Dubbo扩展点[SPI]加载机制使整个框架接口和具体实现完全解耦,使得Dubbo具有良好的扩展性,比如注册中心可以使用Zookeeper、Nacos等,只需要在配置文件中设置就可灵活切换。Dubbo SPI功能上借鉴了JDK SPI,并在其基础上做了一些性能方面的改进。Dubbo SPI是整个框架实现的基石,这里主要探究其实现原理及所用到的设计思想,内容包括:
DUBBO SPI VS JDK SPI
JDK SPI
JDK SPI使用了策略模式,一个接口多种实现。使用起来非常简单:首先定义一个接口,然后写实现类,接着是在资源文件中配置需要使用的实现类,最后用在代码中使用ServiceLoader进行加载使用。下面用一个加解密SPI的例子来说明其使用方式及原理:
- 定义个加解密的接口。
package com.joeycoding.spi; public interface CryService { /** * 加密 */ String encrypt(String message); /** * 解密 */ String decrypt(String data); } - 实现类编写
package com.joeycoding.spi; public class KaiserCry implements CryService { @Override public String encrypt(String message) { ... } @Override public String decrypt(String data) { ... } } - 在META-INF/services创建使用的实现类配置文件
// Sources root +--resources +--META-INF +--services +--com.joeycoding.spi.CryService // 接口全路径名 // com.joeycoding.spi.CryService文件内容 // 实现类全路径名 // 如果有多个用分行符分割 com.joeycoding.spi.KaiserCry com.joeycoding.spi.AesCry - ServiceLoader 加载使用
ServiceLoader<CryService> serviceLoader = ServiceLoader.load(CryService.class); for (CryService cry : serviceLoader) { cry.encrypt("..."); }
ServiceLoader原理
- 通过ClassLoader获取SPI配置的配置信息(URL)
private static final String PREFIX = "META-INF/services/"; Enumeration<URL> configs = null; String fullName = PREFIX + service.getName(); if (loader == null) configs = ClassLoader.getSystemResources(fullName); else configs = loader.getResources(fullName); - 通过
class.forName(...)方法创建Class类// loader为当前线程的classLoader loader = Thread.currentThread().getContextClassLoader(); Class<?> c = null; c = Class.forName(cn, false, loader); - 通过Class的
newInstance()创建服务实例并缓存起来,用于遍历使用。private LinkedHashMap<String,S> providers = new LinkedHashMap<>(); S p = service.cast(c.newInstance()); providers.put(cn, p);
Bubbo SPI与 JDK SPI的异同
- 和JDK SPI一样,Dubbo SPI同样需要在Resourse root中配置,只是支持的文件夹和文件内容有所区别。
// JDK SPI 支持的文件路径 META-INF/services/... // Dubbo SPI 支持的文件路径 META-INF/services/... META-INF/dubbo/... META-INF/dubbo/internal/... // JDK SPI 支持的文件内容格式 com.joeycoding.spi.KaiserCry com.joeycoding.spi.AesCry // Dubbo SPI 支持的文件内容格式 // @SPI(impl) impl=com.joeycoding.spi.KaiserCry,com.joeycoding.spi.AesCry - JDK SPI通过
ServiceLoader加载扩展点实例,类似的,Dubbo SPI则通过ExtensionLoader加载实例。 - Dubbo SPI定义了
@SPI注解需要配合注解使用,而JDK不需要。 - JDK SPI 扩展机制会一次性实例化所有扩展点的实现,如果这些实现初始化很耗时,但实际上又没用上就会很浪费。Dubbo SPI先缓存扩展点的Class对象,用到的时候在进行实例化。
- JDK SPI 如果扩展点加载失败,报错不精准。
- DUBBO SPI 增加了对扩展点
AOP和IoC的支持:Setter 方法进行依赖注入,Wrapper 装饰器的方式进行功能增强。
@SPI、@Adaptive和@Activity
Dubbo SPI的使用方式与JDK SPI大致一样。现在看看那些不一样的地方。首先,使用Dubbo SPI的接口需要加上@SPI的注解,注解的value值对应的是配置文件中扩展实现类名=前面的值。例如我们实现接口的类为EnglishPinter。
// 接口
@SPI("print")
public interface PrintService {
void sayHello();
}
// META配置
print=com.joeycoding.dubbo.spi.EnglishPinter
然后,我们在使用的时候通过extensionLoader.getExtension("name")的方式获取到唯一的扩展点实现。这就是关于注解@SPI的使用。配置文件的查找匹配和JDK SPI类似,区别在于Dubbo初始化的时候只缓存Class对象,扩展点实例化采用懒加载的方式。
// 1 获取Dubbo SPI扩展点实现配置信息
// fileName包含: META-INF/services、META-INF/dubbo、META-INF/dubbo/internal
Enumeration<URL> urls = currentClassLoader.getResources(fileName);
// 2 缓存所有的SPI扩展实现类Class
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
Dubbo整个框架中信息流的核心是URL,Dubbo SPI也正是通过URL的参数来适配运行时具体的实现类的。通过自适应注解@Adaptive和一个动态编译[后面会详细介绍]的接口名$Adaptive类来达到动态实现的效果。下面介绍两个例子:
// SPI 接口
@SPI(value = "dubbo", scope = ExtensionScope.FRAMEWORK)
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
...
