はじめに
Rubyは毎年12月25日にアップデートされます。
Ruby 3.4は2024年12月25日に正式リリースされました。
この記事ではRuby 3.4で導入された変更点や新機能について、サンプルコード付きでできるだけわかりやすく紹介していきます。
ただし、すべての変更点を網羅しているわけではありません。僕が個人的に「Railsアプリケーションの開発時に役立ちそうだな」とか「これはトリビア的な知識として知っておくと良いかも」と思った内容をピックアップしています。本記事で紹介していない変更点も多数ありますので、以下のような情報源もぜひチェックしてみてください。
動作確認したRubyのバージョン
本記事は以下の環境で確認した結果を記載しています。
$ ruby -v
ruby 3.4.1 (2024-12-25 revision 48d4efcb85) +PRISM [arm64-darwin24]
NOTE: Ruby 3.4.0はバージョンの表記に誤りがあったため、すぐに3.4.1がリリースされました(参考)。
フィードバックお待ちしています
本文の説明内容に間違いや不十分な点があった場合はコメント欄から指摘 or 修正をお願いします🙏
本記事はPart 1とPart 2の2部構成です
記事が思いのほか長くなってしまったため、Part 1とPart 2の2部構成になっています。
- Part 1 = 文字列の凍結に関する変更点を理解する
- Part 2 = 新機能と変更点の総まとめ(本記事)
Part 1をまだ読んでいない人はPart 1もぜひチェックしてください。
それでは以下が本編です!
Ruby 3.4の概要(というか、個人的な感想)
大きな変更点としては、文字列リテラルをデフォルトで凍結状態にするための取り組みが動き始めた点でしょうか。
何年も前から「Rubyの文字列は将来的にイミュータブルになるかも」という話がありましたが、「おっ、いよいよ来るか?」という感じです。
とはいえ、Ruby 3.4の時点では警告が出る程度で既存のコードが動かなくなるような致命的な問題はおきないので安心してください。
言語仕様的にはブロックのデフォルトパラメータとして it が使えるようになった点が興味深いですね。
あまり多用しすぎるとコードの可読性を落としそうなので、個人的には「用量と用法を守ってお使いください」と考えていますが。
エラーメッセージやHash#inspectの表示形式が変わった点にも注目です。
このあたりは日々の開発効率にも影響してきそうな部分ですね。
その他、後方互換性問題に関してはそこまでインパクトの大きい変更点はなさそうです。
ただし、細かいレベルではちょこちょこあります。
いずれも「そんなケースは滅多にないやろ」と思うようなレアケースばかりですが、大きな開発プロジェクトだと、「滅多にない何か」を踏んでしまう可能性もゼロではありません。
後方互換性問題が起きそうな部分については本記事でなるべく網羅したつもりなので、じっくり読んで既存のコードに影響がないかどうかチェックしてください。
また、今回のRuby 3.4に限らず、Rubyでは以前から仕様変更が予定されていた機能については前のバージョンで警告が出ます。
いきなりRuby 3.4に上げず、まずRuby 3.3で警告が出ていないかどうかチェックしましょう。
ただし、デフォルトでは警告は表示されない点に要注意です。
RUBYOPT=-Wのような環境変数を設定してからテストコードの実行結果を確認したり、ログを検索したりするようにしてください。
それでは、Ruby 3.4の具体的な変更点について見ていきましょう。
言語仕様に関する変更点
文字列リテラルをデフォルトで凍結状態にするための取り組みが動き始めた
Ruby 3.4では文字列リテラルをデフォルトで凍結状態にするための取り組みが動き始めました。
この件についてはPart 1の記事で詳しく書いているので、本記事では概要を紹介するだけにとどめます。
詳細についてはPart 1をご覧ください。
frozen_string_literal: true/false が指定されていないファイルで文字列に破壊的な変更を加えると警告が出るようになった
Ruby 3.4では、frozen_string_literalのマジックコメントが付いていないファイルで文字列(文字列リテラルで作成されたもの)に破壊的変更を加えようとすると警告が出ます。
# Ruby 3.4 のデフォルトでも文字列リテラルはfreezeされないが、破壊的変更を加えると警告が出る
a = "ruby"
a.frozen? #=> false
a.upcase! #=> warning: literal string will be frozen in the future (run with --debug-frozen-string-literal for more information)
# 破壊的変更自体はこれまで通り適用される
a #=> "RUBY"
ただし、この警告は-wオプションを付けてrubyコマンドを実行するか、RUBYOPT=-Wの環境変数を指定しないと表示されない点に注意してください。
# オプションなしだと警告は出ない
$ ruby sample.rb
# -w オプションを付けると警告が出る
$ ruby -w sample.rb
sample.rb:3: warning: literal string will be frozen in the future (run with --debug-frozen-string-literal for more information)
# もしくは RUBYOPT=-W の環境変数を指定する
$ RUBYOPT=-W ruby sample.rb
sample.rb:3: warning: literal string will be frozen in the future (run with --debug-frozen-string-literal for more information)
frozen_string_literal: true/false が指定されていないファイルで、 String#+@ メソッドを使うと複製された文字列を返すようになった
frozen_string_literalを指定しない場合、文字列リテラルで作成された文字列は単項演算子+を使うと、selfではなく複製された文字列を返します。
そのため、以下のコードを実行すると、Ruby 3.3と3.4で挙動が異なります。
# frozen_string_literal を指定していないので、Ruby 3.4の世界では a はチルド文字列
a = "ruby"
b = +a
# 参考:b はチルド文字列ではない(文字列リテラルから生成されていない)ので破壊的変更を加えても警告は出ない
b.upcase!
puts a
puts b
Ruby 3.3では+aでselfが返るため、b.upcase!の破壊的変更がaにも波及しています(どちらも大文字になる)。
# Ruby 3.3の場合
$ ruby sample.rb
RUBY
RUBY
Ruby 3.4では+aで複製された文字列が返るため、b.upcase!を呼び出してもaは小文字のままです。
# Ruby 3.4の場合
$ ruby sample.rb
ruby
RUBY
Symbol#to_s で返ってくる文字列がチルド文字列になった
Ruby 3.4では Symbol#to_s で返ってくる文字列がチルド文字列になりました。
そのため、シンボルから生成した文字列に破壊的変更を加えると警告が出ます(要 -w オプション)。
# シンボルを文字列に変換すると、チルド文字列が返る
name = :ruby.to_s
name #=> "ruby"
name.frozen? #=> false
# チルド文字列なので破壊的変更を加えると警告が出る
name.upcase!
