1.はじめに
**「PyTorchによる発展的ディープラーニング」**を読んでいます。今回は、7章のTransformerを勉強したので自分なりのまとめをアウトプットしたいと思います。
2.Transformerとは?
2017年自然言語処理の分野でエポックメイキングな論文**「Attention All You Need」**が発表されました。そこで提案されたモデルが Transformer で、翻訳タスクにおいて今まで主流であったRNNを一切使わずに、Attention のみでSoTAを達成しました。
以後、自然言語処理分野では BERT、XLNet、ALBERT など、この Transformer をベースにしたモデルが席巻し、自然言語処理なら Transformer と言われるようになりました。
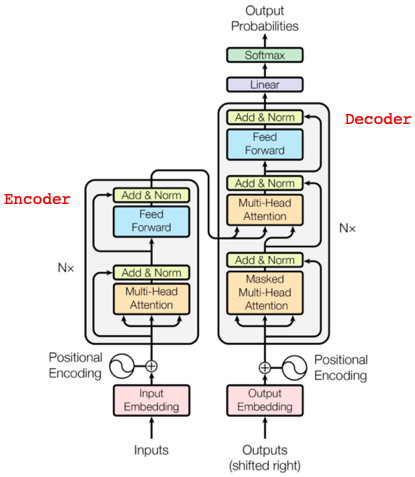
これが、翻訳タスクを行うTransformerのモデル図です。例えば日英翻訳を考えると、左側のEncoderで日文の各単語のAttentionを学習し、その情報を参照しつつ右側のDecoderで英文の各単語のAttentionを学習するわけです。それでは、特徴を5つ説明します。
1) Psitional Encoding
Transformer最大の狙いは、RNNのように単語を1つづつ処理するのではなく、センテンス毎に単語を全て並列処理することで、GPUを活用し処理速度の大幅アップを図ることです。そのために、Positional Encodingで各単語に単語順の情報を付加し、並列処理によって単語順の情報が失われることを防いでいます。
2) Scaled dot-product Attention
これが Transformer の肝なので、少し丁寧に説明します。Attentionの計算には、Query(Attentionを計算したい単語ベクトル)、Key(関連度の計算に使う単語ベクトルの集まり)、Value(重み付け和計算に使うベクトルの集まり)の3つが登場します。
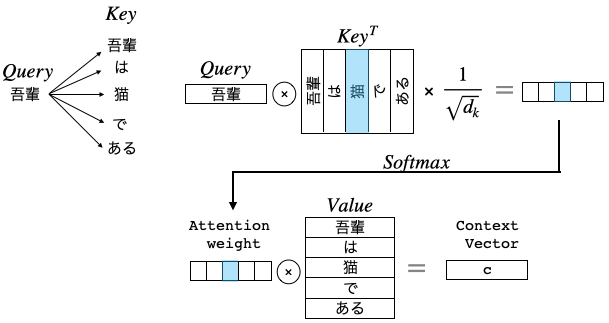
センテンスが「吾輩」、「は」、「猫」、「で」、「ある」と5つの単語で構成されているときに、「吾輩」のAttentionをどう計算するかを説明します。
関連度はベクトルの内積で計算できるので、「吾輩」ベクトルQueryと5つの単語ベクトルの転置行列**$Key^T$**の内積を取ります。そして、${\sqrt{d_k}}$で割ってからSoftmaxを掛けることで、「吾輩」にどの単語がどの程度関連しているかを表す重み(Attention Weight)を求めます。
${\sqrt{d_k}}$で割る理由は、内積計算で大き過ぎる値があるとSoftmaxを掛けたとき、それ以外の値が0になってしまう恐れがあるためです。
次に、Attention Weight と5つの単語ベクトルの行列Valueを内積することで、「吾輩」に関連度の深い単語のベクトル成分が支配的なContext Vectorが計算できます。これが「吾輩」のAttentionの計算です。
さて、Transformer は並列計算が可能で、全てのQueryに対して一気に計算が出来るので、
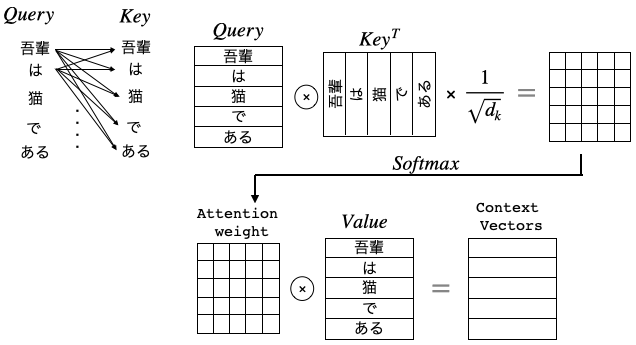
このように全てのQueryのAttention計算が一発で完了します。この計算が論文では下記の式で表されています。
Attention(Q, K, V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
3) Multi-Head Attention
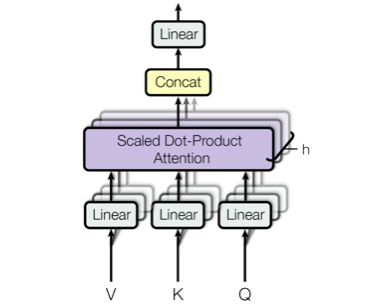
Scaled dot-product Attentionへの入力 Query, Key, Value は、前段の出力がそれぞれの全結合層を経由して入って来る構造になっています。つまり、前段の出力にそれぞれ重み$W_q,W_k,W_v$を掛けたものです。
このとき、大きな Query, Key, Valueのセット(ヘッドと言います)を1つ持たせるよりも、小さな Query, Key, Valueのヘッドを複数個持たせ、それぞれのヘッドが潜在表現$W_q,W_k,W_v$を計算し最後に1つにした方がパフォーマンスが上がるというのが Multi-Head Attentionです。
