streamlit を使ってサンプルアプリを実装してみました。
リポジトリ内の examples/rag ディレクトリがそれです。run.sh で起動します。
cd examples/rag
./run.sh
追加の依存インストールが未だであれば以下を実行します。
pip install 'raggify[exam]'
見た目はこんな感じ↓です。
メインメニュー
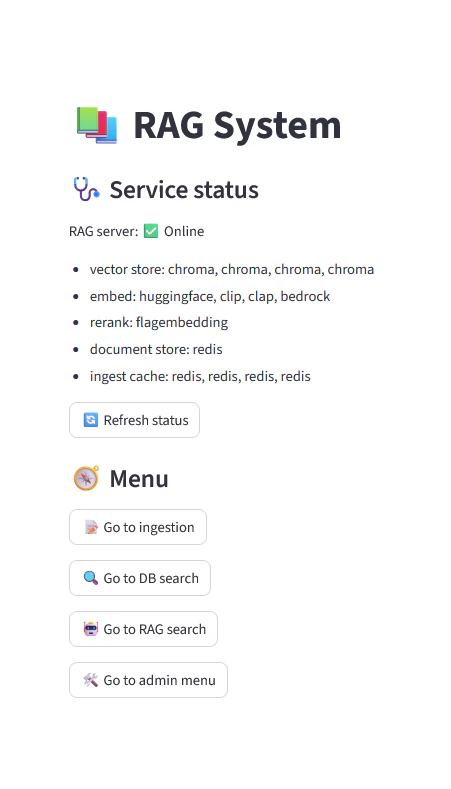
改めて見るとステータス表示とか雑でした。ベクトルストア、埋め込み、キャッシュが4連になっているのはストアをモダリティごとに分けているためです。
ナレッジベース登録
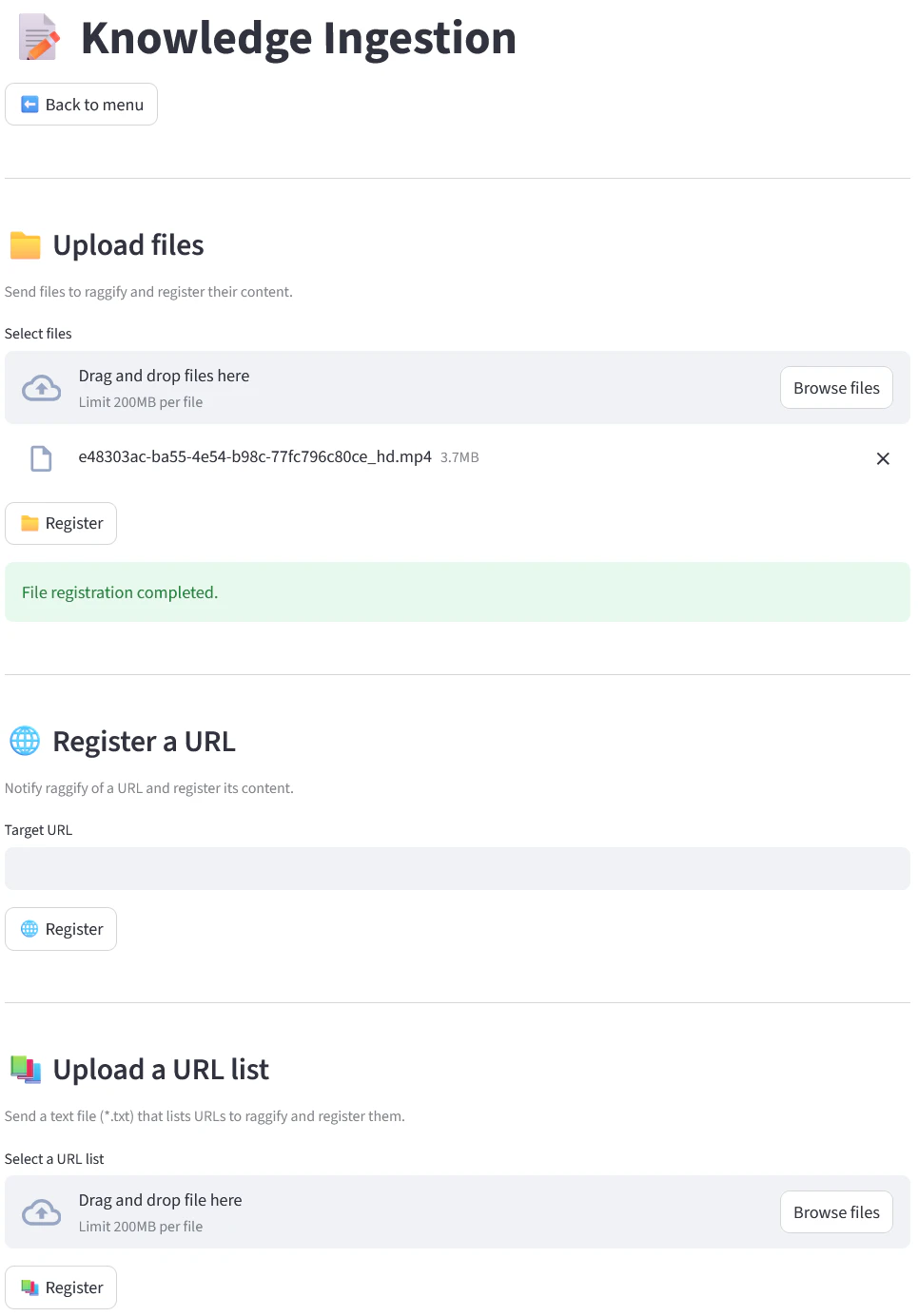
- ファイルアップロード
- URL 指定
- URL リスト(テキストファイル)アップロード
のいずれかの方法でドキュメントを登録できます。URL リストは以下のような形式を想定していて、コメント行(#)と空行を読み飛ばします。
http://some.site.com
http://hoge.site.com
# http://fuga.site.com
http://piyo.site.com/sitemap.xml
