1.はじめに
2019年に First Order Motion Model for Image Animation という論文が発表されました。内容は、同じカテゴリの静止画と動画を使って、静止画を動画のように動かすというものです。
百聞は一見にしかず、こんなことが簡単に出来ます。

左が有村架純さんの静止画、中央がトランプ大統領の動画、そして右が生成した有村架純さんがトランプ大統領のように動く動画です。
2.First Order Motion Model とは?
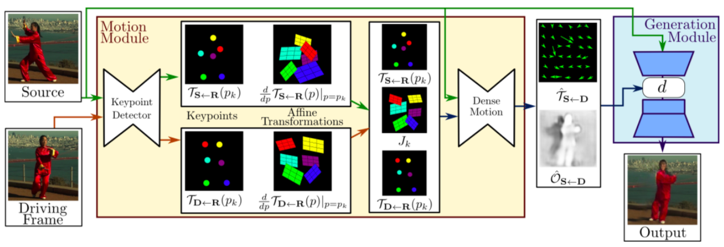
これは、モデルの概要図で、大きく分けて Motion Module と Generation Module の2つで構成されています。入力は、静止画 source と、動画 Driving Frame です。
Motion Module は、静止画と動画の各フレームそれぞれに対して、キーポイント位置(顔の場合なら目、鼻、口、顔の輪郭など)、キーポイントにおける勾配を、Refarence画像(図ではRと表示)を基準として計算します。
そして、そのキーポイント計算とヤコビアン$J_k$(静止画と動画フレームの大きさの比率)から、動画の各フレームの画素を静止画のどの画素から作れば良いかを示すマッピング関数を計算します。
この様に静止画と動画の各フレームの差を計算するのではなく、Refarence画像という概念的な基準画像との差を計算することで静止画と動画の各フレームが独立に計算出来、両者の画像の差が大きくても上手く変換ができます。
また、静止画を動かすとそもそも静止画に含まれていない部分が発生しますが、それを上手く処理するオクルージョン(Oで表示)という処理を行っています。
Generation Module は、それらの結果と静止画から、画像を出力します。損失関数は、静止画と出力画像の誤差+正則化項(マッピング関数が単純な変換に近くなるような拘束条件)です。
学習時は、静止画と動画は同一の動画から任意のフレームを選択して行います。推論時は、学習時と同じカテゴリーであれば静止画と動画とも任意のもので行えます(これがこのモデルの素晴らしいところです)。
3.学習済みの重みを使って試してみる
学習済みの重みが提供されていますので、それを使って静止画と動画から動画を生成してみましょう。事前に、コードとサンプルデータ(重み、画像、動画)をダウンロードします。
まず、google colab 上で静止画や動画を表示する関数display()を定義します。
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from skimage.transform import resize
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
def display(source, driving, generated=None):
fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6))
ims = []
for i in range(len(driving)):
cols = [source]
cols.append(driving[i])
if generated is not None:
cols.append(generated[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000)
plt.close()
return ani
引数は、静止画、動画、生成動画で、動画と生成動画は ndarray 形式です。静止画、動画、生成動画をフレーム毎に concatenate し、matplotlib の animation でアニメーション形式にしたものを返します。
4.顔のカテゴリーで試してみる
それでは顔のカテゴリーの動画を生成します。静止画・動画は、顔のキーポイント位置(目、鼻、口、顔の輪郭など)が検出できれば絵でも人形でもアニメでも構わないので、ここでは静止画はモナリザ、動画はトランプ大統領を使ってみます。
from demo import load_checkpoints
from demo import make_animation
from skimage import img_as_ubyte
source_image = imageio.imread('./sample/05.png')
driving_video = imageio.mimread('./sample/04.mp4')
# Resize image and video to 256x256
source_image = resize(source_image, (256, 256))[..., :3]
driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video]
generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml',
checkpoint_path='./sample/vox-cpk.pth.tar')
predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True)
HTML(display(source_image, driving_video, predictions).to_html5_video())

凄い! **モナリザがトランプ大統領のように動き出しました。**正に、何でもありの世界です。
このモデルには、生成動画の顔のキーポイント位置を動画の方に合わせる(つまり顔を動画の方に合わせる)というモードがあるので、そちらを試してみると、
predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=False, adapt_movement_scale=True)
HTML(display(source_image, driving_video, predictions).to_html5_video())

生成された動画は、基本的にモナリザなのですが、キーポイント位置をトランプ大統領にしているので、**「トランプ大統領似のモナリザ」**という訳がわからない世界に突入しています(笑)。
5.オリジナルの動画を作成するには
使用する動画は顔の位置が大体合っていれば何でもOKです。なので、自分で入手した動画から顔だけクロップした動画を作れば、それが使用できます。
!ffmpeg -i ./sample/07.mkv -ss 00:08:57.50 -t 00:00:08 -filter:v "crop=600:600:760:50" -async 1 hinton.mp4
ffmpeg をこのように使えば、1行でクロップ動画が作れます。引数を簡単に説明すると、
-i: 動画パス (コードは.mkvになっていますが、mp4でもOKです)
-ss: 動画のクロップスタート時刻(時間:分:秒:1/100秒)
-t: クロップ動画の長さ(時間:分:秒)
-filter:v "crop=XX:XX:XX:XX":(クロップ画像の横サイズ:クロップ画像の縦サイズ:クロップ画像の左上角の横位置:クロップ画像の左上角の縦位置)
*クロップ画像の左上角の横位置・縦位置は、動画の左上角を(0,0)として計算した位置です。
-async 1:クロップ画像保存パス
簡単に使えますので、ぜひお試しを。
6.全身のカテゴリーで試してみる
キーポイント位置が検出できれば、カテゴリーは何でもOKですので、今度は全身のカテゴリーでやってみましょう。
Fashion video dataset というファッションモデルの動きを集めたデータセットを用いて体のキーポイント位置(頭、顔、各関節など)を学習した重みを使います。
波瑠さんの静止画をファッションモデルの動画のように動かしてみます。
from demo import load_checkpoints
from demo import make_animation
from skimage import img_as_ubyte
source_image = imageio.imread('./sample/fashion003.png')
driving_video = imageio.mimread('./sample/fashion01.mp4', memtest=False)
# Resize image and video to 256x256
source_image = resize(source_image, (256, 256))[..., :3]
driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video]
generator, kp_detector = load_checkpoints(config_path='config/fashion-256.yaml',
checkpoint_path='./sample/fashion.pth.tar')
predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True)
HTML(display(source_image, driving_video, predictions).to_html5_video())

左が波瑠さんの静止画、中央がファッションモデルの動画、そして右が生成した波瑠さんがファッションモデルのように動く動画です。動きがスムーズですね。
ここまでにご紹介した内容を試せるコードを Google Colab で作成しましたので、やってみたい方はこの「リンク」をクリックして動かしてみて下さい。
(参考)
・AliaksandrSiarohin/first-order-model
・【論文読解】First Order Motion Model for Image Animation