はじめに
こんにちは。動画像処理の研究を行っているM1です。
就職活動の際に、RDBのインデックスについて聞かれることがあり、答えることができなかったので、勉強したので残しておきます。
RDB(Relational Database)とは
リレーショナルデータベース(RDB)は、データを表(テーブル)形式で管理・保存するデータベースの一種です。
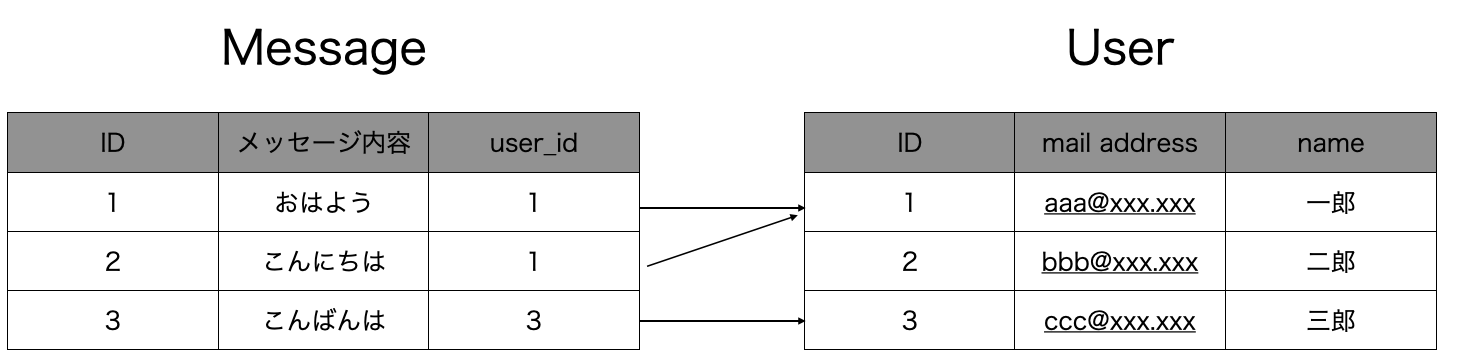
以下のように、主キーでそのテーブルを代表するカラムを指定し、外部キーで別テーブルと関連づけます。(以下のメッセージテーブルだとおかしな部分があるのですが外部キーとの関連付けの例なので気にしずに。。。)
インデックスとは
データへのアクセスを少ない実行数にして高速化するためのもの。
特定のルールに従って並べられているので最初から順に見ていく必要はなく、一気に特定のクラスタまで飛んでから探せるのが良い!!文だけだとわかりずらいので構造と例を用いて説明します。
インデックスの構造と例
インデックスは、基本的にはB-treeインデックスが利用されています。1
B-treeのインデックスの構造は、以下の図のとおりです
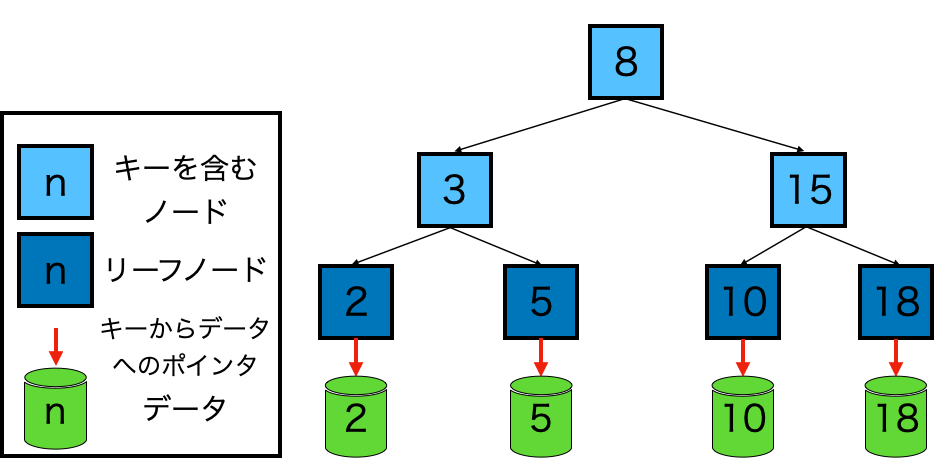
上記の図は、Messageテーブルのuser_idだと思って下さい。B-treeは、「木」という名前のとおり、木構造でデータを保持します。最下層のリーフ(葉)と呼ばれるノードだけが、実データに対するポインターを保持しており、DBは、最上位のノードから順に辿って、リーフから実データを見つけ出します。
B-treeインデックスの長所
B-treeインデックスの長所は、汎用性の高さです。
- 各キーにおける検索速度にばらつきが少ない均一性
- データ量の増加に比べてパフォーマンス低下が少ない持続性
- 検索、挿入、更新、削除のいずれかの処理もそこそこ早い処理汎用性
- 等価(=)に限らず、不等号(<,>, <=)を使ってもそこそこ早い非等値性
- GROUP BY、COUNTなどのソートが必要な処理を高速化できる親ソート性
このように汎用性の高さが伺えます。ただ、全てに対してそこそこ優れているので、場合によっては他のタイプのインデックスの方が速くなることもあります。
postgresqlで実際にB-treeインデックスの作成
実際にpostgresqlでやってみます。なぜpostgresqlかは、ChatGPTに実際にインデックスを作成してと言ったら、postgresqlで書いたので。
postgresqlをインストール
コードを表示
brew install postgresql
brew services start postgresql
psql postgres
CREATE DATABASE testdb;
\c testdb
シンプルのインデックスについて
コードや結果を表示
#!/bin/bash
psql -d testdb <<EOF
\timing on
-- customers テーブルを作成
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL,
name VARCHAR(255)
);
-- 大量データを挿入(500,000件)
INSERT INTO customers (email, name)
SELECT
'email' || gs || '@example.com' AS email,
'Customer ' || gs AS name
FROM generate_series(1, 500000) AS gs;
-- インデックスなしでの実行
\echo "クエリ実行(インデックスなし):"
SELECT * FROM customers WHERE email = 'email500000@example.com';
-- インデックス作成
\echo "インデックスを作成中..."
