1.はじめに
**「PyTorchによる発展的ディープラーニング」**を読んでいます。今回は、8章のBERTを勉強したので自分なりのまとめをアウトプットしたいと思います。
2.BERTとは?
Transformer が発表された翌年の2018年に、とうとう自然言語処理分野でも人間を超える精度を持ったBERTが発表されました。
BERTは、あらゆる自然言語処理タスクにファインチューニングで対応でき、なんと11種類のタスクにおいて圧倒的なSoTAを達成したのです。
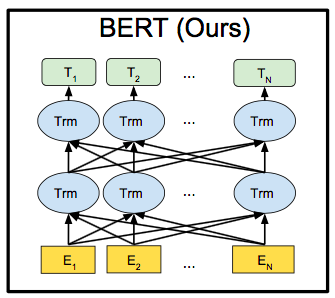
これが論文に載っているBERTのモデル図です。単語の長さ方向に展開してあるので複雑に見えますが、簡単に言えばTransformerのEncoder部分のみを取り出したものです。では、BERTとTransformerの違いは何処にあるのでしょうか。それは、2種類のタスクによる事前学習と目的のタスクに合わせたファインチューニングの2段階学習を行うことです。
1) 2種類のタスクによる事前学習
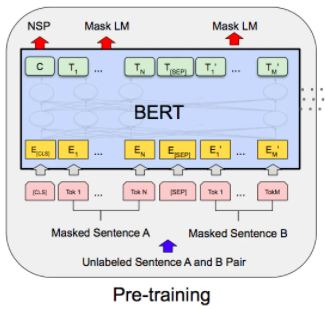
センテンスの15%の単語にマスクをしてその単語を当てるタスク(Masked Language Model)と2つの文の文脈が繋がっているのかどうかを判定するタスク(Next Sentence Prediction)を同時に学習します。
入力するセンテンスの先頭には**[CLS]を入れ、2つの文には1つ目か2つ目を表す埋め込み表現を加算すると共に間に[SEP]**を入れます。
この2つのタスクを学習することによって、単語を文脈に応じて特徴ベクトルに変換できる能力や文が意味的に繋がってるかどうか判定できる能力(おおまかに文の意味を理解する能力)を獲得します。
この地頭を鍛えるような事前学習にはかなり計算コストがかかり、TPUを4つ使っても4日間くらい掛かるらしいですが、誰かが1回やれば後はファインチューニングで様々なタスクが解けるネットワークに変身できるわけです。
2) ファインチューニング
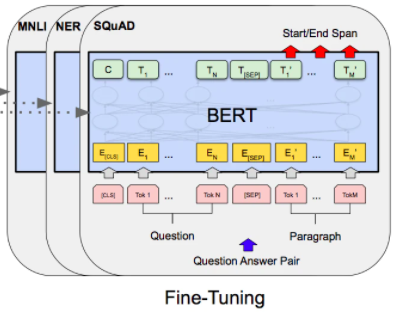
事前学習の重みを初期値として、ラベルありデータでファインチューニングを行います。
事前学習によって地頭が相当鍛えられているので、少ない文章データから性能の良いモデルが作成可能です。論文では、様々なタスクのファインチューニングの計算コストは、TPU1つで1時間以内で終わったということです。
以下は、BERTがSoTAを記録した11個のNLPタスクです。
| データセット | タイプ | 概要 |
|---|---|---|
| MNLI | 推論 | 前提文と仮説文が含意/矛盾/中立のいずれか判定 |
| QQP | 類似判定 | 前提文と仮説文が含意/矛盾/中立のいずれか判定 |
| QNLI | 推論 | 文と質問のペアが渡され、文に答えが含まれるか否かを判定 |
| SST-2 | 1文分類 | 文のポジ/ネガの感情分析 |
| CoLA | 1文分類 | 文が文法的に正しいか否かを判別 |
| STS-B | 類似判定 | 2文が意味的にどれだけ類似しているかをスコア1~5で判別 |
| MRPC | 類似判定 | 2文が意味的に同じか否かを判別 |
| RTE | 推論 | 2文が含意しているか否かを判定 |
| SQuAD v1.1 | 推論 | 質問文と答えを含む文章で、答えがどこにあるか予測 |
| SQuAD v2.0 | 推論 | v1.1に答えが存在しないという選択肢を加えたもの |
| SWAG | 推論 | 与えられた文に続く文を4択から選ぶ |
3) その他の違い
・Transformerでは単語の位置情報をPositonal Encoderではsin,cosからなる値を与えていましたが、BERTでは学習させます。
・活性化関数の一部にReLUではなく、GELU(入力0のあたりの出力がカクっとせず、滑らかになっている)を使っています。
3.今回実装するモデル
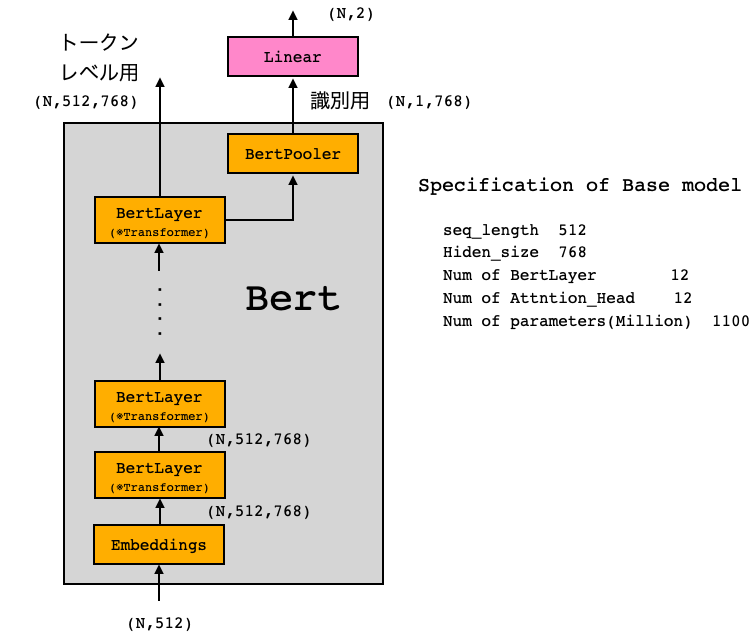
今回は、BERTの事前学習済みモデルを使って、文章のネガポジ判定をするタスクのファインチューンニングを行います。BERTモデルにはモデルサイズの異なる2つのタイプがあり、今回使うのはBaseと呼ばれる小さい方のモデルです。
BERTの出力は識別用とトークンレベル用の2つあり、今回は識別用に全結合層を接続しネガポジ判定を行います。使用するデータセットは、映画のレビュー(英文)の内容がポジティブなのかネガティブなのかをまとめたIMDb(Internet Movie Dataset)です。
モデルを学習させることによって、ある映画のレビューを入力したら、そのレビューがポジティブなのかネガティブなのかを判定し、レビューの単語の相互Attentionから判定の根拠にした単語を明示させるようにします。
4. モデルのコード