URL としてサイトマップ(.xml)を渡すと専用経路でサイトツリーを再帰的に取り込みます。
データベース検索
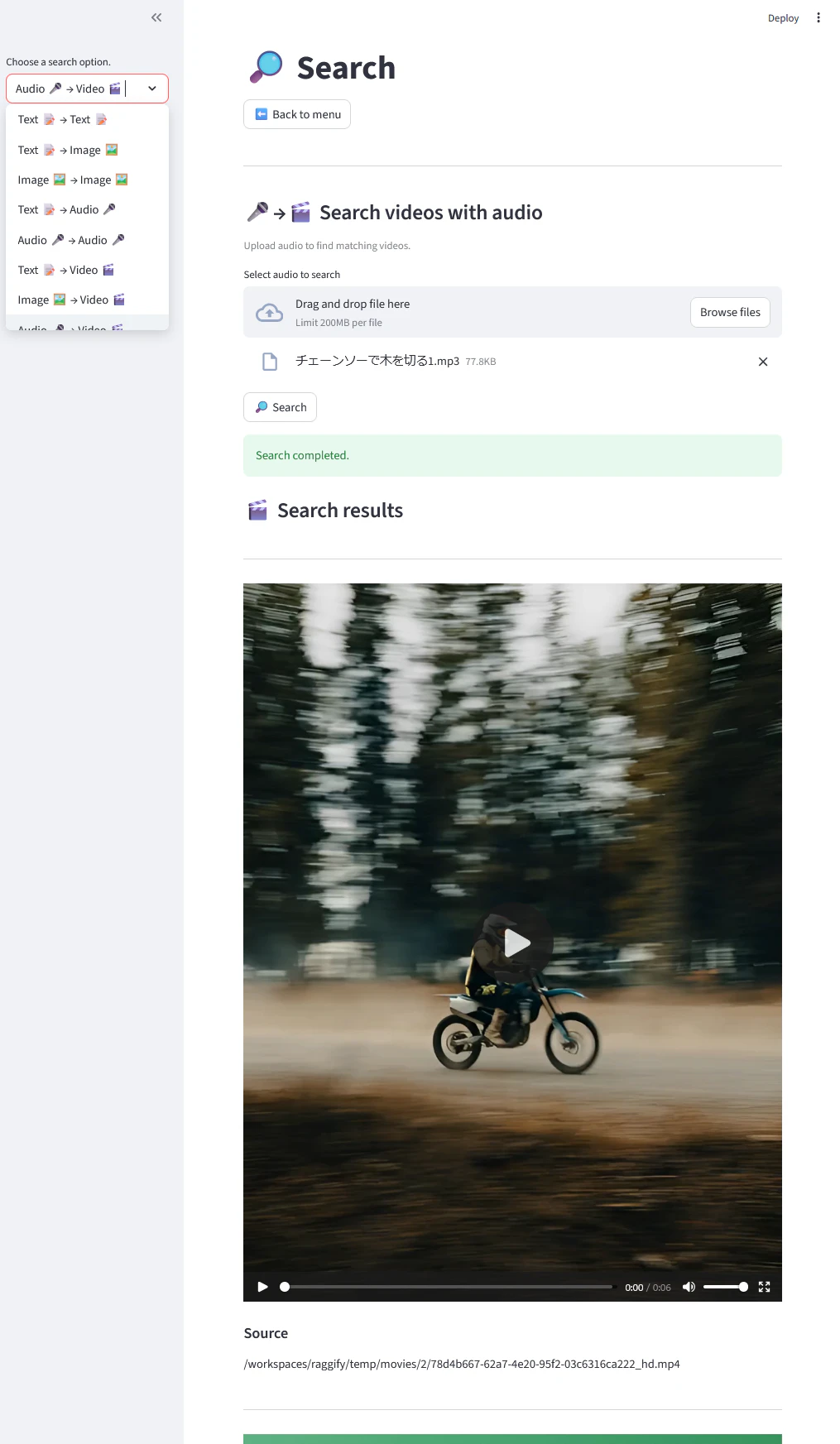
これが一番派手な(?)機能です。画面左のメニューから色々なパターンのクロスモーダル検索を試せます。上の例は、チェーンソーで木を切る音🎤をクエリとして検索実行し、バイクが爆走する動画🎬が最上位に来ているところです。どちらも「ブーーン」ですからね。これぞクロスモーダル検索の醍醐味。
他にも、テキスト → 画像検索なんかは恩恵を実感しやすいです。でたらめなファイル名であってもちゃんとクエリテキストに沿った内容の画像が返ってくるので。
RAG 検索
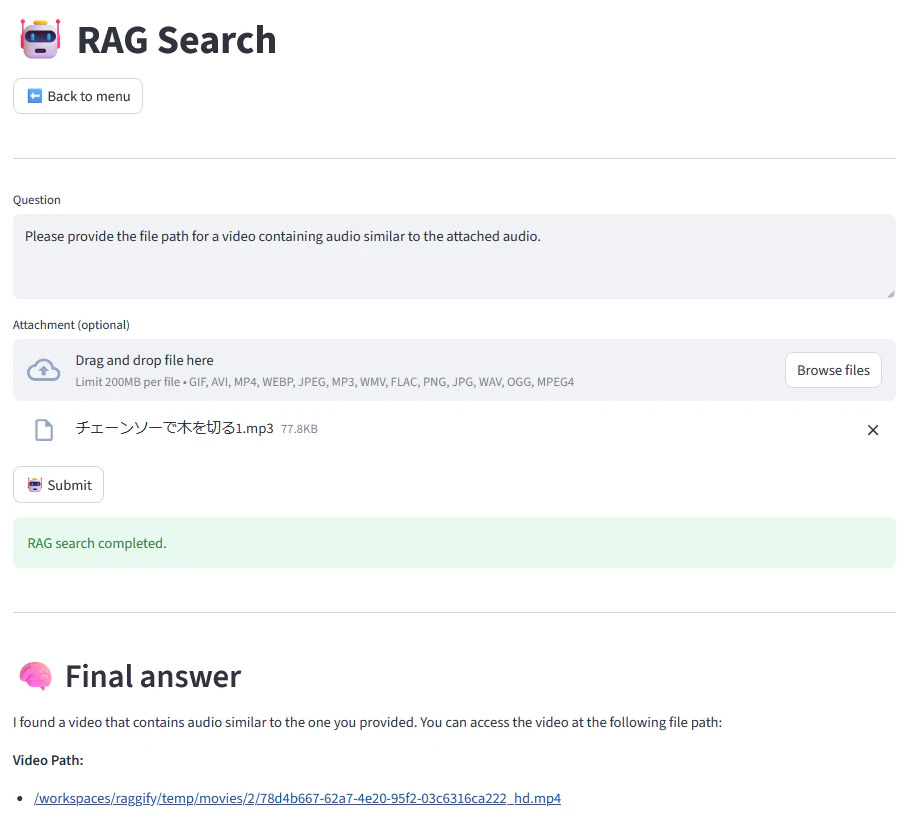
最終的には、先程のデータベース検索結果をこのように LLM に渡してやることで RAG システムとしては完成、という感じだと思います。これはデモ実装なので質問 → 回答の1ラリーで終わりますが、ちゃんとチェーンソーの音声ファイルからバイクの動画の格納場所を回答してくれました。
⌨️ CLI としての利用
raggify --help
先程のデモアプリは背後で Raggify の REST API クライアントを使用していました。ほぼ同様の機能が CLI コマンドとしても利用可能です。
