curator-recipes 5.1.0
Curator作为分布式协调系统Zookeeper的Java框架,通过Zookeeper实现了另一种分布式锁的解决方案[Redis的实现方案]。这里主要通过Curator源码分析其分布式锁实现的细节。接下来的内容包括:
- Zookeeper实现分布式锁图解
- Zookeeper分布式锁实现的理论基础
- 锁的核心概念实现细节
- 总结
Zookeeper实现分布式锁图解
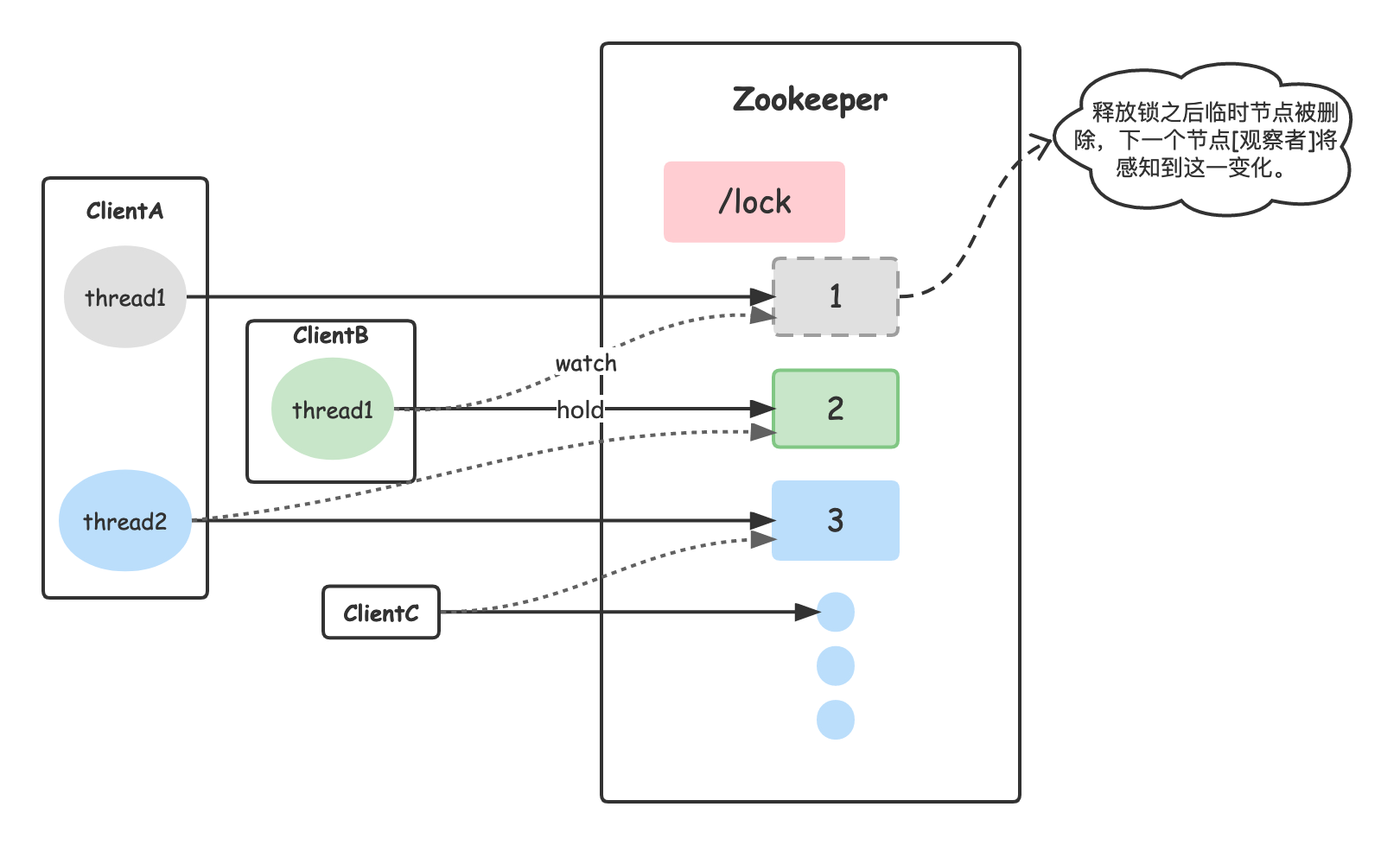
分布式锁解决的是传统的Java锁无法跨JVM使用的问题。如图所示,多个客户端【Clinet】相当于不同JVM进程,它们同时去获取锁,每个获取锁的线程在没有获取到锁时会进入等待状态,同时它们会实时监听着上一个获取锁的线程是否已经释放了锁资源。这样一个线程获取锁、执行任务然后释放锁,下一个线程收到通知获取锁再执行任务...循环往复。那么,zookeeper是如何管理锁资源的呢?