#=> warning: string returned by :ruby.to_s will be frozen in the future
# 破壊的変更自体はこれまで通り適用される
name #=> "RUBY"
繰り返しになりますが、上記3つのトピックはPart 1の記事で詳しく説明しているので、詳細はこちらをご覧ください(上の説明に出てきた「チルド文字列」についてもこの中で説明しています)。
デフォルトのブロックパラメータとして it が追加された
Ruby 3.4ではデフォルトのブロックパラメータとして it が追加されました。
[1, 2, 3].map { it * 10 }
#=> [10, 20, 30]
上のコードは以下と同じ意味です。
[1, 2, 3].map { |n| n * 10 }
#=> [10, 20, 30]
番号付きパラメータの_1と同じ、とも言えます。
[1, 2, 3].map { _1 * 10 }
#=> [10, 20, 30]
it はブロックがネストしていても使える
it はブロックがネストしている場合でも使えます。
たとえば、以下のコードを実行すると、ブロックごとに it が参照しているデータが異なることがわかります。
[[1, 2, 3],[10, 20, 30]].map do
puts "parent: #{it}"
it.each do
puts "child: #{it}"
end
end
実行結果(外側のブロックと内側のブロックで it が参照しているデータが異なる)
parent: [1, 2, 3]
child: 1
child: 2
child: 3
parent: [10, 20, 30]
child: 10
child: 20
child: 30
とはいえ、コードの可読性はあまりよくないので、なるべく使わない方がいいでしょう。
ちなみに、_1の場合はブロックがネストすると構文エラーになります。
この点は it と _1 の仕様が異なる点です。
[[1, 2, 3],[10, 20, 30]].map do
puts "parent: #{_1}"
_1.each do
puts "child: #{_1}"
end
end
実行結果(構文エラーが発生するので実行不能)
syntax error found (SyntaxError)
64 | puts "parent: #{_1}"
65 | _1.each do
> 66 | puts "child: #{_1}"
| ^~ numbered parameter is already used in outer block
67 | end
68 | end
参考文献: プロと読み解くRuby 3.4 NEWS - STORES Product Blog
ハッシュだとどうなるのか?
ハッシュの場合、itの中にはキーと値の配列が入ります。
{a: 1}.each { p it } #=> [:a, 1]
with_index 付きで呼ぶとどうなるのか?
では each_with_index や with_index 付きで呼ぶとどうなるでしょうか?
結果は以下の通りです。
[10].each_with_index { p it } #=> 10
この場合、indexに該当するブロックパラメータは2つめのパラメータになるので無視されます。
以下のコードでいうところの、nだけがitに格納されるイメージです。
[10].each_with_index { |n, i| p "#{n}:#{i}" } #=> "10:0"
番号付きパラメータと併用するとどうなるのか?
番号付きパラメータとitを同時に使おうとすると構文エラーになります。
[1, 2, 3].map.with_index(10) do
it * _2
end
#=> syntax error found (SyntaxError)
#=> numbered parameters are not allowed when 'it' is already used
通常のパラメータと併用するとどうなるのか?
通常のパラメータとitを同時に使おうとした場合も構文エラーになります。
[1, 2, 3].map.with_index(10) do |_n, i|
it * i
end
#=> syntax error found (SyntaxError)
#=> `it` is not allowed when an ordinary parameter is defined
Ruby 3.3で警告が出ていないか念のためチェックしよう
この仕様変更はRuby 3.3リリース時にすでに予定されており、もし後方互換性の問題が発生しそうな場合は、実行時に警告が出るようになっていました。
# Ruby 3.3
def it = 10
# ブロックパラメータがないので警告が出る
[1, 2, 3].map { it * 10 }
#=> warning: `it` calls without arguments will refer to the first block param in Ruby 3.4; use it() or self.it
#=> [100, 100, 100]
警告が出るケースは以下の記事で詳しく説明しています。
基本的に滅多に発生しないレアケースだと思いますが、念のためRuby 3.4にアップデートする前にRuby 3.3で警告が出ていないかチェックしておきましょう。
ローカル変数やメソッド引数にitがあったらどうなるのか?
(2025.1.3追記)
@scivola さんの興味深い記事があったので、以下の記事を参考にしてこの項を追記します。
itがローカル変数として存在していた場合は、ブロックパラメータではなくローカル変数のitとして参照されるので注意してください。
# ローカル変数として事前にitを定義しておく
it = 110
# itはブロックパラメータではなく、上で定義したローカル変数として参照される
[1, 2, 3].map { it.to_s }
#=> ["110", "110", "110"]
# (["1", "2", "3"] ではないので注意)
メソッドの引数だった場合も同様です。
# メソッドの引数名をitにする
def with_it(it)
# itはブロックパラメータではなく、メソッド引数のitとして参照される
[1, 2, 3].map { it.to_s }
end
with_it(110)
#=> ["110", "110", "110"]
# (["1", "2", "3"] ではないので注意)
詳しくは前述の @scivola さんの記事をご覧ください。
ちなみに_1を使う場合はそもそも構文エラー(_1は予約語扱い)になるのでこの問題は発生しません。
# _1という名前のローカル変数を使おうとすると構文エラー
_1 = 110
#=> syntax error found (SyntaxError)
#=> _1 is reserved for numbered parameters
# _1という名前の引数名を使おうとすると構文エラー
def with_1(_1)
#=> syntax error found (SyntaxError)
#=> _1 is reserved for numbered parameters
メソッド呼び出し時に **nil をキーワード引数に渡すと、**{} と同等に扱われるようになった
以下のようなメソッドがあったとします。
def sample_keyword(foo: 1, bar: 2)
[foo, bar]
end
Ruby 3.3では **nil をキーワード引数として渡そうとするとTypeErrorが発生していました。
# Ruby 3.3
sample_keyword(foo: 10, **nil)
#=> no implicit conversion of nil into Hash (TypeError)
Ruby 3.4では **nil は **{} と同等に扱われる(=0個のキーワード引数を渡したことになる)ため、エラーになりません。
# Ruby 3.4
sample_keyword(foo: 10, **nil)
#=> [10, 2]
わざわざ明示的に**nilを渡すケースはないと思いますが、以下のような条件分岐があると、結果的に**nilを渡すことがあるかもしれません(参考)。
# 条件によっては options は nil になる
options = {bar: 20} if some_condition
sample_keyword(foo: 10, **options)
Ruby 3.4なら上のようなケースでもエラーにならず呼び出せます。
トップレベルで Ruby という定数を定義すると警告が出る
Ruby 3.4ではトップレベルで Ruby という定数を定義すると警告が出るようになりました。
Ruby = 1
#=> warning: ::Ruby is reserved for Ruby 3.5
ただし、この警告は-wオプションを付けてrubyコマンドを実行するか、RUBYOPT=-Wの環境変数を指定しないと表示されない点に注意してください。
# そのままだと警告は出ない
$ ruby -e "Ruby = 1"
# -w オプションを付けると警告が出る
$ ruby -w -e "Ruby = 1"
-e:1: warning: ::Ruby is reserved for Ruby 3.5
# もしくは RUBYOPT=-W の環境変数を指定する
$ RUBYOPT=-W ruby -e "Ruby = 1"
-e:1: warning: ::Ruby is reserved for Ruby 3.5
警告メッセージにもあるように、Ruby 3.5では Ruby という定数は予約語(モジュール名)になる予定で、以下のようにRubyに関する情報を格納する名前空間としての利用方法が検討されています。
# Ruby 3.5(予想)
Ruby::VERSION #=> "3.5.0"
後方互換性に関する変更点
エラーメッセージやバックトレースの表示形式が変わった
Ruby 3.3ではエラーが発生したときに以下のような内容が表示されていました。
# Ruby 3.3
$ ruby backtrace_sample.rb
/path/to/lib/gate.rb:22:in `calc_fare': undefined local variable or method `distanse' for an instance of Gate (NameError)
FARES[distanse - 1]
^^^^^^^^
Did you mean? distance
from /path/to/lib/gate.rb:14:in `exit'
from backtrace_sample.rb:9:in `<main>'
Ruby 3.4ではこれが以下のような表示に変わりました。
# Ruby 3.4
$ ruby backtrace_sample.rb
/path/to/lib/gate.rb:22:in 'Gate#calc_fare': undefined local variable or method 'distanse' for an instance of Gate (NameError)
FARES[distanse - 1]
^^^^^^^^
Did you mean? distance
from /path/to/lib/gate.rb:14:in 'Gate#exit'
from backtrace_sample.rb:9:in '<main>'
えっ?どこが変わったのかよくわからないですって?