コマンド一覧は help から。
raggify --help
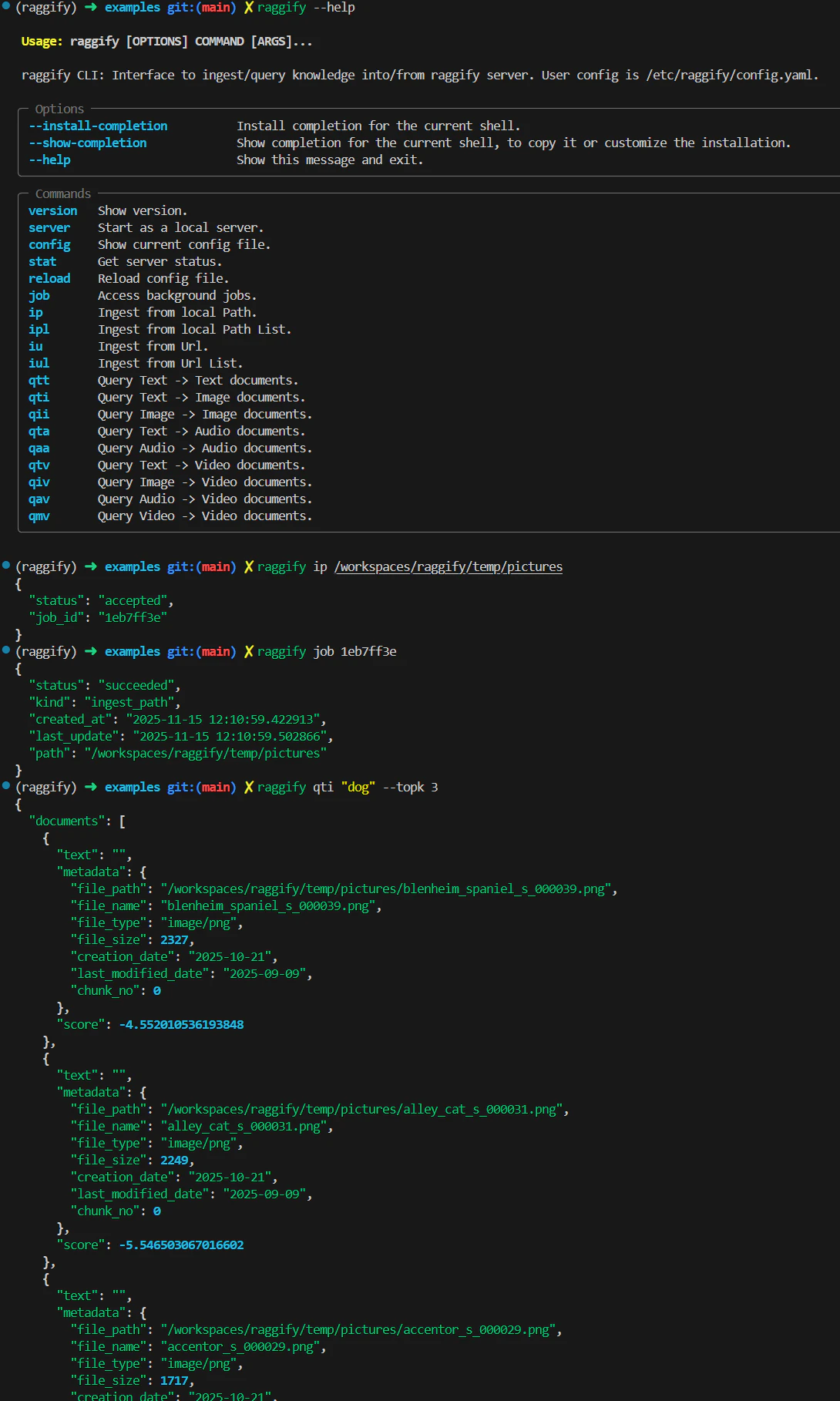
一部のサブコマンドは単体で動作しますが、Ingest 系、Query 系のサブコマンドは全て Raggify サーバの動作を前提としているため、予め raggify server を実行し起動しておく必要があります。
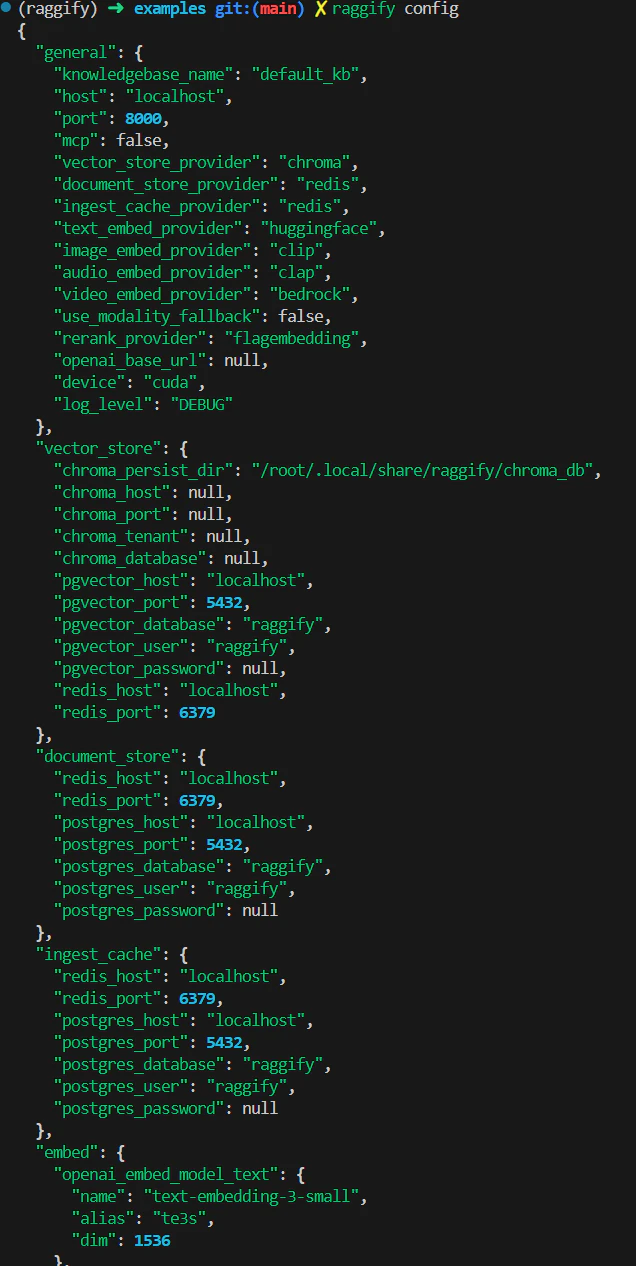
raggify config
現状の /etc/raggify/config.yaml の内容は raggify config コマンドで確認できます。なお、config.yaml を削除した状態で raggify config を叩くとデフォルト設定でファイルを再生成します。
🤖️ MCP サーバとしての利用
raggify server --mcp
サーバー起動時、以下のように --mcp オプションを付けることで MCP サーバとしてもアクセス可能になります。
raggify server --mcp
デフォルトは OFF のため、永続化設定は config.yaml から。
mcp: true
LM Studio