Zookeeper分布式锁实现的理论基础
主从架构的Zookeeper
整个Zookeeper的存储模型是类似于UNIX文件系统的树状存储方式。Zookeeper的核心数据结构znode就相当于文件系统中的文件。不管集群的数量是多少,znode同级节点的数据都是唯一的。主从架构的Zookeeper,Master负责增删改及同步操作,Slave可提供查询。
临时顺序节点
Zookeeper实现分布式锁是基于其顺序性和临时性的节点特性实现的。顺序节点很好理解,在创建节点的时候是按先后顺序生成的。所谓临时性是指:在Zookeeper客户端[这里由Curator实现]和服务端创建连接的时候,Zookeeper服务端会创建并维护一个针对于客户端的session会话,连接是基于TCP的长连接,当会话断开时[暂且这么理解]session失效,这时客户端所创建的临时节点也会被删除掉。这样避免了在客户端为获取锁之后由于宕机无法主动释放锁[删除节点],导致后面的线程无法获取到锁的问题。
监听[watch]机制
Zookeeper的监听机制是指当一个节点被监听之后,节点发生任何变化[这里主要是删除]监听方马上就能收到通知,这正好对应JDK隐式锁的通知wait¬ify机制。
锁的核心概念实现细节
加“锁”的本质
首先看一下获取锁lock.acquire()的操作主要的流程:
第一步,按调用获取锁的顺序创建一个以数字结尾的临时节点,同时该临时节点的父节点为分布式锁名。znode在Zookeeper的存储模型如下。
# 假设同时有5个线程同时过来获取锁
--------------------------- znode -------------------------
/test_lock #锁名
_c_521498f6-d9b9-49e5-9264-cc4105720a4e-lock-0000000000, #临时节点
_c_013c130b-7996-42f7-b88c-633fd8614d16-lock-0000000001,
_c_1baafb19-61e9-4db0-81c3-61217bbfc380-lock-0000000002,
_c_252539da-c410-45ab-a7ea-f684581997ce-lock-0000000003,
_c_eacad5a9-5fce-406d-948a-3717cd9444a8-lock-0000000004
第二步,尝试获取锁,如果发现自己创建的节点是[或者成为]第一个顺序节点则获取成功。反之,先通过监听器监听自己的前一个顺序节点,并进入阻塞状态。
InterProcessLock lock = new InterProcessMutex(client, "/test_lock");
if (lock.acquire(5000, TimeUnit.MILLISECONDS)) {
// ...
}
// #LockInternals.java acqure()
// 1、创建临时顺序节点
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
// 2、获取锁
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
// 获取锁的核心逻辑简化代码
boolean internalLockLoop(...) {
// 进入循环获取锁
while(!haveTheLock) {
// 这一段代码就是通过判断当前节点前面是否还有节点来获取锁
List<String> children = getSortedChildren();
String sequenceNodeName = ourPath.substring(basePath.length() + 1);
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
// 获取成功
if(predicateResults.getsTheLock()) {
return true;
}
else {
// 获取失败
synchronized(this) {
// 启用监听器监听前一个节点
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
// 进入阻塞
wait();
}
}
}
}
第三步,当获取到锁的线程执行完方法后,需要释放锁release。锁释放主要做了两件事情:1.移除掉自己的观察器;2删除临时节点。临时节点的删除[变化]会通知到下一个正在监听节点的线程。监听器会调用notifyAll方法唤醒阻塞的线程,该线程再次去获取锁。代码如下:
// 锁释放
final void releaseLock(String lockPath) throws Exception {
// 移除监听器和删除临时节点
client.removeWatchers();
revocable.set(null);
deleteOurPath(lockPath);
}
// 监听器唤醒方法
default CompletableFuture<Void> postSafeNotify(Object monitorHolder) {
return runSafe(() -> {
synchronized(monitorHolder) {
monitorHolder.notifyAll();
}
});
}
公平锁的实现
由于每个线程竞争锁的时候创建的节点是有序的,锁释放之后直接通知的是下一个线程,这样获取锁的顺序完全是排队的顺序。所以Curator实现的分布式锁天然就是公平锁。
可重入
不管是JDK的可重入锁还是分布式锁实现的方式都是借助记录线程号,等重入方法进入的时候做递增操作,释放的时候递减,直达锁完全释放。Curator的实现是在锁对象中持有一个记录线程的并发容器ConcurrentMap<Thread, LockData> threadData。这样只要发现线程重入,则做好记录并获取锁成功。
Thread currentThread = Thread.currentThread()
// 存在则为线程重入
LockData lockData = threadData.get(currentThread);
if ( lockData != null )
{
// re-entering
lockData.lockCount.incrementAndGet();
return true;
}
总结
Curator还实现了其他类JDK的锁机制,如Semaphore、读写锁等。其实现的方式和上面介绍的方式如出一辙:核心都是通过创建顺序临时节点,然后通过简单的算法[允许同时存在多少个节点]来决定是否能获取到锁;释放锁就是删除临时节点并发送节点移除通知。从并发性能来看:由于Zookeeper实现的分布式锁,创建删除节点都需要频繁的磁盘操作,这相比于Redisin-memery的方式来说说性能开销相对较高。安全性方面,Zookeeper的节点可持久化及实时监听机制保证了极高的安全性。所以一般安全性要求高的时候选择使用Zookeeper的实现,并发性高的时候可选择Redis的实现方案。