じゃあdiffを見てみましょう。diffはこんな感じです。
(左がRuby 3.3、右がRuby 3.4)

diffを見ると以下のような部分が変わっていることがわかります。
- メソッド名の手前にクラス名が入った(例:
in `calc_fare'→in 'Gate#calc_fare') - バッククオートがシングルクオートに変わった(例:
in `<main>'→in '<main>')
バッククオートはMarkdownのコードスパンにも使われているため、何も考えずにエラーメッセージをコピペすると意図せずMarkdownのフォーマットが崩れたりすることがありましたが、新しいメッセージではその問題を気にせずにコピペできるので便利そうです。
デフォルトのパーサーがPrismに変わった
Ruby 3.4からデフォルトのパーサーがparse.y から Prismに変わりました。
Prismパーサーはエラートレラント(問題が発生しても正常に処理を継続する能力)、移植性、メンテナンス性、高速性、効率性を考慮した設計になっている点が特徴です。
Prismは、Ruby 3.3.0にバンドルされた新しいライブラリで、プログラミング言語Rubyの新しいパーサであるPrismパーサのバインディングです。Prismはエラートレラント、移植性、メンテナンス性、高速性、効率性を考慮して設計されています。
このこと自体は後方互換性に影響しないのですが、その影響でエラーメッセージの形式が変わったりしています(詳しくは次の項で説明します)。
構文エラー発生時のエラーメッセージが変わった
パーサーがPrismに変わった影響で構文エラーが発生した場合のエラーメッセージの形式が少し変わっています。
試しに以下のように構文エラーが含まれるRubyスクリプトを用意して違いを見てみましょう。
class Gate
STATIONS = [:umeda, :juso, :mikuni]
FARES = [160, 190]
def initialize(name)
@name = name
end
def enter(ticket)
ticket.stamp(@name)
end
def exit(ticket)
fare = calc_fare(ticket)
fare <= ticket.fare
end
def calc_fare(ticket)
from = STATIONS.index(ticket.stamped_at))
to = STATIONS.index(@name)
distance = to - from
FARES[distanse - 1]
end
end
このスクリプトは下から6行目の以下の部分で閉じ括弧の)が1つ多くなっています。
# )) ではなく ) が正しい
from = STATIONS.index(ticket.stamped_at))
Ruby 3.3のエラーメッセージは以下の通りです。
$ ruby backtrace_sample.rb
backtrace_sample.rb:2:in `require_relative': --> /path/to/lib/gate.rb
Unmatched `)', missing `(' ?
1 class Gate
18 def calc_fare(ticket)
> 19 from = STATIONS.index(ticket.stamped_at))
23 end
24 end
/path/to/lib/gate.rb:19: syntax error, unexpected ')', expecting `end' or dummy end (SyntaxError)
...TIONS.index(ticket.stamped_at))
... ^
from backtrace_sample.rb:2:in `<main>'
Ruby 3.4の場合は次のようになります。
$ ruby backtrace_sample.rb
backtrace_sample.rb:2:in 'Kernel#require_relative': --> /path/to/lib/gate.rb
Unmatched `)', missing `(' ?
1 class Gate
18 def calc_fare(ticket)
> 19 from = STATIONS.index(ticket.stamped_at))
23 end
24 end
/path/to/lib/gate.rb:19: syntax errors found (SyntaxError)
17 |
18 | def calc_fare(ticket)
> 19 | ... )
| ^ unexpected ')', ignoring it