4) Musked Multi-Head Attention
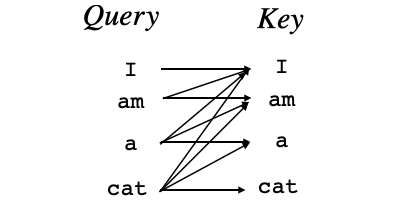
Decoder側のAttentionも並列計算するわけですが、「I」のAtentionを計算するとき、「am」、「a」、「cat」を計算対象に入れると、予測すべき単語をカンニングすることになるので、Keyにある先の単語は見えなくするためにマスクを掛けます。この機能を加えた Multi-Head Attention を、Musked Multi-Head Attention と呼びます。
5) Position-wise Feed-Forward Networks
これは、Attention層からの出力を2層の全結合層で特徴量を変換するユニットです。入力が(単語数,単語埋め込み次元数)、これに2つの全結合層の重みとの内積をとったものが出力(単語数,単語埋め込み次元数)となります。各単語毎に独立したニューラルネットワークがある様な形になるので、Position-wise という名前を付けています。
3.今回実装するモデル
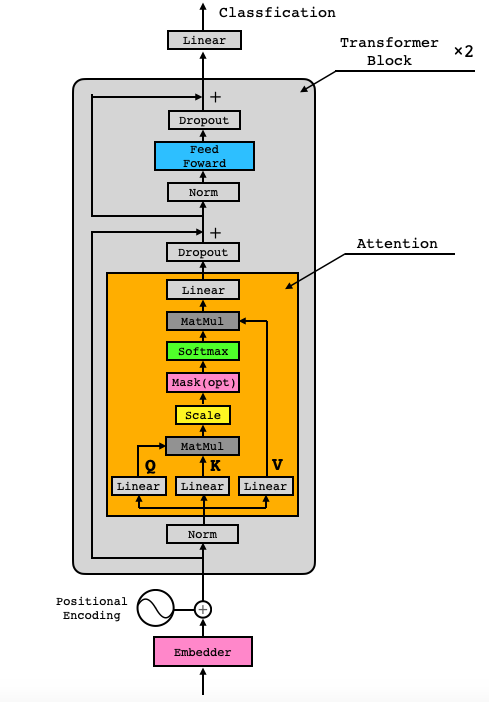
今回は、Transformer翻訳モデルの左側のEncoderだけを使って、センテンスの各単語のAttentionを学習することで分類タスクを解かせるモデルを実装します。なお、分かりやすさを優先し、Multi-Head Attention ではなく、Single-Head Attention です。
使用するデータセットは、映画のレビュー(英文)の内容がポジティブなのかネガティブなのかをまとめたIMDb(Internet Movie Dataset)です。
モデルを学習させることによって、ある映画のレビューを入力したら、そのレビューがポジティブなのかネガティブなのかを判定し、レビューの単語の相互Attentionから判定の根拠にした単語を明示させるようにします。
それでは、入力から順番に実装して行きたいと思います。
4.モデルのコード
class Embedder(nn.Module):
'''idで示されている単語をベクトルに変換します'''
def __init__(self, text_embedding_vectors):
super(Embedder, self).__init__()
self.embeddings = nn.Embedding.from_pretrained(
embeddings=text_embedding_vectors, freeze=True)
# freeze=Trueによりバックプロパゲーションで更新されず変化しなくなります
def forward(self, x):
x_vec = self.embeddings(x)
return x_vec
Pytorchのnn.Embeddingユニットを使って、単語IDを埋め込みベクトルに変換する部分です。
class PositionalEncoder(nn.Module):
'''入力された単語の位置を示すベクトル情報を付加する'''
def __init__(self, d_model=300, max_seq_len=256):
super().__init__()
self.d_model = d_model # 単語ベクトルの次元数
# 単語の順番(pos)と埋め込みベクトルの次元の位置(i)によって一意に定まる値の表をpeとして作成
pe = torch.zeros(max_seq_len, d_model)
# GPUが使える場合はGPUへ送る
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
pe = pe.to(device)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * i)/d_model)))
# 表peの先頭に、ミニバッチ次元となる次元を足す
self.pe = pe.unsqueeze(0)
# 勾配を計算しないようにする
self.pe.requires_grad = False
def forward(self, x):
# 入力xとPositonal Encodingを足し算する
# xがpeよりも小さいので、大きくする
ret = math.sqrt(self.d_model)*x + self.pe
return ret
