1.はじめに
ニューラルネットワークの画像識別については、通常どこまで精度が上げられるかが注目されますが、私は天邪鬼なので、精度をちょっぴり落としたら、どれだけ重みパラメータが減らせるかに注目してみます。
ニューラルネットワークは精度の最後1〜2%を上げるために、リソースの大半が使われることが多いと思うので、精度を1〜2%程度犠牲にしただけでも、結構重みパラメーターを減らせるはずです。
今回実験に使うモデルは、kerasのチュートリアルに載っている、MNIST(0〜9の手書き数字)を識別する**MLP(多層パーセプトロン)とCNN(畳み込みネットワーク)**を使います。この2つのモデルの精度は98〜99%くらいなので、目標精度は97%台として、重みパラメータをどれだけ減らすことが出来るかを試してみます。
2.MLP(多層パーセプトロン)
これが、kerasチュートリアルに載っている、MLPの基本構造です(実際は、これに Dropout が2つ追加してありますが、単純化するために省略してあります)。
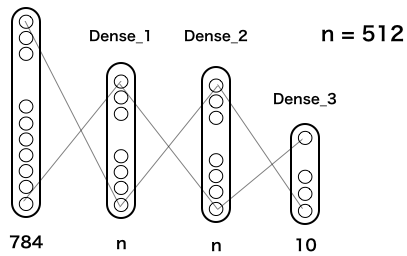
MNISTは2828ピクセルなので、入力は2828=784個。隠れ層は2層でいずれも n = 512個で全結合されています。
この n を順次小さくしたら精度はどうなって行くのかをまず確認してみましょう。次のコードを実行します(実行時間は、google colab のGPUで3分半程度)。
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
batch_size = 128
num_classes = 10
epochs = 20
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# multi Perceptoron_1
def mlp(n):
model = Sequential()
model.add(Dense(n, activation='relu', input_shape=(784,)))
model.add(Dense(n, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
#model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=0,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
return score[1]
# test
list_n = [512, 256, 128, 64, 32, 16]
x, y = [], []
for n in list_n:
params = n*n + 796*n + 10
acc = mlp(n)
x.append(params)
y.append(acc)
print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc)
# graph
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.xscale('log')
plt.show()
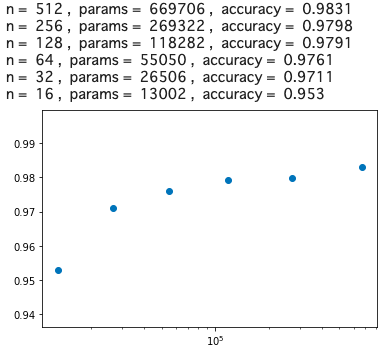
グラフの横軸は重みパラメータ数(log)、縦軸は精度です。精度97%を確保しようとすると、n = 32, params = 26506, accuracy = 0.9711 が分岐点でしょうか。
そうすると、精度を若干犠牲にすることによって、669706/26506 = 25.26 なのでベースモデルの約1/25まで、重みパラメータを減らせるわけです。
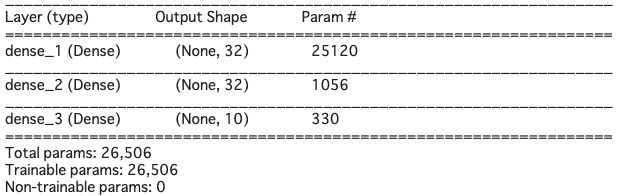
model.summary() でモデルの概要を見てみると(先頭の#を取って実行すると表示されます)、こんな感じ
これ以上重みパラメータを減らすことは無理でしょうか。いえ、まだ別の手があります。
重みパラメータを一番消費するところはどこでしょうか。入力784個とdense_1のところで、(784+1)*32=25120 と全体の重みパラメータの95%はここで消費されているわけです。ちなみに、784+1となるのは、バイアス分が1あるからです。
数字の解像度が悪くても、ある程度は識別出来るだろうと仮説を立て、2828=784個の入力をフイルター(Max Pooling)を使って、1/4の1414=196個にするモデルを考えます。
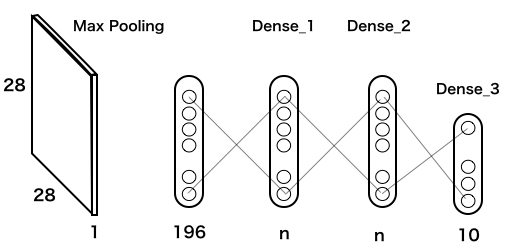