}
// 动态编译的SPI 接口实现类
public class Protocol$Adaptive implements org.apache.dubbo.rpc.Protocol {
public int getDefaultPort() {
throw new UnsupportedOperationException("...");
}
public org.apache.dubbo.rpc.Exporter export(org.apache.dubbo.rpc.Invoker arg0) {
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol)scopeModel.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
// 真实的调用
return extension.export(arg0);
}
}
从上面的简写的代码可以看出没有加@Adaptive注解的方法getDefaultPort直接抛出异常,加了@Adaptive注解的方法则是通过URL的参数去匹配运行时的扩展实现类,然后调用这个实现类的方法。如果@Adaptive注解中有值则,会通过这些值来匹配实现类,具体规则如下:
@SPI(value = "netty", scope = ExtensionScope.FRAMEWORK)
public interface Transporter {
@Adaptive({Constants.SERVER_KEY/* server */, Constants.TRANSPORTER_KEY/* transporter */})
RemotingServer bind(URL url, ChannelHandler handler) throws RemotingException;
}
// $Adaptive
// 优先级:client值 > transporter值 > netty
public class Transporter$Adaptive implements org.apache.dubbo.remoting.Transporter {
...
String extName = url.getParameter("client", url.getParameter("transporter", "netty"));
...
}
// 配置文件
netty=org.apache.dubbo.remoting.transport.netty4.NettyTransporter
在Dubbo SPI中,扩展点自动激活的的注解@Activate能解决需要同时激活多个扩展点实现的需求。例如:过滤器[Filter]和监听器[Listener]就是使用了@Activate的注解。在扫描完META-INF下SPI配置后,ExtensionLoader会缓存所有的@Activate注解的Class对象。然后通过ExtensionLoader的getActivateExtension(url,key,group)方法获取自动激活的扩展实例。
private volatile Class<?> cachedAdaptiveClass = null;
private Set<Class<?>> cachedWrapperClasses;
private final ConcurrentMap<Class<?>, String> cachedNames = new ConcurrentHashMap<>();
// 缓存 @Adaptive
if (clazz.isAnnotationPresent(Adaptive.class)) {
cacheAdaptiveClass(clazz, overridden);
}
// 缓存包装类
if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
}
// 缓存 @Activate
cacheActivateClass(clazz, names[0]);
下面在获取Filter责任链的代码中,只会把属于group的所有Filter放到责任链中[即group = "provider", 例如CacheFilter]。另外只有key所对应的值在url中出现才会加入其中。
@Activate(group = {CONSUMER, PROVIDER}, value = CACHE_KEY)
public class CacheFilter implements Filter {
...