Positional Encoderの部分です。
class Attention(nn.Module):
'''Transformerは本当はマルチヘッドAttentionですが、
分かりやすさを優先しシングルAttentionで実装します'''
def __init__(self, d_model=300):
super().__init__()
# SAGANでは1dConvを使用したが、今回は全結合層で特徴量を変換する
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
# 出力時に使用する全結合層
self.out = nn.Linear(d_model, d_model)
# Attentionの大きさ調整の変数
self.d_k = d_model
def forward(self, q, k, v, mask):
# 全結合層で特徴量を変換
k = self.k_linear(k)
q = self.q_linear(q)
v = self.v_linear(v)
# Attentionの値を計算する
# 各値を足し算すると大きくなりすぎるので、root(d_k)で割って調整
weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.d_k)
# ここでmaskを計算
mask = mask.unsqueeze(1)
weights = weights.masked_fill(mask == 0, -1e9)
# softmaxで規格化をする
normlized_weights = F.softmax(weights, dim=-1)
# AttentionをValueとかけ算
output = torch.matmul(normlized_weights, v)
# 全結合層で特徴量を変換
output = self.out(output)
return output, normlized_weights
Attentionの部分です。ここでの mask計算は、テキストデータが短く<pad>を入れた箇所は、softmaxを掛けたら0になって欲しいので、該当箇所をマイナス無限大(-1e9)に置き換えています。
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=1024, dropout=0.1):
'''Attention層から出力を単純に全結合層2つで特徴量を変換するだけのユニットです'''
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.linear_1(x)
x = self.dropout(F.relu(x))
x = self.linear_2(x)
return x
Feed Forward の部分です。単純な2層の全結合層です。
class TransformerBlock(nn.Module):
def __init__(self, d_model, dropout=0.1):
super().__init__()
# LayerNormalization層
# https://pytorch.org/docs/stable/nn.html?highlight=layernorm
self.norm_1 = nn.LayerNorm(d_model)
self.norm_2 = nn.LayerNorm(d_model)
# Attention層
self.attn = Attention(d_model)
# Attentionのあとの全結合層2つ
self.ff = FeedForward(d_model)
# Dropout
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x, mask):
# 正規化とAttention
x_normlized = self.norm_1(x)
output, normlized_weights = self.attn(
x_normlized, x_normlized, x_normlized, mask)
x2 = x + self.dropout_1(output)
# 正規化と全結合層
x_normlized2 = self.norm_2(x2)
output = x2 + self.dropout_2(self.ff(x_normlized2))