| ^ unexpected ')', expecting end-of-input
20 | to = STATIONS.index(@name)
21 | distance = to - from
from backtrace_sample.rb:2:in '<main>'
diffを見ると次のようになっています。
(左がRuby 3.3、右がRuby 3.4)
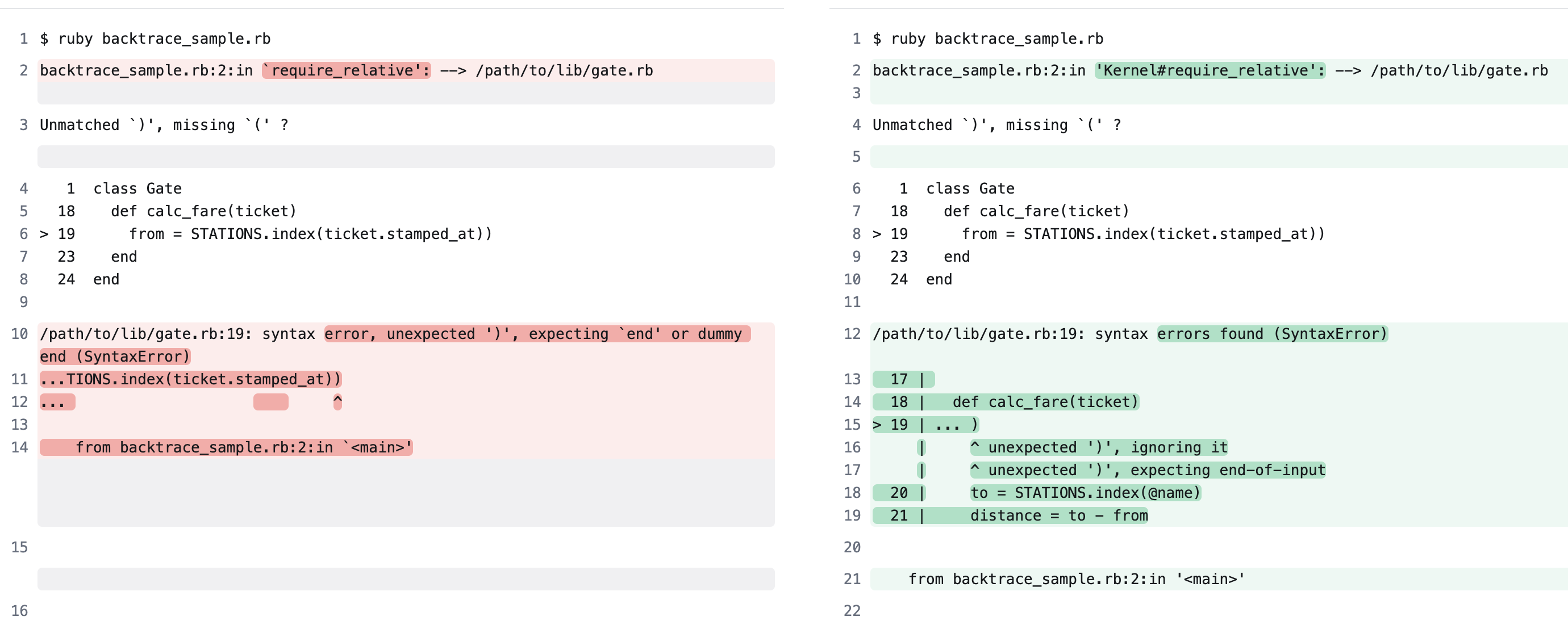
Ruby 3.4の方が後半のエラーメッセージがより詳しくなっていますね。
/path/to/lib/gate.rb:19: syntax errors found (SyntaxError)
17 |
18 | def calc_fare(ticket)
> 19 | ... )
| ^ unexpected ')', ignoring it
| ^ unexpected ')', expecting end-of-input
20 | to = STATIONS.index(@name)
21 | distance = to - from
from backtrace_sample.rb:2:in '<main>'
ただ、...TIONS.index(ticket.stamped_at)) みたいにエラーが発生している箇所をクローズアップしてくれるところはRuby 3.3の方がわかりやすいような気もします。
/path/to/lib/gate.rb:19: syntax error, unexpected ')', expecting `end' or dummy end (SyntaxError)
...TIONS.index(ticket.stamped_at))
... ^
from backtrace_sample.rb:2:in `<main>'
とはいえ、Ruby 3.4のエラーメッセージもこれからどんどん進化していくはずです。
従来のparse.yを使用することも可能
実行時に --parser=parse.y オプションを指定すれば、Ruby 3.4でも従来のparse.yを使用することができます。
$ ruby --parser=parse.y backtrace_sample.rb
backtrace_sample.rb:2:in 'Kernel#require_relative': --> /path/to/lib/gate.rb
Unmatched `)', missing `(' ?
1 class Gate
18 def calc_fare(ticket)
> 19 from = STATIONS.index(ticket.stamped_at))
23 end
24 end
/path/to/lib/gate.rb:19: syntax error, unexpected ')', expecting 'end' or dummy end (SyntaxError)
...TIONS.index(ticket.stamped_at))
... ^
from backtrace_sample.rb:2:in '<main>'
Hash#inspect で返ってくるハッシュの表示形式が変わった
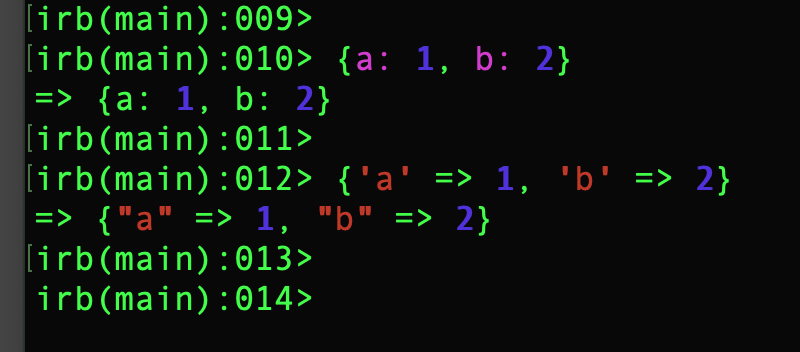
Ruby 3.4ではHash#inspectで返ってくるハッシュの表示形式が変わりました。
具体的な違いを見てみましょう。
まずはキーがシンボルの場合です。
# Ruby 3.3
{a: 1, b: 2}.inspect
#=> "{:a=>1, :b=>2}"
# Ruby 3.4
{a: 1, b: 2}.inspect
#=> "{a: 1, b: 2}"
=>を使わないモダンな記法に変わっていますね。
次はキーがシンボル以外の場合です
# Ruby 3.3
{'a' => 1, 'b' => 2}.inspect
#=> '{"a"=>1, "b"=>2}'
# Ruby 3.4
{'a' => 1, 'b' => 2}.inspect
#=> '{"a" => 1, "b" => 2}'
ご覧のとおり、Ruby 3.4では=>の前後にスペースが入りました。
このおかげでRuby 3.4の方が、irbやrails consoleを使ったり、ログを確認したりするときに読みやすくなりそうです。
Kernel#Float()メソッドが小数部分を省略した文字列をFloatに変換できるようになった
Ruby 3.3では以下のように Kernel#Float() メソッドに小数部分を省略した文字列を渡すと ArgumentError が発生していました。
# Ruby 3.3
# 小数部分を省略するとエラー
Float("1.")