このモデルのコードを実行します(実行時間は、google colab のGPUで3分半程度)。
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.layers import MaxPooling2D, Flatten # 追加
batch_size = 128
num_classes = 10
epochs = 20
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 28, 28, 1) # 変更
x_test = x_test.reshape(10000, 28, 28, 1) # 変更
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# multi Perceptoron_2
def mlp(n):
model = Sequential()
model.add(MaxPooling2D(pool_size=(2, 2),input_shape=(28, 28, 1))) # 画像を14*14に縮小
model.add(Flatten()) # 全結合にする
model.add(Dense(n, activation='relu'))
model.add(Dense(n, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
#model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=0,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
return score[1]
# test
list_n = [512, 256, 128, 64, 32, 16]
x, y = [], []
for n in list_n:
params = n*n + 208*n + 10 # モデル変更
acc = mlp(n)
x.append(params)
y.append(acc)
print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc)
# graph
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.xscale('log')
plt.show()
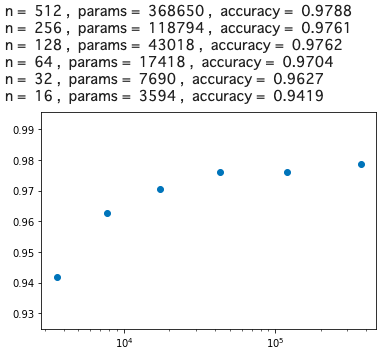
全体的に、若干精度の悪い方へスライドしましたが、n = 64, params = 17418, accuracy = 0.9704 が分岐点になりました。
そうすると、精度を若干犠牲にすることによって、669706/17418=38.44 ということで、ベースモデルの約1/38まで重みパラメータを減らすことが出来ることが分かりました。結構減らせるものですね。
3.CNNの驚くべき結果
これが、kerasチュートリアルに載っている、CNNの基本構造です(実際は、これに Dropout が2つ追加してありますが、単純化するために省略してあります)。
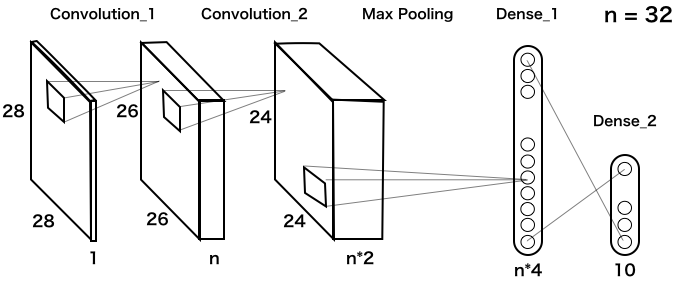
2つある畳み込み層は、33=9のフィルターを使っています。その後、Max Poolingで縦横それぞれ1/2に縮小し、n4の全結合層に繋げています。
では、nを変化させた時の重みパラメータの数と精度を見てみましょう。次のコードを実行します(実行時間は、google colab のGPUで3分半程度)。
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
img_rows, img_cols = 28, 28
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# CNN_1
def cnn(n):
model = Sequential()
model.add(Conv2D(n, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(n*2, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(n*4, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
#model.summary()
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=0,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