return output, normlized_weights
Attention と Feed Foward を組み合わせて、Transformer Block を作る部分です。両方とも、Layer Normalization と Dropoutを掛けると共に、ResNetと同様な残渣結合を行っています。
class ClassificationHead(nn.Module):
'''Transformer_Blockの出力を使用し、最後にクラス分類させる'''
def __init__(self, d_model=300, output_dim=2):
super().__init__()
# 全結合層
self.linear = nn.Linear(d_model, output_dim) # output_dimはポジ・ネガの2つ
# 重み初期化処理
nn.init.normal_(self.linear.weight, std=0.02)
nn.init.normal_(self.linear.bias, 0)
def forward(self, x):
x0 = x[:, 0, :] # 各ミニバッチの各文の先頭の単語の特徴量(300次元)を取り出す
out = self.linear(x0)
return out
最後にネガポジ判定をする部分です。各文の先頭単語の特徴量を使用して分類し、その損失をバックプロパゲーションして学習することで、先頭単語の特徴量が自然と文章のネガ・ポジを判定する特徴量になります。
class TransformerClassification(nn.Module):
'''Transformerでクラス分類させる'''
def __init__(self, text_embedding_vectors, d_model=300, max_seq_len=256, output_dim=2):
super().__init__()
# モデル構築
self.net1 = Embedder(text_embedding_vectors)
self.net2 = PositionalEncoder(d_model=d_model, max_seq_len=max_seq_len)
self.net3_1 = TransformerBlock(d_model=d_model)
self.net3_2 = TransformerBlock(d_model=d_model)
self.net4 = ClassificationHead(output_dim=output_dim, d_model=d_model)
def forward(self, x, mask):
x1 = self.net1(x) # 単語をベクトルに
x2 = self.net2(x1) # Positon情報を足し算
x3_1, normlized_weights_1 = self.net3_1(
x2, mask) # Self-Attentionで特徴量を変換
x3_2, normlized_weights_2 = self.net3_2(
x3_1, mask) # Self-Attentionで特徴量を変換
x4 = self.net4(x3_2) # 最終出力の0単語目を使用して、分類0-1のスカラーを出力
return x4, normlized_weights_1, normlized_weights_2
今まで定義したクラスを使って、最終的にモデル全体を組み上げる部分です。
5.コード全体と実行
コード全体は Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
実行すると、

こんな形で、判定結果とその根拠を表示します。
6.日本語データセットでもやってみる。
色々Webを見ていると、chABSA-datasetという日本の上場企業の有価証券報告書から文章を取り出しネガポジ判定し判定根拠を表示する例があったので、同様に Google Colab でまとめてみました。自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
(参考)
・つくりながら学ぶ! PyTorchによる発展ディープラーニング
・ディープラーニングでネガポジ分析アプリを作ってみた(python)【前編】
・論文解説 Attention Is All You Need (Transformer)