}
// ProtoclFilterWrapper获取过滤器链的代码
// export()
// key: service.filter
// group: provider
List<Filter> filters = ScopeModelUtil.getExtensionLoader(Filter.class, url.getScopeModel()).getActivateExtension(url, key, group);
public List<T> getActivateExtension(URL url, String[] values, String group) {
cachedActivateGroups.forEach((name, activateGroup) -> {
// 匹配group
if (isMatchGroup(group, activateGroup)
&& !namesSet.contains(name)
&& !namesSet.contains(REMOVE_VALUE_PREFIX + name)
// url 中是否出现
&& isActive(cachedActivateValues.get(name), url)) {
activateExtensionsMap.put(getExtensionClass(name), getExtension(name));
}
});
}
动态编译技术
基于字节码的方式生成 Class 的工具:CGLIB,ASM,Javassist等。dubbo使用了动态生成字符串代码,再编译为 Class 的方式。Dubbo提供的编译器工具类有基于Javassist的JavassistCompiler和基于JDK的JdkCompiler。动态编译的原理如下图:
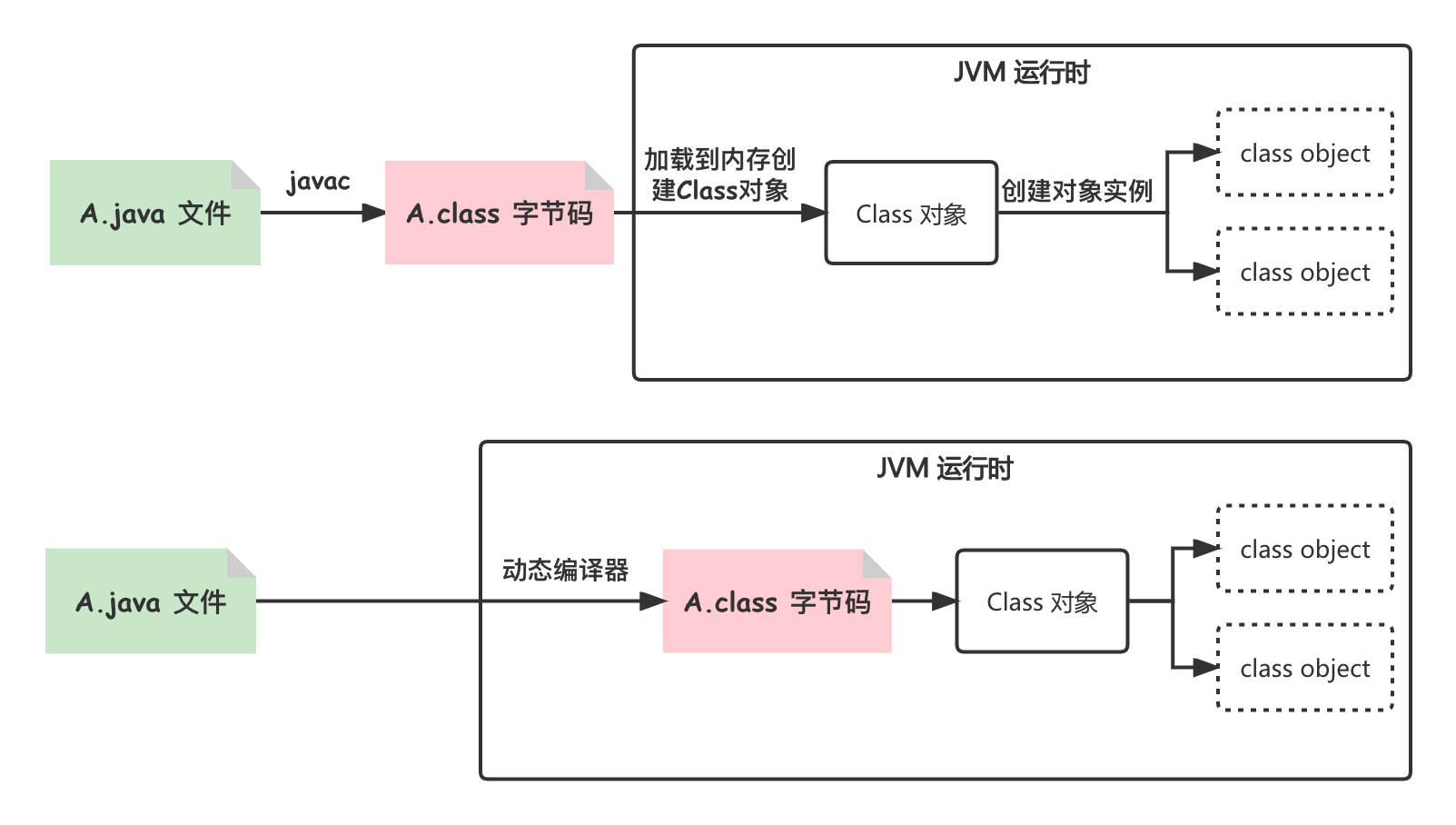
Javassist可通过字符串动态编译,以下是一个简单的例子:
// 基于字节码的方式生成 Class 的工具:CGLIB,ASM,Javassist.