LM Studio から使ってみます。mcp.json の記入例は以下の通りです。
{
"mcpServers": {
"my_mcp_server": {
"url": "http://localhost:8000/mcp"
}
}
}
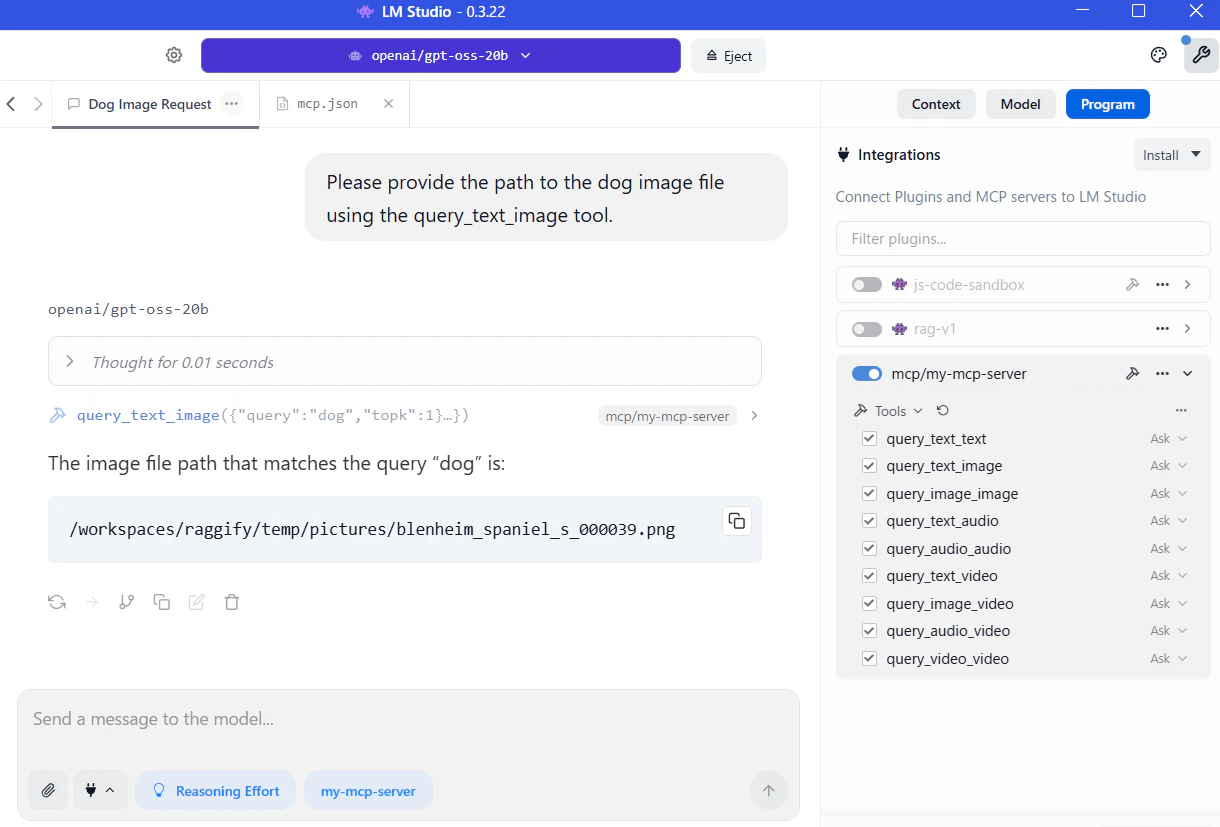
犬の画像の場所を教えてくれました。LLM の性能にもよるかもしれませんが、ツール名までちゃんと指示してやらないとツールを使わずに回答してきたりしました。
💾 永続データの管理
Chroma / ローカルディレクトリ
デフォルト設定では、ベクトルストア、ドキュメントストア、インジェストキャッシュがそれぞれローカルディレクトリへの書き出しになっていて、そのパスは ~/.local/share/raggify です。
vector_store_provider: chroma
document_store_provider: local
ingest_cache_provider: local
データを削除したい場合は、現状 rm -rf ~/.local/share/raggify でディレクトリごと削除する運用を想定しています。レコード単位での削除インタフェースを整備するかは今後検討します。
外部データベース