#=> invalid value for Float(): "1." (ArgumentError)
Float("1.E-1")
#=> invalid value for Float(): "1.E-1" (ArgumentError)
# 小数部分を省略しなければOK
Float("1.0") #=> 1.0
Float("1.0E-1") #=> 0.1
Ruby 3.4では小数部分を省略しても自動的に0を補ってFloatに変換できるようになりました。
# Ruby 3.3
# 小数部分を省略してもFloatに変換できる
Float("1.") #=> 1.0
Float("1.E-1") #=> 0.1
Floatは大文字で始まっていますが、ここで使われているのはクラス名ではなく、Kernelモジュールに定義されているメソッドであることに注意してください(引数を渡すことでクラス名ではなく、メソッドと見なされる)。
# 引数がなければクラス(定数)と見なされる
Float #=> Float
# 引数を渡すとメソッドと見なされる
Float("0.1") #=> 0.1
Float "0.1" #=> 0.1
ちなみに、PythonやNode.jsでは以前からこういった変換ルールになっていたそうです(参考)。
$ python3 -c 'print(1.E-1)'
0.1
$ node -e 'console.log(1.E-1)'
0.1
String#to_f メソッドが小数部分を省略した文字列をFloatに変換できるようになった(ただし後方互換性問題あり)
Kernel#Float()と同様にString#to_fメソッドでも小数部分を省略できるようになりました。
とはいえ、Kernel#Float() とは少し事情が違うので注意が必要です。
まず、"1."のような文字列(指数表記を含まない文字列)は小数部分を省略しても、Ruby 3.3も3.4もエラーなく変換できます。
# Ruby 3.3でも3.4でも同じように変換できる
"1.".to_f #=> 1.0
問題は"1.E-1"のように指数表記を含むケースです。この場合、Ruby 3.3と3.4で戻り値が異なります。
# Ruby 3.3
"1.E-1".to_f #=> 1.0
# Ruby 3.4
"1.E-1".to_f #=> 0.1
Ruby 3.3では.より後ろを無視するような挙動になるのに対し、Ruby 3.4では自動的に小数部分に0を補ってからFloatに変換します。
このため、もしプログラム内で"1.E-1"のような文字列(指数表記を含み、なおかつ小数部分が省略された文字列)に対してto_fメソッドを呼び出すことがあれば、Ruby 3.3と3.4で得られる数値が異なる点に注意してください。
なお、小数部分を省略しない場合はRuby 3.3も3.4も同じ値を返します。
# 小数部分を省略しない場合はRuby 3.3も3.4も同じ
"1.2E-1".to_f #=> 0.12
いくつかの奇妙な代入構文が廃止された
Ruby 3.4では以下のような代入構文が廃止されました。
# indexを指定して代入する場合に、ブロックも同時に渡すと構文エラー
a[0, &b] = 1
#=> syntax errors found (SyntaxError)
# unexpected block arg given in index assignment; blocks are not allowed in index assignment expressions
# 以下のような記述も同様に構文エラーとなる
a[0, &b] += 1
a[0, &b] &&= 1
a[0, &b] ||= 1
# indexを指定して代入する場合に、キーワード引数も同時に渡すと構文エラー
a[0, kw: 1] = 2
#=> syntax errors found (SyntaxError)
# unexpected keyword arg given in index assignment; keywords are not allowed in index assignment expressions
# 以下のような記述も同様に構文エラーとなる
a[0, kw: 1] += 2
a[0, kw: 1] &&= 2
a[0, kw: 1] ||= 2
長年Rubyを使ってきて、こういう構文は見たことも書いたこともなく、使いどころがよくわからないので、この構文が廃止されて問題が出るのはよっぽどのレアケースなんじゃないだろうか?と個人的には思っています。
詳しい内容が気になる方は以下のissueを読んでみてください。
コアクラス(組み込みライブラリ)のアップデート
Array: 指定されたindexの要素を返す fetch_values が追加された
Ruby 3.4ではArrayクラスに指定されたindexの要素を返す fetch_values メソッドが追加されました。
array = [:a, :b, :c]
# 指定されたindexの要素を指定された順番で返す
array.fetch_values(0, 2) #=> [:a, :c]
array.fetch_values(2, 0) #=> [:c, :a]
# 負のindexを指定することもできる
array.fetch_values(-1, -2) #=> [:c, :b]
# 指定されたindexが範囲外の場合はIndexErrorが発生する
array.fetch_values(0, 1, 44)
#=> index 44 outside of array bounds: -3...3 (IndexError)
# ブロックを渡すと、指定されたindexが範囲外の場合にブロックの戻り値を返す
array.fetch_values(0, 1, 44) { |index| "#{index} is not found" }
#=> [:a, :b, "44 is not found"]
ちなみに、よく似た機能を持つ既存のメソッドとして values_at があります。
values_at はindexに対応する要素がなければ nil が返るのが fetch_values との違いです。
array = [:a, :b, :c]
# indexに対応する要素があれば fetch_values と結果は同じ
array.values_at(0, 2) #=> [:a, :c]
# indexに対応する要素がなければ nil を返すのが fetch_values との違い
array.values_at(0, 1, 44) #=> [:a, :b, nil]
また、Hashクラスには以前から指定されたキーの要素を返す fetch_values メソッドと values_at メソッドがあります。
h = {a: 1, b: 2, c: 3}
h.fetch_values(:a, :c) #=> [1, 3]
# fetch_values は対応するキーがなければエラー
h.fetch_values(:a, :z) #=> key not found: :z (KeyError)
# ブロックでキーが存在しない場合の戻り値を定義できる
h.fetch_values(:a, :z) { |k| "#{k} is not found" } #=> [1, "z is not found"]
h.values_at(:a, :c) #=> [1, 3]
# values_at は対応するキーがなければnil (ハッシュにデフォルト値が設定されていればその値)
h.values_at(:a, :z) #=> [1, nil]
HashもArrayも values_at はあるのに、 fetch_values はHashにしか定義されていないのはなぜ?という疑問から、このメソッドが生まれたようです。
Hash.new で capacity を指定できるようになった
Ruby 3.4では Hash.new で :capacity をオプションで指定できるようになりました。
大量の要素を追加することが事前にわかっている場合は、:capacityを指定することでパフォーマンスを改善できる可能性があります(デフォルト値は0)。
# 1万個の要素を追加することが事前にわかっているので :capacity を指定しておく
h = Hash.new(capacity: 10_000)
なお、:capacityオプションが追加されたことにより、Hash.new(hoge: 123)のようなデフォルト値指定はできなくなっています。
# Ruby 3.3
# 指定されたキーがない場合のデフォルト値として`{hoge: 123}`を指定する
h = Hash.new(hoge: 123)
h[:x] #=> {:hoge=>123}
# Ruby 3.4
# Ruby 3.4だと未定義のキーワード引数と見なされてエラーになる
h = Hash.new(hoge: 123)
#=> unknown keyword: :hoge (ArgumentError)
この場合、{}でハッシュを囲めば問題を回避できます。
# {}で囲めばOK
h = Hash.new({hoge: 123})
h[:x] #=> {hoge: 123}
# capacity と同時にデフォルト値を指定する場合はこう書く
h = Hash.new({hoge: 123}, capacity: 10_000)
h[:x] #=> {hoge: 123}
Ruby 3.3で警告が出ていないか念のためチェックしよう
この仕様変更はRuby 3.3リリース時にすでに予定されており、もし後方互換性の問題が発生しそうな場合は、実行時に警告が出るようになっていました(要 -w オプション)。
# Ruby 3.3
$ ruby -w -e 'Hash.new(hoge: 123)'
-e:1: warning: Calling Hash.new with keyword arguments is deprecated and will be removed in Ruby 3.4; use Hash.new({ key: value }) instead
