1.はじめに
名著、**「ゼロから作るDeep Learning2」**を読んでいます。今回は7章のメモ。
コードの実行はGithubからコード全体をダウンロードし、ch07の中で jupyter notebook にて行っています。
2.文章生成
まず、6章の train_rnnlm.py で学習した重みファイル Rnnlm.pkl を読み込んで文章生成を行うコード rnnlm_gen.py を実行してみます。
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import ptb
# PTBデータセットを読み込む
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen() # モデル生成
model.load_params('../ch06/Rnnlm.pkl') # 学習済みの重みをロード
# start文字とskip文字の設定
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 文章生成
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)

なにやら、それらしい英文が生成されました。理屈は簡単で、最初の単語を決めたら次の単語の予測を行い、その予測結果を元にまた次の単語を予測するということを繰り返すというものです。ポイントは、モデル生成のところに出て来る RnnlmGen()ですので、それを見て行きます。
3.class RnnlmGen
文章生成を行うクラスをゼロから作ることも出来ますが、6章の学習の時に使った class Rnnlm に機能を追加する方が簡単です。
下記の様にコードの冒頭で、class RnnlmGen(Rnnlm): と宣言することによって、class Rnnlm にあったメソッドは全て class RnnlmGen にビルトインされることになります。これを**「継承」**と言います。
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id # 文章生成の単語idを指定
# word_ids が sample_size に達するまで続ける
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1) # 2次元配列に(ミニバッチ対応)
score = self.predict(x) # 予測結果を取得
p = softmax(score.flatten()) # ソフトマックスで確率分布を正規化
# 長さ10000、サイズ1で、pの確率分布に従ってランダムチョイス
sampled = np.random.choice(len(p), size=1, p=p)
# skip_ids がないか、サンプルした単語がskip_idsになければ
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x)) # word_idsにアペンド
return word_ids
def get_state(self):
return self.lstm_layer.h, self.lstm_layer.c
def set_state(self, state):
self.lstm_layer.set_state(*state)
ここにあるのは、class Rnnlm に追加するメソッドです。predict(x) でxの次の単語の出現度合いを予測しsoftmax で正規化すると、語彙数分の確率分布pが得られます。
sampled = np.random.choice(len(p), size=1, p=p)は0〜語彙数-1の整数から1つ、確率分布pに従って、ランダムサンプリングするということになります。
ちなみに、class Rnnlm を見ておくと、
class Rnnlm(BaseModel):
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 重みの初期化
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# レイヤの生成
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
# すべての重みと勾配をリストにまとめる
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()
こんな内容です。今回はこのクラスを「継承」しましたので、これらのメソッドは自動的に class RnnlmGen にビルトインされます。これは便利ですよね。
4.日本語データセット
私は、英語の文章生成では、うまく出来ているのかどうか実感できないので、日本語でもやってみます。但し、予測方法は単語単位ではなく文字単位とします。
今回は、青空文庫から夏目漱石の「吾輩は猫である」の**テキストファイル(ルビあり)**をダウンロードして使います。ダウンロードしたら解凍し、wagahaiwa_nekodearu.txt という名称でch07に保存します。
import sys
import re
path = './wagahaiwa_nekodearu.txt'
bindata = open(path, "rb")
lines = bindata.readlines()
for line in lines:
text = line.decode('Shift_JIS') # Shift_JISで読み込み
text = re.split(r'\r',text)[0] # 改行削除
text = text.replace('|','') # ルビ前記号削除
text = re.sub(r'《.+?》','',text) # ルビ削除
text = re.sub(r'[#.+?]','',text) # 入力者注削除
print(text)
file = open('data_neko.txt','a',encoding='utf-8').write(text) # UTF-8に変換
前処理用のコードです。実行すると、テキストファイルの形式(Shift-JIS)で読み込み、改行、ルビ、入力者注などを削除してから、UTF-8に変換し、data_neko.txt という名前で保存します。後は、エディターを使って手動で、文章の前後にある余分な部分を削除します。
次に、data_neko.txt から corpus, word_to_id, id_to_word を取得する関数 load_data() を定義します。
import numpy as np
import io
def load_data():
# file_name をUTF-8 形式で textに読み込み
file_name = './data_neko.txt'
with io.open(file_name, encoding='utf-8') as f:
text = f.read().lower()
# word_to_id, id_to_ward の作成
word_to_id, id_to_word = {}, {}
for word in text:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
# corpus の作成
corpus = np.array([word_to_id[W] for W in text])
corpus_test = corpus[300000:] # テストデータ
corpus = corpus[:300000] # 学習データ
return corpus_test, corpus, word_to_id, id_to_word
今回作成した corpus 全体は318,800語なので、300,000語より後の18,800語をcorpus_test とし、前の300,000語を corpus にしています。
5.学習
それでは、ch06で使った学習コードをGPUを使って実行します。
import sys
sys.path.append('..')
