TL;DR
- Hugging Face transformersライブラリにはLLMでFlash Attention 2を簡単に使える機能がある
- パディングが必要な場合でも特別な対応をすることなくFlash Attention 2を使えるので、簡単かつ効率的にLLMの学習が行える
Flash Attentionとパディングについて
Flash AttentionはtransformerアーキテクチャのAttentionの計算で使用するGPUメモリ量を系列長の2乗のオーダーから1乗に削減する技術です。
以前にこちらの記事
で、Flash AttentionとDeepSpeedを使えば3.6BサイズのLLMでもRAM 40GBのGPU1枚でフルファインチューニングできるということを解説しました。
その時は、optimumライブラリのbettertransformerという機能を通じてFlash Attentionを使ったのですが、データの前処理としてpackingという少し特殊なことを行っていました。
Flash Attentionにはミニバッチ内で異なるサイズのattention biasは使えないという弱点があり、異なる系列長のデータをパディングで長さを揃えて一つのミニバッチにするということができません。
そのため、事前に複数行のデータを固定の長さになるまで1行に詰め込むpackingという処理をして、パディングなしですべてのデータの系列長を揃えていました。
しかし、packingを行うともともと別のテキスト間にもアテンションが張られることになるので、packingを行わない時と学習の計算内容が異なってしまいます。1
一つ一つのテキストが十分長ければ2 packingの影響は軽微になると期待できますが、テキストが短い場合は影響が大きくなる可能性もあります。
Flash Attentionではパディングで長さを揃えられないという問題に対して、実は本家Flash Attentionのライブラリに回避策が実装されています。
それは、forward計算時にpackingに相当することを行うということです。Attentionを計算する前にミニバッチ内のすべてのデータからパディングトークンを除いた上で、すべてのデータを1行に並び変えてしまうということをします。するとバッチサイズが1になるので、ミニバッチ内で異なるサイズのattention biasは使えないという問題は回避でき、もともと別の行であったデータ間にはattention maskをかけることができます。
図で説明すると以下のようになり、非常に長いバッチサイズ1のデータに対してブロック対角のattention maskをかけるということになります。(Causal LMではそれに加えてcausal maskもかけます。)



Attention maskにより、もともと別の行だったデータ間にはattentionが張られないので、計算内容は通常の計算と同じになるということが保証されます。
通常のattentionの計算だと、ミニバッチ内のすべてのデータを横に並べるなんてことをしたら計算量が系列長の2乗で増えるので手に負えなくなりますが、Flash Attentionであれば1乗でしか増えないので、データをバッチの次元の方向に並べても系列長の方向に並べても計算量はほとんど変わらないということになります。
コード内ではaccumulateという言葉が使われていたので、以下ではこの手法のことをaccumulationと呼ぶこととします。(データを系列長方向に積み重ねる(accumulate)というイメージです。)
さて、accumulationの機能を使うためには基本的にはFlash Attentionのライブラリを使ってモデルのattention部分を自分で書き換える必要があるのですが、最近ではtransformersライブラリの各種言語モデルのコードにもFlash Attention 2が実装されており、accumulationも自動で行われる仕様になっています。
transformersライブラリのLLMでFlash Attention 2を使う方法は非常に簡単で、AutoModelForCausalLM.from_pretrained()の引数にattn_implementation="flash_attention_2"を与えるだけです。(use_flash_attention_2=Trueでもよいですが、こちらの引数は今後廃止されるそうです。)
すべての言語モデルでFlash Attention 2が使えるわけではありませんが、記事執筆時点でLlamaとGPT-NeoXには実装されていますので、多くのオープンソース日本語LLMで使うことができると思います。
ただし、この方法にはデメリットもあります。
それは、本家Flash Attention 2はAmpereかそれより新しいアーキテクチャのGPUしかサポートしていないので、Google colabではT4とV100 GPUでは動作しません。3(READMEにTuring GPUsもそのうちサポートするとは書いてあります。)
optimumライブラリのbettertransformerであれば、T4とV100 GPUでも動作するので、手法によって一長一短があります。
環境
実験はGoogle Colab (Pro)上でA100GPU (Syetem RAM 83.5GB, GPU RAM 40.0GB)を使用して行いました。
ライブラリのインストール
transformersのバージョンは実験時に利用可能な最新版を指定しました。
!pip install -U transformers==4.36.2
!pip install datasets accelerate bitsandbytes sentencepiece
!pip install deepspeed ninja
!pip install flash-attn --no-build-isolation
Pythonおよび主要ライブラリのバージョン
Python 3.10.12
accelerate 0.26.1
bitsandbytes 0.42.0
datasets 2.16.1
deepspeed 0.12.6
flash-attn 2.4.2
ninja 1.11.1.1
sentencepiece 0.1.99
torch 2.1.0+cu121
transformers 4.36.2
データセット準備
データセットは過去の実験と同じくdatabricks-dolly-15k-jaを使用します。
Flash Attention 2を使って簡単にLLMのファインチューニングを行えることを確かめるのが目的なので、特にデータセットに対して工夫はしません。
from datasets import load_from_disk
dataset = load_dataset("kunishou/databricks-dolly-15k-ja", split="train")