return score[1]
# test
list_n = [32, 16, 8, 4, 2, 1]
x, y = [], []
for n in list_n:
params = 1170*n*n + 56*n + 10
acc = cnn(n)
x.append(params)
y.append(acc)
print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc)
# graph
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.xscale('log')
plt.show()
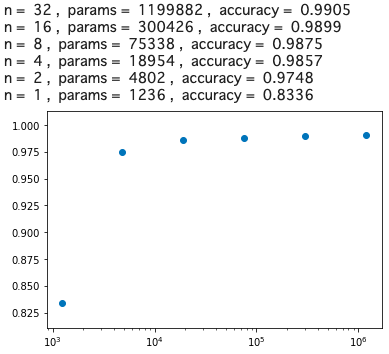
これは凄い! 分岐点は、n = 2, params = 4802, accuracy = 0.9748 です。
そうすると、精度を若干犠牲にすることによって、1199882/4802=249.8 なのでベースモデルの約1/250まで重みパラメータの数を減らすことが出来たわけです。
さて、先程同様、model.summary()でモデルの概要を見てみると、

MLPとは逆で、入力と畳み込みの部分はパラメータの数は少ないです。畳み込み層のパラメータは、3*3=9個のフィルターが共通で使われるので、重みパラメータが少なくなります。
その代わりに、最終の畳み込み層から全結合に入るところが、(12124+1)*8=4616 で、全体の重みパラメータの96%を占めています。ここを何とか出来ないか。
畳み込み層は、ほとんど重みパラメータを消費しないので、Max Poolingの後に再度畳み込み層を2つ入れて、さらにMax Poolingを掛けたらどうかというのが、以下のモデルです。
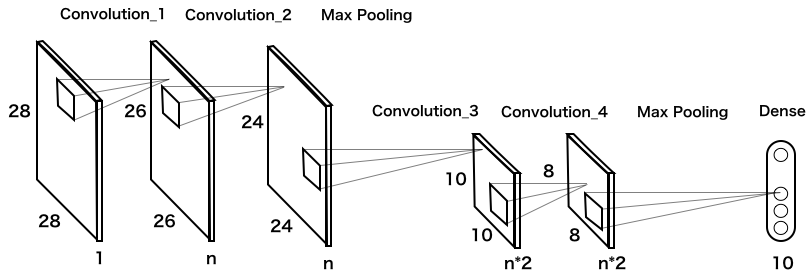
では、このモデルのコードを実行します(実行時間は、google colab のGPUで3分半程度)。
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
img_rows, img_cols = 28, 28
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# CNN_2
def cnn(n):
model = Sequential()
model.add(Conv2D(n, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(n, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(n*2, (3, 3), activation='relu'))
model.add(Conv2D(n*2, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))
#model.summary()
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=0,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
return score[1]
# test
list_n = [32, 16, 8, 4, 2, 1]
x, y = [], []
for n in list_n:
params = 63*n*n + 335*n + 10
acc = cnn(n)
x.append(params)
y.append(acc)
print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc)
# graph
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.xscale('log')
plt.show()
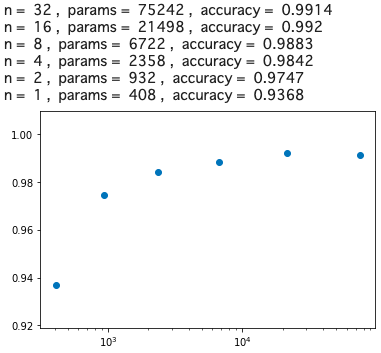
驚いたことに、重みパラメータ数がたった932個で、精度97%が確保出来ました。この重みパラメータ数は、ベースモデルのなんと1/1000以下です!
そして、MLPの17418個と比べると、17418/932=18.68 で、MLPの約1/18の重みパラメータで同等の精度が得られることが分かりました。
画像認識においては、CNNの畳み込み層が極めて有効に働くことが大変良く分かる結果ですね。CNN、恐るべしです!