from common import config
# GPUで実行する場合は下記のコメントアウトを消去(要cupy)
# ==============================================
config.GPU = True
# ==============================================
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity, to_gpu
from dataset import ptb
from ch06.better_rnnlm import BetterRnnlm
# ハイパーパラメータの設定
batch_size = 20
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 20.0
max_epoch = 40
max_grad = 0.25
dropout = 0.5
# 学習データの読み込み
corpus_test, corpus, word_to_id, id_to_word = load_data()
corpus_val = corpus_test # 簡略化のため、valとtestは同じに
if config.GPU:
corpus = to_gpu(corpus)
corpus_val = to_gpu(corpus_val)
corpus_test = to_gpu(corpus_test)
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus_val)
print('valid perplexity: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params()
else:
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)
# テストデータでの評価
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('test perplexity: ', ppl_test)
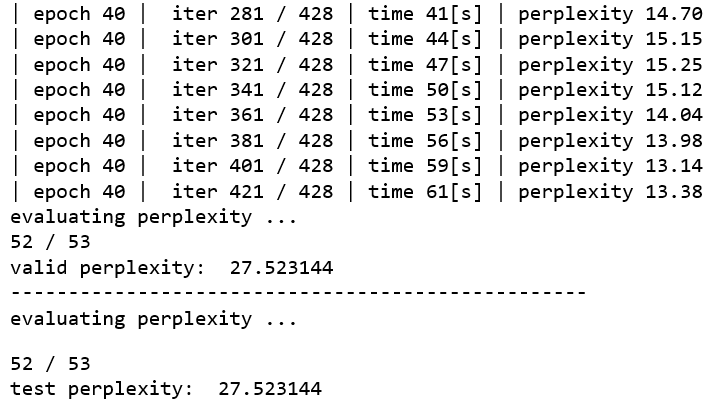
windowsマシン(GTX1060)を使って約40分で学習が完了しました。完了すると、ch07フォルダー内に学習済みの重みパラメータが BetterRnnlm.pkl という名前で保存されます。
6.class BetterRnnlmGen
次に、class BetterRnnlmGen を定義します。基本的に、6章の class BetterRnnlm を継承しますが、「吾輩は猫である」の vocab_size は PTB とは異なるので、関連する def __init___() の部分を追加して上書きします(これをオーバーライドと言います)。
import sys
sys.path.append('..')
import numpy as np
from common.functions import softmax
from ch06.rnnlm import Rnnlm
from ch06.better_rnnlm import BetterRnnlm
from common.time_layers import * # def __init__ で必要なファイルをインポート
class BetterRnnlmGen(BetterRnnlm):
def __init__(self, vocab_size=3038, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b) # weight tying!!