CREATE INDEX idx_customers_email ON customers(email);
-- インデックスありでの実行
\echo "クエリ実行(インデックスあり):"
SELECT * FROM customers WHERE email = 'email500000@example.com';
-- インデックス削除
\echo "インデックスを削除中..."
DROP INDEX IF EXISTS idx_customers_email;
-- テーブルが存在する場合は削除
DROP TABLE IF EXISTS customers;
EOF
chmod +x test.sh <-最初だけ
./test.sh
Timing is on.
CREATE TABLE
Time: 5.829 ms
INSERT 0 500000
Time: 2094.416 ms (00:02.094)
"クエリ実行(インデックスなし):"
id | email | name
--------+-------------------------+-----------------
500000 | email500000@example.com | Customer 500000
(1 row)
Time: 26.997 ms
"インデックスを作成中..."
CREATE INDEX
Time: 438.591 ms
"クエリ実行(インデックスあり):"
id | email | name
--------+-------------------------+-----------------
500000 | email500000@example.com | Customer 500000
(1 row)
Time: 0.296 ms
"インデックスを削除中..."
DROP INDEX
Time: 0.637 ms
DROP TABLE
Time: 2.459 ms
実行結果を見てみると、インデックスなしは、26.997ms、インデックス有りだと0.296msです。約91倍違うことがわかりました。
続いて、複合のカラムに対する複合インデックスについて行います。
複合インデックスについて
コードや結果を表示
#!/bin/bash
psql -d testdb <<EOF
\timing on
-- orders テーブルを作成
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INT,
order_date DATE,
product_id INT,
quantity INT,
total_amount DECIMAL(10, 2)
);
-- 大量データを挿入(500,000件)
INSERT INTO orders (customer_id, order_date, product_id, quantity, total_amount)
SELECT
(random() * 1000)::INT + 1 AS customer_id,
'2023-01-01'::DATE + (random() * 365)::INT AS order_date,
(random() * 100)::INT + 1 AS product_id,
(random() * 10 + 1)::INT AS quantity,
(random() * 1000)::DECIMAL(10,2) AS total_amount
FROM generate_series(1, 500000) AS gs;
-- インデックスなしでのクエリ実行
\echo "クエリ実行(複合インデックスなし):"
SELECT * FROM orders
WHERE customer_id = 500 AND order_date BETWEEN '2023-01-01' AND '2023-1-2';
-- 複合インデックス作成
\echo "複合インデックスを作成中..."
CREATE INDEX idx_orders_customer_orderdate ON orders(customer_id, order_date);
-- インデックスありでのクエリ実行
\echo "クエリ実行(複合インデックスあり):"
SELECT * FROM orders
WHERE customer_id = 500 AND order_date BETWEEN '2023-01-01' AND '2023-1-2';
-- テーブルが存在する場合は削除
DROP TABLE IF EXISTS orders;
EOF
chmod +x multiple_index.sh <-最初だけ
./multiple_index.sh
Timing is on.
CREATE TABLE
Time: 5.252 ms
INSERT 0 500000
Time: 1883.745 ms (00:01.884)
"クエリ実行(複合インデックスなし):"
order_id | customer_id | order_date | product_id | quantity | total_amount
----------+-------------+------------+------------+----------+--------------
93187 | 500 | 2023-01-01 | 25 | 5 | 619.11
438120 | 500 | 2023-01-01 | 14 | 6 | 320.22
(2 rows)
Time: 24.121 ms
"複合インデックスを作成中..."