// dubbo使用了生成字符串代码再编译为 Class 的方式。
// 例子:
// 1. 初始化 Javassist 的类池
ClassPool classPool = ClassPool.getDefault();
// 2. 创建一个Hello World类
CtClass ctClass = classPool.makeClass("Hello World");
// 3. 添加一个方法
CtMethod ctMethod = CtNewMethod.make("public void test(String someone) {"
"System.out.println(\"Hello \"+someone);}", ctClass);
ctClass.addMethod(ctMethod);
Class<?> aClass = ctClass.toClass(); // 生成类
Object object = aClass.newInstance(); // 创建实例
Method m = aClass.getDeclaredMethod("test", String.class); // 获取实例方法
m.invoke(object, "Javassist"); // test方法调用
Dubbo中动态编译的过程[也就是生成接口名$Adaptive字节码]的过程在ExtensionLoader的createAdaptiveExtensionClass()的方法中:先根据通用方法生成字符串代码,然后用编译器进行编译。由@SPI设置可以看出默认使用的javassist编译器。这样,通过getAdaptiveExtension(...)拿到的@SPI扩展首先调用就是对应的接口名$Adaptive实现,然后再通过url中的配置调用匹配到的扩展实现类的方法。
private Class<?> createAdaptiveExtensionClass() {
// 1
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
// 2
org.apache.dubbo.common.compiler.Compiler compiler = extensionDirector.getExtensionLoader(
org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
}
// 编译器默认使用javassist
@SPI(value = "javassist", scope = ExtensionScope.FRAMEWORK)
public interface Compiler {
...
}
IoC & AOP
IoC
依赖注入的原理比较简单,先通过反射获取类的所有方法,然后遍历所有set开头的方法,通过方法入参类型通过ExtensionLoader获取,获取到扩展实现则进行赋值。
private T injectExtension(T instance) {
for (Method method : instance.getClass().getMethods()) {
