目次
意外と無駄な事務作業ってまだある
こんにちは。SIerで働いている新米エンジニアです。
みなさんはこの作業無駄だな…と感じる事務作業はあったりしませんか?
私は、入社以降、「え、この作業まだ人手でやってるの?」と感じる瞬間が多々ありました。。
特に、私がやっていた業務では「ある文書の中から値をコピーし、システムに転記する作業」を全て手動で実施する、ということがあり、どうにか自動化出来ないかな…と考えていました。
そこで、生成AIの勉強も兼ねて、Gemini + LangChainを利用して文書中から必要な情報を質問形式で取得できる仕組みを構築してみました。
今回は、検証用に適当に作成した以下の請求書から、合計金額を取得するRAGをpythonのlangchainで実装してみました。
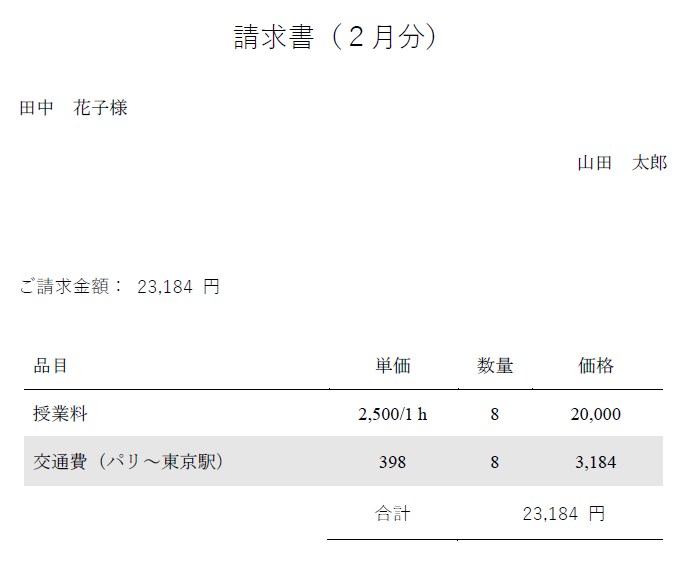
(検証用なので、かなり雑です。。)
実装してみた
以下が作成したコードになります。
環境構築
まず必要なライブラリをインストールします。
pip install -U langchain-openai
pip install langchain PyMuPDF openai faiss-cpu
pip install -U langchain-openai langchain-community
データ読み込みと準備
API KEYはOpenAIとGemini用をそれぞれのプラットフォームで事前に作成します。
私はGoogle colabで動かしていたので、API KEYはcolabのシークレットキーとして設定して読み込んでいましたが、皆様のお手元の環境に合わせて動かしていただけたらと思います。
import os
from google.colab import userdata
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# gemini APIキーの設定
google_api_key = userdata.get("GOOGLE_API_KEY")
os.environ["GOOGLE_API_KEY"] = google_api_key # 環境変数に設定
# OpenAI APIキーの設定
openai_api_key = userdata.get("API_KEY")
os.environ["OPENAI_API_KEY"] = openai_api_key # 環境変数に設定
# データ保存ディレクトリ
data_dir = "/content/data"
# データフォルダ内のドキュメントを読み込む
def load_documents_from_folder(folder_path):
documents = []
for file_name in os.listdir(folder_path):
if file_name.endswith(".pdf"):
loader = PyPDFLoader(os.path.join(folder_path, file_name))
documents.extend(loader.load())
return documents
documents = load_documents_from_folder("/content/data")
# ドキュメントをチャンクに分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
ベクトル検索のセットアップ
RAGの検索方法はベクトル検索を用いました。
ドキュメントの埋め込みにはOpen AIの埋め込み用モデルを用いています。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
質問応答チェーンの構築
今回は請求書から各項目をユーザーの質問に答える形で抜き出して回答するシステムなので、プロンプトはかなりシンプルでも機能しました。
実際、より複雑なドキュメントになってくると、few shotなどプロンプトエンジニアリングを考えて工夫する必要があるかもしれません。。
from langchain.chat_models import ChatGoogleGenerativeAI
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
# プロンプトテンプレートの定義
prompt_template = """
あなたは請求書から必要な情報を抜き出して教えてくれるRPAツールのバックエンド処理を担当するツールです。
以下の参考文献とこれまでの会話履歴をもとに、ユーザーの質問に対して正確かつ簡潔に答えてください。
回答の際には必ず参考文献からの情報を引用してください。
# 会話履歴
{chat_history}
# ユーザーの質問
{question}
# 参考文献
{context}
# 回答
"""
PROMPT = PromptTemplate(
input_variables=["chat_history", "context", "question"],
template=prompt_template
)
# 会話履歴を保持するメモリを作成
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# LLMとチェーンの設定
llm = ChatGoogleGenerativeAI(model="gemini-pro")
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm, retriever=retriever, memory=memory, combine_docs_chain_kwargs={"prompt": PROMPT}
)
実行
ユーザーの質問に基づいて回答を生成するようにします。
print("質問を入力してください(終了するには 'exit' と入力)")
while True:
query = input("ユーザー: ")
if query.lower() == 'exit':
print("プログラムを終了します。")
break
result = qa_chain({"question": query})
print("アシスタント:", result["answer"])
実行例
次のように質問すると、値を返してくれました!
質問:
1月の請求金額は?
回答:
23,184円
終わりに
今回は、請求書から転記したい値を取り出す部分のみ作成しました。
この後は、取り出した値をシステムにペーストするだけ…というところですが、そこの方が厄介そうなのでまだまだ先は長そうです…
(また、回答の安定性がどうか、などまだまだ課題はありそうです…)
実際に実装してみて、自動化も意外と難しいんだな、と感じました。。
また何か進展があったらブログを書きたいと思います!