念のためRuby 3.4にアップデートする前にRuby 3.3で警告が出ていないかチェックしておきましょう。
Integer/Rational: ** の計算結果が巨大な値を返す場合に例外が発生するようになった
Ruby 3.3までは、** (べき乗)の戻り値が巨大になる場合、警告と共に Float::INIFINITY が返ってきました。
# Ruby 3.3
100000000 ** 1000000000
#=> warning: in a**b, b may be too big
#=> Infinity
これはコンピュータのリソースを食い潰さないための予防策だったのですが、「正しい計算結果を出せないなら、Float::INIFINITYを返すのではなく、例外を出す方が自然だろう」ということで、Ruby 3.4では ArgumentError が発生するようになりました。
# Ruby 3.4
100000000 ** 1000000000
#=> exponent is too large (ArgumentError)
Rationalの計算でも同様に例外が発生します。
4r ** 400000000000000000000
#=> exponent is too large (ArgumentError)
なお、この例外は64ビット環境で必要なメモリが16GBを超えそうな場合に発生するとのことです。
Range: イテレート(繰り返し処理)できない範囲オブジェクトに対してsizeを呼ぶと例外が出るようになった
(0.5..2.4)のように非整数値で始まる範囲オブジェクトはイテレート(繰り返し処理)ができません。
そのため、eachメソッドを呼び出そうとするとエラーが発生します。
(0.5..2.4).each { puts _1 }
#=> can't iterate from Float (TypeError)
にもかかわらず、Ruby 3.3までは size メソッドを呼び出すことができました。
これは両端の数値を四捨五入してから size を計算していたためです。
# Ruby 3.3
# (1..2).size と同じ
(0.5..2.4).size #=> 2
# (1..3).size と同じ
(0.5..2.5).size #=> 3
しかし、この挙動はわかりづらいということで、Ruby 3.4からはTypeErrorが発生するようになりました。
# Ruby 3.4
(0.5..2.4).size
#=> can't iterate from Float (TypeError)
同様に(..1).sizeや(nil..1).sizeのように、開始位置を指定しない範囲オブジェクト(beginless range)でもエラーが発生するようになりました。
# Ruby 3.3
(..1).size #=> Infinity
(nil..1).size #=> Infinity
# Ruby 3.4
(..1).size #=> can't iterate from Float (TypeError)
(nil..1).size #=> can't iterate from Float (TypeError)
なお、countの挙動はRuby 3.3でも3.4でも変わっていません。
# countはRuby 3.3も3.4も同じ
(0.5..2.4).count
#=> `each': can't iterate from Float (TypeError)
(..1).size #=> Infinity
(nil..1).size #=> Infinity
Range: step メソッドが常に + を使ってイテレートするようになった
Rubyには範囲内の要素を、引数に指定されたステップで繰り返す step メソッドがあります。
(1..10).step(3).to_a
#=> [1, 4, 7, 10]
Ruby 3.3まではイテレートできる範囲オブジェクト以外は step メソッドが使えませんでした。
# Ruby 3.3
from = Time.utc(2024, 12, 1, 0, 0, 0)
to = Time.utc(2024, 12, 1, 0, 1, 0)
# Timeの範囲オブジェクトはイテレートできない
(from..to).each { p _1 } #=> can't iterate from Time (TypeError)
# イテレートできないので20秒おきに繰り返すこともできない
(from..to).step(20).to_a #=> can't iterate from Time (TypeError)
Ruby 3.4では、+メソッドで加算していけるオブジェクトであれば step メソッドが呼び出せるようになりました。
# Ruby 3.4
from = Time.utc(2024, 12, 1, 0, 0, 0)
to = Time.utc(2024, 12, 1, 0, 1, 0)
# Timeの範囲オブジェクトはイテレートできない(Ruby 3.3と同じ)
(from..to).each { p _1 } #=> can't iterate from Time (TypeError)
# Timeオブジェクトは + でその秒数分進んだ時間を返すので、stepメソッドが使える
(from..to).step(20).to_a
#=> [2024-12-01 00:00:00 UTC, 2024-12-01 00:00:20 UTC, 2024-12-01 00:00:40 UTC, 2024-12-01 00:01:00 UTC]
これにより、Railsでは以下のように書くことで、7日おきに進む時間の配列を生成することができます(参考)。
# 2024年12月1日から2024年12月25日まで、7日おきに進んだ時間の配列を生成する
(Time.parse('2024-12-01')..Time.parse('2024-12-25')).step(7.days).to_a
なお、stepの引数は+で加算できるものならなんでも良いので、以下のようなコードを書くこともできます。
# これはRuby 3.3も3.4も同じ
('a'..'e').step(2).to_a
#=> ["a", "c", "e"]
# Ruby 3.4ならこんなstepも書ける(ただし適当な件数でtakeしないと無限ループするので注意)
('a'..'e').step('!').take(3)
#=> ["a", "a!", "a!!"]
# Ruby 3.3だと上のコードはエラーになる
('a'..'e').step('!').take(3)
#=> no implicit conversion of String into Integer (TypeError)
Time: require 'time' なしで xmlschema/iso8601 メソッドが使えるようになった
Ruby 3.4ではrequire 'time'なしで xmlschema(エイリアスはiso8601) メソッドが使えるようになりました。
# Ruby 3.3
# require 'time' 無しだとxmlschemaメソッドが呼び出せない
Time.utc(2024, 12, 1, 0, 0, 0).xmlschema
#=> undefined method `xmlschema' for an instance of Time (NoMethodError)
# iso8601メソッドも同様
Time.utc(2024, 12, 1, 0, 0, 0).iso8601
#=> undefined method `iso8601' for an instance of Time (NoMethodError)
# Ruby 3.4
# require 'time' 無しでもxmlschemaメソッドが呼び出せる
Time.utc(2024, 12, 1, 0, 0, 0).xmlschema
#=> "2024-12-01T00:00:00Z"
# iso8601メソッドも同様
Time.utc(2024, 12, 1, 0, 0, 0).iso8601
#=> "2024-12-01T00:00:00Z"
加えて、メソッドの実装がC言語で書き直されているため、パフォーマンスが向上しています(そもそも、JSONやXMLへのシリアライズ処理を高速化するために、この変更が導入されたようです)。
Warning.categories メソッドで警告のカテゴリ一覧を取得できるようになった
Ruby 3.4では Warning.categories メソッドが追加されました。
このメソッドを呼ぶと警告の全カテゴリを配列で取得できます。
Warning.categories
#=> [:deprecated, :experimental, :performance, :strict_unused_block]
Rubyコミッタの方たちが警告に関するテストを書く際に利用することを想定して追加されたようですが、非コミッタの我々でも単純に警告の種類がいくつあるのかを確認したいときに便利だと思います。
標準ライブラリのアップデート
JSON.parse が約1.5倍速くなった
Ruby 3.4の JSON.parse メソッド(および JSON.loadメソッド)はRuby 3.3時代に比べて約1.5倍速くなったそうです。
CSV.open がBOMを自動検出するようになった
Ruby 3.4では CSV.open がCSVファイルに含まれるBOM(Byte Order Mark)を自動検出するようになりました。
たとえば、以下のようなCSVファイルがあり、ファイルの先頭にBOM(U+FEFF ZERO WIDTH NO-BREAK SPACE)が含まれているとします。
id,name
1,Alice
Ruby 3.3では以下のようなコードを書くと、idの値が取得できません。
# Ruby 3.3
CSV.open("with-bom.csv", headers: true) do |csv|
row = csv.to_a[0]