print(len(dataset)) # -> 15015
LINEのjapanese-large-lm-3.6bモデルを使用するので、対応したトークナイザを読み込みます。
import torch
from transformers import AutoTokenizer
model_name = "line-corporation/japanese-large-lm-3.6b"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
プロンプトのテンプレートを用意して、datasetに適用してからトークナイズします。
def format_prompt(sample):
instruction = f"### Instruction\n{sample['instruction']}"
input = f"### Context\n{sample['input']}" if len(sample["input"]) > 0 else None
output = f"### Answer\n{sample['output']}"
# join all the parts together
prompt = "\n\n".join([i for i in [instruction, input, output] if i is not None])
return prompt
# template dataset to add prompt to each sample
def template_dataset(sample):
sample["text"] = f"{format_prompt(sample)}{tokenizer.eos_token}"
return sample
# apply prompt template per sample
dataset = dataset.map(template_dataset, remove_columns=list(dataset.features))
# tokenize
dataset = dataset.map(
lambda sample: tokenizer(sample["text"]), batched=True, remove_columns=list(dataset.features)
)
データの系列長の分布を調べると以下のようになっています。
import numpy as np
seq_lengths = [len(sample["input_ids"]) for sample in tokenized_dataset]
print(f"mean: {np.mean(seq_lengths)}")
print(f"median: {np.median(seq_lengths)}")
print(f"min: {np.min(seq_lengths)}")
print(f"max: {np.max(seq_lengths)}")
mean: 191.94452214452215
median: 114.0
min: 18
max: 9398
以前の方法では、Flash Attentionを使用するために、事前にデータを固定長まで詰め込むpackingを行ってすべてのデータ行の系列長を揃える必要があったのですが、今回はaccumulationを行うのでその必要はありません。
ただし、系列長がバラバラすぎるとミニバッチによって必要なGPUメモリの変動が大きくなりOOMが起きやすくなるので、系列長が閾値を超えるデータ行は捨てることとします。
今回の実験では閾値は256としました。
max_length = 256
dataset = tokenized_dataset.filter(lambda sample: len(sample["input_ids"]) <= max_length)
print(len(dataset)) # -> 11874
学習
学習対象のモデルを読み込みます。
上で説明したようにfrom_pretrained()に引数attn_implementation="flash_attention_2"を渡すだけでFlash Attention 2が使用できます。
Flash Attention 2を使用する際にはモデルの重みはfloat16かbfloat16である必要があります。
import torch
from transformers import AutoTokenizer
model_name = "line-corporation/japanese-large-lm-3.6b"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
attn_implementation="flash_attention_2",
device_map="cuda",
)
optimumライブラリを通じてFlash Attentionを使う場合はmodel.to_bettertransformer()のようにモデルを変換する必要がありましたが、それも必要ありません。
Flash Attention 2を使用していても、通常のモデルと同様に扱えます。
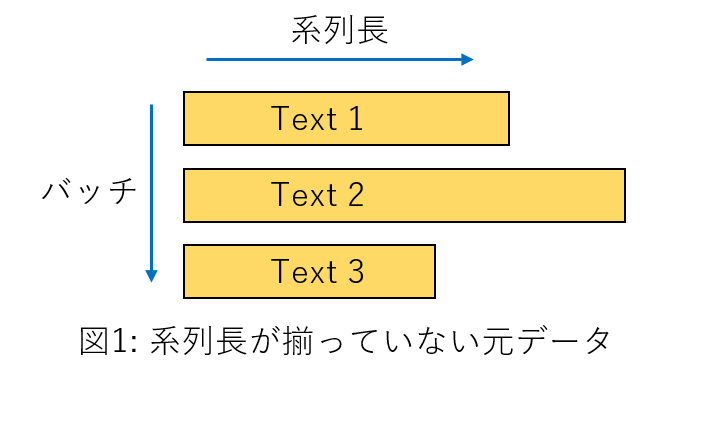
さて、用意したdatasetは行ごとに系列長が異なるので、ミニバッチとして扱うためには一度パディングをして図2のように長さを揃えてやる必要があります。
そのためのcollatorを準備します。
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
モデルに入力される時点では、ミニバッチ内の一番長いデータに合わせてパディングが行われるのですが、モデル内部でパディングトークンは取り除かれて、図3のようにミニバッチ内のすべてのデータが1行に結合されるという処理(accumulation)が走ることとなります。
この処理は内部的に行われるので、我々は全く気にせずに昔ながらのパディングをして入力する言語モデルの学習を行えばよいということになります。
(本当にaccumulationが行われているか確信を持てなかったので、モデルコードをローカルに持ってきて内部のテンソルのshapeをprintしてみましたが、確かにパディングを除く全データが結合されていました。)
ということで、あとはHugging FaceのTrainerを用いて簡単に学習を実行できます。
GPU1枚でフルファインチューニングを行うためにDeepSpeedを使いますので、環境変数を設定します。
import os
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994"
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