CREATE INDEX
Time: 219.073 ms
"クエリ実行(複合インデックスあり):"
order_id | customer_id | order_date | product_id | quantity | total_amount
----------+-------------+------------+------------+----------+--------------
93187 | 500 | 2023-01-01 | 25 | 5 | 619.11
438120 | 500 | 2023-01-01 | 14 | 6 | 320.22
(2 rows)
Time: 0.290 ms
DROP TABLE
Time: 2.329 ms
インデックスがあまり効果が発揮されない場合について
コードや結果を表示
#!/bin/bash
psql -d testdb <<EOF
\timing on
-- users テーブルを作成
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL,
name VARCHAR(255),
gender CHAR(1) -- 'M' または 'F'
);
-- 大量データを挿入(500,000件)
INSERT INTO users (email, name, gender)
SELECT
'user' || gs || '@example.com' AS email,
'User ' || gs AS name,
CASE WHEN gs % 2 = 0 THEN 'M' ELSE 'F' END AS gender
FROM generate_series(1, 500000) AS gs;
-- インデックスなしでのクエリ実行
\echo "クエリ実行(インデックスなし):"
SELECT COUNT(*) FROM users WHERE gender = 'M';
-- 低選択性のインデックス作成
\echo "インデックスを作成中(低選択性)..."
CREATE INDEX idx_users_gender ON users(gender);
-- インデックスありでのクエリ実行
\echo "クエリ実行(インデックスあり、低選択性):"
SELECT COUNT(*) FROM users WHERE gender = 'M';
-- インデックス削除
\echo "インデックスを削除中..."
DROP INDEX IF EXISTS idx_users_gender;
-- テーブルが存在する場合は削除
DROP TABLE IF EXISTS users;
EOF
chmod +x no_index.sh <-最初だけ
./no_index.sh
Timing is on.
CREATE TABLE
Time: 6.052 ms
INSERT 0 500000
Time: 1802.583 ms (00:01.803)
"クエリ実行(インデックスなし):"
count
--------
250000
(1 row)
Time: 35.865 ms
"インデックスを作成中(低選択性)..."
CREATE INDEX
Time: 172.721 ms
"クエリ実行(インデックスあり、低選択性):"
count
--------
250000
(1 row)
Time: 14.827 ms
"インデックスを削除中..."
DROP INDEX
Time: 0.546 ms
DROP TABLE
Time: 2.446 ms
実行結果を見てみると、インデックスなしは、35.865ms、インデックス有りだと14.827msです。約2.5倍違うことがわかりました。インデックス有りの方が速いですが、上記二つに比べたら比率が違います。
ならどのような時にインデックスを作成すれば良いのでしょうか?それは、特定の列の値がどれくらいの種類の多さを持つというカーディナリティで決まります。
先ほどの例でインデックスの効果があまり発揮されなかった例は、性別に対してインデックスを貼りました。そのため、カーディナリティは「2」となり、全体の約50%の行しか対象として絞れないためそこまで速くなりませんでした。書籍1によると全体のレコードの約5%に絞ると効果が出るとされています。
コラム
B-treeインデックスの長所において、なぜ持続性があるのかを数学を使って説明します。
まず初めに、Big-O記法について説明します。Big-O記法とは、入力サイズnに対して、処理時間がnのどのような関数として増大していくかという増え方を表す記法です。
例えば、インデックスを使わない場合1,000のレコードに対して最大検索回数は1,000なのでO(1000)とあらわされるので、O(n)と表せます。
B-treeの検索回数は、最上位のノードから最下層のリーフまでの高さに依存します。上記に示したB-treeのインデックス構造は、最大3回で探すことができます。したがって、最大検索回数=O(h)となります。続いて、nとhの関係について考えます。その前にB木のにおける各ノードのキー数及び子ノード数の最小値最大値を決定する最小度数tの定義が以下の通りです。
- キーの数
- 最小数: t-1
- 最大数: 2t-1
- 子ノード数
- 最小数: t
- 最大数: 2t
上の図で説明すると、「3」のノードのキーは一つだから生まれるノードは、最小で1か、最大で2しか無理です。という感じです。なので、この場合は、なのでt=1です。本来ならt=2以上とされています。
t=2の例が以下の通りです。
[20]
/ \
[10] [30, 40]
[30]
/ \
[10, 20] [40, 50]
/ | \ / \
[5] [15] [25] [35] [45] [55]
t=2でおおまかなn個を判別できる高さ(h)は、
- キー
- 最小数: t - 1 = 2 - 1 = 1
- 最大数: 2t -1 = 2 * 1 - 1 = 3
- 子ノード数
- 最小数: t = 2
- 最大数: 2t = 2 * 2 = 4
- h=1
- 1 <= n <= 3
- h=2
- 1(ルートノード) + 2(子の最小数) <= n <= 3 + 4 * 3
- h=3
- 1 + 2 + 4 < = <= 3 + 4 * 3 + 16 * 3
h=1は無視しますが n >= t^hという関係になります。
したがって h <= log_t(n)となり、定数は無視できるので、h <= log(n)となります。
よって、O(h) = O(log(t))となるのでデータ量が増えても持続性などが良いよねとなります。
おわりに
書籍やChatGPTに聞きながら書いたのでもし間違えていたらすみません😞