from bert import get_config, BertModel, set_learned_params
# モデル設定のJOSNファイルをオブジェクト変数として読み込みます
config = get_config(file_path="./data/bert_config.json")
# BERTモデルを作成します
net_bert = BertModel(config)
# BERTモデルに学習済みパラメータセットします
net_bert = set_learned_params(
net_bert, weights_path="./data/pytorch_model.bin")
BERTモデルを作成し、事前学習済みの重みパラメータをセットします。
class BertForIMDb(nn.Module):
'''BERTモデルにIMDbのポジ・ネガを判定する部分をつなげたモデル'''
def __init__(self, net_bert):
super(BertForIMDb, self).__init__()
# BERTモジュール
self.bert = net_bert # BERTモデル
# headにポジネガ予測を追加
# 入力はBERTの出力特徴量の次元、出力はポジ・ネガの2つ
self.cls = nn.Linear(in_features=768, out_features=2)
# 重み初期化処理
nn.init.normal_(self.cls.weight, std=0.02)
nn.init.normal_(self.cls.bias, 0)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=False, attention_show_flg=False):
'''
input_ids: [batch_size, sequence_length]の文章の単語IDの羅列
token_type_ids: [batch_size, sequence_length]の、各単語が1文目なのか、2文目なのかを示すid
attention_mask:Transformerのマスクと同じ働きのマスキングです
output_all_encoded_layers:最終出力に12段のTransformerの全部をリストで返すか、最後だけかを指定
attention_show_flg:Self-Attentionの重みを返すかのフラグ
'''
# BERTの基本モデル部分の順伝搬
# 順伝搬させる
if attention_show_flg == True:
'''attention_showのときは、attention_probsもリターンする'''
encoded_layers, pooled_output, attention_probs = self.bert(
input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg)
elif attention_show_flg == False:
encoded_layers, pooled_output = self.bert(
input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg)
# 入力文章の1単語目[CLS]の特徴量を使用して、ポジ・ネガを分類します
vec_0 = encoded_layers[:, 0, :]
vec_0 = vec_0.view(-1, 768) # sizeを[batch_size, hidden_sizeに変換
out = self.cls(vec_0)
# attention_showのときは、attention_probs(1番最後の)もリターンする
if attention_show_flg == True:
return out, attention_probs
elif attention_show_flg == False:
return out
BERTモデルにIMDbのネガ・ポジを判定するLinearをつなげたモデルです。重みパラメータの更新は、BertLayerの全部の層で行うとヘビーなので、BertLayerの最終層(12層目)と追加したLinearのみで行います。
5.コード全体と実行
コード全体は Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
コードを実行するとたった2epochの学習ですが、テストデータの正解率は約90%でした。前回、Transfomerでも同じタスクをやったのですが、その時の正解率が約85%でしたので、+5ポイントの改善になっています。
さて、判定根拠の明示ですが、

こんな感じで、どの単語を判定根拠にしたかを明示します。
(参考)
・つくりながら学ぶ! PyTorchによる発展ディープラーニング
・自然言語処理の王様「BERT」の論文を徹底解説