# あれ、1じゃないの!?
puts row["id"] #=> nil
# nameは正常に取得できるんだけど・・・
puts row["name"] #=> Alice
end
なぜなら、"id"の手前にBOMが含まれるからです。
以下のように書けば "id" を取得できます。
# BOMを明示的にヘッダ名に指定する
row["\u{feff}id"] #=> 1
ですが、BOMは目に見えない文字列なので、この問題に遭遇すると多くの人が row["id"] で値が取得できない理由がぱっとわからず、右往左往することになります(経験あり)。
Ruby 3.4ではBOMを自動検出してくれるので、row["\u{feff}id"] のようなコードを書かずとも値を取得できます。
# Ruby 3.4
CSV.open("with-bom.csv", headers: true) do |csv|
row = csv.to_a[0]
# BOMを自動検出してくれるので、普通にヘッダ名を指定すればOK!
puts row["id"] #=> 1
puts row["name"] #=> Alice
end
なお、これはcsv gem 3.3.1で導入された変更点なので、Ruby 3.4でなくても最新のcsv gemをインストールすれば同じ挙動になります。
そして、この変更は僕が投稿した以下のissueが発端となって対応してもらったのでした(ちょっと自慢?)。
irbに関する変更点
型ベースの入力補完ができるようになった
Ruby 3.4のirbでは型ベースの入力補完ができるようになりました。
たとえば以下の例ではnがIntegerであることを考慮してupまで入力するとuptoが補完候補として表示されています。

一方、以下の例ではsがStringになるので、upまで入力するとupcase、upcase!、uptoの3つが補完候補として表示されています。

この機能はRuby 3.3では実験的機能だったため、repl_type_completor gemのインストールや--type-completorオプションの指定が必要でしたが、Ruby 3.4ではデフォルトで使えるようになりました。
その他の変更点
ブロックを使わないメソッドにブロックを渡すと警告が出るようになった
次のようにブロックを使わないメソッドがあったとします。
def i_dont_use_block
"I don't use block."
end
i_dont_use_block { puts "Please call me!" }
Ruby 3.4では上のようにブロックを使わないメソッドに対してブロックを渡すと警告が出るようになりました(要 -w オプション)。
$ ruby -w sample/unused_block.rb
sample/unused_block.rb:5: warning: the block passed to 'Object#i_dont_use_block' defined at sample/unused_block.rb:1 may be ignored
ただし、1点だけ注意すべき点があります。
それはブロックを使用する同名メソッドがあると警告が出なくなる点です。
def i_dont_use_block
"I don't use block."
end
class Other
# 全く別のクラスに同名のメソッドを定義する
# 上のメソッドとは異なりこのメソッドはブロックを使用する
def i_dont_use_block
yield
end
end
i_dont_use_block { puts "Please call me!" }
# 上のコードを動かしても警告は出ない
$ ruby -w sample/unused_block.rb
これはダックタイピングを使って、あえてブロックを使うケースと使わないケースを同等に処理するコードがありうるためです。
class Myself
# こっちはブロックを使わない
def i_dont_use_block
"I don't use block."
end
end
class Other
# こっちはブロックを使う
def i_dont_use_block
yield
end
end
[Myself.new, Other.new].each do |obj|
# ブロックを使うかどうかに関わらず、ダックタイピング的に
# 全部まとめてブロックを付けてメソッドを呼び出す
obj.i_dont_use_block { puts "Please call me!" }
end
こういったケースも警告の対象にしたい場合は、-W:strict_unused_blockオプションを付けて実行すると警告が出るようになります。
$ ruby -W:strict_unused_block sample/unused_block.rb
sample/unused_block.rb:14: warning: the block passed to 'Myself#i_dont_use_block' defined at sample/unused_block.rb:2 may be ignored
Please call me!
:strict_unused_blockオプションを付けると誤検知が増える副作用もあるので、メリットとデメリットを天秤にかけて使用するオプションを検討してください。
参考文献: プロと読み解くRuby 3.4 NEWS - STORES Product Blog
なお、この警告は非推奨警告ではないため、RUBYOPT=-W:deprecated のように警告カテゴリを限定すると出力されません。
# 警告が出る
$ ruby -w sample/unused_block.rb
sample/unused_block.rb:5: warning: the block passed to 'Object#i_dont_use_block' defined at sample/unused_block.rb:1 may be ignored
$ RUBYOPT=-W ruby sample/unused_block.rb
sample/unused_block.rb:5: warning: the block passed to 'Object#i_dont_use_block' defined at sample/unused_block.rb:1 may be ignored
# 警告が出ない(指定されたカテゴリに属さないので)
$ ruby -W:deprecated sample/unused_block.rb
$ RUBYOPT=-W:deprecated ruby sample/unused_block.rb
:deprecated カテゴリではないので、この警告はあくまで開発者への注意喚起であり、将来的にこういった呼び出しが禁止されるわけではなさそうです。
パフォーマンスに影響が出そうなメソッドの再定義をすると警告が出るようになった
String#empty?やInteger#+など、Rubyのメソッドの中にはインタプリタやJITが実行を最適化しているメソッドがあります。
Ruby 3.4ではこうしたメソッドを再定義すると、警告が出るようになりました(要 -w オプション)。
class String
# String#empty? はインタプリタやJITが実行を最適化している
# にもかかわらず、わざわざ再定義した
def empty?
self.size == 0
end
end
puts "".empty?
puts "1".empty?