// 非 setter 方法
if (!isSetter(method)) {
continue;
}
// 注解标注不注入
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
Class<?> pt = method.getParameterTypes()[0];
// 原始类型不注入
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
Object object = getExtension(type, name);
// property赋值,完成注入
if(object != null) {
method.invoke(instance, object);
}
}
AOP
AOP的实现原理就遍历扩展实现类,是否包含扩展点类型相同的构造函数,并为其注入扩展类实例,这样一层层包装起来,最后作为扩展类实例返回回去。
private T createExtension(String name, boolean wrap) {
...
for (Class<?> wrapperClass : wrapperClassesList) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
instance = postProcessAfterInitialization(instance, name);
}
}
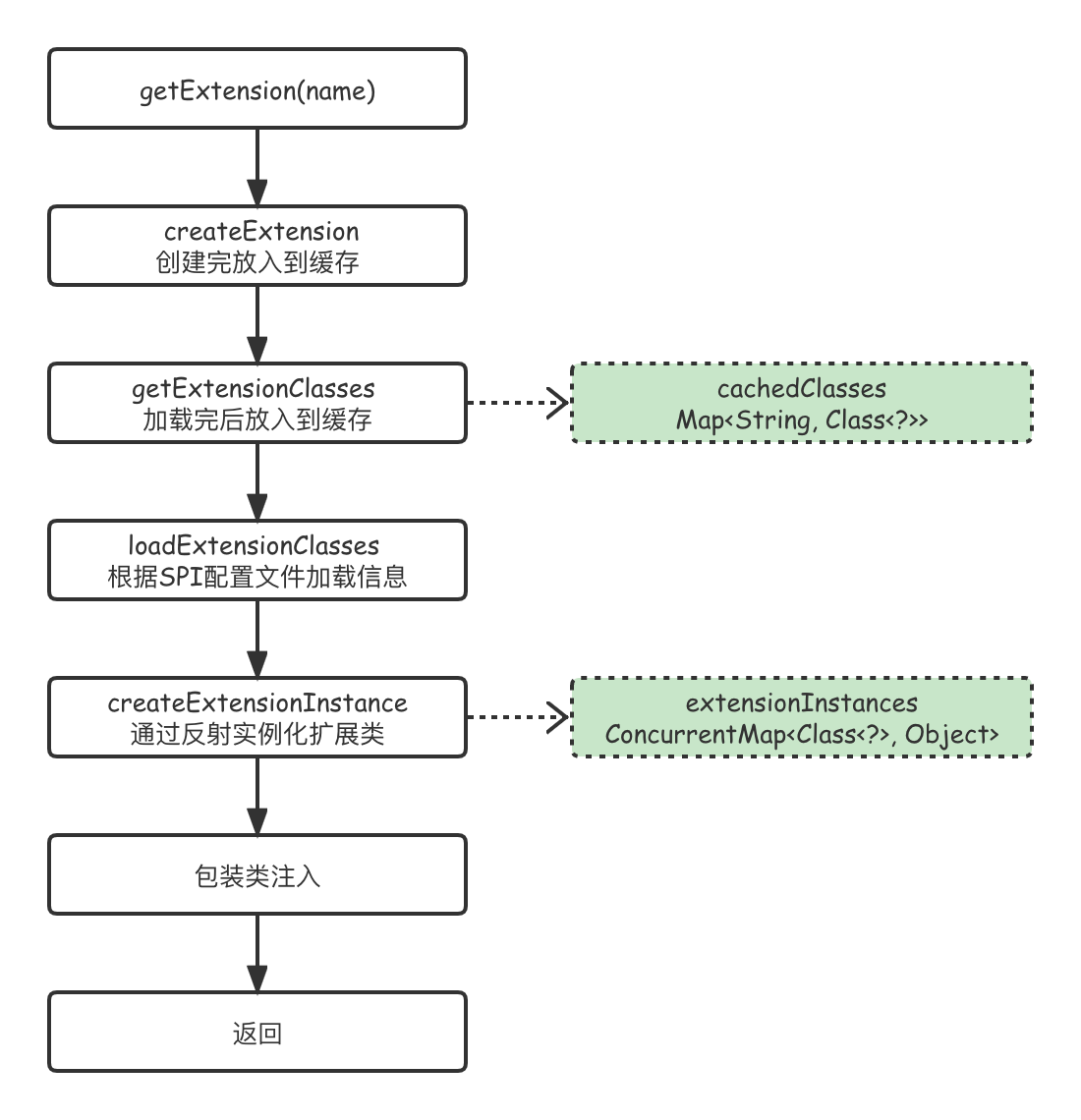