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x).flatten()
p = softmax(score).flatten()
sampled = np.random.choice(len(p), size=1, p=p)
#sampled = np.argmax(p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
def get_state(self):
states = []
for layer in self.lstm_layers:
states.append((layer.h, layer.c))
return states
def set_state(self, states):
for layer, state in zip(self.lstm_layers, states):
layer.set_state(*state)
7.文章生成(日本語版)
最後に、文章生成を行う下記のコードを実行します。
import sys
sys.path.append('..')
from common.np import *
corpus_test, corpus, word_to_id, id_to_word = load_data()
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = BetterRnnlmGen()
model.load_params('./BetterRnnlm.pkl')
# start文字とskip文字の設定
start_word = '吾'
start_id = word_to_id[start_word]
skip_words = ['〇']
skip_ids = [word_to_id[w] for w in skip_words]
# 文章生成(最初の1単語から)
word_ids = model.generate(start_id, skip_ids)
txt = ''.join([id_to_word[i] for i in word_ids])
print(txt)
# 文章生成(フレーズから)
model.reset_state() # モデルをリセット
start_words = '吾 輩 は 猫 で あ る 。'
start_ids = [word_to_id[w] for w in start_words.split(' ')] # 単語idに変換
# フレーズの最後の単語idの前までを予測(予測結果は使わない)
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x)
word_ids = model.generate(start_ids[-1], skip_ids) # フレーズの最後の単語idから予測を実行
word_ids = start_ids[:-1] + word_ids # フレーズと予測結果を連結
txt = ''.join([id_to_word[i] for i in word_ids]) # 文に変換
print('-' * 50)
print(txt)

文章生成のパターンは2通りあります。1つは1単語から後を予測する方法、もう1つは1フレーズから後を予測する方法です。
全体としては意味は全く分かりませんが、文節くらいでみると「なんとなく分からないでもない」という感じでしょうか。
8.足し算モデル
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
from peeky_seq2seq import PeekySeq2seq
# データセットの読み込み
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
# Reverse input? =================================================
is_reverse = False # True
if is_reverse:
# [::-1]で逆順で並べ替え、2次元なので[:, ::-1]
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
# ================================================================
# ハイパーパラメータの設定
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
# Normal or Peeky? ==============================================
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
# model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
# ================================================================
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