Pgvector / Postgres, Redis をサポートしています。ベクトルストアだけ pgvector (postgres ではなく)なので表記に注意。
vector_store_provider: pgvector # pgvector(postgres ではなく)なので注意
document_store_provider: postgres
ingest_cache_provider: postgres
vector_store_provider: redis
document_store_provider: redis
ingest_cache_provider: redis
データベースの初期化とリセット用にそれぞれ examples/init_pgdh.sh と examples/init_redis.sh を用意しています。詳細は README を参照下さい。こちらも全件削除が前提です。
🛠️ 各種設定値等
こちらも README 参照お願いします。
設定のサンプルも載せていますが、私が一番使うプロバイダの組み合わせは以下です。極力ローカルで、動画だけは bedrock、という感じで。たまに検索精度が怪しい時に、検証用に OpenAI や Cohere, Voyage を動員しています。
vector_store_provider: chroma
document_store_provider: redis
ingest_cache_provider: redis
text_embed_provider: huggingface
image_embed_provider: clip
audio_embed_provider: clap
video_embed_provider: bedrock
rerank_provider: flagembedding
device: cuda
おわりに
一個人が自作のライブラリを自分の記事で紹介して完全に自己満でしかないですが、もしここまで読んで下さった方がいらっしゃれば感謝感謝です...!
Raggify の前身の multimodal_ragserver には実はさらに前身がいたので、トータル3、4か月は embedding 沼にハマっていることになります。いやぁ、面白いです。
今後は突貫工事で追加した動画モダリティ周りのデバッグをしつつ、実際に Raggify を使った RAG システム(デモアプリではなく)の実装もやってみたいです。ドキュメントのバージョン管理とか LLM のチューニングとか、それぞれに高い山がありますからね。地道に勉強していきたいです。それでは今回はこの辺りで失礼いたします。
参考