Dubbo扩展机制核心的三个方法:getExtension(name),getAdaptiveExtension()以及getActivateExtension(URL url, String key),举例获取普通扩展类getExtension工作流程如下:
获取自适应扩展的方法getAdaptiveExtension工作流程:
- 和获取普通扩展一样,加载扩展类配置信息。
- 生成
接口名$Adaptive自适应类的代码字符串。 - 通过类加载器和动态编译器编译第2步的代码。
- 返回自适应类实例。
获取自动激活的扩展类的方法getActivateExtension工作流程:
- 通过调用
getExtensionClasses()加载所有的扩展实现类信息。 - 找出所有符合URL条件的@Activate类。
- 通过
getExtension获取扩展类。 - 将扩展类放入到排序的集合中返回。
设计模式
适配器模式
在Dubbo源码中大量使用动态编译的接口$Adaptive自适应类,如Protocol&Adaptive、Transport&Adaptive、RegistryFactory&Adaptive等等。其原理为设计模式中的适配器模式[Adapter]。如下图,适配器模式分为类适配器和对象适配器,由于dubbo中使用方[自适应类]都是引用一个实例对象进行调用,所以用的的对象适配器。
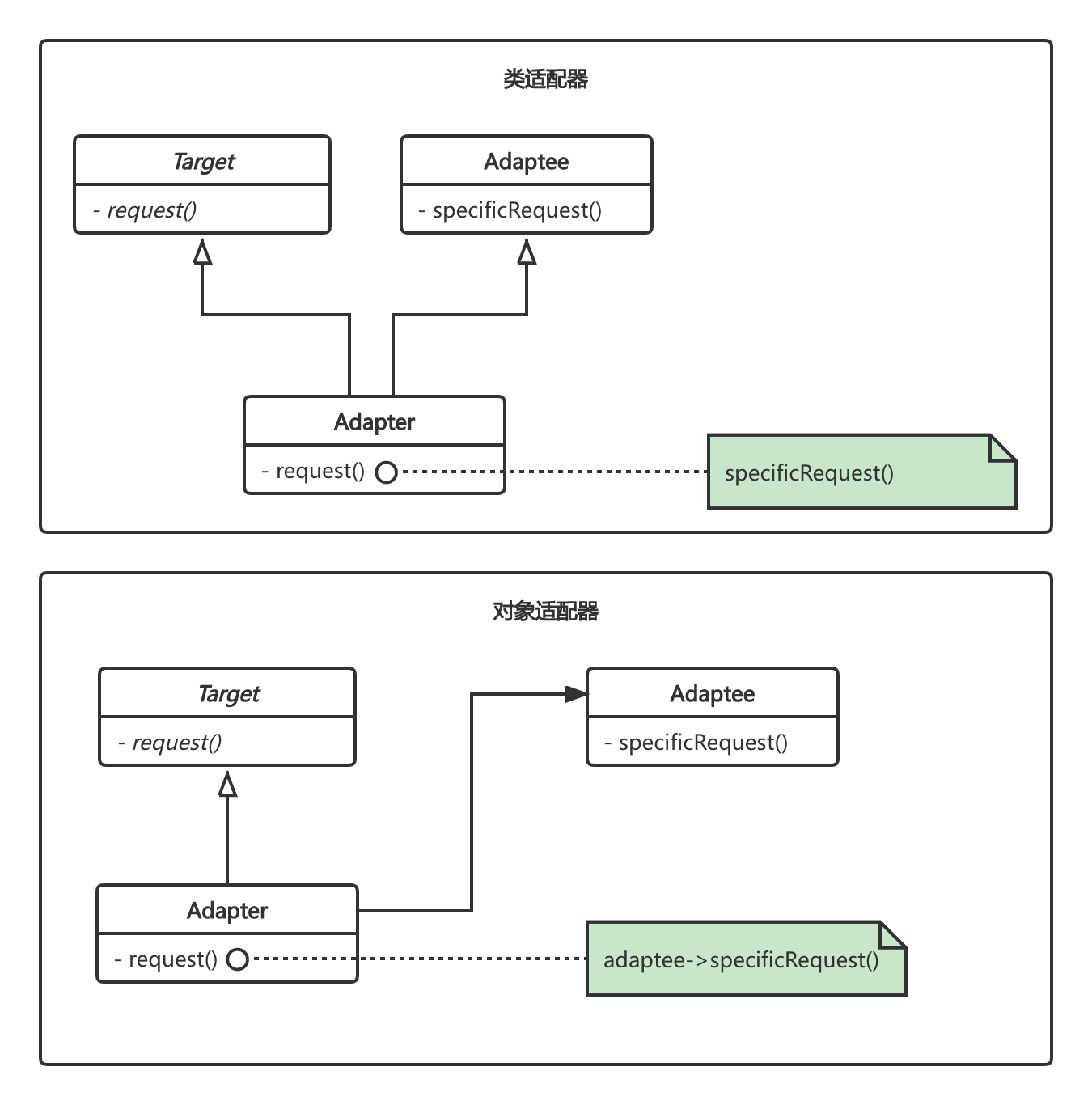
下面以Protocol&Adaptive为例,简单描述下适配器中各参与者的功能。