$ ruby -w sample/performance.rb
sample/performance.rb:2: warning: method redefined; discarding old empty?
true
false
警告の対象の対象になるメソッドはたとえば以下のようなメソッドです(参考)。
-
Integer:#+,#-,#*,#/,#%,#<,#>,#<=,#>= -
Float:#+,#-,#*,#/,#<,#>,#<=,#>= -
String:#freeze,#size,#length,#empty?,#+,#succ,#%,#-@ -
Array:#size,#length,#empty?,#hash -
Hash:#size,#length,#empty?,#[],#[]=
この警告のカテゴリは :performance です。
そのため、RUBYOPT=-W:deprecated のように、:performance以外の警告カテゴリを指定した場合は、この警告は表示されません。
また、:deprecated カテゴリではないので、この警告はあくまで開発者への注意喚起であり、将来的にこうしたメソッドの再定義が禁止されるわけではなさそうです。
base64やbigdecimalといった、いくつかのgemがbundled gemになった
Ruby 3.4では以下のgemがdefault gemからbundled gemになりました。
- mutex_m
- getoptlong
- base64
- bigdecimal
- observer
- abbrev
- resolv-replace
- rinda
- drb
- nkf
- syslog
- csv
bundled gemになると、Bundlerを使うシステム(例 Railsアプリケーションなど)では、明示的にGemfileにgemを記載してインストールしないと、ライブラリが見つからなくてエラーが発生する可能性があります。
特に、base64、bigdecimal、nkf、csvあたりはRailsアプリケーションでの使用頻度が高そうなので、Rubyのバージョンを上げる際は注意が必要です。
エラーが発生する例として、以下のようなBigDecimalを利用するRubyスクリプトを使ってみます。
require 'bigdecimal'
puts BigDecimal("0.1") + BigDecimal("0.2")
もし、Ruby 3.4の実行環境でbigdecimal gemをGemfileに追加せずにこのスクリプトをBundler経由で実行しようとするとエラーになります。
# bigdecimalをGemfileに追加せずにプログラムを実行しようとするとエラーになる
$ bundle exec ruby sample/bigdecimal.rb
sample/bigdecimal.rb:1: warning: bigdecimal was loaded from the standard library, but is not part of the default gems starting from Ruby 3.4.0.
You can add bigdecimal to your Gemfile or gemspec to silence this warning.
/Users/jnito/.rbenv/versions/3.4-dev/lib/ruby/3.4.0+1/bundled_gems.rb:81:in 'Kernel.require': cannot load such file -- bigdecimal (LoadError)
from /Users/jnito/.rbenv/versions/3.4-dev/lib/ruby/3.4.0+1/bundled_gems.rb:81:in 'block (2 levels) in Kernel#replace_require'
from sample/bigdecimal.rb:1:in '<main>'
上のようなエラーが出た場合は、Gemfileに読み込めなかったライブラリのgemを追加してbundle installしてください。
# Ruby 3.4ではbigdecimalをGemfileに追加する必要がある
gem 'bigdecimal'
こうすれば問題なく実行できるようになります。
$ bundle exec ruby sample/bigdecimal.rb
0.3e0
ただし、bundled gemに変更されることが事前にわかっている場合は、前のバージョンのRubyで警告が出ます。
以下はRuby 3.3でGemfileにbigdecimalを追加せずに実行しようとした場合の警告メッセージです。
$ bundle exec ruby sample/bigdecimal.rb
sample/bigdecimal.rb:1: warning: bigdecimal was loaded from the standard library, but will no longer be part of the default gems starting from Ruby 3.4.0.
You can add bigdecimal to your Gemfile or gemspec to silence this warning.
0.3e0
この警告を無視せずにちゃんと対応していれば、Ruby 3.3から3.4にアップデートしてもアプリケーションは問題なく動作するはずです。
「そもそもdefault gemとbundled gemって何?」と思った方は、以下の記事を参照してください。
様々な default gemやbundled gemがアップデートされた
Ruby 3.4でデフォルトでインストールされる default gem や bundled gem もいろいろとアップデートされています。
気になる方はNEWSページにあるアップデート情報をチェックしてみてください。
ガベージコレクター(GC)の実装を動的にロードできるようになった
Ruby 3.4ではガベージコレクターの実装を動的にロードできるようになった・・・みたいですが、詳細は確認できていません。どうもすいません!
参考情報としてRuby 3.4.0のリリースノートに書いてあった説明を転載させてもらいます。 ![]()
- Modular GC 機能により Ruby 標準とは異なる ガベージ・コレクタ (GC) の実装を動的にロードすることができるようになりました。この機能を使うには Ruby をビルドする時に
--with-modular-gcを指定してください。GC ライブラリは環境変数RUBY_GC_LIBRARYを用いて Ruby のランタイムにロードすることができます。[Feature #20351]- Ruby 組み込みのガベージ・コレクタは
gc/default/default.cファイルに分割され、 Ruby ランタイムとのやりとりはgc/gc_impl.hに定義される API を用いて行われます。組み込みのガベージコレクタはmake modular-gc MODULAR_GC=defaultというコマンドを用いてライブラリとしてもビルドすることができ、環境変数としてRUBY_GC_LIBRARY=defaultを定義することで有効にすることができます。 [Feature #20470]- MMTk をベースとした実験的な GC ライブラリが提供されました。このライブラリは
make modular-gc MODULAR_GC=mmtkコマンドによってビルドし、環境変数RUBY_GC_LIBRARY=mmtkによって有効化します。この機能を使うにはビルドを行うマシンに Rust のビルドツールを必要とします。 [Feature #20860]
YJITのパフォーマンスが向上し、メモリの使用量が減った
YJITも様々な改善が行われています。Ruby 3.4.0のリリースノートには以下のような概要(TL;DR)が載っていました。
- x86-64 と arm64 の両方のプラットフォームにおいて、ほとんどのベンチマークのパフォーマンスが向上しました。
- メタデータの圧縮と統一的なメモリ使用量制限によりメモリ使用量を削減しました。
- 様々な不具合修正: YJIT はより堅牢になり、より多くの環境でテストされました。
詳細な内容はRuby 3.4.0のリリースノートを参照してください。
まとめ
というわけで、この記事ではRuby 3.4の変更点と新機能をいろいろと紹介してみました。
冒頭にも書いたとおり、本記事で紹介していない変更点もまだまだたくさんあるので、以下の情報源もぜひチェックしてみてください。
今年も2024年のクリスマスにRuby 3.4を届けてくれるたMatzさんやコミッタのみなさんに感謝したいと思います。どうもありがとうございました!
みなさんもぜひRuby 3.4の新機能を試してみてくださいね。
メリークリスマス!🎄
PR: 拙著「プロを目指す人のためのRuby入門 改訂2版」が好評発売中です🍒
2021年12月2日に拙著「プロを目指す人のためのRuby入門」(通称・チェリー本)の改訂2版が発売されました。第1版の対象バージョンはRuby 2.4でしたが、改訂2版ではRuby 3.0をフルサポートしています。特に、Ruby 2.7から導入されたパターンマッチについては、新しく章を追加して基本から発展的な内容まで詳細に説明しています。
その他、改訂2版の変更点については以下のブログ記事で詳しく説明しています。
前述の通り、本書の対象バージョンはRuby 3.0ですが、Ruby 3.1以降で発生する記述内容との差異は、それぞれ以下の記事にまとめてあります。なので、多少バージョンが古くても安心して読んでいただけます😊