さらにDeepSpeedの設定を書いたjsonファイルを出力します。(長いので折り畳んでおきます。)
%%writefile zero_train.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 1e9,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 1e9,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto"
}
allgather_bucket_sizeとreduce_bucket_sizeの値を以前の記事の時より小さくしています。系統的に調べたわけではないですが、この値の方が若干学習が速かったです。
これで準備が整ったので、Trainerを使って学習を実行します。
今回もハイパラの設定は適当ですが、1ステップ当たりのトークン数は以前の実験の系列長2,048にpackingを行っていたときとほぼ同じになるように、実効バッチサイズ(per_device_train_batch_sizeとgradient_accumulation_stepsの積)を調整して、OOMが起きない範囲でper_device_train_batch_sizeをなるべく大きくしています。
また、optimumライブラリのbettertransformerを使っていた時と違って、Trainerを使ってモデルを保存してもエラーは起きないのですが、GPUおよびCPUのRAM使用量がギリギリの状態で学習しているため学習中にモデルを保存するとOOMが起きるのでsave_strategy="no"としています。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="/content/tmp",
overwrite_output_dir=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=16,
learning_rate=5e-5,
weight_decay=0.01,
num_train_epochs=1,
logging_steps=2,
lr_scheduler_type="constant_with_warmup",
warmup_steps=5,
save_strategy="no",
fp16=True,
deepspeed="./zero_train.json",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
)
# 学習実行
trainer.train()
trainer.save_state()
1エポック46ステップの学習が20分30秒で完了しました。以前のpackingを行った時の学習とほぼ同じ時間です。
以前の学習時には15,015件すべてのデータを使っていて、今回はテキストが長いデータを除いた11,874件なので、学習速度は遅くなっているということになりますが、それでも十分実用的なスピードは出ているといえるでしょう。
モデルを保存する前にOOMを防ぐためにキャッシュをクリアします。
import gc
import deepspeed
del dataset
del trainer
gc.collect()
deepspeed.runtime.utils.empty_cache()
torch.cuda.empty_cache()
モデル保存
model.save_pretrained("/content/tmp", safe_serialization=False)
# マウントしたdriveにコピー
!cp -r /content/tmp/* ./save_dir
動作確認
カーネルを再起動して、学習したモデルを再読み込みして動作確認してみます。
Flash Attentionを使用して学習したモデルでも、読み込み時はFlash Attentionを使っても使わなくてもどちらでも問題なく動作します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "line-corporation/japanese-large-lm-3.6b"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
"./save_dir",
torch_dtype=torch.float16,
# attn_implementation="flash_attention_2", # 対応GPUなら指定してもいい
device_map="cuda",
)
from transformers import pipeline
# パイプライン作成
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
# 生成の設定
generator_params = dict(
max_length = 64,
do_sample = True,
temperature = 0.7,
top_p = 0.9,
top_k = 0,
repetition_penalty = 1.1,
num_beams = 1,
pad_token_id = tokenizer.pad_token_id,
)
input_text = "ふーん、で、君は涼宮ハルヒのキャラで誰が好きなの?"
prompt = f"### Instruction\n{input_text}\n\n### Answer\n"
output = generator(
prompt,
**generator_params,
)
print(output[0]["generated_text"])
出力
### Instruction
ふーん、で、君は涼宮ハルヒのキャラで誰が好きなの?
### Answer
長門有希。彼女は時々異常に見えるが、同時に非常に魅力的な存在です。彼女を見ていると、不思議な気分になります。彼女が退屈な日常を生き抜くために、
きちんと、対話形式に対応するファインチューニングが行えているようです。
いくつか試した限りでは、同じ学習エポック数だとpackingを行った時よりもモデルの応答の品質が高いような印象を受けました。
Accumulationを使うと、異なるデータ間にattentionが張られないので、学習が正確に行えているという可能性はあります。
一方で、学習時に異なるデータを見ることができるという状況は、ある種の正則化として働く可能性も考えられるので、どちらの方法の方が良いかはきちんと検証しないとわからないです。
ちなみに、Flash DecodingもFlash Attentionライブラリに実装されたので推論速度も上がるという話を聞いたので、こちらの記事の実験をもう一度行ってみたのですが、系列長が非常に長い場合を除いて速度は向上しませんでした。