Target:定义特定领域相关接口。如dubbo中Protocol接口,定义服务的发布和引用。
Adaptee:定义一个已经存在的接口实现,这个接口需要适配。例如DubboProtocol。
Adapter:对Adaptee和target进行适配。

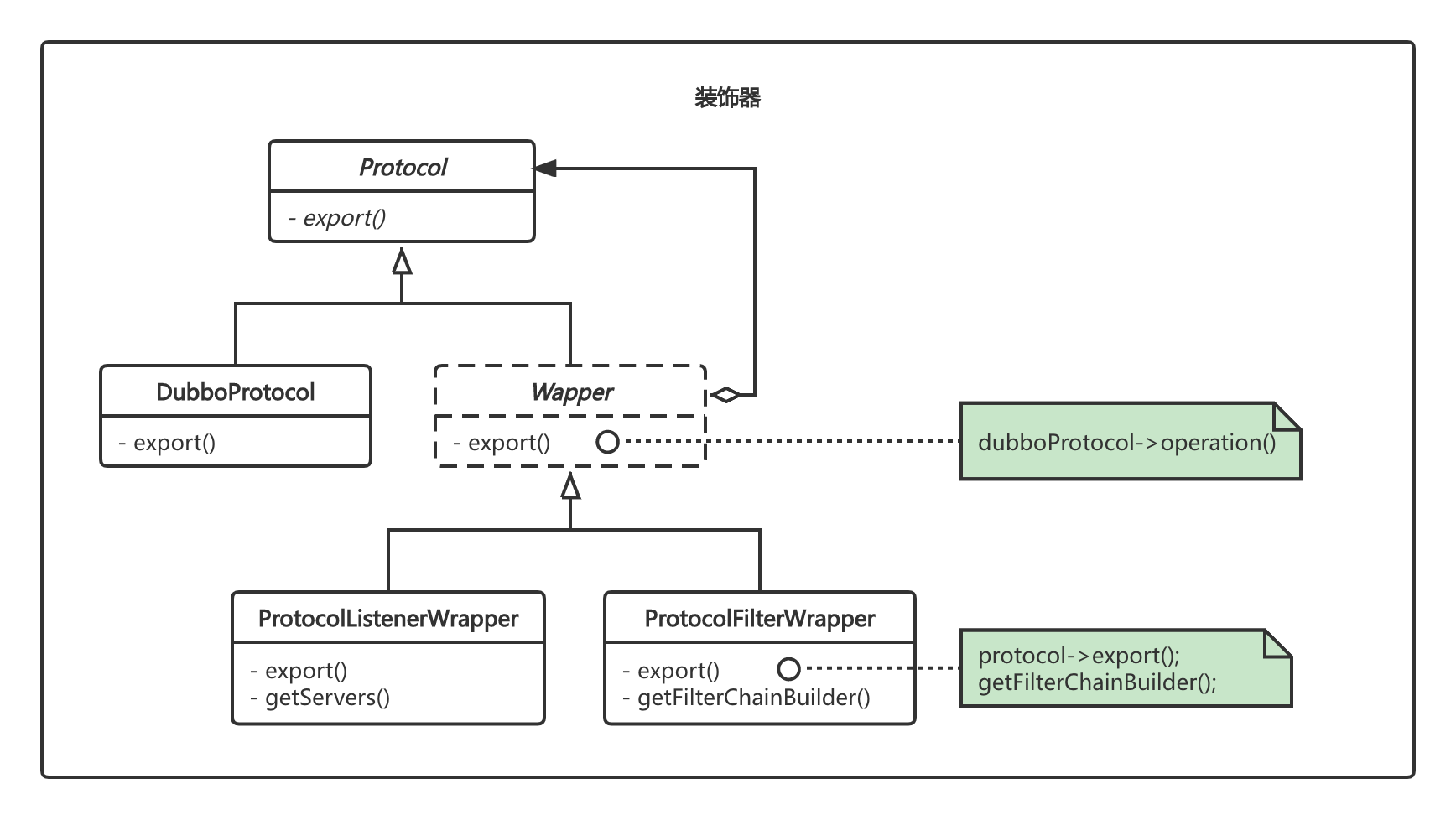
装饰器模式
Dubbo使用各种Wrapper类对相应的扩展点进行功能增强,使用的就是设计模式中的装饰器模式:
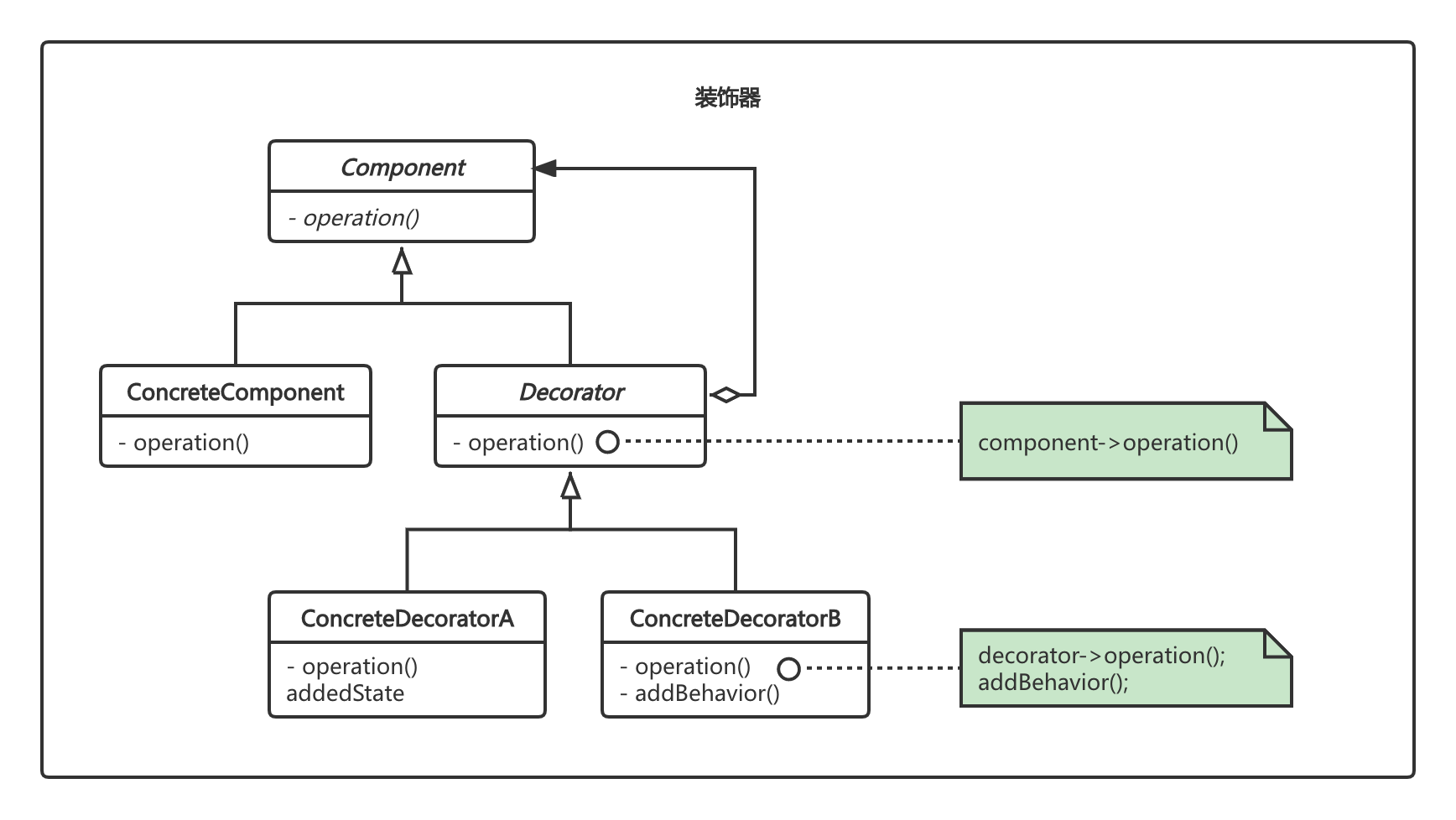
下面以Protocol为例,简单描述下装饰器中各参与者的功能。
Component:定义一个对象的接口[如Protocol],可以给这些对象动态的添加职责,例如Dubbo中监听、限流等功能。
ConcreteComponent:定义实现职责功能对象。例如DubboProtocol。
Decorator:维持一个指向Component的指针,并定义一个与Component一致的接口。
ConcreteDecorator:向组件添加职责。
Dubbo中Protocol的Wapper实现了Protocol接口,同时拥有一个Protocol的成员变量,充当了装饰器模式中Decorator的角色。
总结
Dubbo通过自定义扩展点加载机制使整个框架接口和具体实现完全解耦,使得Dubbo具有良好的扩展性;动态编译器Javassist的使用以及懒加载的方式加载扩展类提升了启动效率;Dubbo SPI针对不同的扩展需求提供了丰富的获取扩展点方法。