# グラフの描画
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()
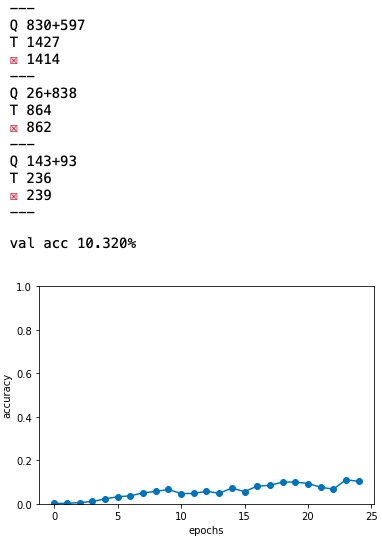
足し算を覚えさせる地味なコードです。まず、 class Seq2seq を見てみましょう。
9.class Seq2seq
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
class Encoder, class Decoder のクラスを組み合わせているだけなので、まず class Encoder を見てみます。
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
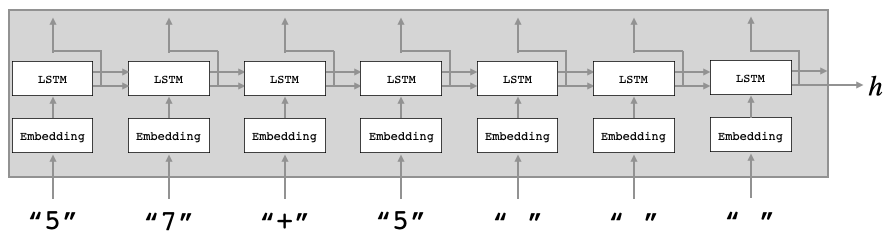
Encoder の模式図です。学習データを順次入力し、最終段のLSTMの出力hを、Decoderへ渡します。
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
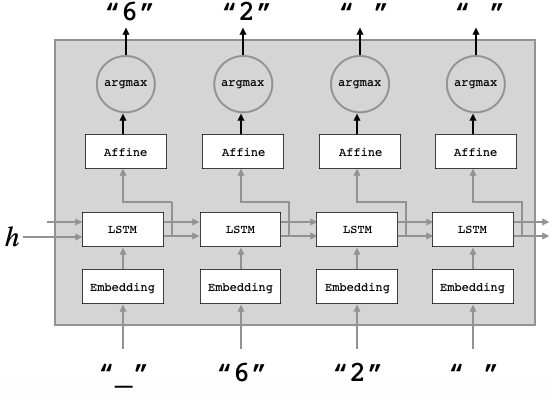
Decoder の模式図です。Decoder は、この後のSoftmax with Lossレイヤの扱いが学習時と生成時で変わるので、Softmax with LossレイヤはSeq2seqクラスで対応します。
9.入力データの反転
入力データを反転させると、学習の進みが早くなり、最終的な精度も高くなります。先程の足し算モデルのコードを、is_reverse = True で実行します。
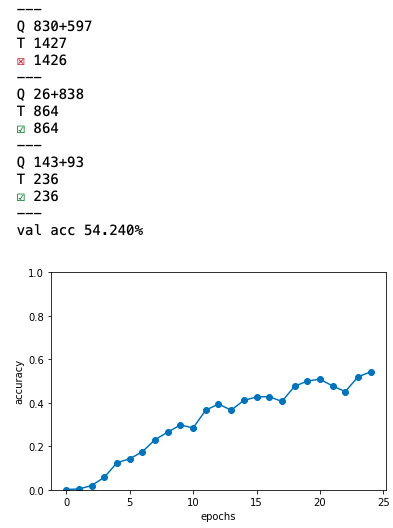
なんと反転するだけで、正答率が10%台から50%台にジャンプアップしてしまいました。各入力要素とその出力要素のタイムラグが近い方が精度が良いということです。なるほど。
10.PeekyDecoder
Encoder から出力されるベクトルh は大変重要な情報ですが、Decoderの最初の時刻にしか入力されません。そこで、ベクトルhの情報を全ての時刻のLSTMレイヤとAffineレイヤへ入力させたらどうかという発想が生まれます。この方法を**Peeky(覗き見)**と言います。class PeekyDecoder を見てみましょう。
class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H)
out = np.concatenate((hs, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2)
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, dscore):
H = self.cache
dout = self.affine.backward(dscore)
dout, dhs0 = dout[:, :, H:], dout[:, :, :H]
dout = self.lstm.backward(dout)
dembed, dhs1 = dout[:, :, H:], dout[:, :, :H]
self.embed.backward(dembed)
dhs = dhs0 + dhs1
dh = self.lstm.dh + np.sum(dhs, axis=1)
return dh
def generate(self, h, start_id, sample_size):
sampled = []
char_id = start_id
self.lstm.set_state(h)
H = h.shape[1]
peeky_h = h.reshape(1, 1, H)
for _ in range(sample_size):
x = np.array([char_id]).reshape((1, 1))
out = self.embed.forward(x)
out = np.concatenate((peeky_h, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((peeky_h, out), axis=2)
score = self.affine.forward(out)
char_id = np.argmax(score.flatten())
sampled.append(char_id)
return sampled
それでは、先程の足し算モデルのモデル生成のところで、model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size) の方を有効にして、実行します。
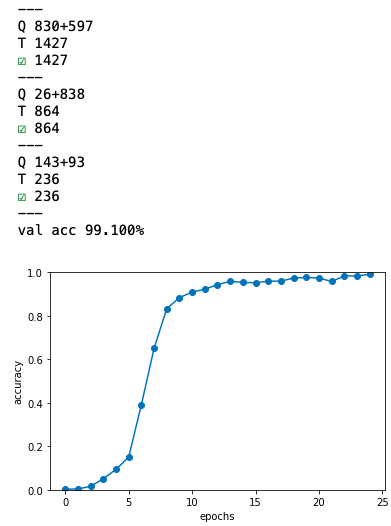
劇的な効果です!正答率は99.1%となりました。